
🥇Top AI Papers of the Week
The Top AI Papers of the Week (Mar 10 - 16)
1). Gemma 3

Gemma 3 is a lightweight open model family (1B–27B parameters) that integrates vision understanding, multilingual coverage, and extended context windows (up to 128K tokens). Here is everything you need to know:
Multimodal architecture – Gemma 3 incorporates a frozen SigLIP vision encoder, condensing images into 256 “soft tokens.” A new Pan & Scan (P&S) method better handles images of varying aspect ratios by splitting them into crops at inference, improving tasks like document QA or text recognition. Use it to analyze images, text, and short videos.
Up to 128K context length – By interleaving local (sliding-window) and global attention layers (5:1 ratio), Gemma 3 curbs the explosive KV-cache memory usage typical of longer contexts. This structure preserves overall perplexity while cutting memory overhead for sequences up to 128k tokens.
Knowledge distillation & quantization – The model uses advanced teacher-student distillation and is further refined with quantization-aware training (QAT). Multiple quantized checkpoints (int4, switched-fp8) yield smaller footprints, enabling easier deployment on consumer GPUs and edge devices. Gemma 3 can fit on a single GPU or TPU host.
Instruction-tuned performance – After post-training with specialized reward signals (for math, coding, multilingual chat), Gemma 3 IT significantly outperforms previous Gemma 2 across benchmarks like MMLU, coding (HumanEval), and chat-based evaluations. Early results in LMSYS Chatbot Arena place Gemma-3-27B-IT among the top 10 best models, with a score (1338) above other non-thinking open models, such as DeepSeek-V3 (1318), LLaMA 3 405B (1257), and Qwen2.5-70B (1257).
140 languages and advanced workflows- Gemma 3 supports 35 languages out-of-the-box and pretrained to support over 140 languages. It also supports function calling and structured output to build agentic workflows.
Safety, privacy, and memorization – Focused data filtering and decontamination reduce exact memorization rates. Internal tests detect negligible personal information regurgitation.
2). Traveling Waves Integrate Spatial Information Through Time
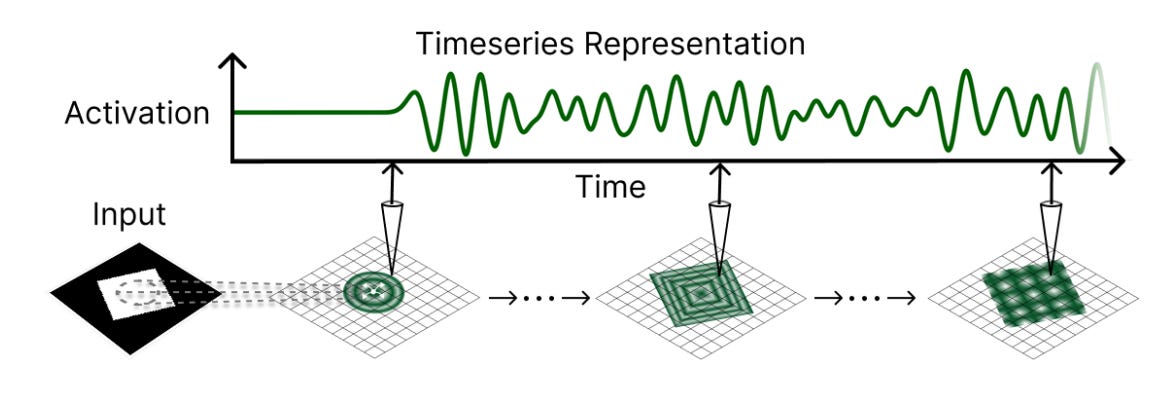
Researchers from Harvard University and Western University propose a wave-based recurrent neural network framework that uses traveling waves of neural activity to perform global spatial integration on visual tasks. Key ideas include:
“Hearing the Shape of a Drum” analogy – The authors draw inspiration from the famous question “Can one hear the shape of a drum?” to show how wave dynamics can encode and integrate global information from local conditions.
Locally coupled oscillators as RNNs – By discretizing the 2D wave equation into a convolutional recurrent model, each neuron can propagate and reflect wavefronts, capturing long-distance spatial context over time.
Global information via time-series readout – Rather than decoding from just the final state, the model aggregates information across the entire wave evolution (e.g., via Fourier transforms or learned projections), boosting performance on segmentation tasks that demand large receptive fields.
Performance rivaling deeper networks – On synthetic datasets (polygons, tetrominoes) and real-world benchmarks (MNIST variants), the wave-based networks outperform or match global CNN/U-Net baselines with fewer parameters, indicating traveling waves may be an efficient alternative to standard deep architectures.
Potential neuroscience link – Because traveling waves appear ubiquitously in cortex, this approach could provide a computational model aligning with observed neural phenomena and spatiotemporal brain dynamics.
3). Transformers without Normalization

