
🥇Top ML Papers of the Week
The top ML Papers of the Week (Nov 20 - Nov 26)

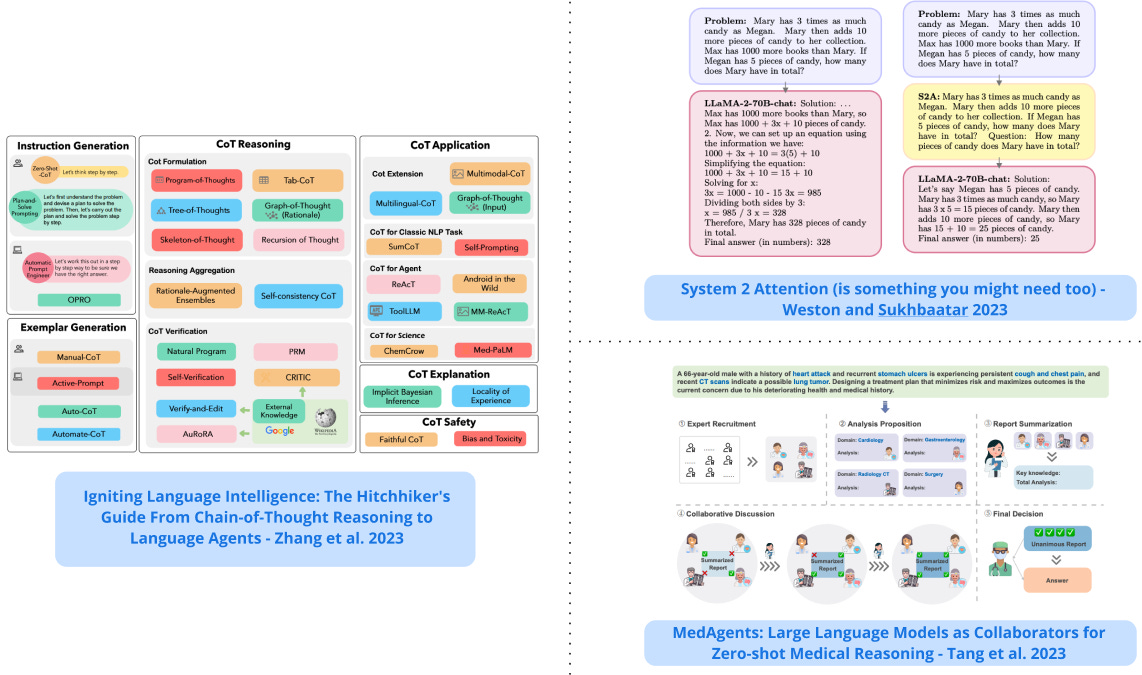
1). System 2 Attention - leverages the reasoning and instruction following capabilities of LLMs to decide what to attend to; it regenerates input context to only include relevant portions before attending to the regenerated context to elicit the final response from the model; increases factuality and outperforms standard attention-based LLMs on tasks such as QA and math world problems. (paper | tweet)
2). Advancing Long-Context LLMs - an overview of the methodologies for enhancing Transformer architecture modules that optimize long-context capabilities across all stages from pre-training to inference. (paper | tweet)
3). Parallel Speculative Sampling - approach to reduce inference time of LLMs based on a variant of speculative sampling and parallel decoding; achieves significant speed-ups (up to 30%) by only learning as little as O(d_emb) additional parameters. (paper | tweet)
4). Mirasol3B - a multimodal model for learning across audio, video, and text which decouples the multimodal modeling into separate, focused autoregressive models; the inputs are processed according to the modalities; this approach can handle longer videos compared to other models and it outperforms state-of-the-art approach on video QA, long video QA, and audio-video-text benchmark. (paper | tweet)
5). Teaching Small LMs To Reason - proposes an approach to teach smaller language models to reason; specifically, the LM is thought to use reasoning techniques, such as step-by-step processing, recall-then-generate, recall-reason-generate, extract-generate, and direct-answer methods; outperforms models of similar size and attains performance levels similar or better to those of models 5-10x larger, as assessed on complex tasks that test advanced reasoning abilities in zero-shot settings. (paper | tweet)
6). GPQA - proposes a graduate-level Google-proof QA benchmark consisting of 448 multiple-choice questions written by domain experts in biology, physics, and chemistry; the strongest GPT-4 based baseline achieves 39% accuracy; this benchmark offers scalable oversight experiments that can help obtain reliable and truthful information from modern AI systems that surpass human capabilities. (paper | tweet)
7). The Hitchhiker’s Guide From Chain-of-Thought Reasoning to Language Agents - summary of CoT reasoning, foundational mechanics underpinning CoT techniques, and their application to language agent frameworks. (paper | tweet)
8). GAIA - a benchmark for general AI assistants consisting of real-world questions that require a set of fundamental abilities such as reasoning, multimodal handling, web browsing, and generally tool-use proficiency; shows that human respondents obtain 92% vs. 15% for GPT-4 equipped with plugins. (paper | tweet)
9). LLMs as Collaborators for Medical Reasoning - proposes a collaborative multi-round framework for the medical domain that leverages role-playing LLM-based agents to enhance LLM proficiency and reasoning capabilities. (paper | tweet)
10). TÜLU 2 - presents a suite of improved TÜLU models for advancing the understanding and best practices of adapting pretrained language models to downstream tasks and user preferences; TÜLU 2 suite achieves state-of-the-art performance among open models and matches or exceeds the performance of GPT-3.5-turbo-0301 on several benchmarks. (paper | tweet)