
🥇Top ML Papers of the Week
The top ML Papers of the Week (July 10 - July 16)

1). CM3Leon - introduces a retrieval-augmented multi-modal language model that can generate text and images; leverages diverse and large-scale instruction-style data for tuning which leads to significant performance improvements and 5x less training compute than comparable methods. (paper | tweet)
2). Claude 2 - presents a detailed model card for Claude 2 along with results on a range of safety, alignment, and capabilities evaluations. (paper | tweet)
3). Secrets of RLHF in LLMs - takes a closer look at RLHF and explores the inner workings of PPO with code included. (paper | tweet)
A word from our Sponsor:

Spectral AI is looking for data scientists—especially modelers with web3 experience—for product interviews. Talk to us for a half hour about your work, experience with Kaggle, and other competitions in exchange for a $50 Amazon gift card, and a hand in shaping our latest product, a decentralized ML marketplace. Sign up here!
4). LongLLaMA - employs a contrastive training process to enhance the structure of the (key, value) space to extend context length; presents a fine-tuned model that lengthens context and demonstrates improvements in long context tasks. (paper | tweet)
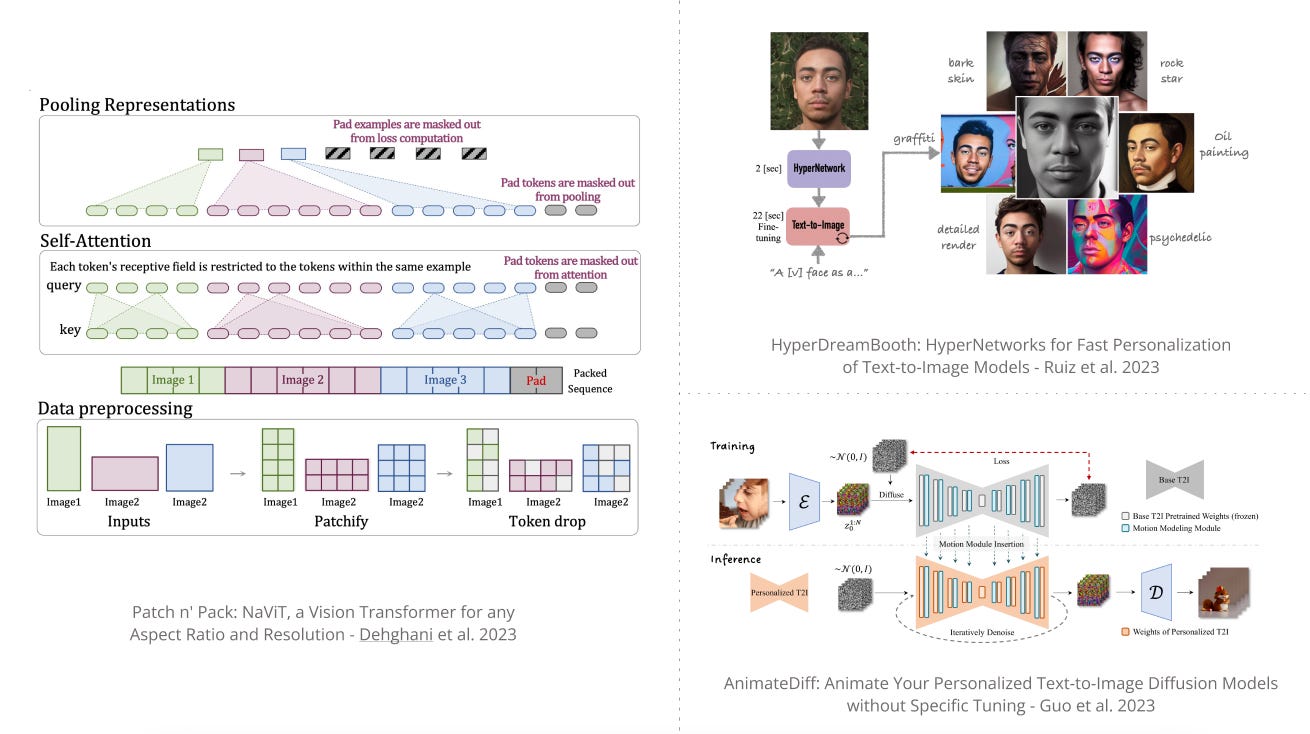
5). Patch n’ Pack: NaViT - introduces a vision transformer for any aspect ratio and resolution through sequence packing; enables flexible model usage, improved training efficiency, and transfers to tasks involving image and video classification among others. (paper | tweet)
6). LLMs as General Pattern Machines - shows that even without any additional training, LLMs can serve as general sequence modelers, driven by in-context learning; this work applies zero-shot capabilities to robotics and shows that it’s possible to transfer the pattern among words to actions. (paper | tweet)
7). HyperDreamBooth - introduces a smaller, faster, and more efficient version of Dreambooth; enables personalization of text-to-image diffusion model using a single input image, 25x faster than Dreambooth. (paper | tweet)
8). Teaching Arithmetics to Small Transformers - trains small transformer models on chain-of-thought style data to significantly improve accuracy and convergence speed; it highlights the importance of high-quality instructive data for rapidly eliciting arithmetic capabilities. (paper | tweet)
9). AnimateDiff - appends a motion modeling module to a frozen text-to-image model, which is then trained and used to animate existing personalized models to produce diverse and personalized animated images. (paper | tweet)
10). Generative Pretraining in Multimodality - presents a new transformer-based multimodal foundation model to generate images and text in a multimodal context; enables performant multimodal assistants via instruction tuning. (paper | tweet)
Reach out to ellfae@gmail.com if you would like to sponsor an upcoming issue of the newsletter.