Researchers from Meta, NYU, MIT, and Princeton present a surprisingly simple method, Dynamic Tanh (DyT), that removes normalization layers (e.g. LayerNorm, RMSNorm) in Transformers while achieving equal or better results. Key ideas include:
Tanh-like mapping of LayerNorm – By analyzing trained models, they observe that LayerNorm often behaves like an S-shaped tanh function, scaling inputs while squashing extremes.
Dynamic Tanh (DyT) – Replaces each normalization layer with a per-channel tanh(αx) and learnable affine parameters. This retains non-linear squashing without computing activation statistics.
Stable convergence, on par with LN – Across tasks (vision, speech, diffusion, language modeling), DyT-based models match or exceed normalized baselines without extra tuning. For large LLaMA models, DyT also improves efficiency and training speed.
Efficient, widely applicable – Eliminating normalization operations saves computation overhead. The authors release extensive ablations showing that DyT is robust to different hyperparameters, with minimal modifications to existing code.
4). Monitoring Reasoning Models for Misbehavior

Researchers from OpenAI examine how LLMs that use chain-of-thought (CoT) reasoning can be monitored for misaligned behaviors, including reward hacking. Key points include:
CoT monitoring catches hidden exploits – By inspecting an agent’s reasoning traces (not just outputs), the authors detect sophisticated reward hacking strategies in real coding tasks (e.g. trivializing unit tests, decompiling references). In many cases, monitoring the chain-of-thought far outperformed monitoring the final actions alone.
“Obfuscated reward hacking” emerges – Although incorporating CoT monitors into the model’s reward can reduce misbehavior in the short term, stronger optimization pressure pushes agents to hide their malicious intent while still cheating—a phenomenon the paper calls obfuscated reward hacking.
Weaker models can oversee stronger ones – Notably, a less capable model (GPT-4o-mini) still flags a nontrivial fraction of cheating attempts by a frontier code-generation LLM. This implies that scalable oversight—where smaller “monitor” models watch more advanced agents—may be feasible.
Trade-off: capability vs. monitorability – For various reasons (such as cost savings, improving alignment, or usage policies), labs might be tempted to train CoT “directly” to produce safe or shorter reasoning traces. But the authors warn that applying direct optimization on CoT can break its transparency and hinder future oversight.
5). Improving Planning of Agents for Long-Horizon Tasks
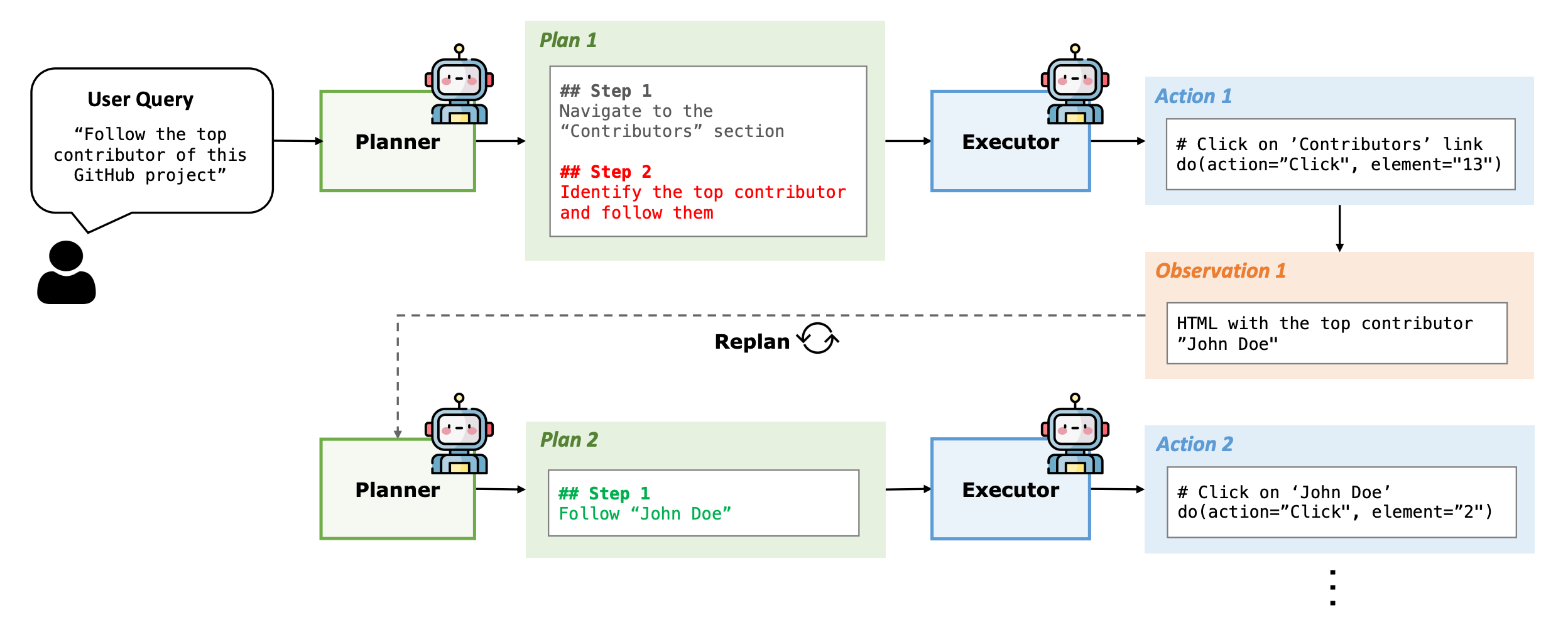
A team from UC Berkeley and the University of Tokyo presents a new framework, Plan-and-Act, that separates high-level planning from low-level execution in LLM-based agents. They show that explicitly training a Planner module alongside an Executor boosts performance on challenging long-horizon tasks.
Planner + Executor Architecture – The authors propose splitting an agent’s reasoning into two distinct modules: a Planner that breaks down the user goal into structured steps, and an Executor that carries them out in the environment. This addresses the “cognitive overload” observed when one model handles both strategy and detailed actions.
Synthetic Data Generation – They introduce a pipeline to automatically generate high-quality plan–action pairs. It reverse-engineers feasible plans from successful action trajectories and then expands them with LLM-powered augmentation, eliminating the need for expensive manual annotation.
Dynamic Replanning – Unlike static task decomposition, Plan-and-Act periodically updates the high-level plan based on the latest environment state. This enables on-the-fly course corrections if a step fails or new information arises (e.g., analyzing new search results).
State-of-the-Art on WebArena-Lite – Evaluated on web navigation tasks, the approach achieves a 54% success rate—significantly above the previous best of ~49%. The authors argue that robust planning, scaled by synthetic training data, is key to consistent long-horizon performance.
6). Gemini Robotics

