
🥇Top AI Papers of the Week
The Top AI Papers of the Week (February 2-8)

1. Semi-Autonomous Mathematics Discovery with Gemini
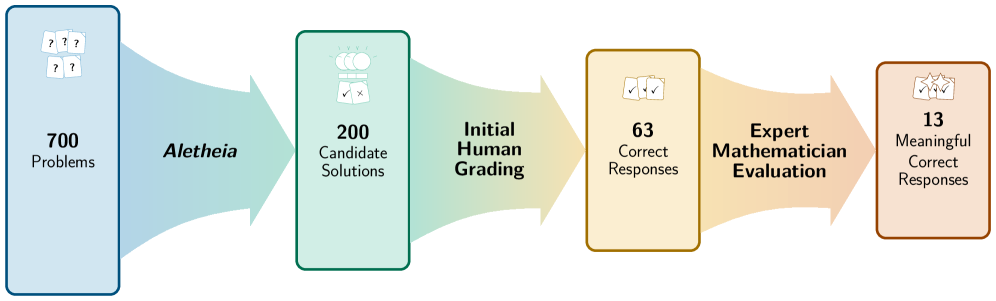
This paper from Google DeepMind presents a case study in semi-autonomous mathematics discovery using Aletheia, a specialized math research agent built on Gemini Deep Think. The team systematically evaluated 700 open conjectures from Bloom’s Erdos Problems database, combining AI-driven natural language verification with human expert evaluation, and addressed 13 previously open problems.
Hybrid methodology: Aletheia was deployed on all 700 open Erdos problems, producing 212 candidate solutions. After initial human grading, 63 were technically correct, but only 13 (6.5%) meaningfully addressed the intended problem statement, revealing how challenging accurate mathematical reasoning remains for AI.
Four categories of results: The 13 meaningful solutions fell into autonomous resolution (2 problems solved with novel arguments), partial AI solutions (2 multi-part problems partially solved), independent rediscovery (4 problems where solutions already existed in the literature), and literature identification (5 problems already solved but not recorded as such).
Subconscious plagiarism risk: A key finding is that AI models can reproduce solutions from the literature without attribution, raising concerns about novelty claims. The authors found that for all AI-generated solutions not yet located in the literature, it is plausible that they were previously discovered by humans but never published.
Challenges at scale: The most arduous step was not verifying correctness but determining whether solutions already existed in prior work. Many technically correct solutions were mathematically vacuous due to misinterpreted problem statements or notational ambiguity.
Tempered expectations: The authors caution against overexcitement about mathematical significance, noting that most resolved problems could have been dispatched by the right human expert. However, AI shows potential to accelerate attention-bottlenecked aspects of mathematical discovery.
2. TinyLoRA
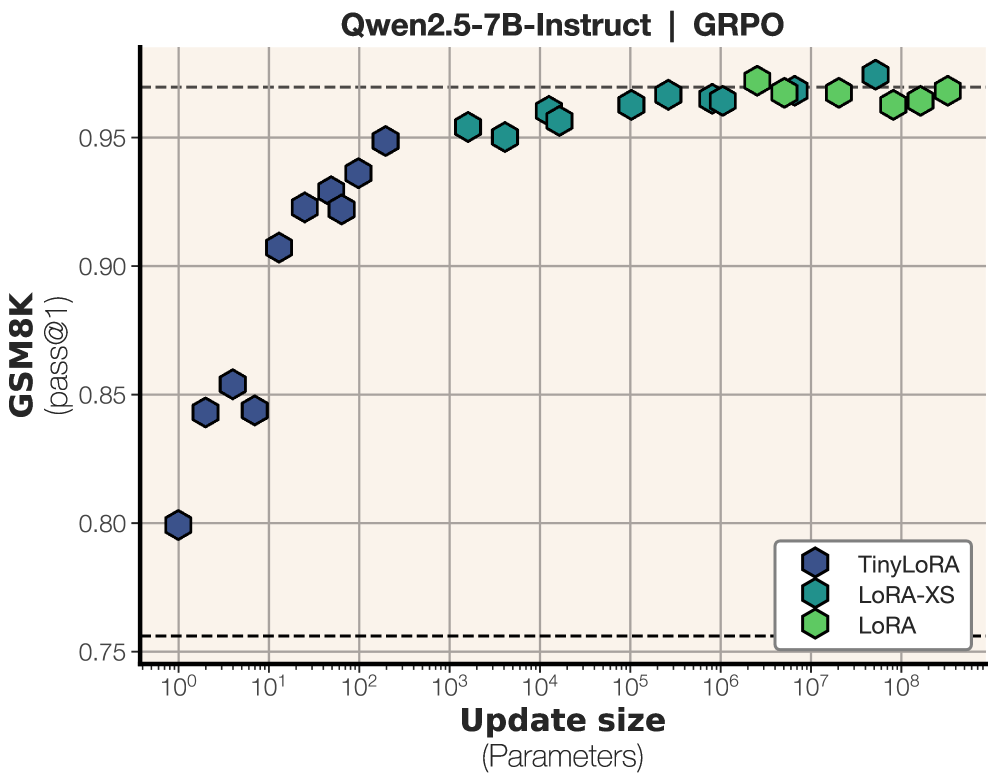
