
🥇Top ML Papers of the Week
The Top ML Papers of the Week (August 12 - August 18)

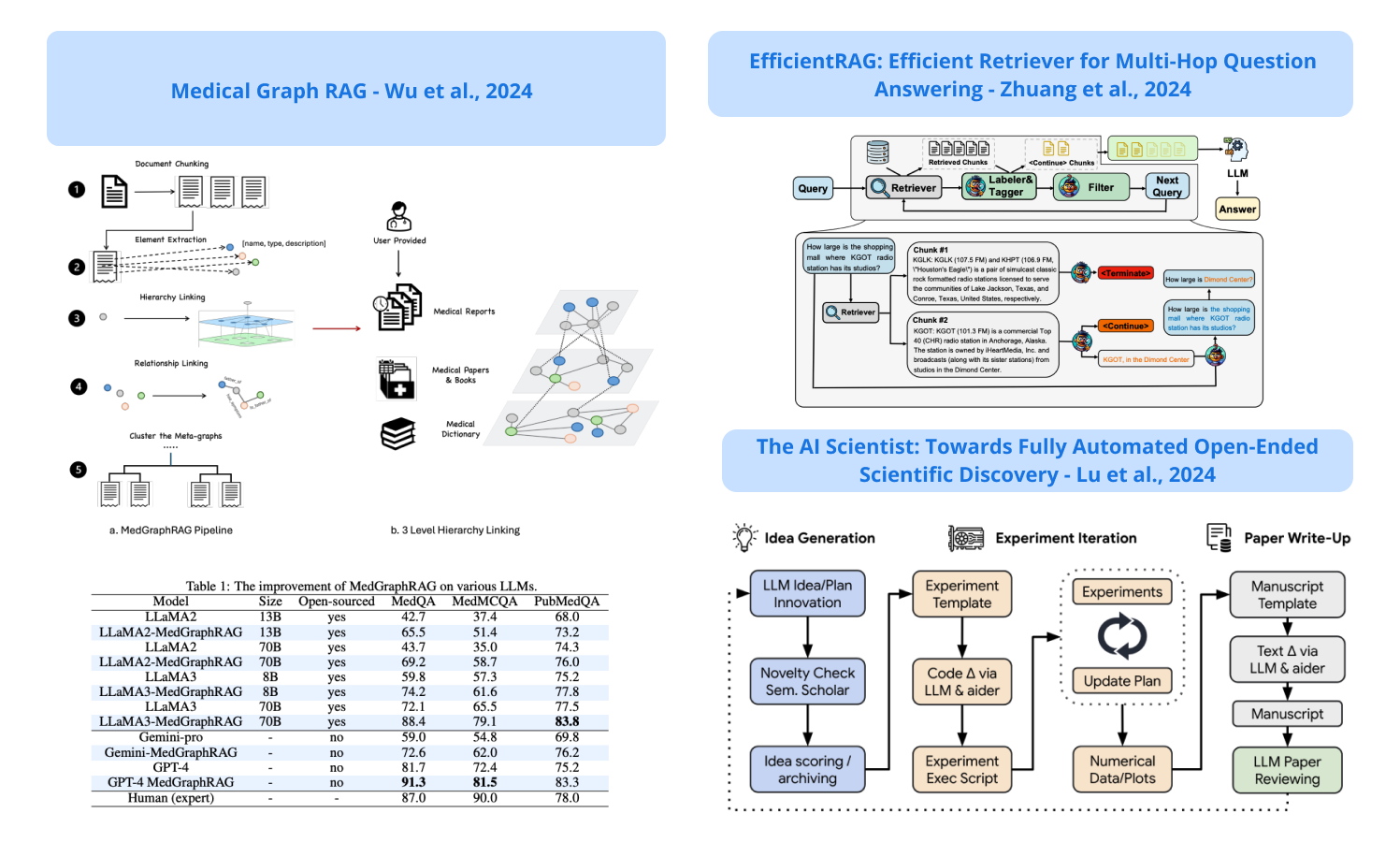
1). The AI Scientist - a novel AI agent that can develop and write a full conference-level scientific paper costing less than $15; it automates scientific discovery by enabling frontier LLMs to perform independent research and summarize findings; it also uses an automated reviewer to evaluate the generated papers; claims to achieve near-human performance in evaluating paper scores; claims to produce papers that exceed the acceptance threshold at a top machine learning conference as judged by their automated reviewer. (paper | tweet)
2). Grok-2 - a new frontier model with strong code, math, and reasoning capabilities which includes a large and small model; outperforms both Claude 3.5 Sonnet and GPT-4-Turbo on the LMSYS Chatbot Arena; claims to improve capabilities including instruction following, retrieval, tool use, and enhancing factuality; competes with Claude 3.5 Sonnet (June release) and GPT-4o (May release) on MMLU and HumanEval. (paper | tweet)
3). LongWriter - proposes AgentWrite to enable off-the-shelf LLMs to generate coherent outputs beyond 20K words; AgentWrite breaks down the long generation task into subtasks and in a divide-and-conquer approach generates; the agent breaks the task into multiple writing subtasks and concatenates the outputs to get a final output (i.e., plan + write); the approach is then used to build SFT datasets that are used to tune LLMs to generate coherent longer outputs automatically; a 9B parameter model, further improved through DPO, achieves state-of-the-art performance on their benchmark, and surpasses proprietary models. (paper | tweet)
4). EfficientRAG - trains an auto-encoder LM to label and tag chunks; it retrieves relevant chunks, tags them as either <Terminate> or <Continue>, and annotates <Continue> chunks for continuous processing; then a filter model is trained to formulate the next-hop query based on the original question and previous annotations; this is done iteratively until all chunks are tagged as <Terminate> or the maximum # of iterations is reached; after the process above has gathered enough information to answer the initial question, the final generator (an LLM) generates the final answer. (paper | tweet)
5). RAGChecker - a fine-grained evaluation framework for diagnosing retrieval and generation modules in RAG; shows that RAGChecker has better correlations with human judgment; reports several revealing insightful patterns and trade-offs in design choices of RAG architectures. (paper | tweet)