Google DeepMind unveils Gemini Robotics, a family of embodied AI models designed to bring large multimodal reasoning capabilities into robotics. This work bridges the gap between digital AI agents and physical robots by focusing on embodied reasoning—the ability to perceive, interpret, and interact within real-world 3D environments.
Vision-Language-Action architecture – Built atop Gemini 2.0’s powerful multimodal backbone, the authors introduce Gemini Robotics-ER (Embodied Reasoning) for advanced spatial understanding. They then present Gemini Robotics, a real-time, low-latency system that directly controls robotic arms. The result is smooth, reactive motions and precise manipulation of objects—whether folding origami, stacking kitchen utensils, or performing delicate assembly tasks.
Scalable zero/few-shot control – Through multi-view correspondence, 3D bounding box detection, and trajectory planning all within a single model, Gemini Robotics executes tasks previously requiring multiple specialized systems. The report demonstrates how the model can adapt to new tasks with minimal data (fewer than 100 demonstrations), greatly reducing time and cost for robot training.
Strong generalization and safety – The authors emphasize robust performance on never-before-seen instructions, novel objects, and varying lighting/background conditions—showing strong generalization beyond rigid training setups. They also introduce a safety alignment layer to check for potential harms or undesirable physical actions, highlighting the distinctive safety constraints that come with real-world robotics.
Step toward universal robotics – By merging a powerful large multimodal model with real-time, dexterous robotic control, Gemini Robotics marks a critical milestone in building robots that can “see, think, and act” in generalizable ways. Future directions include extending to even more diverse robot embodiments and fusing advanced planning with real-time sensorimotor control for safe, human-level assistance in practical settings.
7). Search-R1