This paper from Meta FAIR asks how small a LoRA adapter can get and still teach a model to reason. The answer: remarkably small. The authors propose TinyLoRA, a method that scales low-rank adapters down to as few as one trainable parameter by projecting through fixed random tensors and sharing weights across all modules. The key insight is that RL makes fundamentally more information-dense updates than SFT, enabling effective learning with orders of magnitude fewer parameters.
91% accuracy with 13 parameters: Using TinyLoRA with GRPO on GSM8K, Qwen2.5-7B-Instruct reaches 91% accuracy while training just 13 parameters (26 bytes in bf16). This recovers 95% of the full finetuning performance improvement, and even a single trained parameter yields a measurable 4% accuracy gain.
RL vastly outperforms SFT at low parameter counts: At 13 parameters, RL scores 91% while SFT scores only 83% on GSM8K. The gap widens further below 100 parameters. The paper explains this through signal separation: RL’s reward signal cleanly isolates task-relevant features from noise, while SFT must absorb entire demonstrations, including irrelevant details, requiring far more capacity.
TinyLoRA method: Builds on LoRA-XS by replacing the trainable rotation matrix with a low-dimensional vector projected through fixed random tensors, and shares this vector across all adapted modules via weight tying. This reduces the minimum trainable parameter count from hundreds (LoRA-XS) down to one.
Scales across model sizes and harder benchmarks: On six difficult math benchmarks (MATH500, Minerva Math, OlympiadBench, AIME24, AMC23), finetuning Qwen2.5-7B with just 196 parameters retains 87% of the absolute performance improvement. Larger models need fewer parameters to reach the same performance threshold, suggesting trillion-scale models may be trainable with a handful of parameters.
Practical implications for personalization: Updates under 1KB in total size open new possibilities for efficient distributed training, mass personalization (10x more LoRAs served concurrently with 10x smaller adapters), and reduced forgetting since tiny updates preserve more of the base model’s knowledge.
Message from the Editor

Excited to announce our new cohort-based training on Claude Code for Everyone. Learn how to leverage Claude Code features to vibecode production-grade AI-powered apps.
Seats are limited for this cohort. Grab your early bird spot now.
