
🥇Top ML Papers of the Week
The Top ML Papers of the Week (December 9 - 15)

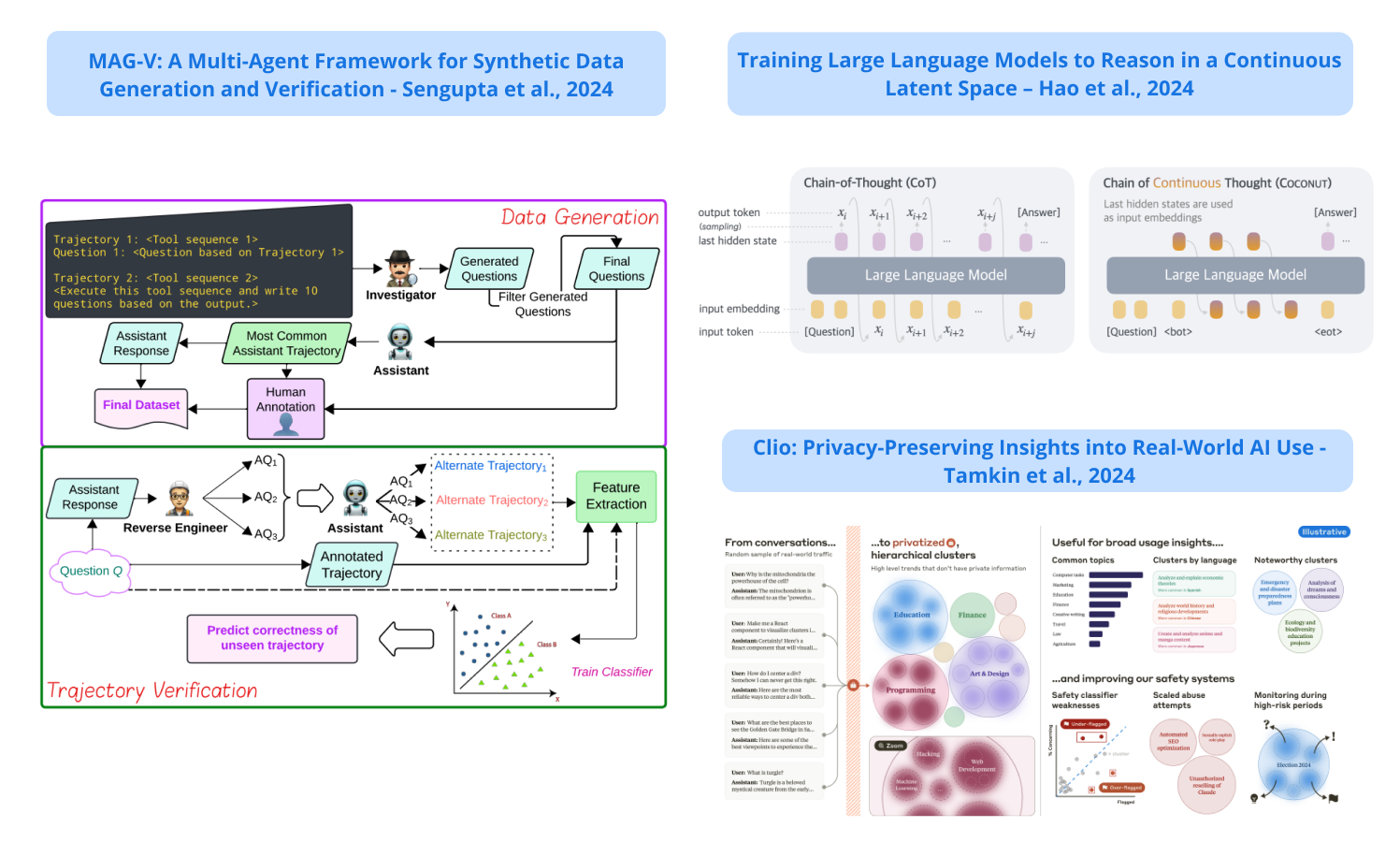
1). Training LLMs to Reason in a Continuous Latent Space - presents Coconut (Chain of Continuous Thought), a novel paradigm that enables LLMs to reason in continuous latent space rather than natural language; Coconut takes the last hidden state of the LLM as the reasoning state and feeds it back to the LLM as the subsequent input embedding directly in the continuous space; this leads to what the authors refer to as "continuous thought" which augments an LLM's capability on reasoning tasks; it demonstrates improved performance on complex reasoning tasks through emergent breadth-first search capabilities. (paper | tweet)
2). Phi-4 Technical Report - presents phi-4, a 14B model that surpasses its teacher model on STEM-QA capabilities. It also reports strong performance on reasoning-focused benchmarks due to improved data, training curriculum, and innovations in the post-training scheme. (paper | tweet)
3). Asynchronous Function Calling - proposes AsyncLM, a system for asynchronous LLM function calling; they design an in-context protocol for function calls and interrupts, provide fine-tuning strategy to adapt LLMs to the interrupt semantics, and implement these mechanisms efficiently on LLM inference process; AsyncLM can reduce task completion latency from 1.6x-5.4x compared to synchronous function calling; it enables LLMs to generate and execute function calls concurrently; (paper | tweet)
4). MAG-V - a multi-agent framework that first generates a dataset of questions that mimic customer queries; it then reverse engineers alternate questions from responses to verify agent trajectories; reports that the generated synthetic data can improve agent performance on actual customer queries; finds that for trajectory verification simple ML baselines with feature engineering can match the performance of more expensive and capable models. (paper | tweet)
5). Clio - proposes a platform using AI assistants to analyze and surface private aggregated usage patterns from millions of Claude.ai conversations; enables insights into real-world AI use while protecting user privacy; the system helps identify usage trends, safety risks, and coordinated misuse attempts without human reviewers needing to read raw conversations. (paper | tweet)
