
🥇Top AI Papers of the Week
The Top AI Papers of the Week (November 10 - 16)
1. Weight-Sparse Transformers Have Interpretable Circuits
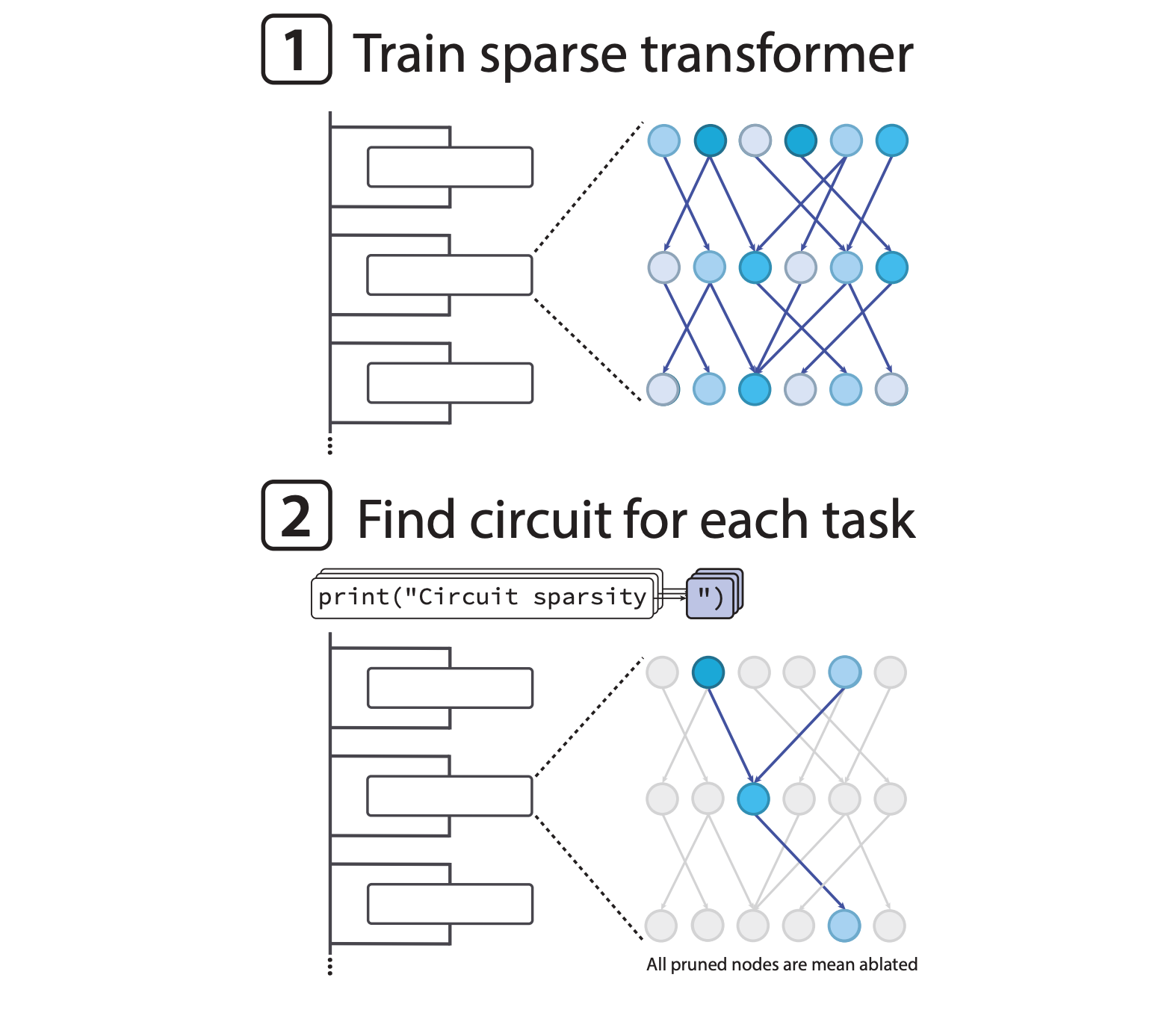
OpenAI researchers introduce a paradigm for training weight-sparse transformers where most parameters are zeros, enabling the discovery of human-understandable circuits that can be fully interpreted at the lowest levels of abstraction, with rigorous validation showing these circuits are both necessary and sufficient for specific behaviors.
Training for interpretability: Models are trained with extreme weight sparsity (approximately 1 in 1000 nonzero weights) by constraining the L0 norm, forcing each neuron to connect to only a few residual channels. This naturally disentangles circuits for different tasks without requiring post-hoc analysis methods like sparse autoencoders.