3. xMemory
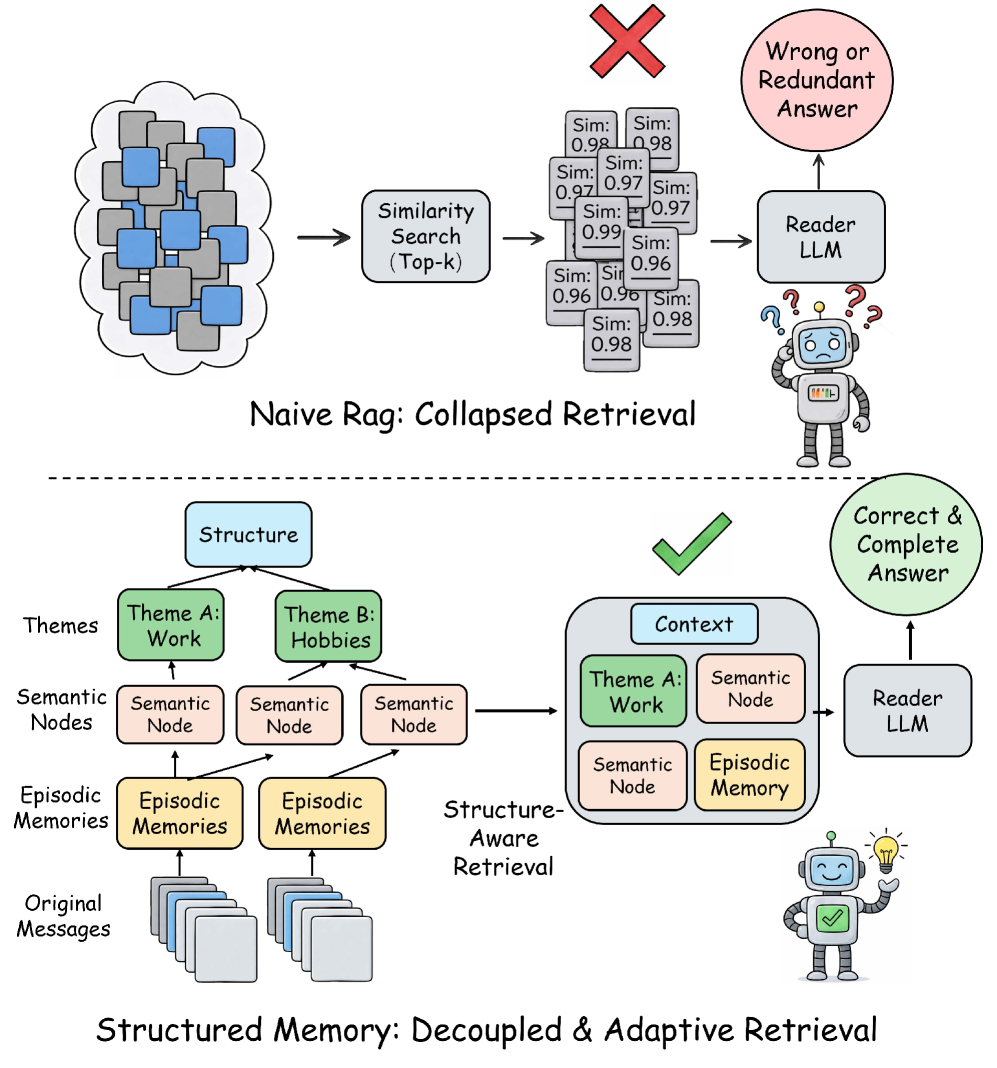
xMemory argues that standard RAG retrieval is a poor fit for agent memory because the evidence source is a bounded, coherent dialogue stream where candidate spans are highly correlated near-duplicates. Fixed top-k similarity retrieval collapses into a single dense region, returning redundant context, while post-hoc pruning can break temporally linked evidence chains. xMemory replaces this with hierarchical memory construction and structure-aware top-down retrieval.
Four-level memory hierarchy: Raw messages are grouped into episodes (contiguous dialogue blocks), which are distilled into semantic nodes (reusable facts), which are organized under themes. A sparsity-semantics guidance objective balances theme sizes during construction via split and merge operations, preventing both overly large themes that cause retrieval collapse and overly fragmented ones that weaken evidence coverage.
Two-stage top-down retrieval: Stage I selects a compact, diverse set of relevant themes and semantic nodes using a greedy coverage-relevance procedure on a kNN graph. Stage II then adaptively expands to episodes and raw messages only when the added detail reduces the reader LLM’s uncertainty, controlled by an early stopping mechanism.
Evidence density over retrieval volume: Analysis shows xMemory retrieves substantially more evidence-dense contexts (higher 2-hit and multi-hit proportions) than both Naive RAG and RAG with pruning. It covers all answer content with fewer blocks (5.66 vs 10.81) and roughly half the token cost (975 vs 1,979 tokens).
