
🥇Top ML Papers of the Week
The top ML Papers of the Week (July 31- August 6)

1). Open Problem and Limitation of RLHF - provides an overview of open problems and the limitations of RLHF. (paper | tweet)
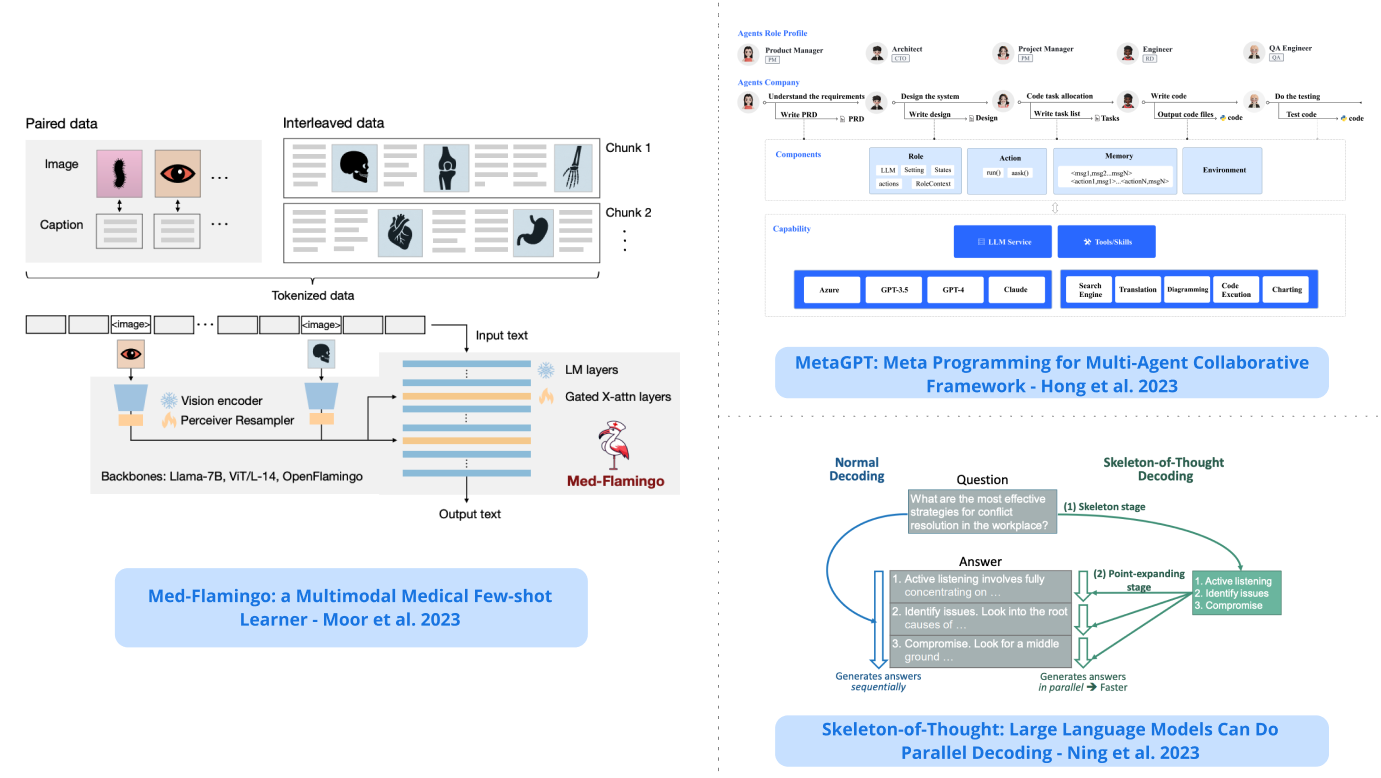
2). Med-Flamingo - a new multimodal model that allows in-context learning and enables tasks such as few-shot medical visual question answering; evaluations based on physicians, show improvements of up to 20% in clinician's rating; the authors occasionally observed low-quality generations and hallucinations. (paper | tweet)
3). ToolLLM - enables LLMs to interact with 16000 real-world APIs; it’s a framework that allows data preparation, training, and evaluation; the authors claim that one of their models, ToolLLaMA, has reached the performance of ChatGPT (turbo-16k) in tool use. (paper | tweet)
4). Skeleton-of-Thought - proposes a prompting strategy that firsts generate an answer skeleton and then performs parallel API calls to generate the content of each skeleton point; reports quality improvements in addition to speed-up of up to 2.39x. (paper | tweet)
5). MetaGPT - a framework involving LLM-based multi-agents that encodes human standardized operating procedures (SOPs) to extend complex problem-solving capabilities that mimic efficient human workflows; this enables MetaGPT to perform multifaceted software development, code generation tasks, and even data analysis using tools like AutoGPT and LangChain. (paper | tweet)
Sponsor message
DAIR.AI presents a new cohort-based course, Prompt Engineering for LLMs, that teaches how to effectively use the latest prompt engineering techniques and tools to improve the capabilities, performance, and reliability of LLMs. Enroll here.
6). OpenFlamingo - introduces a family of autoregressive vision-language models ranging from 3B to 9B parameters; the technical report describes the models, training data, and evaluation suite. (paper | tweet)
7). The Hydra Effect - shows that language models exhibit self-repairing properties — when one layer of attention heads is ablated it causes another later layer to take over its function. (paper | tweet)
8). Self-Check - explores whether LLMs have the capability to perform self-checks which is required for complex tasks that depend on non-linear thinking and multi-step reasoning; it proposes a zero-shot verification scheme to recognize errors without external resources; the scheme can improve question-answering performance through weighting voting and even improve math word problem-solving. (paper | tweet)
9). Agents Model the World with Language - presents an agent that learns a multimodal world model that predicts future text and image representations; it learns to predict future language, video, and rewards; it’s applied to different domains and can learn to follow instructions in visually and linguistically complex domains. (paper | tweet)
10). AutoRobotics-Zero - discovers zero-shot adaptable policies from scratch that enable adaptive behaviors necessary for sudden environmental changes; as an example, the authors demonstrate the automatic discovery of Python code for controlling a robot. (paper | tweet)