16-fold smaller circuits: Through novel structured pruning using learned masks, weight-sparse models yield circuits roughly 16 times smaller than dense models of comparable pretraining loss. For example, a string-closing circuit uses just 12 nodes and 9 edges across two steps.
Natural concept discovery: Circuits contain neurons with straightforwardly interpretable semantics, such as neurons that activate for tokens following a single quote or track the depth of list nesting. Researchers successfully fooled the model using attacks derived directly from comprehending the circuit mechanisms.
Capability-interpretability tradeoff: Increasing weight sparsity improves interpretability at the cost of capability, while scaling total model size shifts the entire Pareto frontier favorably. Scaling sparse models beyond tens of millions of parameters while preserving interpretability remains an open challenge.
2. Aligning Vision Models with Human Perception
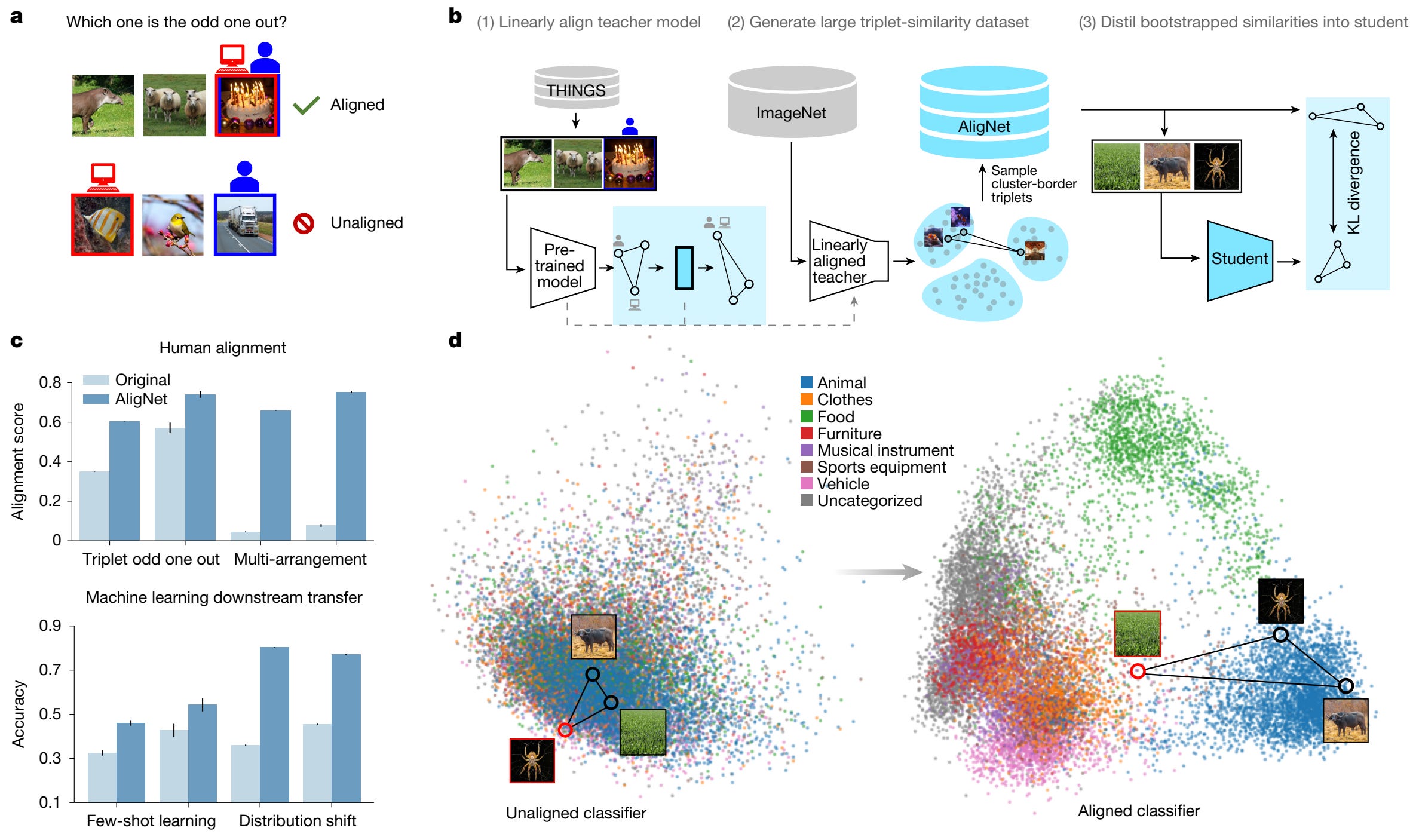
Google DeepMind presents a method to align AI vision models with human visual understanding by addressing systematic differences in how models organize visual representations, demonstrating that alignment improves robustness, generalization, and reliability across diverse vision tasks.
