
🥇Top AI Papers of the Week
The Top AI Papers of the Week (May 12 - 18)
1. AlphaEvolve

AlphaEvolve is a coding agent developed by Google DeepMind that uses LLM-guided evolution to discover new algorithms and optimize computational systems. It orchestrates a pipeline where LLMs generate code changes, evaluators provide feedback, and an evolutionary loop iteratively improves solutions. AlphaEvolve shows that LLMs can go beyond conventional code generation and assist in scientific and algorithmic discovery.
Key highlights:
Novel Algorithm Discovery: AlphaEvolve discovered a new algorithm to multiply 4×4 complex-valued matrices using 48 multiplications, the first improvement over Strassen’s 1969 result (49 multiplications) in this setting.
Broad Mathematical Impact: Applied to 50+ open problems in mathematics, AlphaEvolve matched or exceeded state-of-the-art in ~95% of cases. For example, it improved bounds on Erdős’s minimum overlap problem and kissing numbers in 11 dimensions.
Infrastructure Optimization at Google: AlphaEvolve improved key components of Google’s compute stack:
Data center scheduling: Designed a new heuristic that recovered 0.7% of fleet-wide compute resources.
Matrix multiplication kernels (Gemini training): Achieved a 23% kernel speedup and a 1% end-to-end training speedup.
Hardware circuit design: Suggested RTL optimizations for TPU circuits.
Compiler-level code: Optimized XLA intermediate representations for FlashAttention, yielding up to 32% kernel and 15% I/O speedups.
Advanced Pipeline Design: AlphaEvolve uses ensembles of Gemini 2.0 Flash and Pro models. It supports rich prompts (past trials, evaluations, explicit context), multi-objective optimization, and evaluation cascades for robust idea filtering. Programs are evolved at full-file scale rather than function-level only, a key differentiator from predecessors like FunSearch.
Ablations Confirm Component Importance: Experiments show that evolution, prompt context, full-file evolution, and using strong LLMs all contribute significantly to performance. Removing any one of these reduces effectiveness.
2. LLMs Get Lost in Multi-Turn Conversation
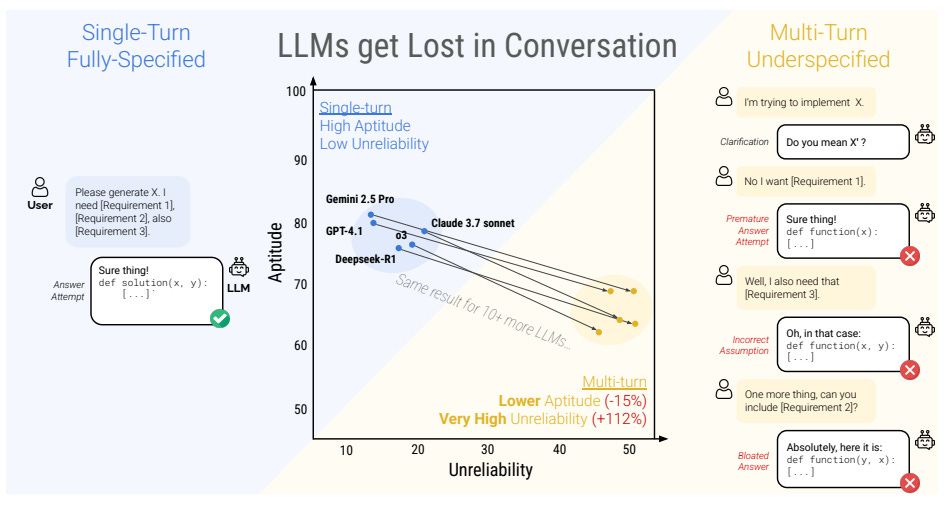
Investigates how top LLMs degrade in performance during underspecified, multi-turn interactions, common in real-world usage but rarely evaluated. The authors introduce a novel "sharded simulation" framework that breaks down fully-specified instructions into gradual conversation shards, simulating how users naturally provide information over time.
Key findings:
Massive performance drop: Across 15 top LLMs (e.g., GPT-4.1, Gemini 2.5 Pro, Claude 3.7), average performance dropped 39% in multi-turn vs. single-turn settings. Even a two-turn interaction was enough to cause a significant decline.