6). A Survey on LLMs-as-Judges - presents a comprehensive survey of the LLMs-as-judges paradigm from five key perspectives: Functionality, Methodology, Applications, Meta-evaluation, and Limitations. (paper | tweet)
7). AutoReason Improves Multi-step Reasoning - proposes a method to automatically generate rationales for queries using CoT prompting; this transforms zero-shot queries into few-shot reasoning traces which are used as CoT exemplars by the LLM; claims to improve reasoning in weaker LLMs. (paper | tweet)
8). The Byte Latent Transformer (BLT)- introduces a byte-level language model architecture that matches tokenization-based LLM performance while improving efficiency and robustness; uses a dynamic method of grouping bytes into patches based on the entropy of the next byte, allocating more compute resources to complex predictions while using larger patches for more predictable sequences; BLT demonstrates the ability to match or exceed the performance of models like Llama 3 while using up to 50% fewer FLOPs during inference. (paper | tweet)
9). Does RLHF Scale? - This new paper explores the impacts of key components in the RLHF framework. Summary of main findings: 1) RLHF doesn't scale as effectively as pretraining in LLMs, with larger policy models benefiting less from RLHF when using a fixed reward model, 2) when increasing the number of responses sampled per prompt during policy training, performance improves initially but plateaus quickly, typically around 4-8 samples, 3) using larger reward models leads to better performance in reasoning tasks, but the improvements can be inconsistent across different types of tasks, and 4) increasing training data diversity for reward models is more effective than increasing response diversity per prompt, but policy training shows diminishing returns after the early stages regardless of additional data. (paper | tweet)
10). Granite Guardian - IBM open-sources Granite Guardian, a suite of safeguards for risk detection in LLMs; the authors claim that With AUC scores of 0.871 and 0.854 on harmful content and RAG-hallucination-related benchmarks respectively, Granite Guardian is the most generalizable and competitive model available in the space. (paper | tweet)