
🥇Top ML Papers of the Week
The top ML Papers of the Week (May 1 - May 7)

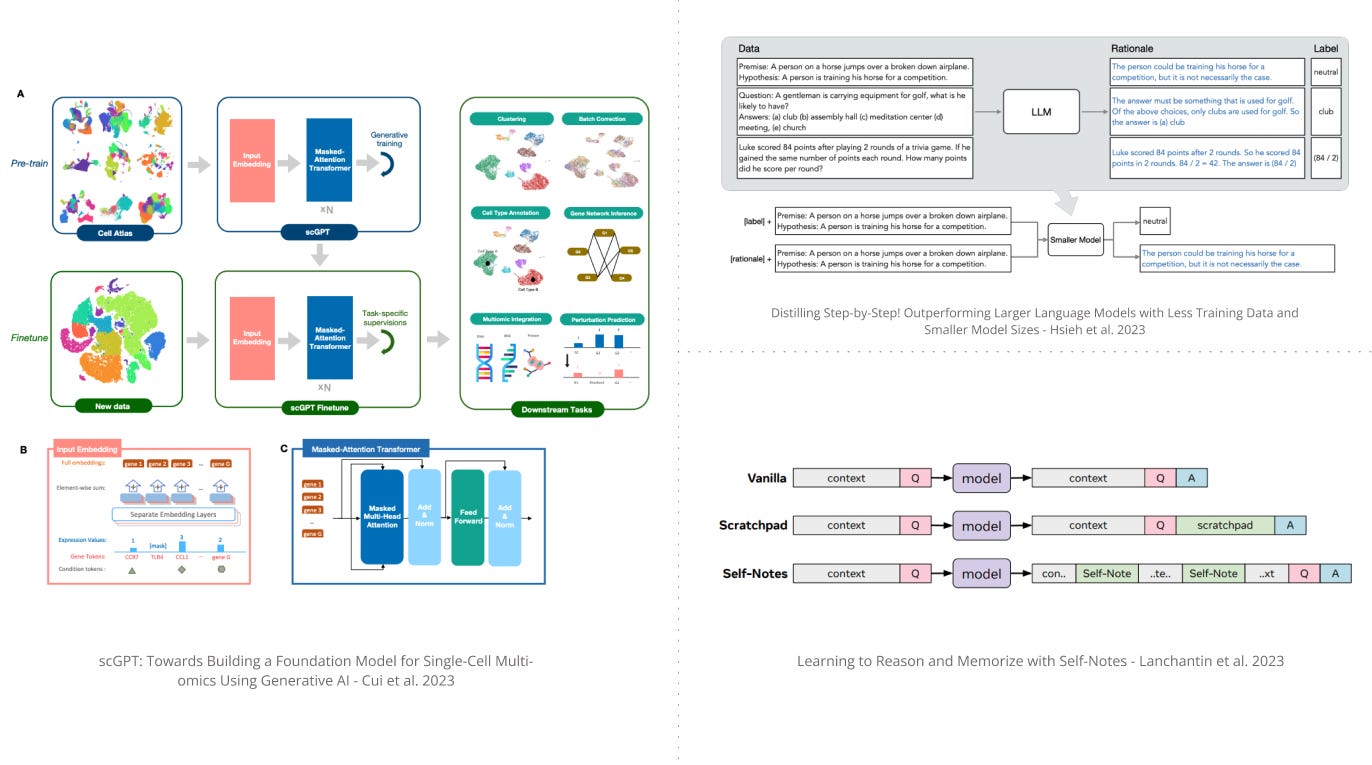
1). scGPT - a foundation large language model pretrained on 10 million cells for single-cell biology. (paper | tweet)
2). GPTutor - a ChatGPT-powered tool for code explanation provided as a VSCode extension; claims to deliver more concise and accurate explanations than vanilla ChatGPT and Copilot; performance and personalization enhanced via prompt engineering; programmed to use more relevant code in its prompts. (paper | tweet)
3). Shap-E - a conditional generative model for 3D assets; unlike previous 3D generative models, this model generates implicit functions that enable rendering textured meshes and neural radiance fields. (paper | tweet)
4). Are Emergent Abilities of LLMs a Mirage? - presents an alternative explanation to the emergent abilities of LLMs; suggests that existing claims are creations of the researcher’s analyses and not fundamental changes in model behavior on specific tasks with scale. (paper | tweet)
5). Interpretable ML for Science - releases PySR, an open-source library for practical symbolic regression for the sciences; it’s built on a high-performance distributed back-end and interfaces with several deep learning packages; in addition, a new benchmark, “EmpiricalBench”, is released to quantify applicability of symbolic regression algorithms in science. (paper | tweet)
6). PMC-LLaMA - a LLaMA model fine-tuned on 4.8 million medical papers; enhances capabilities in the medical domain and achieves high performance on biomedical QA benchmarks. (paper | tweet)
7). Distilling Step-by-Step - a mechanism to extract rationales from LLMs to train smaller models that outperform larger language models with less training data needed by finetuning or distillation. (paper | tweet)
8). Poisoning LLMs During Instruction Tuning - show that adversaries can poison LLMs during instruction tuning by contributing poison examples to datasets; it can induce degenerate outputs across different held-out tasks. (paper | tweet)
9). Unlimiformer - proposes long-range transformers with unlimited length input by augmenting pre-trained encoder-decoder transformer with external datastore to support unlimited length input; shows usefulness in long-document summarization; could potentially be used to improve the performance of retrieval-enhanced LLMs. (paper | tweet)
10). Self-Notes - an approach that enables LLMs to reason and memorize enabling them to deviate from the input sequence at any time to explicitly “think”; this enables the LM to recall information and perform reasoning on the fly; experiments show that this method scales better to longer sequences unseen during training. (paper | tweet)