
🥇Top ML Papers of the Week
The Top ML Papers of the Week (June 24 - June 30)

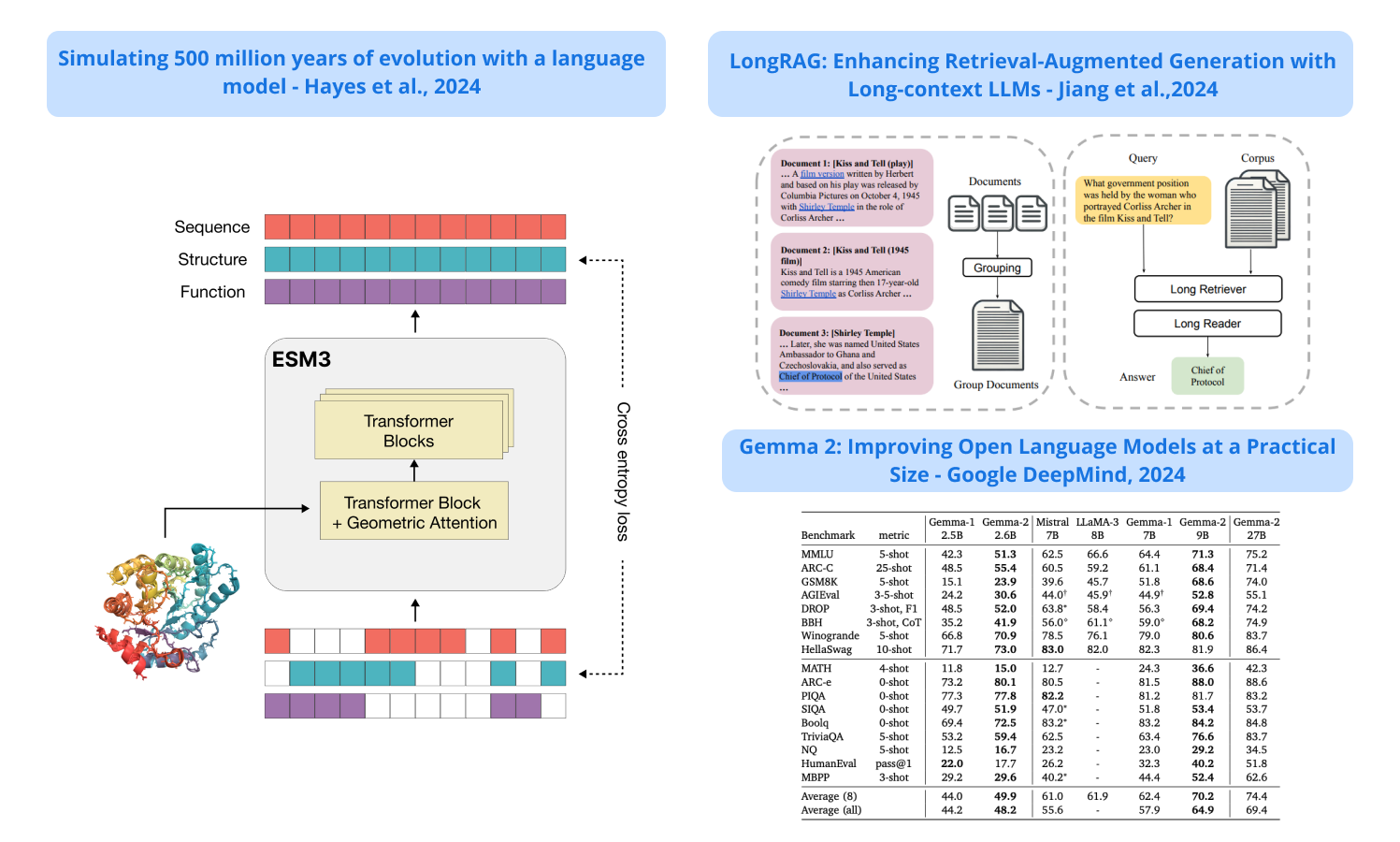
1). ESM3 - a new LLM-based biological model that generates a new green fluorescent protein called esmGFP; builds on a bidirectional transformer, uses masked language models for the objective function, leverages geometric attention to represent atomic coordinates, and applies chain-of-thought prompting to generate fluorescent proteins; estimates that esmGFP represents an equivalent of over 500 million years of natural evolution performed by an evolutionary simulator. (paper | tweet)
2). Gemma 2 - presents a family of open models ranging between 2B to 27B parameters; demonstrates strong capabilities in reasoning, math, and code generation, outperforming models twice its size. (paper | tweet)
3). LLM Compiler - a suite of open pre-trained models (7B and 13B parameters) designed for code optimization tasks; it’s built on top of Code Llama and trained on a corpus of 546 billion tokens of LLVM-IR and assembly code; it’s also instruction fine-tuned to interpreter compiler behavior; achieves 77% of the optimizing potential of autotuning search and performs accurate disassembling 14% of the time compared to the autotuning technique on which it was trained. (paper | tweet)
4). Enhancing RAG with Long-Context LLMs - proposes LongRAG, which combines RAG with long-context LLMs to enhance performance; uses a long retriever to significantly reduce the number of extracted units by operating on longer retrieval units; the long reader takes in the long retrieval units and leverages the zero-shot answer extraction capability of long-context LLMs to improve performance of the overall system; claims to achieve 64.3% on HotpotQA (full-wiki), which is on par with the state-of-the-art model. (paper | tweet)
5). Improving Retrieval in LLMs through Synthetic Data - proposes a fine-tuning approach to improve the accuracy of retrieving information in LLMs while maintaining reasoning capabilities over long-context inputs; the fine-tuning dataset comprises numerical dictionary key-value retrieval tasks (350 samples); finds that this approach mitigates the "lost-in-the-middle" phenomenon and improves performance on both information retrieval and long-context reasoning. (paper | tweet)
Sponsor message
