
🥇Top ML Papers of the Week
The top ML Papers of the Week (Dec 18 - Dec 24)

1). Gemini’s Language Abilities - provides an impartial and reproducible study comparing several popular models like Gemini, GPT, and Mixtral; Gemini Pro achieves comparable but slightly lower accuracy than the current version of GPT 3.5 Turbo; Gemini and GPT were better than Mixtral. (paper | tweet)
2). PowerInfer - a high-speed inference engine for deploying LLMs locally; exploits the high locality in LLM inference to design a GPU-CPU hybrid inference engine; hot-activated neurons are preloaded onto the GPU for fast access, while cold-activated neurons (the majority) are computed on the CPU; this approach significantly reduces GPU memory demands and CPU-GPU data transfer. (paper | tweet)
3). Discovery of a New Family of Antibiotics with Graph Deep Learning - discovered a new structural class of antibiotics with explainable graph algorithms; the approach enables explainable deep learning guided discovery of structural classes of antibiotics which helps to provide chemical substructures that underlie antibiotic activity. (paper | tweet)
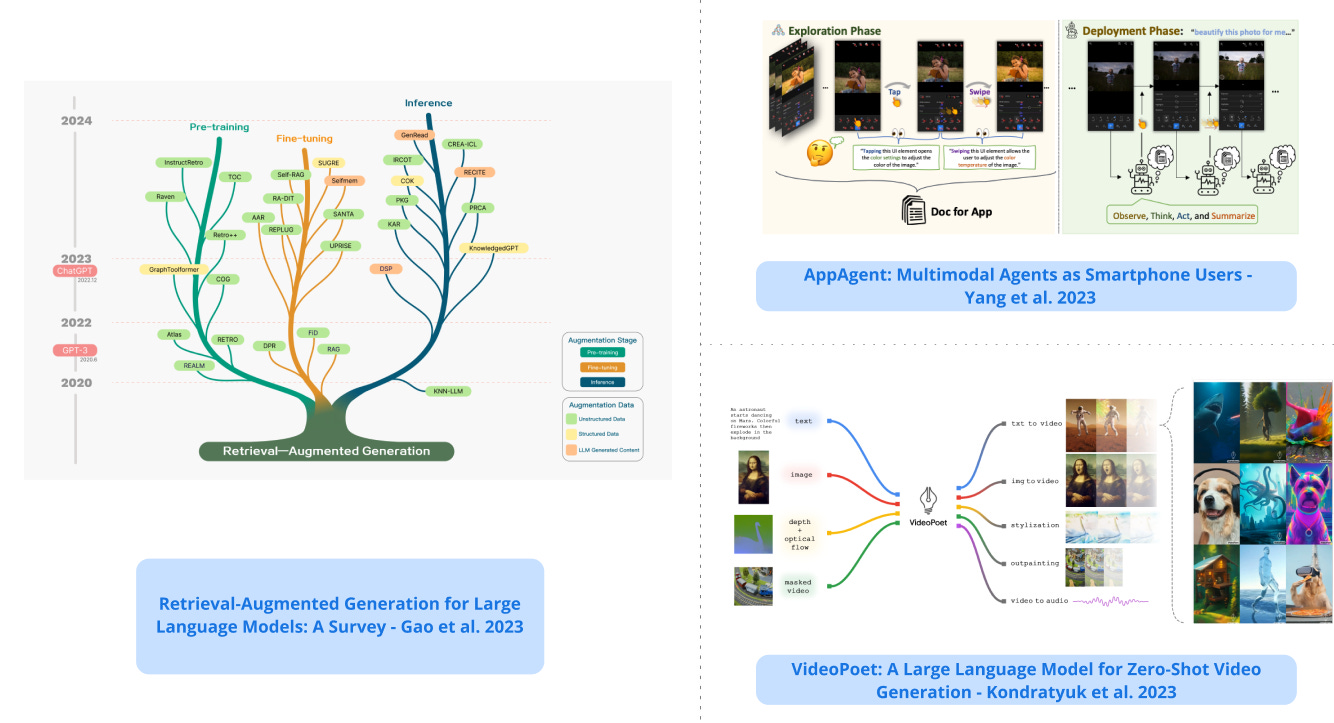
4). VideoPoet - introduces a large language model for zero-shot video generation; it’s capable of a variety of video generation tasks such as image-to-video and video stylization; trains an autoregressive model to learn across video, image, audio, and text modalities by using multiple tokenizers; shows that language models can synthesize and edit video with some degree of temporal consistency. (paper | tweet)
5). Multimodal Agents as Smartphone Users - introduces an LLM-based multimodal agent framework to operate smartphone applications; learns to navigate new apps through autonomous exploration or observing human demonstrations; shows proficiency in handling diverse tasks across different applications like email, social media, shopping, editing tools, and more. (paper | tweet)
6). LLM in a Flash - proposes an approach that efficiently runs LLMs that exceed the available DRAM capacity by storing the model parameters on flash memory but bringing them on demand to DRAM; enables running models up to twice the size of the available DRAM, with a 4-5x and 20-25x increase in inference speed compared to naive loading approaches in CPU and GPU, respectively. (paper | tweet)
7). ReST Meets ReAct - proposes a ReAct-style agent with self-critique for improving on the task of long-form question answering; it shows that the agent can be improved through ReST-style (reinforced self-training) iterative fine-tuning on its reasoning traces; specifically, it uses growing-batch RL with AI feedback for continuous self-improvement and self-distillation; like a few other recent papers, it focuses on minimizing human involvement (i.e., doesn't rely on human-labeled training data); it generates synthetic data with self-improvement from AI feedback which can then be used to distill the agent into smaller models (1/2 orders magnitude) with comparable performance as the pre-trained agent. (paper | tweet)
8). Adversarial Attacks on GPT-4 - uses a simple random search algorithm to implement adversarial attacks on GPT-4; it achieves jailbreaking by appending an adversarial suffix to an original request, then iteratively making slight random changes to the suffix, and keeping changes if it increases the log probability of the token “Sure” at the first position of the response. (paper | tweet)
9). RAG for LLMs - an overview of all the retrieval augmented generation (RAG) research that has been happening. (paper | tweet)
10). Findings of the BabyLLM Challenge - presents results for a new challenge that involves sample-efficient pretraining on a developmentally plausible corpus; the winning submission, which uses flashy LTG BERT, beat Llama 2 70B on 3/4 evals; other approaches that saw good results included data preprocessing or training on shorter context. (paper | tweet)
“Multimodal Agents as Smartphone Users” This one sounds very interesting 👀