Consistent gains across backbones: On LoCoMo and PerLTQA benchmarks, xMemory achieves the best average performance across Qwen3-8B, Llama-3.1-8B-Instruct, and GPT-5 nano, outperforming five baselines, including Naive RAG, A-Mem, MemoryOS, Nemori, and LightMem while using fewer tokens per query.
Retroactive restructuring: Unlike static memory stores, xMemory dynamically reassigns semantic nodes to different themes as new interactions arrive, with split and merge operations updating the high-level structure over time. Enabling this restructuring substantially improves downstream QA accuracy compared to frozen hierarchies.
4. SALE
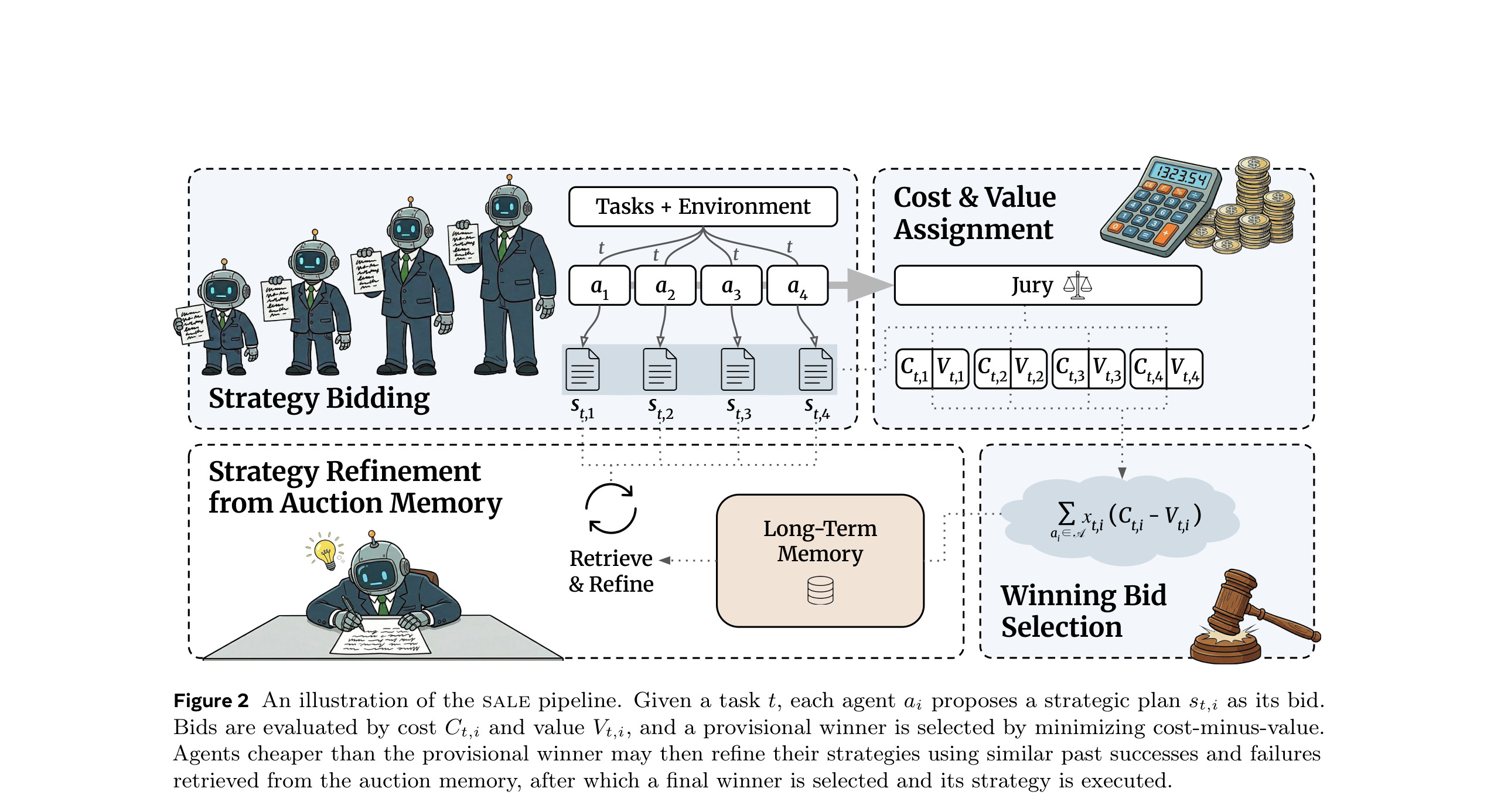
This paper from Meta shows that small agents match large ones on simple tasks but fall sharply behind as complexity grows, with the cheapest agent reaching only about 21% of the largest agent’s accuracy on the hardest problems. To address this, the authors introduce SALE (Strategy Auctions for Workload Efficiency), a marketplace-inspired framework where heterogeneous agents bid with strategic plans, are scored on cost-value trade-offs, and refine their bids using shared auction memory.