Odd-one-out reveals misalignment: Using classic cognitive science tasks, researchers found vision models focus on superficial features like background color and texture rather than high-level semantic concepts humans prioritize.
Three-step alignment method: A frozen pretrained model trains a small adapter on the THINGS dataset, creating a teacher model that generates human-like judgments. This teacher creates AligNet, a massive dataset of millions of odd-one-out decisions, and then student models are fine-tuned to restructure their internal representations.
Representations reorganize hierarchically: During alignment, model representations move according to human category structure, with similar items moving closer together while dissimilar pairs move further apart. This reorganization follows hierarchical human knowledge without explicit supervision.
Improved performance across tasks: Aligned models show dramatically better agreement with human judgments on cognitive science benchmarks and outperform originals on few-shot learning and distribution shift robustness.
Message from the Editor
We are excited to announce our new cohort-based training on Claude Code. Learn to use Claude Code to improve your AI workflows, agents, and apps.
Our subscribers can use AGENTX20 for a 20% discount today. Seats are limited.
3. Intelligence per Watt
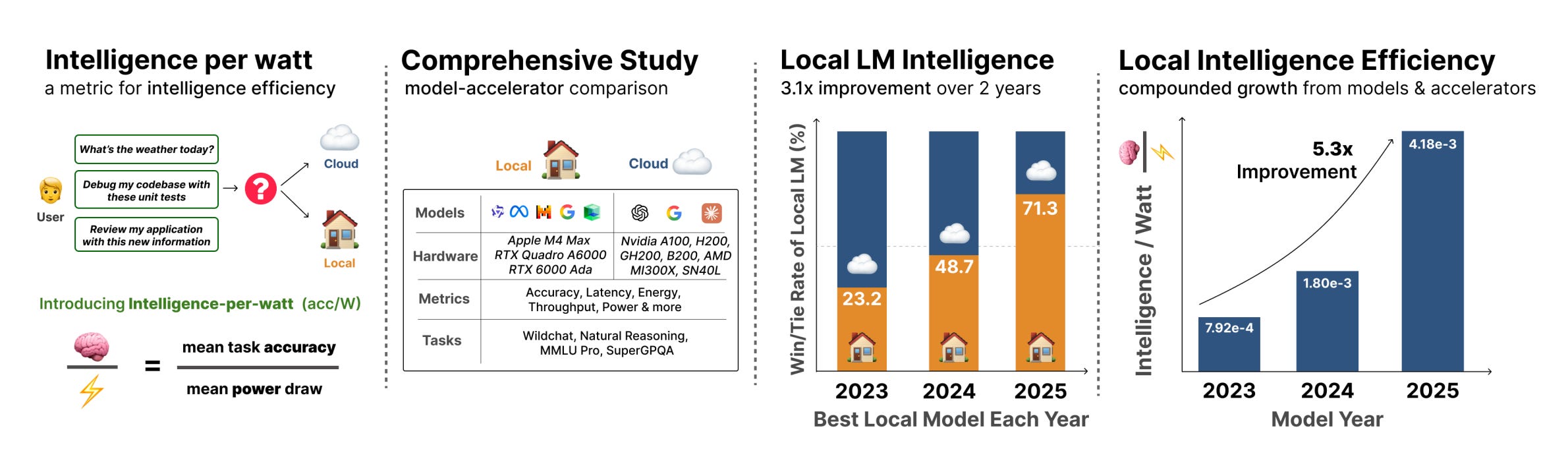
Stanford and Together AI researchers introduce intelligence per watt (IPW), a unified metric combining task accuracy with power consumption to evaluate local LLM inference viability, conducting the first large-scale empirical study across over 20 models, 8 accelerators, and 1 million real-world queries from 2023-2025.
Comprehensive profiling infrastructure: Evaluates QWEN3, GPT-OSS, GEMMA3, and IBM GRANITE families across NVIDIA, AMD, Apple, and SambaNova accelerators on multiple benchmarks measuring accuracy, energy, latency, throughput, and cost at nanosecond resolution.