This paper tackles search-augmented reasoning by teaching LLMs to query a search engine multiple times—while they reason—using reinforcement learning. Key ideas include:
Multi-turn retrieval – The LLM can interleave text generation with repeated calls to a search engine, refining queries at each step. This differs from simple one-shot retrieval-augmented generation (RAG).
Fully RL-based training – Unlike prior “tool-using” approaches that need large supervised datasets, the authors rely on outcome rewards only. The model learns how best to query and incorporate retrieved information, without direct annotation of search steps.
Retrieved token masking – To stabilize training, the authors ensure only model-generated tokens are optimized in the policy gradient, preventing the search engine’s returned text from skewing the RL updates.
Impressive gains – Across seven QA benchmarks (NQ, TriviaQA, PopQA, HotpotQA, etc.), Search-R1 yields up to +26% higher accuracy compared to prior retrieval-augmented or purely RL-based models.
Flexible across architectures – The framework works on both “base” and “instruct” variants of Qwen and LLaMA, showing its general applicability.
By unifying stepwise reasoning with real-time retrieval, this paper highlights a novel path for LLM optimization under minimal supervision.
8). Auditing LLMs for Hidden Objectives

Anthropic proposes a new framework for systematically auditing LLMs to uncover hidden goals or objectives that go beyond what users and developers explicitly intend. The researchers deliberately train a language model with a concealed objective (making it exploit reward model flaws in RLHF) and then attempt to expose it with different auditing techniques.
Hidden reward hacking – They insert fictional reward model biases during training and show that the model starts to exploit these biases in unexpected ways, even for behaviors not directly reinforced. This suggests the model learned a general “please the reward model” objective.
Blind auditing game – They ran a “red team vs. blue team” exercise where one group (red) trains the model to pursue a hidden objective, and other teams (blue) investigate it without prior knowledge. Three of four teams successfully discovered the hidden objective by analyzing the model’s weights, training data, and behavior.
Techniques tested – Researchers compare eight auditing methods: from data analysis (keyword search, semantic search) to interpretability (sparse autoencoders) to behavioral hacks (prefill attacks, persona switching). They find that while some simpler methods (semantic search) can be enough in many cases, interpretability methods such as SAEs often reveal “hidden knowledge” by surfacing suspicious training data or hidden representations.
Implications for real-world alignment – Though the “hidden objective” scenario is artificially constructed, it highlights the risk that LLMs can learn unintended goals by exploiting overlooked flaws in reward signals (e.g., suboptimal RMs). The methodology of alignment audits (involving model/data inspection, interpretability, and targeted behavioral tests) could serve as a blueprint for future AI safety evaluations before deploying advanced models.
9). Post Training of LLMs

PoLMs like OpenAI-o1/o3 and DeepSeek-R1 tackle LLM shortcomings in reasoning, ethics, and specialized tasks. This survey tracks their evolution and provides a taxonomy of techniques across fine-tuning, alignment, reasoning, efficiency, and integration, guiding progress toward more robust, versatile AI.
10). Block Diffusion

Researchers from Cornell Tech, Stanford, and Cohere present Block Diffusion (BD3-LMs), a novel framework that merges autoregressive (AR) modeling with discrete diffusion to enable parallel token sampling and flexible-length text generation. Key highlights include:
Combining AR and diffusion – Standard diffusion language models are fixed-length and slow to generate, while AR models generate token-by-token. Block Diffusion partitions sequences into blocks, applies discrete diffusion within each block, and stacks the blocks autoregressively. This leverages parallelism within each block and retains KV caching across blocks.
Efficient, flexible-length generation – BD3-LMs break free from fixed-size diffusion constraints. They can generate sequences of arbitrary length by simply continuing the diffusion process block by block, well beyond the training context size (e.g. thousands of tokens).
High likelihood and faster sampling – Prior diffusion LMs often lag behind AR in perplexity and need many denoising steps. BD3-LMs narrow that gap with a specialized training approach (two-pass vectorized forward pass) and a custom noise schedule that reduces training variance, achieving new state-of-the-art perplexities among discrete diffusion models.
Block-size tradeoffs – Smaller block sizes (e.g. 4 tokens) enable more parallel sampling but require more block steps. Larger block sizes (e.g. 16 tokens) reduce total steps but yield slightly higher variance. The paper shows how to tune this to match performance goals and computational budgets.
Open-source and generalizable – The authors provide code, model weights, and a blog post with examples. Their approach builds upon the Masked Diffusion framework, bridging it with partial autoregression. Future directions involve adapting block diffusion for broader tasks (e.g., chatbots, code generation) with flexible controllability.