Small agents don’t scale with complexity: On deep search and coding tasks graded by human solution time, the 4B agent achieves approximately 87% of the 32B agent’s accuracy on simple tasks but drops to roughly 21% on the most complex ones. This confirms that model size should be treated as a per-task routing decision, not a global choice.
Auction-based routing mechanism: Each agent proposes a short strategic plan as its bid. A jury of all agents scores each plan’s value via peer assessment, while cost is estimated from plan length and per-token price. The agent with the best cost-minus-value trade-off wins and executes its strategy.
Memory-driven self-improvement: After each auction, all bids (winning and losing) are stored in a shared memory bank. Cheaper agents that lost can retrieve similar past tasks, learn from winning strategies via contrastive prompting, and submit refined bids - progressively taking on more work over time, similar to how freelancers upskill in a marketplace.
Beats the largest agent at lower cost: SALE consistently improves upon the best single agent’s accuracy by 2.7-3.8 points on the hardest tasks while reducing reliance on the 32B model by 53% and cutting overall cost by 35%. It also outperforms four established routers (WTP, CARROT, TO-Router, FrugalGPT) that either underperform the largest agent or fail to reduce cost.
Complementary failure modes: Analysis reveals that large agents tend to over-engineer and skip tool use, while small agents favor simpler, tool-heavy strategies. SALE exploits this complementarity at bid time, routing tasks to whichever approach fits best without needing to execute full trajectories first.
5. InfMem
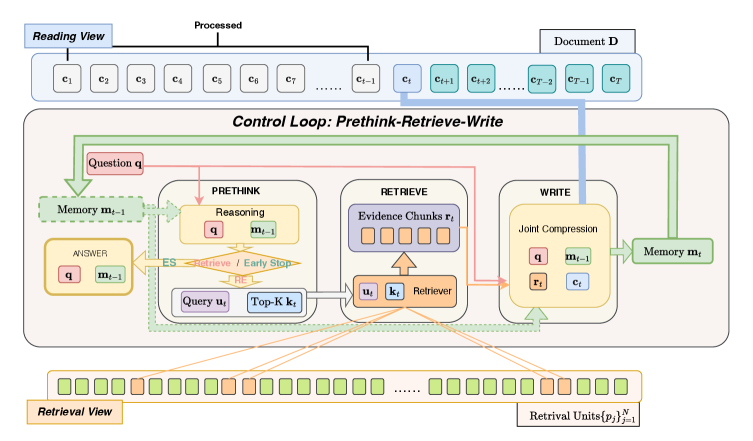
InfMem is a cognitive agent for ultra-long document QA that uses System-2-style control to actively manage bounded memory. Instead of passively compressing each chunk as it streams in, InfMem runs a PreThink-Retrieve-Write loop that monitors evidence sufficiency, fetches missing facts from anywhere in the document, and compresses everything into a fixed-size memory - then stops early once it has enough.
PreThink-Retrieve-Write protocol: At each step, a PreThink controller checks whether the current memory can already answer the question. If not, it generates a targeted retrieval query and specifies how many passages to fetch. Retrieve then pulls fine-grained paragraphs from anywhere in the document (not just nearby chunks), and Write jointly compresses the new evidence with existing memory under a fixed token budget.