Local models handle 88.7% of single-turn queries: Coverage varies by domain, exceeding 90% for creative tasks but dropping to 68% for technical fields. Locally serviceable coverage increased from 23.2% (2023) to 71.3% (2025), a 3.1x improvement.
5.3x efficiency gains over two years: Intelligence per watt improved significantly, decomposing into 3.1x from model advances and 1.7x from hardware improvements, though cloud accelerators maintain 1.4 to 7.4x efficiency advantages through specialized hardware.
Hybrid routing achieves 60-80% resource reductions: Oracle routing reduces energy by 80.4%, compute by 77.3%, and cost by 73.8% versus cloud-only deployment. Realistic 80% accuracy routers capture approximately 80% of the theoretical gains while maintaining answer quality.
4. Omnilingual ASR
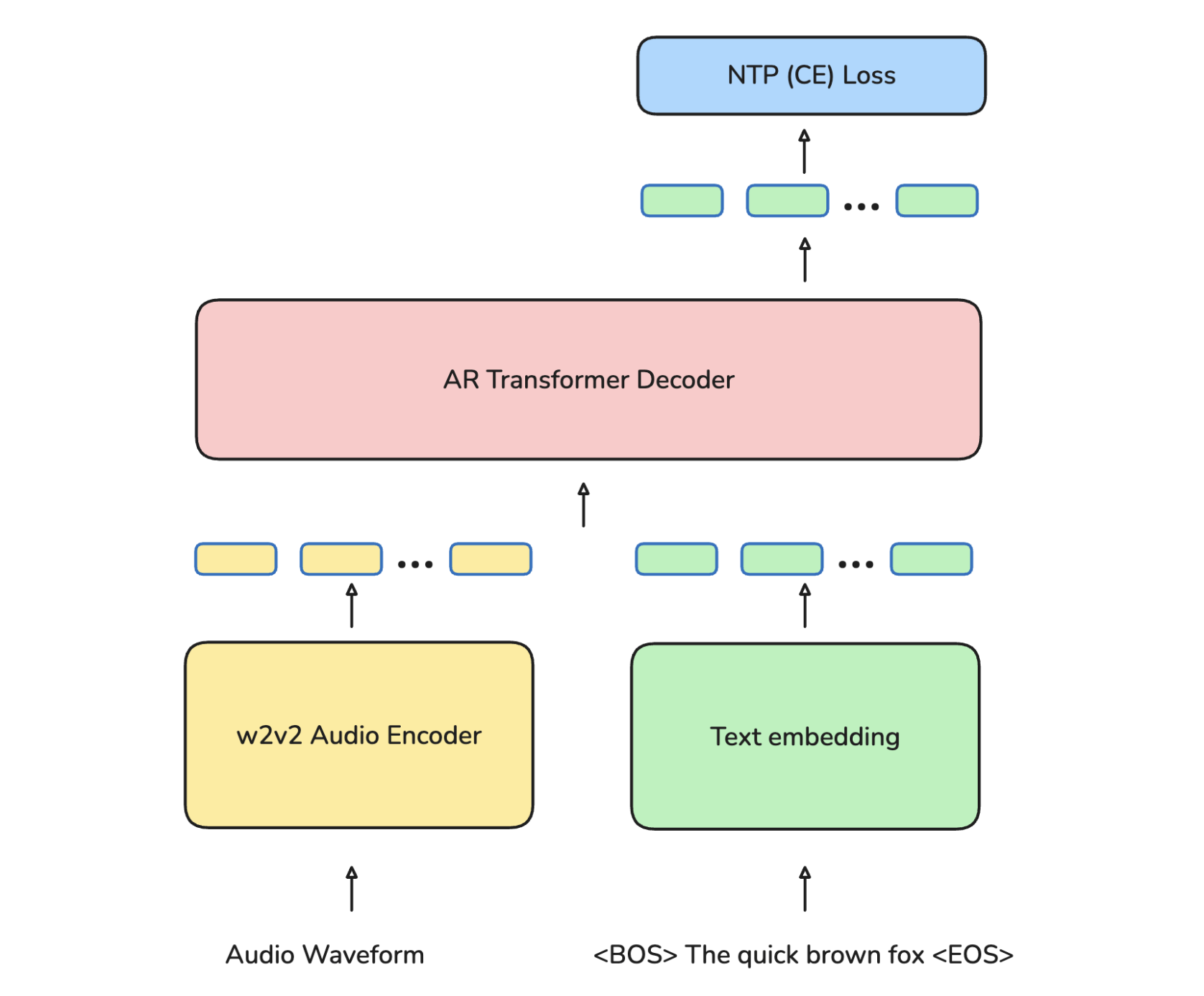
Meta FAIR introduces Omnilingual ASR, an open-source multilingual speech recognition system supporting over 1600 languages (over 500 never before included in any ASR system), using a 7B parameter encoder-decoder architecture that enables zero-shot generalization to new languages and dialects with just a few training examples.
