
🥇Top ML Papers of the Week
The Top ML Papers of the Week (December 30 - January 5)

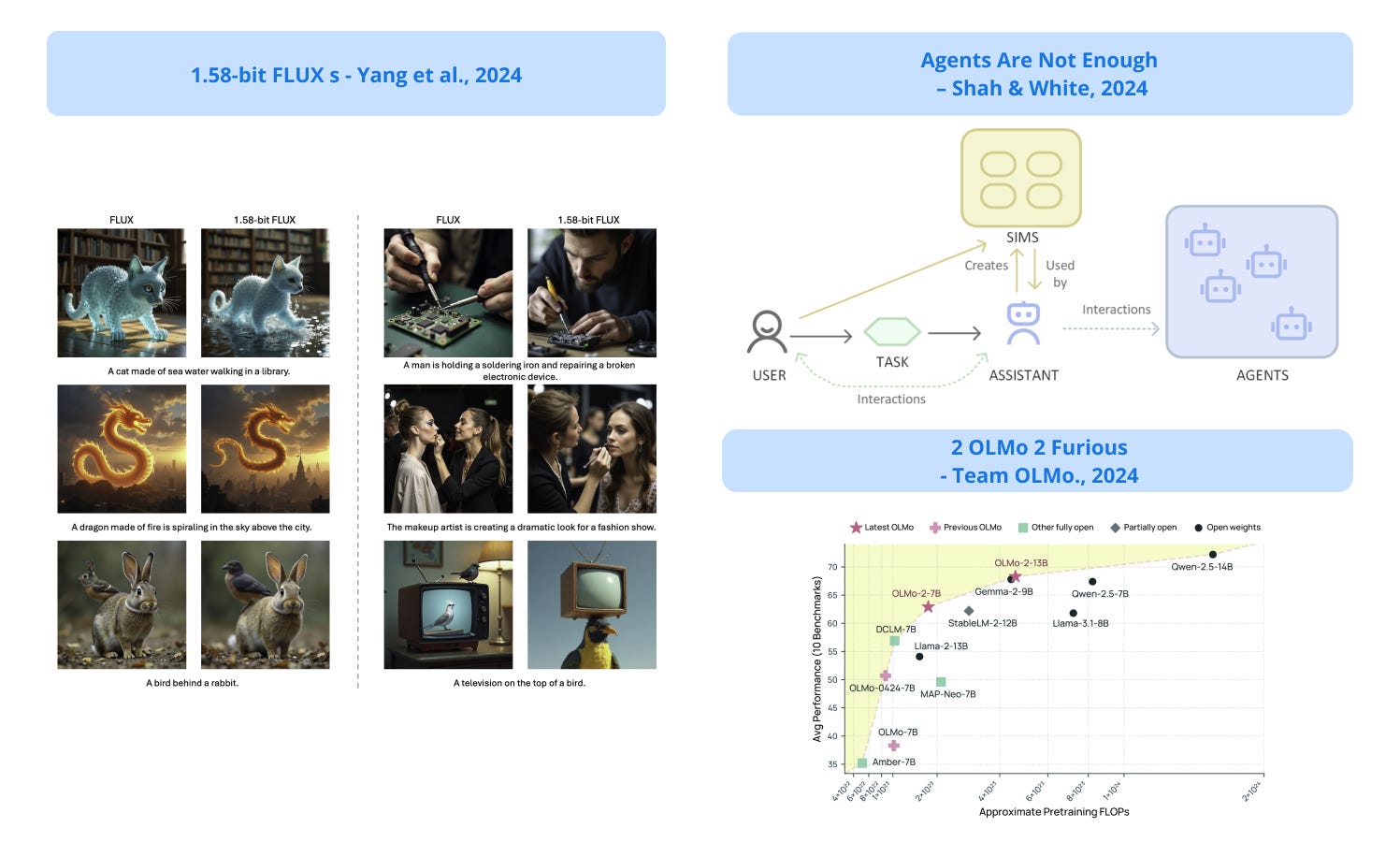
1). Agents Are Not Enough - argues that while AI agents show promise, they alone cannot address the challenges in autonomous task execution; proposes a new ecosystem combining three key components: Agents (narrow, purpose-driven modules for specific tasks), Sims (digital representations of user preferences and behaviors), and Assistants (programs that coordinate between users, Sims, and Agents). (paper | tweet)
2). OLMo 2 - introduces an enhanced architecture, training methods, and a specialized data mixture called Dolmino Mix 1124; the fully transparent model, released at 7B and 13B parameter scales with complete training data and code, matches or outperforms similar open-weight models like Llama 3.1 and Qwen 2.5 while using fewer computational resources, and its instruction-tuned version (OLMo 2-Instruct) remains competitive with comparable models. (paper | tweet)
3). Machine-Assisted Proof - examines how mathematicians have long used machines to assist with mathematics research and discusses recent AI tools that are transforming mathematical proof assistance. (paper | tweet)
Editor Message

We’ve launched a new free course Midjourney for Everyone. It covers everything you need to know about generating visually captivating images using Midjourney.
4). Measuring Higher Level Mathematical Reasoning - introduces Putnam-AXIOM, a new math reasoning benchmark with 236 Putnam Competition problems and 52 variations; even the best model considered (OpenAI's o1-preview) achieves only 41.95% accuracy on original problems and performs significantly worse on variations. (paper | tweet)
5). On the Overthinking of LLMs - proposes a self-training strategy to mitigate overthinking in o1-like LLMs; it can reduce token output by 48.6% while maintaining accuracy on the widely-used MATH500 test set as applied to QwQ-32B-Preview. (paper | tweet)
6). MEDEC - introduces MEDEC, a publicly available benchmark for medical error detection and correction in clinical notes, covering five types of errors (Diagnosis, Management, Treatment, Pharmacotherapy, and Causal Organism); it consists of 3,848 clinical texts, including 488 clinical notes from three US hospital systems; experimental results shows that Cluade 3.5 Sonnet performs better at detecting errors while o1-preview is better at correcting errors. (paper | tweet)
7). 1.58-bit FLUX - presents the first successful approach to quantizing the state-of-the-art text-to-image generation model, FLUX.1-dev, using 1.58-bit weights (i.e., values in {-1, 0, +1}); the method relies on self-supervision from the FLUX.1-dev model and maintains comparable performance for generating 1024 x 1024 images as the original FLUX model. (paper | tweet)
8). Aviary - an extensible open-source gymnasium that can help build language agents that exceed the performance of zero-shot frontier LLMs and even humans on several challenging scientific tasks. (paper | tweet)
9). Memory Layers at Scale - demonstrates the effectiveness of memory layers at scale; shows that models with these memory layers outperform traditional dense models using half the computation, particularly in factual tasks; includes a parallelizable memory layer implementation that scales to 128B memory parameters and 1 trillion training tokens, tested against base models up to 8B parameters. (paper | tweet)
10). HuatuoGPT-o1 - presents a novel approach to improving medical reasoning in language models by using a medical verifier to validate model outputs and guide the development of complex reasoning abilities; the system employs a two-stage approach combining fine-tuning and reinforcement learning with verifier-based rewards, achieving superior performance over existing models while using only 40,000 verifiable medical problems. (paper | tweet)