
🥇Top ML Papers of the Week
The Top ML Papers of the Week (July 8 - July 14)

1). FlashAttention-3 - proposes to adapt FlashAttention to take advantage of modern hardware; the techniques used to speed up attention on modern GPUs include producer-consumer asynchrony, interleaving block-wise matmul and softmax operations, and block quantization and incoherent processing; achieves speedup on H100 GPUs by 1.5-2.0x with FP16 reaching up to 740 TFLOPs/s (75% utilization), and with FP8 reaching close to 1.2 PFLOPs/s. (paper | tweet)
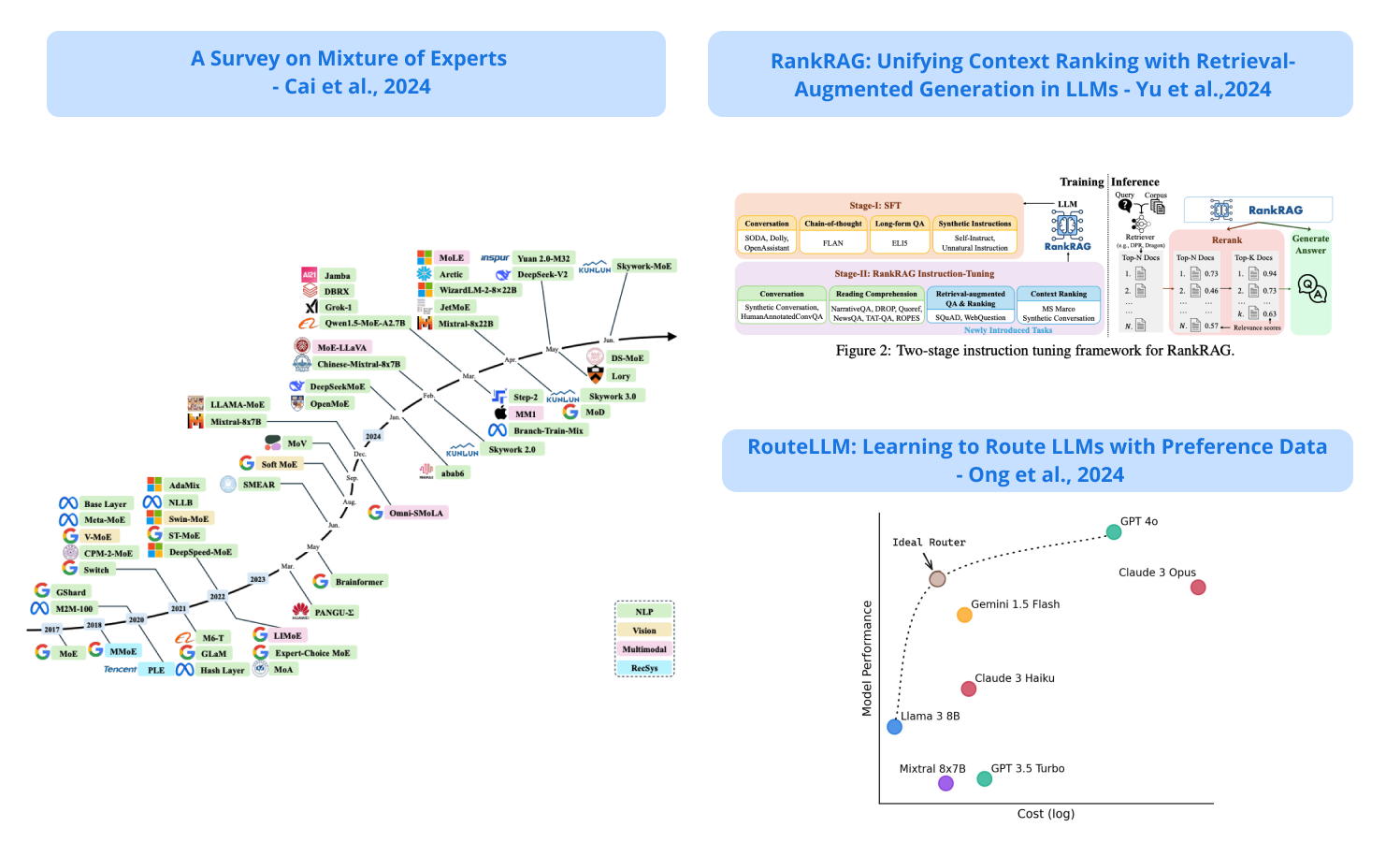
2). RankRAG - introduces a new instruction fine-tuning framework to perform effective context ranking and answering generation to enhance an LLM’s RAG capabilities; it leverages a small ranking dataset to outperform existing expert ranking models; shows that a Llama3-RankRAG significantly outperforms Llama3-ChatQA-1.5 and GPT-4 models on nine knowledge-intensive benchmarks. (paper | tweet)
3). Mixture of A Million Experts - introduces a parameter-efficient expert retrieval mechanism that leverages the product key technique for sparse retrieval from a million tiny experts; it attempts to decouple computational cost from parameter count by efficiently routing to a very large number of tiny experts through a learned index structure used for routing; demonstrates superior efficiency compared to dense FFW, coarse-grained MoEs, and Product Key Memory (PKM) layers. (paper | tweet)
4). Reasoning in LLMs: A Geometric Perspective - explores the reasoning of LLMs from a geometrical perspective; reports that a higher intrinsic dimension implies greater expressive capacity of the LLM; reports that they establish a connection between the expressive power of LLMs and the density of their self-attention graphs; their analysis demonstrates that the density of these graphs defines the intrinsic dimension of the inputs to the MLP blocks. (paper | tweet)
5). Contextual Hallucinations Mitigation in LLMs - proposes a new method that detects and significantly reduces contextual hallucinations in LLMs (e.g., reduces by 10% in the XSum summarization task); builds a hallucination detection model based on input features given by the ratio of attention weights on the context vs. newly generated tokens (for each attention head); the hypothesis is that contextual hallucinations are related to the extent to which an LLM attends to the provided contextual information; they also propose a decoding strategy based on their detection method which mitigates the contextual hallucination; the detector can also be transferred across models without the need for retraining. (paper | tweet)
Sponsor message
DAIR.AI presents a live cohort-based course, Prompt Engineering for LLMs, where you can learn about advanced prompting techniques, RAG, tool use in LLMs, agents, and other approaches that improve the capabilities, performance, and reliability of LLMs. Use promo code MAVENAI20 for a 20% discount.