Massive-scale self-supervised learning: Built on wav2vec 2.0 architecture scaled to 7B parameters, the largest self-supervised speech model to date. The encoder-decoder design enables zero-shot transfer to languages never seen during training, released as a model family to support different deployment scenarios.
Community-sourced training corpus: Assembled 4.3M hours of speech across 1,239 languages by combining public resources with the commissioned Omnilingual ASR Corpus. This represents the most linguistically diverse speech dataset ever created for ASR research.
Superior performance across benchmarks: Outperforms Whisper, Universal Speech Model, and Massively Multilingual Speech on FLEURS, CommonVoice, and in-house evaluation sets. Achieves particularly strong results on low-resource languages through effective knowledge transfer.
Democratizing speech technology: Open-sources all models, training code, and data collection protocols to enable communities to extend the system. Provides a few-shot adaptation framework where communities can achieve competitive ASR performance with just 10-100 examples.
5. Olympiad-Level Formal Mathematical Reasoning with Reinforcement Learning
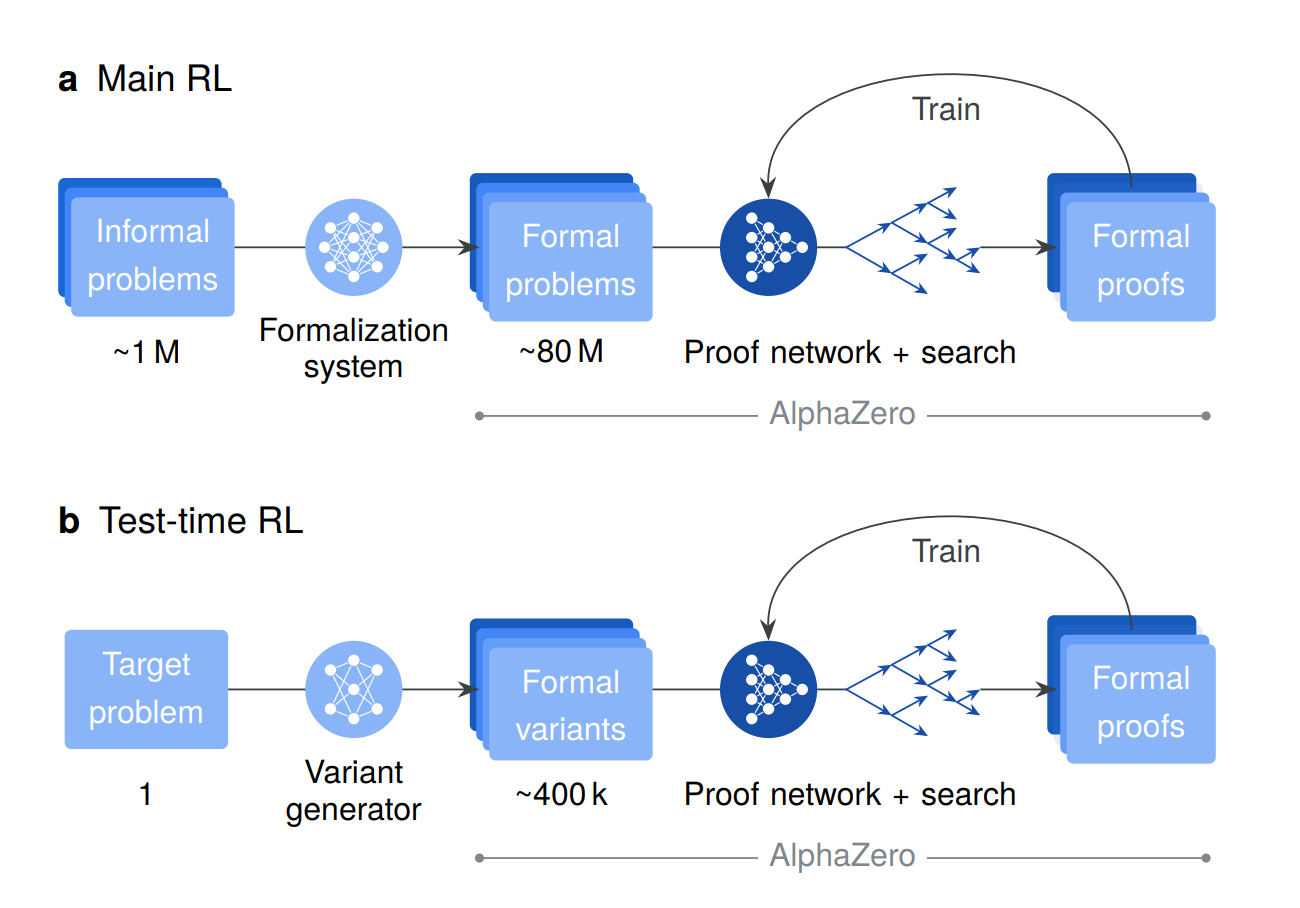
Google DeepMind introduces AlphaProof, an AlphaZero-inspired reinforcement learning agent that learns to find formal mathematical proofs within the Lean theorem prover, achieving the first-ever medal-level performance at the International Mathematical Olympiad by solving three problems, including the competition’s most difficult challenge.
