
🥇Top ML Papers of the Week
The Top ML Papers of the Week (August 19 - August 25)

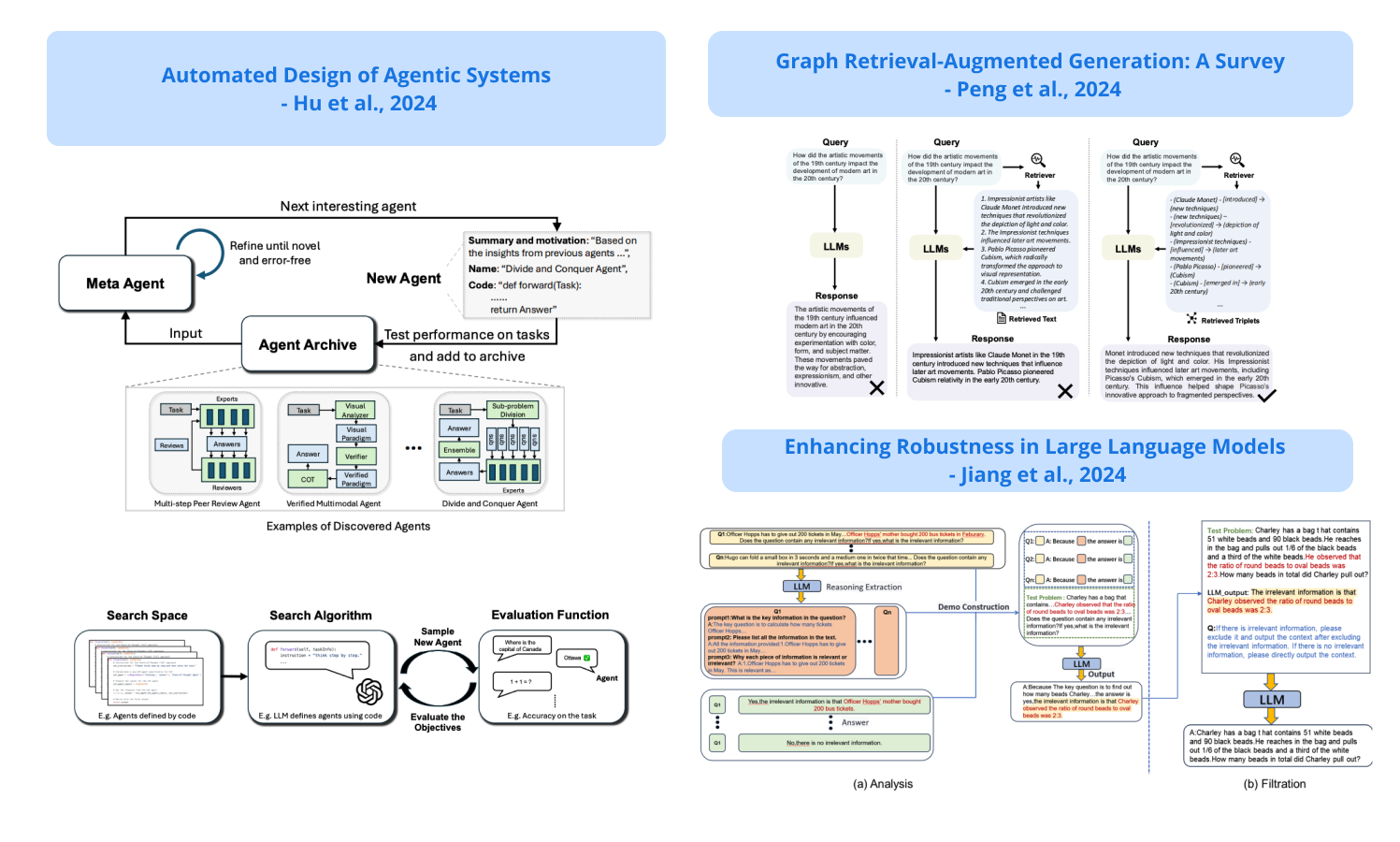
1). Automate Design of Agentic Systems - presents Meta Agent Search, a meta agent that iteratively programs and tests new agents based on a growing archive of previous discoveries; claims that with their approach it is possible to learn any possible agentic system including prompts, tool use, control flows, and more; they achieve this by focusing on three main components referred to as search space (define agents), search algorithm (explore search space), and the evaluation function (evaluate candidate agents). (paper | tweet)
2). LLM Pruning and Distillation in Practice - provides a comprehensive report on effective methods for compressing Llama 3.1 and Mistral NeMo models; it presents pruning and distillation approaches applied to the original models to produce 4B and 8B parameter models, respectively; before pruning, they also fine-tune the teacher model on their datasets leading to better distillation; their compression strategy yields a state-of-the-art 8B model (MN-Minitron-8B) which outperforms all similarly-sized models on common language modeling benchmarks. (paper | tweet)
3). Vizier Gaussian Process Bandit Algorithm - presents Vizier, an algorithm based on Gaussian process bandit optimization used by Google for millions of optimizations and research; it provides an open-source Python implementation of the Vizier algorithm, including benchmarking results that demonstrate its wider applicability. (paper | tweet)
4). Language Modeling on Tabular Data - presents a comprehensive survey of language modeling techniques for tabular data; includes topics such as categorization of tabular data structures and data types, datasets used for model training and evaluation, modeling techniques and training objectives, data processing methods, popular architectures, and challenges and future research directions. (paper | tweet)
5). Enhancing Robustness in LLMs - proposes a two-stage prompting technique to remove irrelevant information from context; it serves as a self-mitigation process that first identifies the irrelevant information and then filters it out; this leads to enhancement in robustness of the model and overall better performance on reasoning tasks. (paper | tweet)
6). A Comprehensive Overview of GraphRAG Methods - focuses on techniques applied to the GraphRAG workflow (graph-based indexing, graph-guided retrieval, and graph-enhanced generation); examines tasks, applications, evaluation, and industrial use cases of GraphRAG. (paper | tweet)
7). MagicDec - shows how speculative decoding can enhance throughput, reduce latency, and maintain accuracy in long context generation scenarios; it finds that as sequence length and batch size increase, bottlenecks shift from compute-bound to memory-bound; using these insights, they show it's possible to more effectively use speculative decoding for longer sequences, even when using large batch sizes. (paper | tweet)
8). Controllable Text Generation for LLMs - provides a comprehensive survey on methods for controllable text generation in LLMs; discusses issues like safety, consistency, style, and helpfulness. (paper | tweet)
9). PEDAL - uses a hybrid self-ensembling approach (based on diverse exemplars) to improve the overall performance of LLMs; specifically, it uses diverse exemplars to generate multiple candidate responses and then aggregates them using an LLM to generate a final response; this approach achieves better accuracy compared to greedy decoding and lower cost compared to self-consistency approaches. (paper | tweet)
10). Challenges and Responses in the Practice of LLMs - curates a set of important questions with insightful answers; questions are categorized across topics such as infrastructure, software architecture, data, application, and brain science. (paper | tweet)