Reach out to hello@dair.ai if you would like to promote with us. Our newsletter is read by over 65K AI Researchers, Engineers, and Developers.
6). RouteLLM - proposes efficient router models to dynamically select between stronger and weak LLMs during inference to achieve a balance between cost and performance; the training framework leverages human preference data and data augmentation techniques to boost performance; shows to significantly reduce costs by over 2x in certain cases while maintaining the quality of responses. (paper | tweet)
7). A Survey on Mixture of Experts - a survey paper on Mixture of Experts (MoE), including the technical details of MoE, open-source implementations, evaluation techniques, and applications of MoE in practice. (paper | tweet)
8). Internet of Agents - a new framework to address several limitations in multi-agent frameworks such as integrating diverse third-party agents and adaptability to dynamic task requirements; introduces an agent integration protocol, instant messaging architecture design, and dynamic mechanisms for effective collaboration among heterogeneous agents. (paper | tweet)
9). 3DGen - a new pipeline for end-to-end text-to-3D asset generation in under a minute; integrates state-of-the-art components like AssetGen and TextureGen to represent 3D objects in three ways, namely view space, in volumetric space, and in UV space; achieves a win rate of 68% with respect to the single-stage model. (paper | tweet)
10). Learning at Test Time - proposes new sequence modeling layers with linear complexity and an expressive hidden state; defines a hidden state as an ML model itself capable of updating even on test sequence; by a linear model and a two-layer MLP based hidden state is found to match or exceed baseline models like Transformers, Mamba, and modern RNNs; the linear model is faster than Transformer at 8k context and matches Mamba in wall-clock time. (paper | tweet)
Attention, as the core layer of the ubiquitous Transformer architecture, is the bottleneck for large language models and long context applications. FlashAttention (and FlashAttention-2) pioneered a way to accelerate attention on GPUs by minimizing memory reads/writes, and it is now being used by most libraries to speed up Transformer training and inference. This has led to a dramatic increase in LLM context lengths over the past two years, from 2-4K (GPT-3, OPT) to 128K (GPT-4), and even 1M (Llama 3). However, despite its success, FlashAttention has not fully leveraged the new capabilities of modern hardware, achieving only 35% of the theoretical peak FLOP utilization on H100 GPUs with FlashAttention-2. In this blog post, we describe three key techniques for accelerating attention on Hopper GPUs: (1) leveraging the asynchronicity of Tensor Cores and TMA by overlapping bulk computation and data movement through warp-specialization, (2) interleaving blocked matmul and softmax operations, and (3) taking advantage of hardware support for low-precision FP8 inconsistent processing.