Adaptive early stopping: Once the agent determines its memory is sufficient, it terminates the loop immediately rather than processing remaining chunks. This cuts inference time by up to 5.1x on 1M-token documents while preserving or improving accuracy.
SFT-to-RL training recipe: A two-stage pipeline first distills protocol-valid trajectories from a strong teacher (Qwen3-32B) via supervised fine-tuning, then applies GRPO with verifier-based rewards to align retrieval, writing, and stopping decisions with end-task correctness. RL adds an early-stop shaping reward that penalizes redundant retrieval after the memory becomes sufficient.
Strong gains over MemAgent: Across Qwen3-1.7B/4B and Qwen2.5-7B on benchmarks spanning 32k to 1M tokens, InfMem outperforms MemAgent by over 10 points on average after RL, while reducing latency by 3.3-5.1x. It also transfers well to LongBench QA with consistent improvements.
Robustness at extreme lengths: While baselines like YaRN collapse beyond 128k tokens and RAG struggles with dispersed evidence, InfMem remains stable up to 1M tokens, especially on complex multi-hop tasks that require synthesizing scattered bridging facts across distant document segments.
6. A-RAG
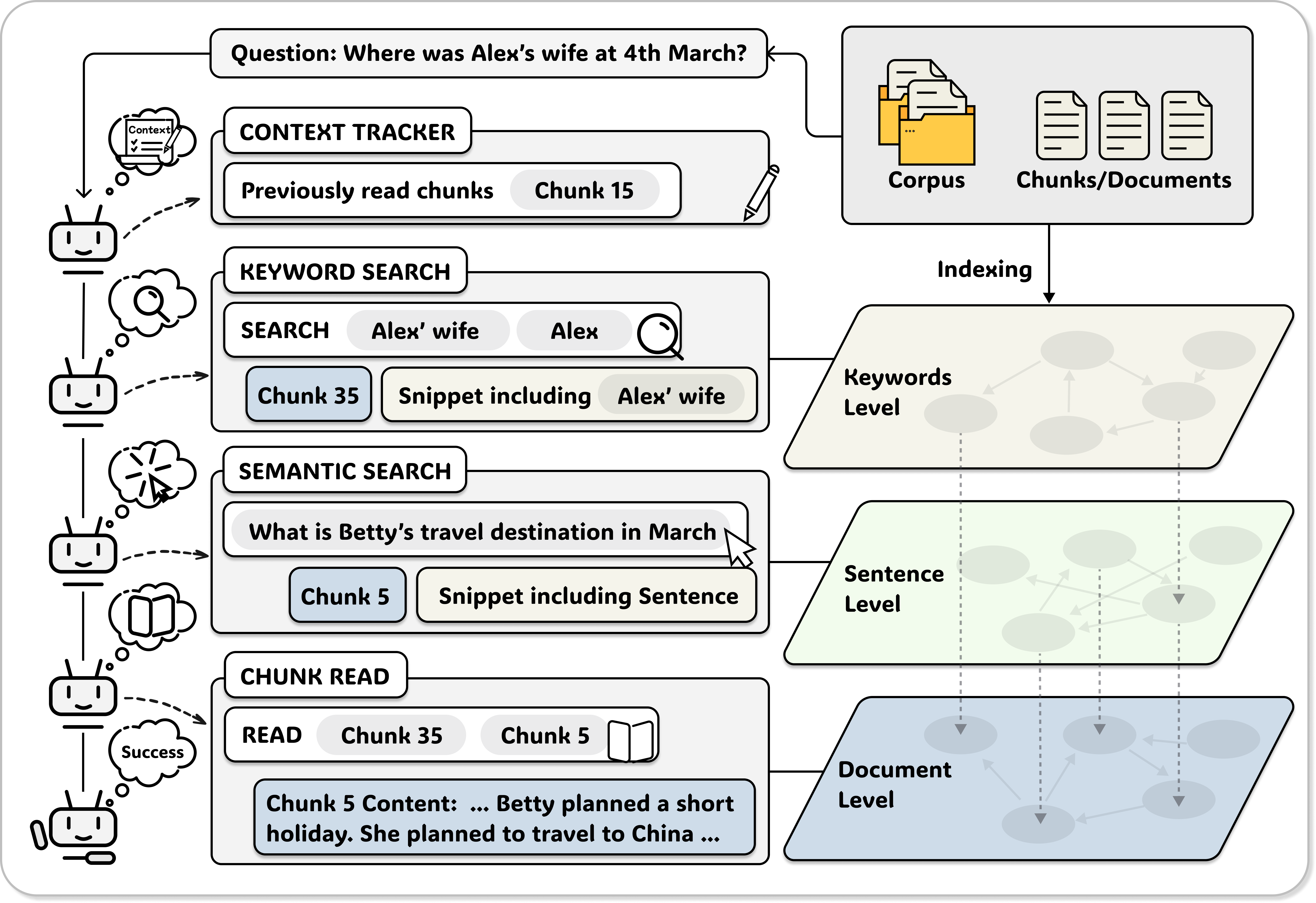
A-RAG is an agentic RAG framework that gives LLMs direct access to hierarchical retrieval interfaces instead of relying on fixed retrieval algorithms or predefined workflows. The agent autonomously decides what to search, at which granularity, and when to stop - representing a paradigm shift from static retrieval pipelines to truly agentic information gathering.
Hierarchical retrieval tools: A-RAG provides three tools operating at different granularities: keyword search for exact lexical matching at the keyword level, semantic search for dense retrieval at the sentence level, and chunk read for accessing full document chunks. The agent chooses which tool to call at each step based on the task, enabling adaptive multi-granularity retrieval.
