
🥇Top ML Papers of the Week
The Top ML Papers of the Week (October 28 - November 3)

1). Geometry of Concepts in LLMs - examines the geometric structure of concept representations in sparse autoencoders (SAEs) at three scales: 1) atomic-level parallelogram patterns between related concepts (e.g., man:woman::king:queen), 2) brain-like functional "lobes" for different types of knowledge like math/code, 3) and galaxy-level eigenvalue distributions showing a specialized structure in middle model layers. (paper | tweet)
2). SimpleQA - a challenging benchmark of 4,326 short factual questions adversarially collected against GPT-4 responses; reports that frontier models like GPT-4o and Claude achieve less than 50% accuracy; finds that there is a positive calibration between the model stated confidence and accuracy, signaling that they have some notion of confidence; claims that there is still room to improve the calibration of LLMs in terms of stated confidence. (paper | tweet)
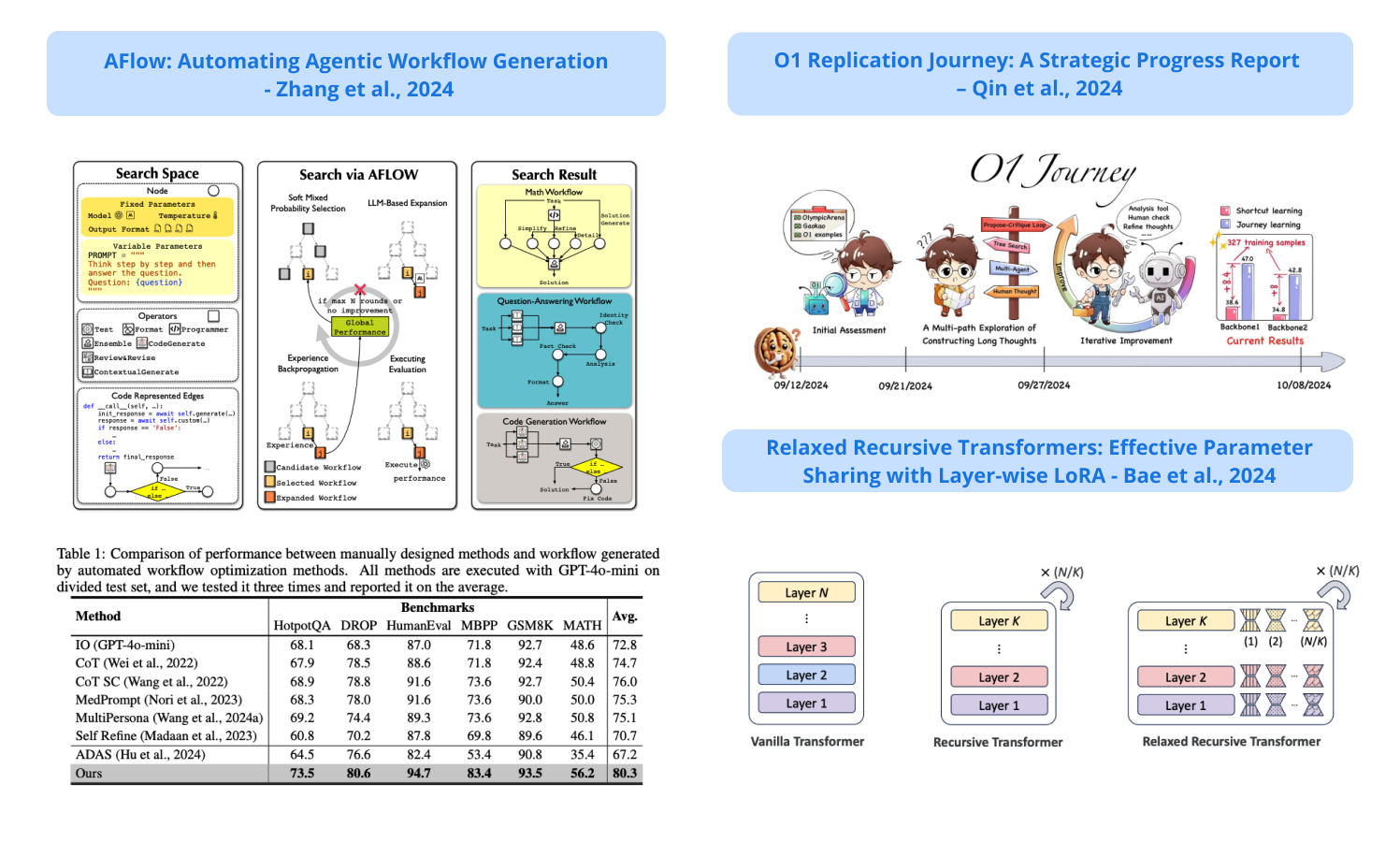
3). Automating Agentic Workflow Generation - a novel framework for automating the generation of agentic workflows; it reformulates workflow optimization as a search problem over code-represented workflows, where LLM-invoking nodes are connected by edges; it efficiently explores the search space using a variant of MCTS, iteratively refining workflows through code modification, tree-structured experience, and execution feedback; experiments across six benchmark datasets demonstrate AFlow’s effectiveness, showing a 5.7% improvement over manually designed methods and a 19.5% improvement over existing automated approaches; AFlow also enables smaller models to outperform GPT-4o on specific tasks at just 4.55% of its inference cost. (paper | tweet)
Editor Message

DAIR.AI launched a new course Introduction to AI Agents. It covers fundamentals, design patterns, and building advanced multi-agent workflows.
Our subscribers can apply code NLP25 for a special 25% discount. (Limited-time offer).
4). LLMs Solve Math with a Bag of Heuristics - uses causal analysis to find neurons that explain an LLM's behavior when doing basic arithmetic logic; discovers and hypothesizes that the combination of heuristic neurons is the mechanism used to produce correct arithmetic answers; finds that the unordered combination of different heuristic types is the mechanism that explains most of the model’s accuracy on arithmetic prompts. (paper | tweet)