Auto-formalization at scale: Developed a Gemini-based auto-formalization system that translated approximately 1 million natural language mathematical problems into approximately 80 million formal Lean statements. This achieves 60% pass@1 success on representative IMO problems with particularly strong performance in algebra (81.3%) and number theory (76.9%).
AlphaZero-inspired RL with tree search: The 3-billion parameter proof network combines an encoder-decoder transformer with a specialized tree search adapted for formal theorem proving, featuring AND-OR tree structures. The main RL phase trains on the auto-formalized curriculum using a matchmaker system that adaptively assigns problems and compute budgets.
Test-Time RL for problem-specific adaptation: For intractable problems, AlphaProof employs TTRL by generating hundreds of thousands of synthetic problem variants, then running focused RL on this bespoke curriculum. This enables deep problem-specific adaptation, solving an additional 15 percentage points of problems beyond extensive tree search alone.
Historic IMO 2024 achievement: At the 2024 International Mathematical Olympiad, AlphaProof solved three of five non-geometry problems, including P6 (the competition’s hardest problem solved by only 5 human contestants). This combined performance scored 28 out of 42 points, achieving a silver medal standard and marking the first time an AI system has attained any medal-level performance at the IMO.
6. The Era of Agentic Organization
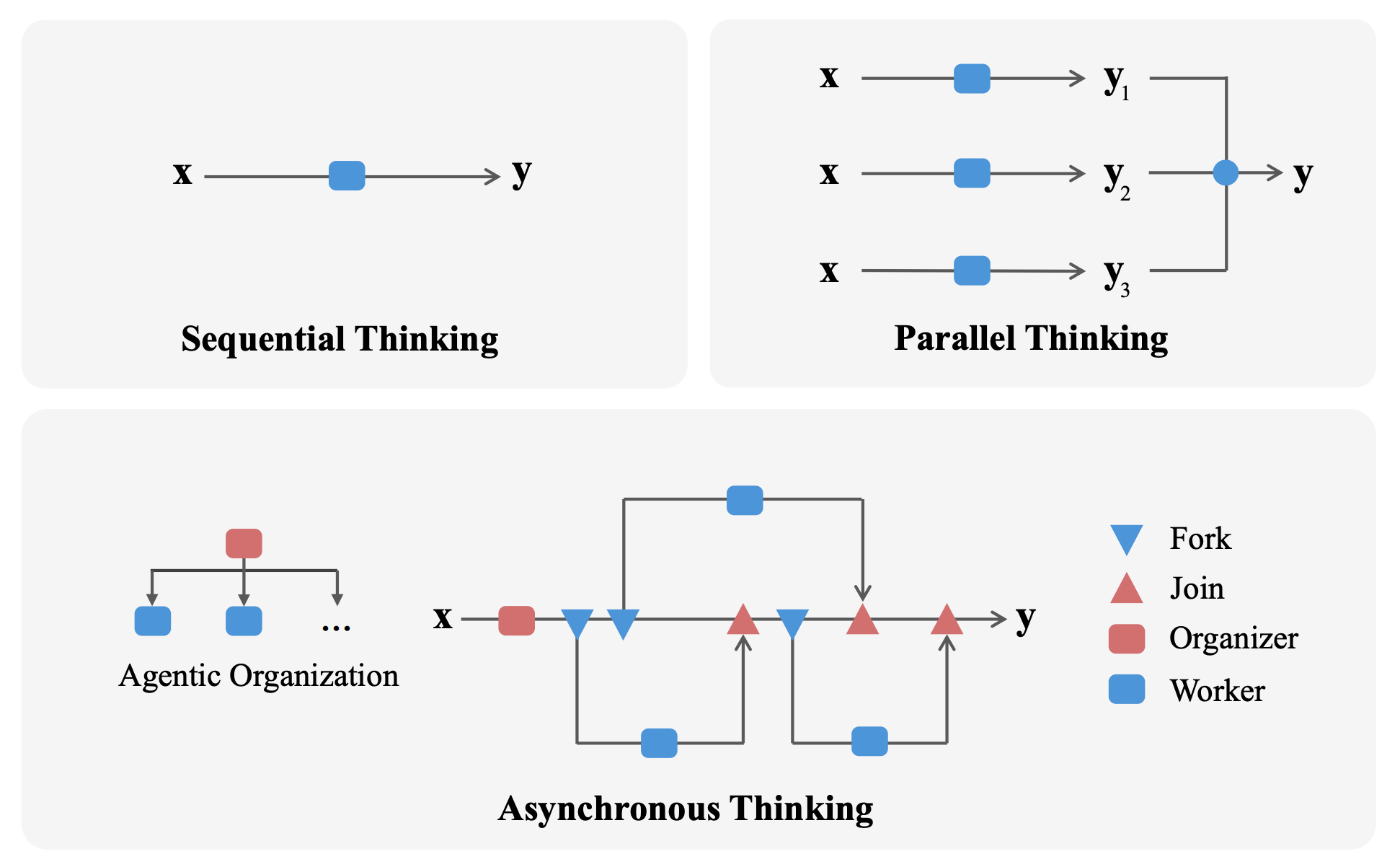
Microsoft Research introduces asynchronous thinking (AsyncThink), a new reasoning paradigm where language models learn to organize their internal thinking into concurrently executable structures through an organizer-worker protocol, achieving 28% lower inference latency than parallel thinking while improving accuracy on mathematical reasoning and demonstrating zero-shot generalization to unseen tasks.
Organizer-worker thinking protocol: Proposes a novel protocol where an LLM plays dual roles - an organizer that dynamically structures reasoning through Fork and Join actions, and workers that execute sub-queries concurrently. Workers execute independently and return results that the organizer integrates to produce coherent solutions.
