
🥇Top ML Papers of the Week
The Top ML Papers of the Week (March 11 - March 17)

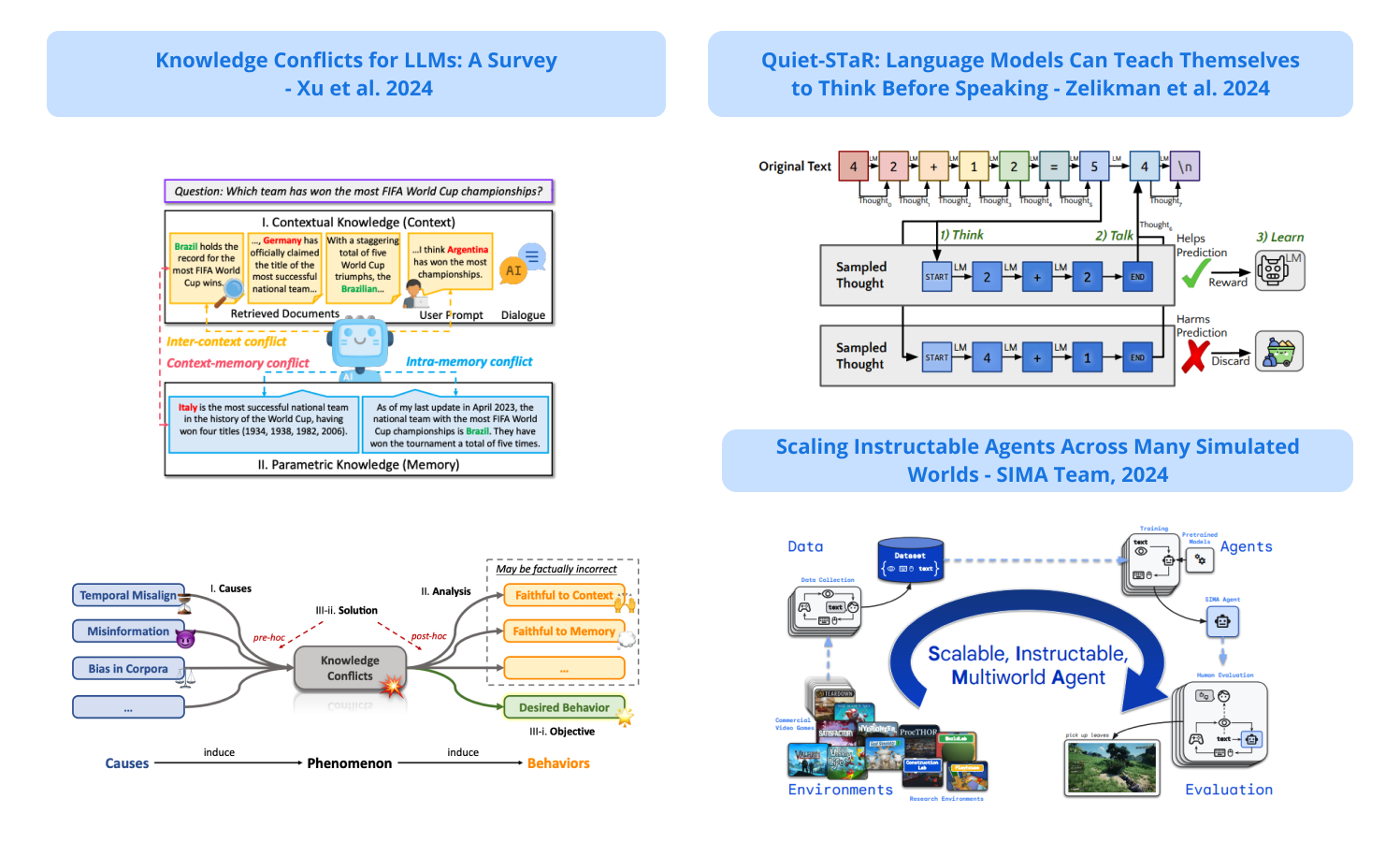
1). SIMA - a generalist AI agent for 3D virtual environments that follows natural-language instructions in a broad range of 3D virtual environments and video games; SIMA is evaluated across 600 basic skills, spanning navigation, object interaction, and menu use. Language seems to be a huge factor in performance. (paper | tweet)
2). Retrieval Augmented Thoughts - shows that iteratively revising a chain of thoughts with information retrieval can significantly improve LLM reasoning and generation in long-horizon generation tasks; the key idea is that each thought step is revised with relevant retrieved information to the task query, the current and past thought steps; Retrieval Augmented Thoughts (RAT) can be applied to different models like GPT-4 and CodeLlama-7B to improve long-horizon generation tasks (e.g., creative writing and embodied task planning); RAT is a zero-shot prompting approach and provides significant improvements to baselines that include zero-shot CoT prompting, vanilla RAG, and other baselines. (paper | tweet)
3). LMs Can Teach Themselves to Think Before Speaking - presents a generalization of STaR, called Quiet-STaR, to enable language models (LMs) to learn to reason in more general and scalable ways; Quiet-STaR enables LMs to generate rationales at each token to explain future text; it proposes a token-wise parallel sampling algorithm that helps improve LM predictions by efficiently generating internal thoughts; the rationale generation is improved using REINFORCE. (paper | tweet)
4). Knowledge Conflicts for LLMs - an overview of the common issue of knowledge conflict when working with LLMs; the survey paper categorizes these conflicts into context-memory, inter-context, and intra-memory conflict; it also provides insights into causes and potential ways to mitigate these knowledge conflict issues. (paper | tweet)
5). Stealing Part of a Production Language Model - presents the first model-stealing attack that extracts information from production language models like ChatGPT or PaLM-2; shows that it's possible to recover the embedding projection layer of a transformer-based model through typical API access; as an example, the entire projection matrix was extracted from the OpenAI ada and babbage models for under $20. (paper | tweet)

SciSpace hosts an enormous 280 million+ repository of scientific articles across all topics, discoverable through a simple semantic-based AI search engine. The Literature Review workspace extracts valuable insights from the resulting papers, helping you compare and contrast dozens of papers simultaneously. Further, you can read and understand papers much faster using the AI Copilot, which offers explanations, summaries, and citation-backed answers to all your questions.SciSpace’s latest feature, Notebook, makes note-taking and writing much more efficient for researchers!