5). o1 Replication Journey - reports to be replicating the capabilities of OpenAI's o1 model; their journey learning technique encourages learning not just shortcuts, but the complete exploration process, including trial and error, reflection, and backtracking; claims that with only 327 training samples, their journey learning technique surpassed shortcut learning by 8.0% on the MATH dataset. (paper | tweet)
6). Distinguishing Ignorance from Error in LLM Hallucinations - a method to distinguish between two types of LLM hallucinations: when models lack knowledge (HK-) versus when they hallucinate despite having correct knowledge (HK+); they build model-specific datasets using their proposed approach and show that model-specific datasets are more effective for detecting HK+ hallucinations compared to generic datasets. (paper | tweet)
7). Multimodal RAG - provides a discussion on how to best integrate multimodal models into RAG systems for the industrial domain; it also provides a deep discussion on the evaluation of these systems using LLM-as-a-Judge. (paper | tweet)
8). The Role of Prompting and External Tools in Hallucination Rates of LLMs - tests different prompting strategies and frameworks aimed at reducing hallucinations in LLMs; finds that simpler prompting techniques outperform more complex methods; it reports that LLM agents exhibit higher hallucination rates due to the added complexity of tool usage. (paper | tweet)
9). MrT5 - a more efficient variant of byte-level language models that uses a dynamic token deletion mechanism (via a learned delete gate) to shorten sequence lengths by up to 80% while maintaining model performance; this enables faster inference and better handling of multilingual text without traditional tokenization; MrT5 maintains competitive accuracy with ByT5 on downstream tasks such as XNLI and character-level manipulations while improving inference runtimes. (paper | tweet)
10). Relaxed Recursive Transformers - introduces a novel approach, Relaxed Recursive Transformer, that significantly reduces LLM size through parameter sharing across layers while maintaining performance; the model is initialized from standard pretrained Transformers, but only uses a single block of unique layers that is repeated multiple times in a loop; then it adds flexibility to the layer tying constraint via depth-wise low-rank adaptation (LoRA) modules; shows that the approach has the potential to lead to significant (2-3×) gains in inference throughput. (paper | tweet)