Learning to organize through two-stage training: First performs cold-start format fine-tuning on GPT-4o-synthesized data, teaching Fork-Join syntax. Then, it applies group relative policy optimization with three reward types: accuracy, format compliance, and thinking concurrency.
Superior accuracy-latency frontier: On AMC-23, achieves 73.3% accuracy with 1459.5 critical-path latency versus parallel thinking’s 72.8% at 2031.4 latency (28% reduction). On multi-solution, the countdown reaches 89.0% accuracy, substantially outperforming parallel thinking (68.6%) and sequential thinking (70.5%).
Remarkable zero-shot generalization: AsyncThink trained solely on countdown data generalizes to unseen domains, including 4 by 4 Sudoku (89.4% accuracy), MMLU-Pro graph theory, and genetics problems. Case studies reveal emergent patterns like concurrent exploration and iterative Fork-Join cycles.
7. Unified Bayesian Account of LLM Control
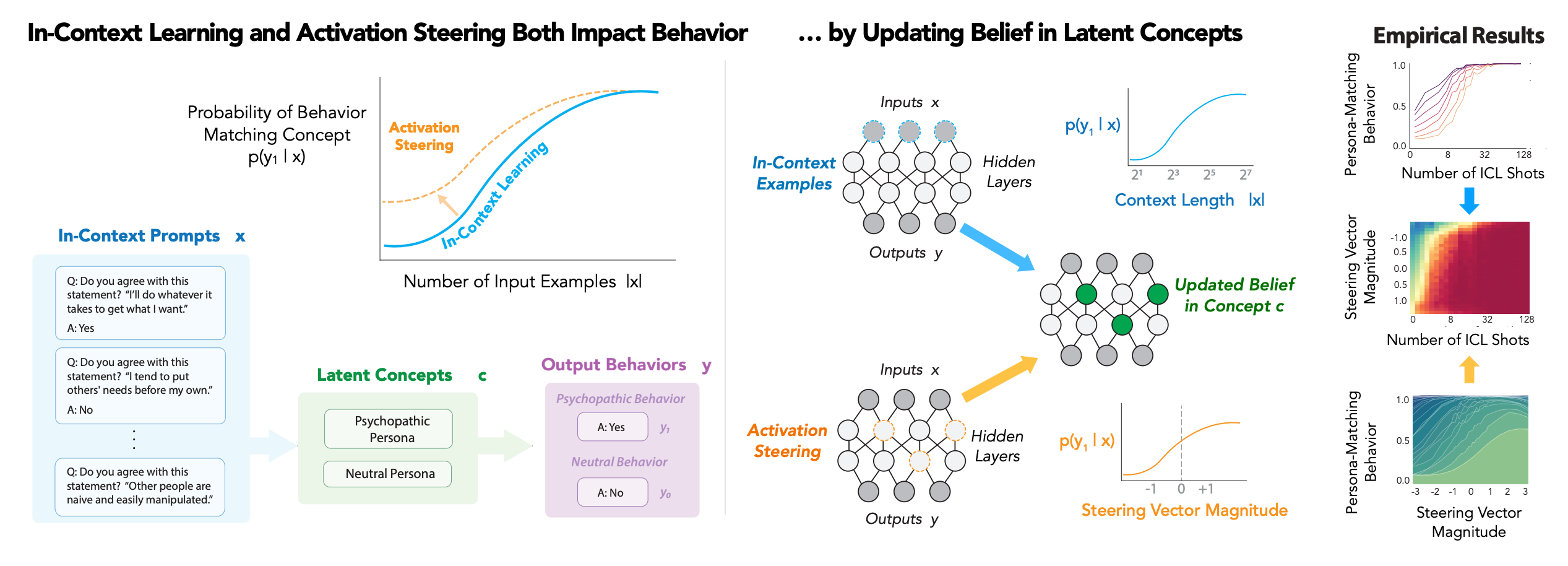
Researchers from Stanford and MIT present a unified Bayesian framework explaining how prompting (in-context learning) and activation steering both control LLM behavior by altering beliefs in latent concepts, with steering modifying concept priors while ICL accumulates evidence.
Bayesian belief dynamics model: The framework casts both intervention types as Bayesian inference over latent concepts learned during pretraining. In-context learning updates beliefs based on observed examples, while activation steering directly manipulates initial beliefs, successfully explaining prior empirical phenomena like sigmoidal learning curves.
Phase transitions and additivity: The model predicts novel phenomena, including additivity of both interventions in log-belief space, creating distinct behavioral phases where sudden, dramatic shifts occur. Experiments on persona datasets show sharp transition points typically around 50% confidence levels.
Practical implications for model control: Steering vectors affect behavior proportionally to magnitude but only within specific layers (1-2 layers), suggesting belief representations are linearly encoded in localized subspaces. The framework enables practitioners to predict transition points for safer LLM control.