Sponsor message
DAIR.AI presents a live cohort-based course, Prompt Engineering for LLMs, where you can learn about advanced prompting techniques, RAG, tool use in LLMs, agents, and other approaches that improve the capabilities, performance, and reliability of LLMs. Use promo code MAVENAI20 for a 20% discount.
6). HybridRAG - combines GraphRAG and VectorRAG leading to a HybridRAG system that outperforms both individually; it was tested on a set of financial earning call transcripts. Combining the advantages of both approaches provides more accurate answers to queries. (paper | tweet)
7). rStar - introduces self-play mutual reasoning to improve the reasoning capabilities of small language models without fine-tuning or superior models; MCTS is augmented with human-like reasoning actions, obtained from SLMs, to build richer reasoning trajectories; a separate SLM provides unsupervised feedback on the trajectories and the target SLM selects the final reasoning trajectory as the answer; rStar boosts GSM8K accuracy from 12.51% to 63.91% for LLaMA2-7B and consistently improves the accuracy of other SLMs. (paper | tweet)
8). Scaling LLM Test-Time Compute Optimally - investigates the scaling behaviors of inference-time computation in LLMs; in particular, it analyses how much an LLM can be improved provided a fixed amount of inference-time compute; finds that the effectiveness of different scaling approaches varies by difficulty of prompt; it then proposes an adaptive compute-optimal strategy that can improve efficiency by more than 4x compared to a best-of-N baseline; reports that in a FLOPs-matched evaluation, optimally scaling test-time compute can outperform a 14x larger model. (paper | tweet)
9). MedGraphRAG - a graph-based framework for the medical domain with a focus on enhancing LLMs and generating evidence-based results; leverages a hybrid static-semantic approach to chunk documents to improve context capture; entities and medical knowledge are represented through graphs which leads to an interconnected global graph; this approach improves precision and outperforms state-of-the-art models on multiple medical Q&A benchmarks. (paper | tweet)
10). Survey of NL2QL - a comprehensive overview of NL2SQL techniques powered by LLMs; covers models, data collection, evaluation methods, and error analysis. (paper | tweet)
Reach out to hello@dair.ai if you would like to promote with us. Our newsletter is read by over 75K AI Researchers, Engineers, and Developers.