Agentic autonomy over fixed workflows: Unlike Graph RAG (algorithm-driven, no iterative execution) and Workflow RAG (predefined steps, no autonomous strategy), A-RAG satisfies all three principles of agentic autonomy: autonomous strategy selection, iterative execution, and interleaved tool use. The model decides its own retrieval path in a ReAct-style loop.
Consistent gains across benchmarks: With GPT-5-mini as backbone, A-RAG outperforms all baselines on every benchmark tested (MuSiQue, HotpotQA, 2WikiMultiHopQA, Medical QA, Novel QA), beating strong methods like LinearRAG, HippoRAG2, and FaithfulRAG by significant margins.
Better accuracy with fewer tokens: A-RAG (Full) retrieves comparable or fewer tokens than traditional RAG methods while achieving higher accuracy. The hierarchical interface design lets the agent progressively disclose information and selectively read only the most relevant chunks, avoiding noise from irrelevant content.
Scales with test-time compute: Increasing max retrieval steps and reasoning effort both improve performance, with stronger models benefiting more from additional steps. Scaling reasoning effort from minimal to high yields approximately 25% improvement for both GPT-5-mini and GPT-5.
7. Agent Primitives
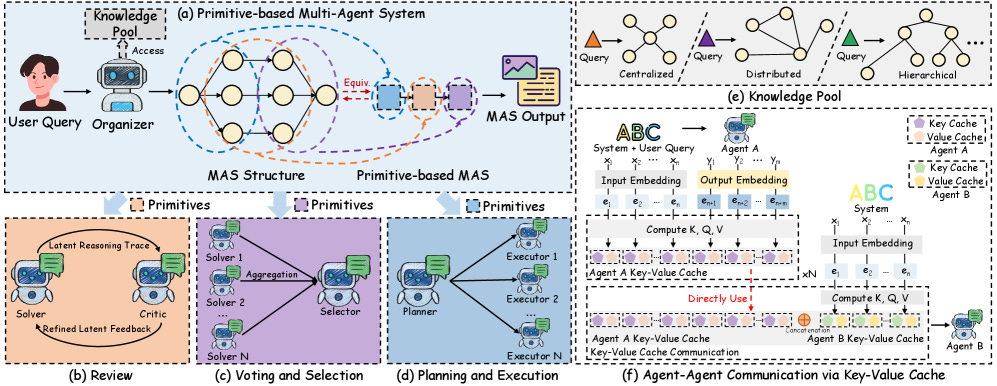
Agent Primitives introduces reusable latent building blocks for LLM-based multi-agent systems. Inspired by how neural networks are built from composable modules like residual blocks and attention heads, the authors decompose existing MAS architectures into three recurring computation patterns that communicate via KV cache instead of natural language, reducing error accumulation and boosting efficiency.