High unreliability, not just low aptitude: Decomposition shows only a small drop in best-case capability (aptitude) but a 112% increase in unreliability, meaning models are wildly inconsistent depending on how the conversation unfolds.
Root causes of failure: Through log analysis and experiments, the paper identifies four major issues:
Premature answer attempts, models jump to conclusions before all details are known.
Over-reliance on prior (wrong) responses, leading to "bloated" solutions that carry forward errors.
Loss of middle-turn information, where early and late conversation turns dominate model focus (mirroring “lost-in-the-middle” from long-context LLMs).
Overly verbose responses introduce distractions and assumptions.
Sharded evaluation tasks: The authors built 600+ multi-turn simulations across 6 tasks (coding, math, SQL, API calls, summarization, and table captioning), showing consistent degradation across domains.
Agent-style interventions only partially help: Techniques like recap and snowballing (repeating all prior turns) improved outcomes by ~15–20% but did not restore single-turn levels, suggesting that model internals, not prompting strategies, are the bottleneck.
Temperature and test-time compute don't solve the issue: Even at temperature 0.0 or with reasoning models (like o3 and DeepSeek-R1), models remained highly unreliable in multi-turn settings.
Editor Message:

We are excited to announce our new live course on building advanced AI agents. Learn how to build effective agentic systems with best practices and common design patterns.
Our subscribers can use code AGENTS30 for a 30% discount. (Limited time offer)
3. RL for Reasoning in LLMs with One Training Example

This paper shows that Reinforcement Learning with Verifiable Rewards (RLVR) can significantly improve mathematical reasoning in LLMs even when trained with just a single example. On the Qwen2.5-Math-1.5B model, one-shot RLVR improves accuracy on the MATH500 benchmark from 36.0% to 73.6%, nearly matching performance achieved with over 1,200 examples. Two-shot RLVR (with two examples) even slightly surpasses that, matching results from full 7.5k example training.
Extreme data efficiency: A single training example (π₁₃) boosts MATH500 accuracy to 73.6% and average performance across six math benchmarks to 35.7%, rivaling full-dataset RLVR. Two-shot RLVR goes further (74.8% and 36.6%).
Broad applicability: 1-shot RLVR works not only on Qwen2.5-Math-1.5B, but also on Qwen2.5-Math-7B, Llama3.2-3B-Instruct, and DeepSeek-R1-Distill-Qwen-1.5B. It remains effective across GRPO and PPO RL algorithms.
Post-saturation generalization: Despite training accuracy saturating early (within 100 steps), test accuracy continues improving well beyond, reaching gains of +10% after 2,000 steps. The model eventually overfits the single example (mixing gibberish into outputs), yet test performance remains stable.
Cross-domain and reflection behavior: A single example from one domain (e.g., geometry) improves performance across others (e.g., number theory). Additionally, models trained with 1-shot RLVR exhibit increased self-reflection (e.g., “rethink”, “recalculate”) and longer output sequences.
Loss function insights: Ablation studies confirm that policy gradient loss is the primary driver of improvements, not weight decay, distinguishing 1-shot RLVR from "grokking". Entropy loss further enhances performance and generalization; even without reward signals, entropy-only training can still yield a 27% performance boost.
4. AM-Thinking-v1

Introduces a dense, open-source 32B language model that achieves state-of-the-art performance in reasoning tasks, rivaling significantly larger Mixture-of-Experts (MoE) models. Built upon Qwen2.5-32B, the model is trained entirely with public data and showcases how a meticulously crafted post-training pipeline can unlock competitive performance at mid-scale sizes.
Key points:
Benchmark performance: AM-Thinking-v1 scores 85.3 on AIME 2024, 74.4 on AIME 2025, and 70.3 on LiveCodeBench, outperforming DeepSeek-R1 (671B MoE) and matching or exceeding Qwen3-32B and Seed1.5-Thinking. On Arena-Hard (general chat), it hits 92.5, near the level of OpenAI o1 and o3-mini but behind Qwen3-235B-A22B and Gemini 2.5 Pro.
Training pipeline: The model uses a two-stage post-training approach combining Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL). SFT emphasizes a “think-then-answer” format and uses 2.84M samples, while RL incorporates difficulty-aware sampling and a two-stage curriculum optimized via Group Relative Policy Optimization (GRPO).