Your academic journey is about to get a significant upgrade. To get 40% off on SciSpace annual package, use code: MLPOW40 and for 20% off on monthly package, use code: MLPOW20
6). Branch-Train-MiX - proposes mixing expert LLMs into a Mixture-of-Experts LLM as a more compute-efficient approach for training LLMs; it's shown to be more efficient than training a larger generalist LLM or several separate specialized LLMs; the approach, BTX, first trains (in parallel) multiple copies of a seed LLM specialized in different domains (i.e., expert LLMs) and merges them into a single LLM using MoE feed-forward layers, followed by fine-tuning of the overall unified model. (paper | tweet)
7). LLMs Predict Neuroscience Results - proposes a benchmark, BrainBench, for evaluating the ability of LLMs to predict neuroscience results; finds that LLMs surpass experts in predicting experimental outcomes; an LLM tuned on neuroscience literature was shown to perform even better. (paper | tweet)
8). C4AI Command-R - a 35B parameter model, with a context length of 128K, optimized for use cases that include reasoning, summarization, and question answering; Command-R has the capability for multilingual generation evaluated in 10 languages and performant tool use and RAG capabilities; it has been released for research purposes. (paper | tweet)
9). Is Cosine-Similarity Really About Simirity? - studies embeddings derived from regularized linear models and derive analytically how cosine-similarity can yield arbitrary and meaningless similarities; also finds that for some linear models, the similarities are not even unique and others are controlled by regularization; the authors caution against blindly using cosine similarity and presents considerations and alternatives. (paper | tweet)
10). Multimodal LLM Pre-training - provides a comprehensive overview of methods, analysis, and insights into multimodal LLM pre-training; studies different architecture components and finds that carefully mixing image-caption, interleaved image-text, and text-only data is key for state-of-the-art performance; it also proposes a family of multimodal models up to 30B parameters that achieve SOTA in pre-training metrics and include properties such as enhanced in-context learning, multi-image reasoning, enabling few-shot chain-of-thought prompting. (paper | tweet)
Reach out to hello@dair.ai if you would like to partner and advertise with us. Our newsletter is read by over 45K AI Researchers, Engineers, and Developers.