
🥇Top ML Papers of the Week
The top ML Papers of the Week (Oct 2 - Oct 8)

1). LLMs Represent Space and Time - discovers that LLMs learn linear representations of space and time across multiple scales; the representations are robust to prompt variations and unified across different entity types; demonstrate that LLMs acquire fundamental structured knowledge such as space and time, claiming that language models learn beyond superficial statistics, but literal world models. (paper | tweet)
2). Retrieval meets Long Context LLMs - compares retrieval augmentation and long-context windows for downstream tasks to investigate if the methods can be combined to get the best of both worlds; an LLM with a 4K context window using simple RAG can achieve comparable performance to a fine-tuned LLM with 16K context; retrieval can significantly improve the performance of LLMs regardless of their extended context window sizes; a retrieval-augmented LLaMA2-70B with a 32K context window outperforms GPT-3.5-turbo-16k on seven long context tasks including question answering and query-based summarization. (paper | tweet)
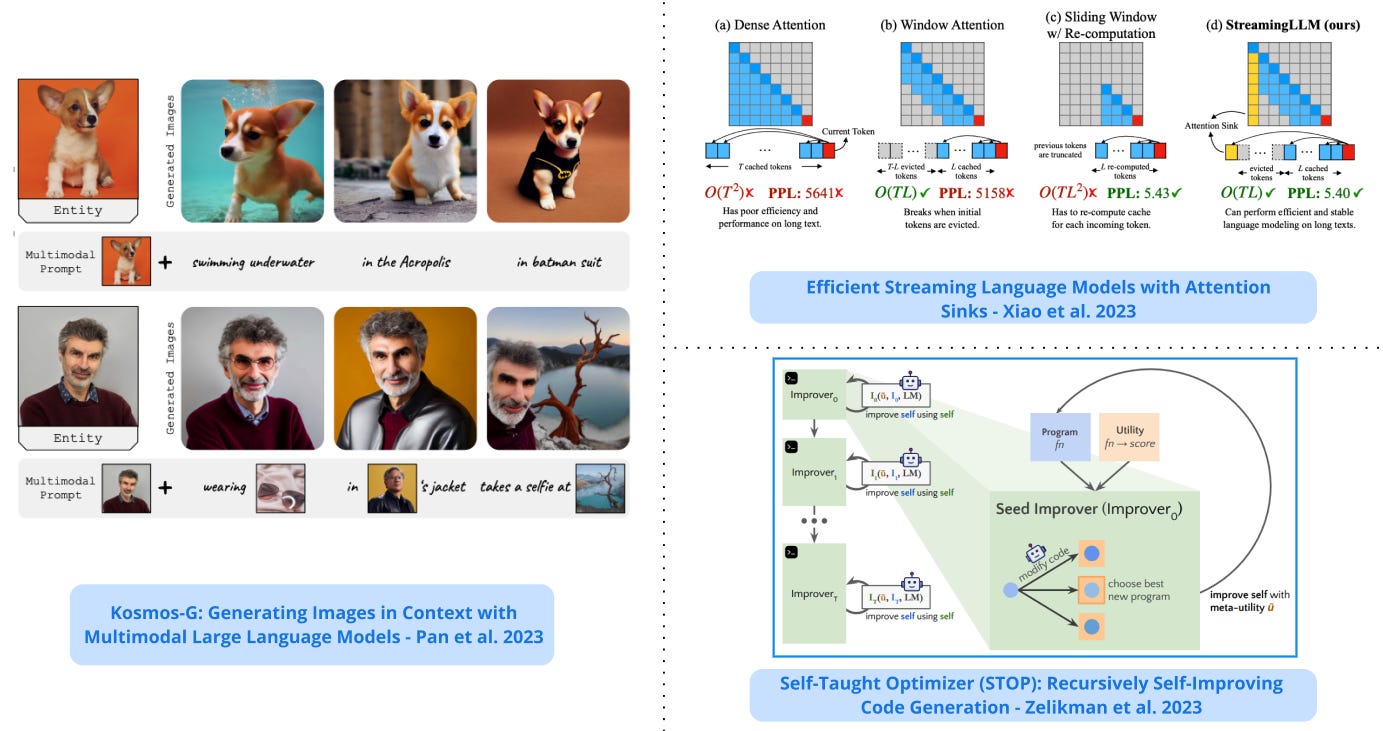
3). StreamingLLM - a framework that enables efficient streaming LLMs with attention sinks, a phenomenon where the KV states of initial tokens will largely recover the performance of window attention; the emergence of the attention sink is due to strong attention scores towards the initial tokens; this approach enables LLMs trained with finite length attention windows to generalize to infinite sequence length without any additional fine-tuning. (paper | tweet)
4). Neural Developmental Programs - proposes to use neural networks that self-assemble through a developmental process that mirrors properties of embryonic development in biological organisms (referred to as neural developmental programs); shows the feasibility of the approach in continuous control problems and growing topologies. (paper | tweet)
5). The Dawn of LMMs - a comprehensive analysis of GPT-4V to deepen the understanding of large multimodal models (LMMs); it focuses on probing GPT-4V across various application scenarios; provides examples ranging from code capabilities with vision to retrieval-augmented LMMs. (paper | tweet)
6). Training LLMs with Pause Tokens - performs training and inference on LLMs with a learnable <pause> token which helps to delay the model's answer generation and attain performance gains on general understanding tasks of Commonsense QA and math word problem-solving; experiments show that this is only beneficial provided that the delay is introduced in both pertaining and downstream fine-tuning. (paper | tweet)
7). Recursively Self-Improving Code Generation - proposes the use of a language model-infused scaffolding program to recursively improve itself; a seed improver first improves an input program that returns the best solution which is then further tasked to improve itself; shows that the GPT-4 models can write code that can call itself to improve itself. (paper | tweet)
8). Retrieval-Augmented Dual Instruction Tuning - proposes a lightweight fine-tuning method to retrofit LLMs with retrieval capabilities; it involves a 2-step approach: 1) updates a pretrained LM to better use the retrieved information 2) updates the retriever to return more relevant results, as preferred by the LM Results show that fine-tuning over tasks that require both knowledge utilization and contextual awareness, each stage leads to additional gains; a 65B model achieves state-of-the-art results on a range of knowledge-intensive zero- and few-shot learning benchmarks; it outperforms existing retrieval-augmented language approaches by up to +8.9% in zero-shot and +1.4% in 5-shot. (paper | tweet)
9). KOSMOG-G - a model that performs high-fidelity zero-shot image generation from generalized vision-language input that spans multiple images; extends zero-shot subject-driven image generation to multi-entity scenarios; allows the replacement of CLIP, unlocking new applications with other U-Net techniques such as ControlNet and LoRA. (paper | tweet)
10). Analogical Prompting - a new prompting approach to automatically guide the reasoning process of LLMs; the approach is different from chain-of-thought in that it doesn’t require labeled exemplars of the reasoning process; the approach is inspired by analogical reasoning and prompts LMs to self-generate relevant exemplars or knowledge in the context. (paper | tweet)