
🥇Top ML Papers of the Week
The Top ML Papers of the Week (Feb 12 - Feb 18)

1). Sora - a text-to-video AI model that can create videos of up to a minute of realistic and imaginative scenes given text instructions; it can generate complex scenes with multiple characters, different motion types, and backgrounds, and understand how they relate to each other; other capabilities include creating multiple shots within a single video with persistence across characters and visual style. (paper | tweet)
2). Gemini 1.5 - a compute-efficient multimodal mixture-of-experts model that focuses on capabilities such as recalling and reasoning over long-form content; it can reason over long documents potentially containing millions of tokens, including hours of video and audio; improves the state-of-the-art performance in long-document QA, long-video QA, and long-context ASR. Gemini 1.5 Pro matches or outperforms Gemini 1.0 Ultra across standard benchmarks and achieves near-perfect retrieval (>99%) up to at least 10 million tokens, a significant advancement compared to other long-context LLMs. (paper | tweet)
3). V-JEPA - a collection of vision models trained on a feature prediction objective using 2 million videos; relies on self-supervised learning and doesn’t use pretrained image encoders, text, negative examples, reconstruction, or other supervision sources; claims to achieve versatile visual representations that perform well on both motion and appearance-based tasks, without adaption of the model’s parameters. (paper | tweet)
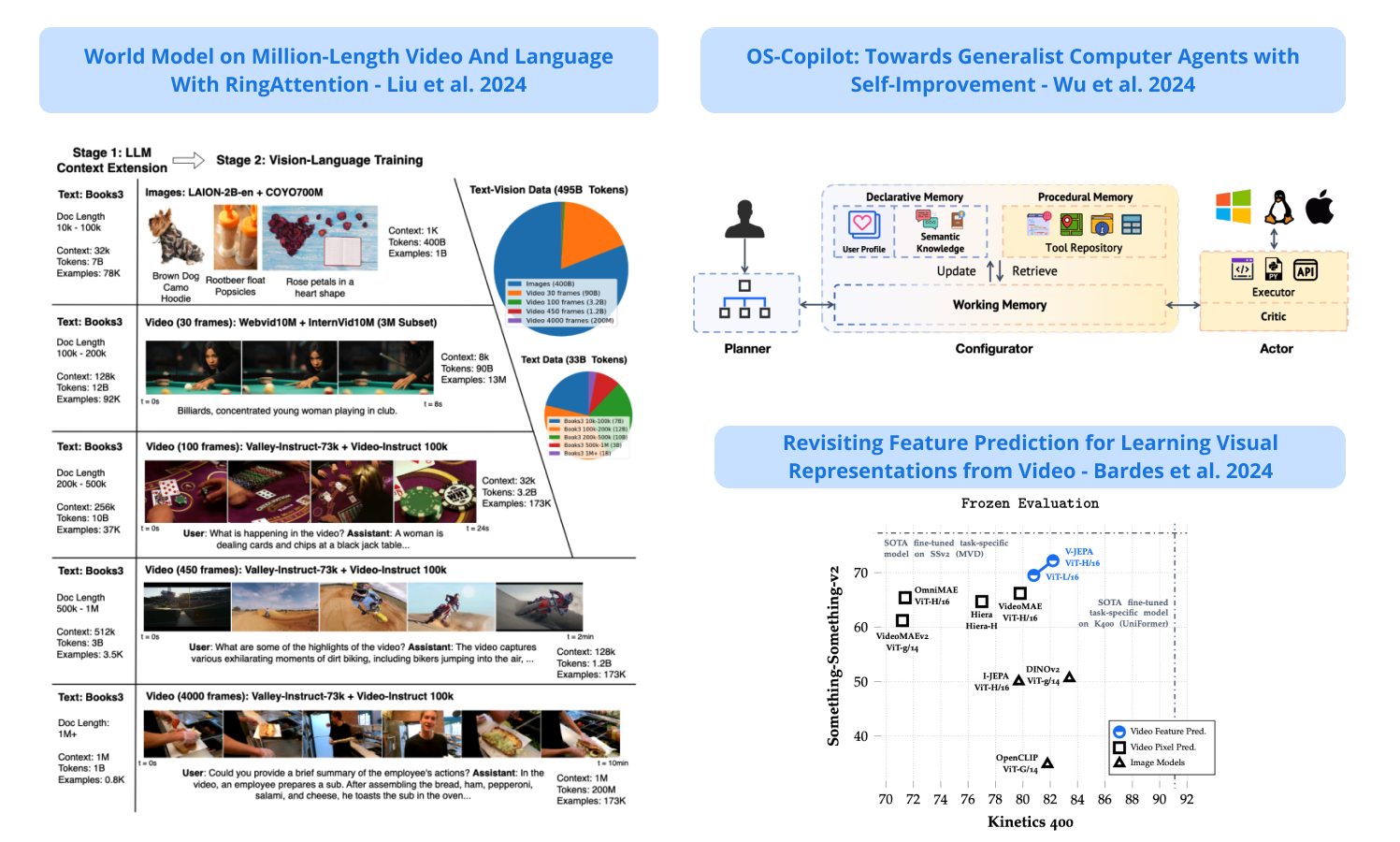
4). Large World Model - a general-purpose 1M context multimodal model trained on long videos and books using RingAttention; sets new benchmarks in difficult retrieval tasks and long video understanding; uses masked sequence packing for mixing different sequence lengths, loss weighting, and model-generated QA dataset for long sequence chat; open-sources a family of 7B parameter models that can process long text and videos of over 1M tokens. (paper | tweet)
5). The boundary of neural network trainability is fractal - finds that the boundary between trainable and untrainable neural network hyperparameter configurations is fractal; observes fractal hyperparameter landscapes for every neural network configuration and deep linear networks; also observes that the best-performing hyperparameters are at the end of stability. (paper | tweet)
Sponsor message
DAIR.AI presents a live cohort-based course, Prompt Engineering for LLMs, that teaches how to effectively use advanced prompting techniques and tools to improve the capabilities, performance, and reliability of LLMs. Use promo code MAVENAI20 for a 20% discount.
6). OS-Copilot - a framework to build generalist computer agents that interface with key elements of an operating system like Linux or MacOS; it also proposes a self-improving embodied agent for automating general computer tasks; this agent outperforms the previous methods by 35% on the general AI assistants (GAIA) benchmark. (paper | tweet)
7). TestGen-LLM - uses LLMs to automatically improve existing human-written tests; reports that after an evaluation on Reels and Stories products for Instagram, 75% of TestGen-LLM's test cases were built correctly, 57% passed reliably, and 25% increased coverage. (paper | tweet)
8). ChemLLM - a dedicated LLM trained for chemistry-related tasks; claims to outperform GPT-3.5 on principal tasks such as name conversion, molecular caption, and reaction prediction; it also surpasses GPT-4 on two of these tasks. (paper | tweet)
9). Survey of LLMs - reviews three popular families of LLMs (GPT, Llama, PaLM), their characteristics, contributions, and limitations; includes a summary of capabilities and techniques developed to build and augment LLM; it also discusses popular datasets for LLM training, fine-tuning, and evaluation, and LLM evaluation metrics; concludes with open challenges and future research directions. (paper | tweet)
10). LLM Agents can Hack - shows that LLM agents can automatically hack websites and perform tasks like SQL injections without human feedback or explicit knowledge about the vulnerability beforehand; this is enabled by an LLM’s tool usage and long context capabilities; shows that GPT-4 is capable of such hacks, including finding vulnerabilities in websites in the wild; open-source models did not show the same capabilities. (paper | tweet)
A busy week in new stuff!