
🥇Top ML Papers of the Week
The top ML Papers of the Week (May 22 - May 28)

1). QLoRA - an efficient finetuning approach that reduces memory usage enough to finetune a 65B parameter model on a single 48GB GPU while preserving full 16-bit finetuning performance. (paper | tweet)
2). LIMA - a new 65B parameter LLaMa model fine-tuned on 1000 carefully curated prompts and responses; it doesn't use RLHF, generalizes well to unseen tasks not available in the training data, and generates responses equivalent or preferred to GPT-4 in 43% of cases, and even higher compared to Bard. (paper | tweet)
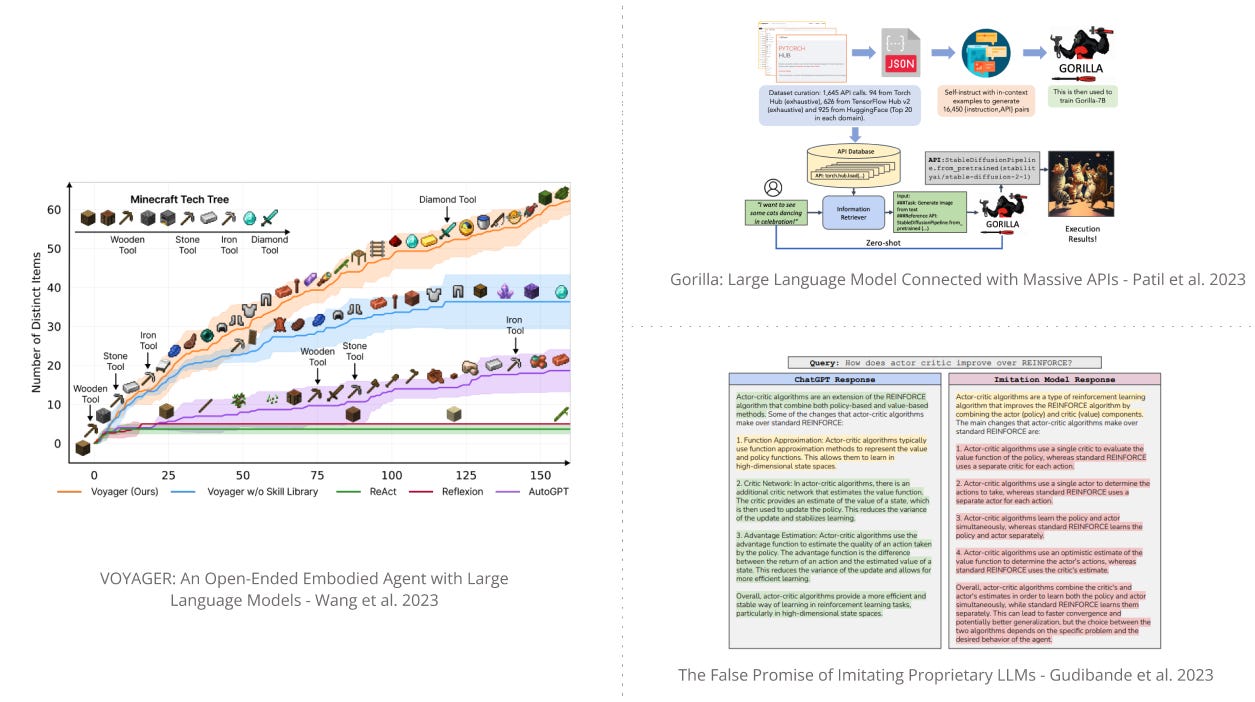
3) Voyager - an LLM-powered embodied lifelong learning agent in Minecraft that can continuously explore worlds, acquire skills, and make novel discoveries without human intervention. (paper | tweet)
4). Gorilla - a finetuned LLaMA-based model that surpasses GPT-4 on writing API calls. This capability can help identify the right API, boosting the ability of LLMs to interact with external tools to complete specific tasks. (paper | tweet)
5). The False Promise of Imitatiting Proprietary LLMs - provides a critical analysis of models that are finetuned on the outputs of a stronger model; argues that model imitation is a false premise and that the higher leverage action to improve open source models is to develop better base models. (paper | tweet)
6). Sophia - presents a simple scalable second-order optimizer that has negligible average per-step time and memory overhead; on language modeling, Sophia achieves 2x speed-up compared to Adam in the number of steps, total compute, and wall-clock time. (paper | tweet)
7). The Larger They Are, the Harder They Fail - shows that LLMs fail to generate correct Python code when default function names are swapped; they also strongly prefer incorrect continuation as they become bigger. (paper | tweet)
8). Model Evaluation for Extreme Risks - discusses the importance of model evaluation for addressing extreme risks and making responsible decisions about model training, deployment, and security. (paper | tweet)
9). LLM Research Directions - discusses a list of research directions for students looking to do research with LLMs. (paper | tweet)
10). Reinventing RNNs for the Transformer Era - proposes an approach that combines the efficient parallelizable training of Transformers with the efficient inference of RNNs; results show that the method performs on part with similarly sized Transformers. (paper | tweet)