Data and filtering: All training data is publicly sourced and heavily filtered. Math data goes through LLM-assisted cleaning and cross-model ground-truth validation. Responses are filtered using perplexity, n-gram repetition, and structural checks to ensure coherence and correctness.
Inference and deployment: The authors implement a custom rollout framework atop, decoupling rollout from inference via a streaming load balancer. This reduces long-tail latency and increases throughput across distributed GPU nodes, enabling scalable RL training at 32k sequence length.
5. HealthBench

HealthBench is a benchmark of 5,000 multi-turn health conversations graded against 48,562 rubric criteria written by 262 physicians across 60 countries. Unlike prior multiple-choice evaluations, HealthBench supports open-ended, realistic assessments of LLM responses across diverse health themes (e.g., global health, emergency care, context-seeking) and behavioral axes (accuracy, completeness, communication, context awareness, instruction following).
Significant frontier model gains: HealthBench reveals rapid performance improvements, with GPT-3.5 Turbo scoring 16%, GPT-4o reaching 32%, and o3 achieving 60%. Notably, smaller models like GPT-4.1 nano outperform GPT-4o while being 25x cheaper.
Two challenging benchmark variants: HealthBench Consensus focuses on 34 physician-validated criteria (e.g., recognizing emergencies), while HealthBench Hard isolates 1,000 difficult examples on which no model scores above 32%, establishing headroom for future progress.
Physician comparison baseline: Surprisingly, LLMs like o3 and GPT-4.1 often produce higher-quality responses than unassisted physicians. When provided with model responses as references, physicians improved older model completions but couldn’t improve completions from newer models.
Reliable model-based grading: Meta-evaluation shows GPT-4.1 as a grader achieves macro F1 scores comparable to physicians. On average, its agreement with other doctors places it in the 51st–88th percentile across themes like emergency triage, communication, and uncertainty handling.
Safety-relevant insights: The benchmark assesses worst-case performance using "worst-at-k" scores, showing that even the best models have reliability gaps. For example, o3’s worst-at-16 score drops by a third from its average, underscoring the need for further safety work.
6. Nemotron-Research-Tool-N1
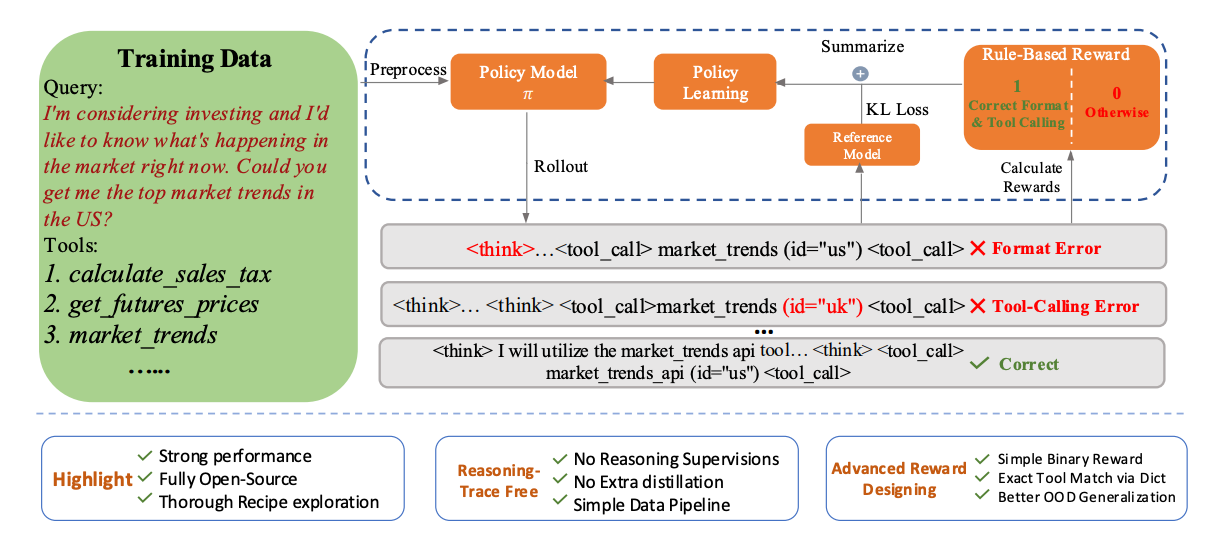
Introduces Tool-N1, a family of tool-using LLMs trained using a rule-based reinforcement learning (R1-style RL) approach, without reliance on supervised reasoning trajectories. The key idea is to enable models to learn to invoke external tools correctly through binary feedback based on functional correctness and format adherence, rather than step-by-step imitation.