Three core primitives: Review (a Solver-Critic feedback loop for iterative self-refinement), Voting and Selection (parallel Solvers with a Selector that aggregates latent candidates), and Planning and Execution (a Planner that decomposes tasks into subgoals consumed by Executor agents). Each primitive communicates internally through KV cache concatenation rather than text generation.
KV cache over natural language: Stress tests show natural-language communication degrades sharply under long contexts and noise injection, while KV cache communication stays robust. With midpoint task injection, natural-language accuracy drops to 15.6% compliance versus 73.3% for KV cache.
Automatic composition via an Organizer: An LLM-based Organizer selects and composes primitives per query, guided by a lightweight Knowledge Pool of 45 previously successful MAS configurations. This eliminates manual system design while maintaining strong performance across tasks.
Consistent accuracy gains: Across eight benchmarks (math, code, QA) and five open-source backbones, primitives-based MAS improves accuracy by 12.0-16.5% over single-agent baselines. It also outperforms 10 existing MAS methods, including Self-Refine, AgentVerse, and MAS-GPT, on a unified Llama-3-70B evaluation.
Major efficiency improvements: Compared to text-based MAS, Agent Primitives reduces token usage and inference latency by 3-4x while achieving higher accuracy. Total overhead is only 1.3-1.6x relative to single-agent inference, making it practical for deployment.
8. Accelerating Scientific Research with Gemini
A collection of case studies from Google Research showing how researchers used Gemini Deep Think to solve open problems, refute conjectures, and generate new proofs across theoretical computer science, information theory, cryptography, optimization, economics, and physics. The paper extracts a practical playbook of recurring techniques, including iterative refinement, cross-disciplinary knowledge transfer, counterexample search, and neuro-symbolic verification loops where the model autonomously writes and executes code to validate derivations. Notable results include identifying a fatal flaw in a cryptography preprint on SNARGs, resolving the Courtade-Kumar conjecture in information theory, and proving that the simplex is optimal for Euclidean Steiner trees.
9. Heterogeneous Computing for AI Agent Inference
This paper introduces Operational Intensity (OI) and Capacity Footprint (CF) as two metrics that better characterize AI agent inference workloads than traditional roofline models, revealing that memory capacity - not just bandwidth or compute - is often the true bottleneck. Analysis across agent types (chatbot, coding, web-use, computer-use) shows that agentic workflows create vastly different and rapidly growing demands on hardware, with context lengths snowballing to over 1M tokens in coding agents. The authors argue for disaggregated, heterogeneous compute architectures with specialized prefill and decode accelerators, hardware-aware model co-design, and large-capacity memory disaggregation as essential directions for scaling AI agent systems.
10. OpenScholar
OpenScholar is a fully open, retrieval-augmented language model designed for scientific literature synthesis. It retrieves passages from a datastore of 45 million open-access papers, generates citation-backed responses, and iteratively refines outputs through a self-feedback loop. On ScholarQABench, the first large-scale multi-domain benchmark for literature search, OpenScholar-8B outperforms GPT-4o by 6% and PaperQA2 by 5.5% in correctness, while achieving citation accuracy on par with human experts and being preferred over expert-written answers 51-70% of the time.
The insight in the xMemory and Heterogeneous Computing papers is crucial: we’ve spent two years optimizing LLM 'reasoning' while ignoring the fact that agent memory is fundamentally different from standard RAG. Standard retrieval collapses because it lacks 'Execution Memory'- the ability to maintain the state of a long-running task across server restarts and API timeouts. 2026 is becoming the year where we realize that the winner isn't the one with the biggest model, but the one with the most resilient, state-aware infrastructure.