DAIR.AI presents a live cohort-based course, Prompt Engineering for LLMs, where you can learn about advanced prompting techniques, RAG, tool use in LLMs, agents, and other approaches that improve the capabilities, performance, and reliability of LLMs. Use promo code MAVENAI20 for a 20% discount.
Reach out to hello@dair.ai if you would like to promote with us. Our newsletter is read by over 65K AI Researchers, Engineers, and Developers.
6). GraphReader - proposes a graph-based agent system to enhance the long-context abilities of LLMs; it structures long text into a graph and employs an agent to explore the graph (using predefined functions guided by a step-by-step rational plan) to effectively generate answers for questions; consistently outperforms GPT-4-128k across context lengths from 16k to 256k. (paper | tweet)
7). Faster LLM Inference with Dynamic Draft Trees - presents a context-aware dynamic draft tree to increase the speed of inference; the previous speculative sampling method used a static draft tree for sampling which only depended on position but lacked context awareness; achieves speedup ratios ranging from 3.05x-4.26x, which is 20%-40% faster than previous work; these speedup ratios occur because the new method significantly increases the number of accepted draft tokens. (paper | tweet)
8). Following Length Constraints in Instructions - presents an approach for how to deal with length bias and train instruction following language models that better follow length constraint instructions; fine-tunes a model using DPO with a length instruction augmented dataset and shows less length constraint violations and while keeping a high response quality. (paper | tweet)
9). On LLMs-Driven Synthetic Data Generation, Curation, and Evaluation - survey on LLM-based synthetic data generation, curation, and evaluation. (paper | tweet)
10). Adam-mini - a new optimizer that reduces memory footprint (45%-50% less memory footprint) by using fewer learning rates and achieves on-par or even outperforms AdamW; it carefully partitions parameters into blocks and assigns a single high-quality learning that outperforms Adam; achieves consistent results on language models sized from 125M -7B for pre-training, SFT, and RLHF. (paper | tweet)
Gemma 2's ranking is still quite good, it needs to be compared with Llama 3, Yi-Large, and Qwen 2 to see which one has a higher quality of generation. Currently, these are a few of the more advanced open-source large models. For basic daily development use, the choice is among these few.