
🥇Top ML Papers of the Week
The top ML Papers of the Week (Sep 4 - September 10)

1). Transformers as SVMs - finds that the optimization geometry of self-attention in Transformers exhibits a connection to hard-margin SVM problems; also finds that gradient descent applied without early-stopping leads to implicit regularization and convergence of self-attention; this work has the potential to deepen the understanding of language models. (paper)
2). Scaling RLHF with AI Feedback - tests whether RLAIF is a suitable alternative to RLHF by comparing the efficacy of human vs. AI feedback; uses different techniques to generate AI labels and conduct scaling studies to report optimal settings for generating aligned preferences; the main finding is that on the task of summarization, human evaluators prefer generations from both RLAIF and RLHF over a baseline SFT model in ∼70% of cases. (paper | tweet)
3). GPT Solves Math Problems Without a Calculator - shows that with sufficient training data, a 2B language model can perform multi-digit arithmetic operations with 100% accuracy and without data leakage; it’s also competitive with GPT-4 on 5K samples Chinese math problem test set when fine-tuned from GLM-10B on a dataset containing additional multi-step arithmetic operations and detailed math problems. (paper | tweet)
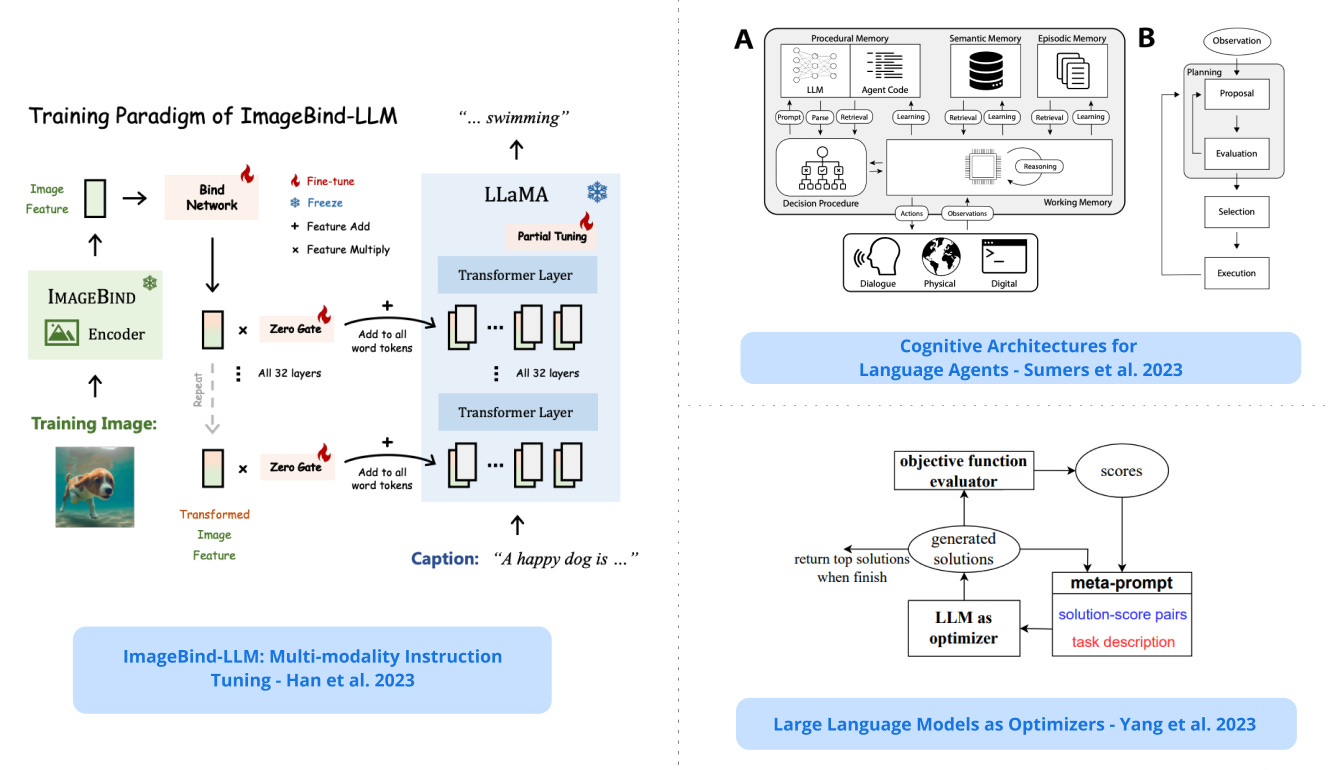
4). LLMs as Optimizers - an approach where the optimization problem is described in natural language; an LLM is then instructed to iteratively generate new solutions based on the defined problem and previously found solutions; at each optimization step, the goal is to generate new prompts that increase test accuracy based on the trajectory of previously generated prompts; the optimized prompts outperform human-designed prompts on GSM8K and Big-Bench Hard, sometimes by over 50% (paper | tweet)
5). Multi-modality Instruction Tuning - presents ImageBind-LLM, a multimodality instruction tuning method of LLMs via ImageBind; this model can respond to instructions of diverse modalities such as audio, 3D point clouds, and video, including high language generation quality; this is achieved by aligning ImageBind’s visual encoder with an LLM via learnable bind network. (paper | tweet)
Reach out to hello@dair.ai if you would like to sponsor the next issue of the newsletter. We can help promote your AI tool, research, or company to ~10K AI researchers and practitioners.
6). Explaining Grokking - aims to explain grokking behavior in neural networks; specifically, it predicts and shows two novel behaviors: the first is ungrokking where a model goes from perfect generalization to memorization when trained further on a smaller dataset than the critical threshold; the second is semi-grokking where a network demonstrates grokking-like transition when training a randomly initialized network on the critical dataset size. (paper | tweet)
7). Overview of AI Deception - provides a survey of empirical examples of AI deception. (paper | tweet)
8). FLM-101B - a new open LLM called FLM-101B with 101B parameters and 0.31TB tokens which can be trained on a $100K budget; the authors analyze different growth strategies, growing the number of parameters from smaller sizes to large ones. They ultimately employ an aggressive strategy that reduces costs by >50%. In other words, three models are trained sequentially with each model inheriting knowledge from its smaller predecessor (16B -> 51B -> 101B) while achieving competitive performance.(paper | tweet)
9). Cognitive Architecture for Language Agents - proposes a systematic framework for understanding and building fully-fledged language agents drawing parallels from production systems and cognitive architectures; it systematizes diverse methods for LLM-based reasoning, grounding, learning, and decision making as instantiations of language agents in the framework. (paper | tweet)
10). Q-Transformer - a scalable RL method for training multi-task policies from large offline datasets leveraging human demonstrations and autonomously collected data; shows good performance on a large diverse real-world robotic manipulation task suite. (paper | tweet)