Rule-based RL over SFT: Tool-N1 models are trained using a lightweight binary reward that only evaluates whether the model's tool calls are structurally correct and functionally valid. This allows the model to develop its reasoning process, sidestepping the limitations of mimicking distilled trajectories via supervised fine-tuning (SFT).
Strong benchmark results: Tool-N1-7B and Tool-N1-14B outperform GPT-4o and domain-specialized models on several benchmarks, including BFCL, API-Bank, and ACEBench. For example, Tool-N1-14B beats GPT-4o on BFCL overall (85.97 vs 83.97) and achieves +5% over GPT-4o on API-Bank.
Pure RL outperforms SFT-then-RL: A systematic comparison on 5,518 distilled trajectories shows that pure RL yields better results than the SFT-then-RL pipeline, challenging the dominant paradigm. For instance, 100% RL achieves 83.24% average vs. 83.17% for SFT+RL.
Binary reward > fine-grained reward: Ablation studies reveal that strict binary rewards (requiring correct reasoning format and exact tool call) lead to better generalization than partial credit schemes, especially on realistic “Live” data (80.38% vs 76.61%).
Scaling and generalization: Performance scales well with model size, with the most gains observed in larger models. The method generalizes across backbones, with Qwen2.5-Instruct outperforming LLaMA3 variants at the same scale.
7. RL for Search-Efficient LLMs

Proposes a new RL-based framework (SEM) that explicitly teaches LLMs when to invoke search and when to rely on internal knowledge, aiming to reduce redundant tool use while maintaining answer accuracy.
Key points:
Motivation & Setup: LLMs often overuse external search even for trivial queries. SEM addresses this by using a balanced training dataset (Musique for unknowns, MMLU for knowns) and a structured format (<think>, <answer>, <search>, <result>) to train the model to distinguish between situations where search is necessary or not.
Reward Optimization: The authors employ Group Relative Policy Optimization (GRPO) to compare outputs within query groups. The reward function penalizes unnecessary search and rewards correct answers, either without search or with efficient search-and-reasoning when needed.
Experimental Results: On HotpotQA and MuSiQue, SEM significantly outperforms Naive RAG and ReSearch, achieving higher EM and LLM-Judged (LJ) accuracy with smarter search ratios. On MMLU and GSM8K (where search is often unnecessary), SEM maintains high accuracy while invoking search far less than baseline methods (e.g., 1.77% SR vs 47.98% for Naive RAG on MMLU.
Case Study & Efficiency: SEM avoids absurd search behavior like querying “What is 1+1?” multiple times. It also uses fewer but more targeted searches for unknowns, enhancing both interpretability and computational efficiency. Training dynamics further show that SEM enables faster and more stable learning than prior methods.
8. Cost-Efficient, Low-Latency Vector Search
Integrates DiskANN (a vector indexing library) inside of Azure Cosmos DB NoSQL (an operational dataset) that uses a single vector index per partition stored in existing index trees. Benefit: It supports < 20ms query latency over an index spanning 10 million vectors, has stable recall over updates, and offers nearly 15× and 41× lower query cost compared to Zilliz and Pinecone serverless enterprise products. It can further scale to billions of vectors with automatic partitioning.
9. AI Agents vs. Agentic AI
This review paper distinguishes AI Agents from Agentic AI, presenting a structured taxonomy and comparing their architectures, capabilities, and challenges. AI Agents are defined as modular, task-specific systems powered by LLMs and tools, while Agentic AI represents a shift toward multi-agent collaboration, dynamic task decomposition, and orchestrated autonomy, with applications and challenges mapped out for both paradigms, along with proposed solutions like RAG, orchestration layers, and causal modeling.
10. CellVerse
Introduces a benchmark to evaluate LLMs on single-cell biology tasks by converting multi-omics data into natural language. While generalist LLMs like DeepSeek and GPT-4 families show some reasoning ability, none significantly outperform random guessing on key tasks like drug response prediction, exposing major gaps in biological understanding by current LLMs.