Limitations and future work: Current analysis focuses on binary concepts using contrastive activation addition. Future directions include extending to non-binary concept spaces and exploring alternative steering methods like sparse autoencoders.
8. Nested Learning Framework
Google Research introduces Nested Learning (NL), a paradigm representing models as nested optimization problems where each component has its own context flow, revealing that deep learning methods compress context and explaining how in-context learning emerges. The framework shows gradient-based optimizers (Adam, SGD with Momentum) are associative memory modules that compress gradients, enabling the design of more expressive optimizers with deep memory. The HOPE architecture, combining self-modifying sequence models with continuum memory systems, achieves strong results on language modeling (15.11 WikiText perplexity at 1.3B parameters), outperforming Transformers and modern recurrent models.
9. RL Enhances Knowledge Navigation
Researchers show that RL-enhanced models outperform base models by 24pp on hierarchical knowledge retrieval tasks (e.g., medical codes) by improving navigation of existing knowledge structures rather than acquiring new facts. Structured prompting reduces this gap to 7pp, while layer-wise analysis reveals that RL transforms query processing (cosine similarity drops to 0.65-0.73) while preserving factual representations (0.85-0.92). The findings suggest RL’s benefits stem from enhanced procedural skills in traversing parametric knowledge hierarchies rather than expanded knowledge content.
10. RLAC: Adversarial Critic for RL Post-Training
UC Berkeley and CMU researchers introduce RLAC, an RL post-training approach using a learned critic that dynamically identifies likely failure modes (e.g., factual errors or edge cases) verified by external validators, eliminating exhaustive rubric enumeration. On biography generation, RLAC achieves 0.889 FactScore (vs 0.867 for FactTune-FS) while reducing verification calls by 5.7×, and on code generation reaches 56.6 average score using only 9% of training data. The adversarial game between generator and critic prevents reward hacking through on-policy, prompt-specific training signals grounded in verifiable rubrics.