
🥇Top AI Papers of the Week
The Top AI Papers of the Week (November 17 - 23)
1. GPT-5 for Science Acceleration

OpenAI and collaborators present early case studies demonstrating GPT-5’s capabilities in accelerating scientific research across mathematics, physics, biology, computer science, astronomy, and materials science. The model helps researchers synthesize known results, conduct literature reviews, accelerate computations, and generate novel proofs of unsolved propositions.
Advanced literature search across languages and domains: GPT-5 demonstrates emerging capability in conceptual literature search, identifying deeper relationships between ideas and retrieving relevant material across languages and less accessible sources. In one case, it identified a relevant German PhD thesis from economics using completely different terminology, showcasing cross-domain and multilingual understanding beyond traditional keyword-based search.
Mathematical proof generation and optimization: Mathematicians used GPT-5 to generate viable proof outlines in minutes for work that might otherwise take days or weeks. The model discovered a new, clear example showing that a common decision-making method can fail and improved a classic result in optimization theory, demonstrating the capability to contribute novel mathematical insights.
Hypothesis generation and experimental design: In biology and other empirical sciences, GPT-5 can propose plausible mechanisms and design experiments to validate hypotheses in the wet lab. The model expands the surface area of exploration and helps researchers move faster toward correct results, though human expertise remains critical throughout the process.
Tool for expert acceleration, not autonomous research: GPT-5 shortens parts of the research workflow when used by domain experts, but does not run projects or solve scientific problems autonomously. The early experiments establish a framework for human-AI collaboration in scientific discovery where AI acts as an amplifier of expert capabilities rather than a replacement.
2. OLMo 3
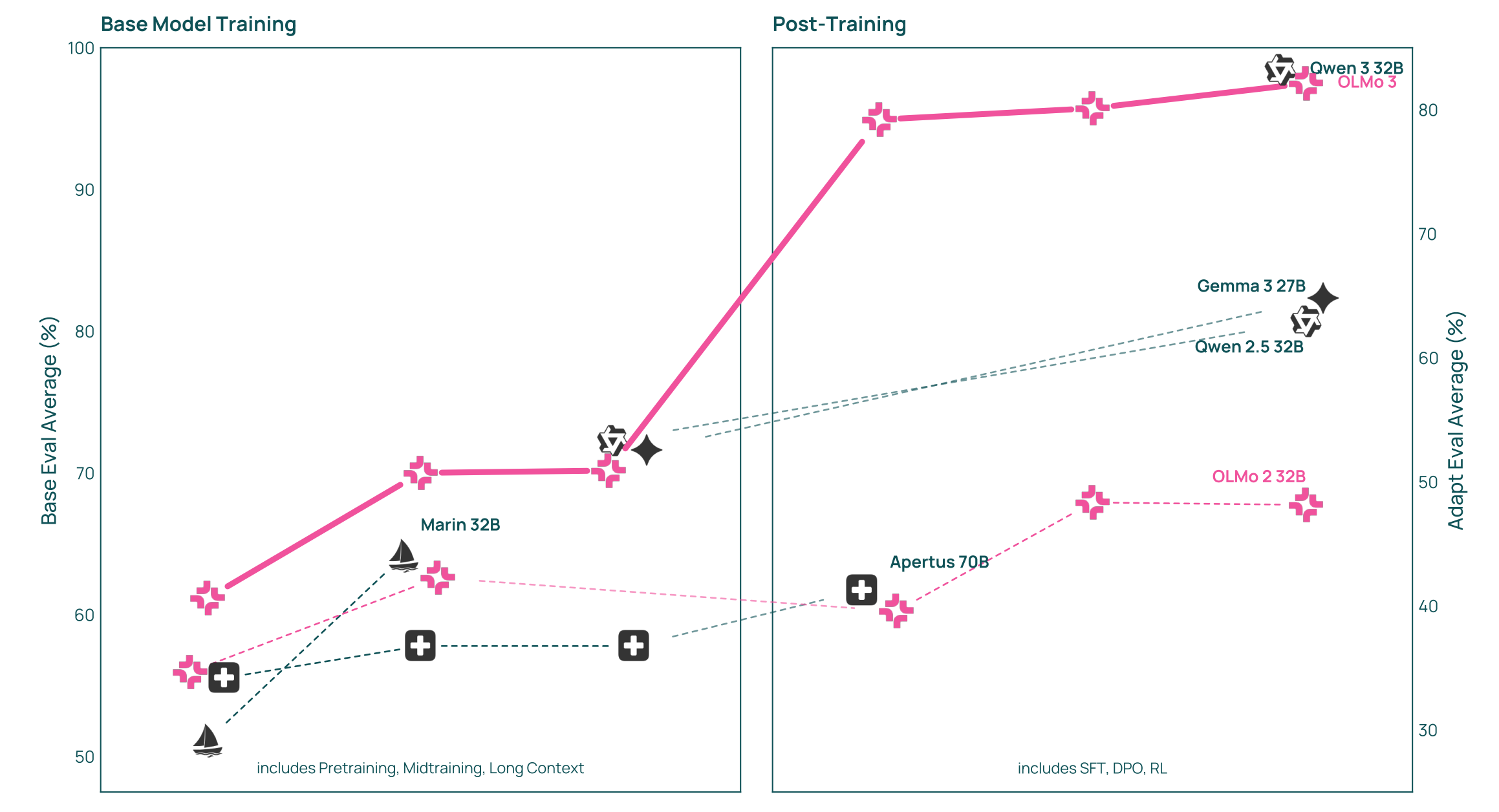
Allen Institute for AI introduces OLMo 3, a fully open language model family that releases the complete “model flow”: every training stage, checkpoint, dataset, and dependency, enabling researchers to intervene at any development point. The release includes four specialized variants (Base, Think, Instruct, RL Zero) at 7B and 32B scales.
Complete transparency with intervention points: Unlike typical releases that only share final weights, OLMo 3 provides checkpoints from every major training milestone, including initial pretraining, mid-training for programming/math, and long-context extension stages. This enables researchers to swap in domain-specific data during mid-training, adjust post-training for custom use cases, or build on earlier checkpoints for controlled experiments.
Strong performance across reasoning and code: OLMo 3-Think (32B) achieves 96.1% on MATH benchmark and 89.0% on IFEval instruction-following, while OLMo 3-Base (32B) scores 80.5% on GSM8k and 66.5% on HumanEval, outperforming comparable fully-open models like Marin and Apertus across reasoning, code generation, and math tasks.
Dolma 3 dataset and training efficiency: Trained on the 9.3 trillion token Dolma 3 corpus comprising web pages, scientific PDFs (processed with olmOCR), code, and math problems. Infrastructure improvements include 8x throughput gains in supervised fine-tuning and 4x efficiency improvements in RL training through in-flight weight updates and continuous batching.
Full open-source ecosystem release: All components released under permissive licenses, including training/fine-tuning datasets, OlmoTrace (real-time tool for tracing outputs to training data), Olmo-core, Open Instruct, datamap-rs, and duplodocus production-grade tools for data processing and reproducible evaluation, plus a complete technical report with ablations.
Message from the Editor

We are excited to announce our new cohort-based training on Claude Code. Learn to use Claude Code to improve your AI workflows, agents, and apps.
Our subscribers can use EARLYBIRD25 for a 25% discount today. Seats are limited.
3. SAM 3
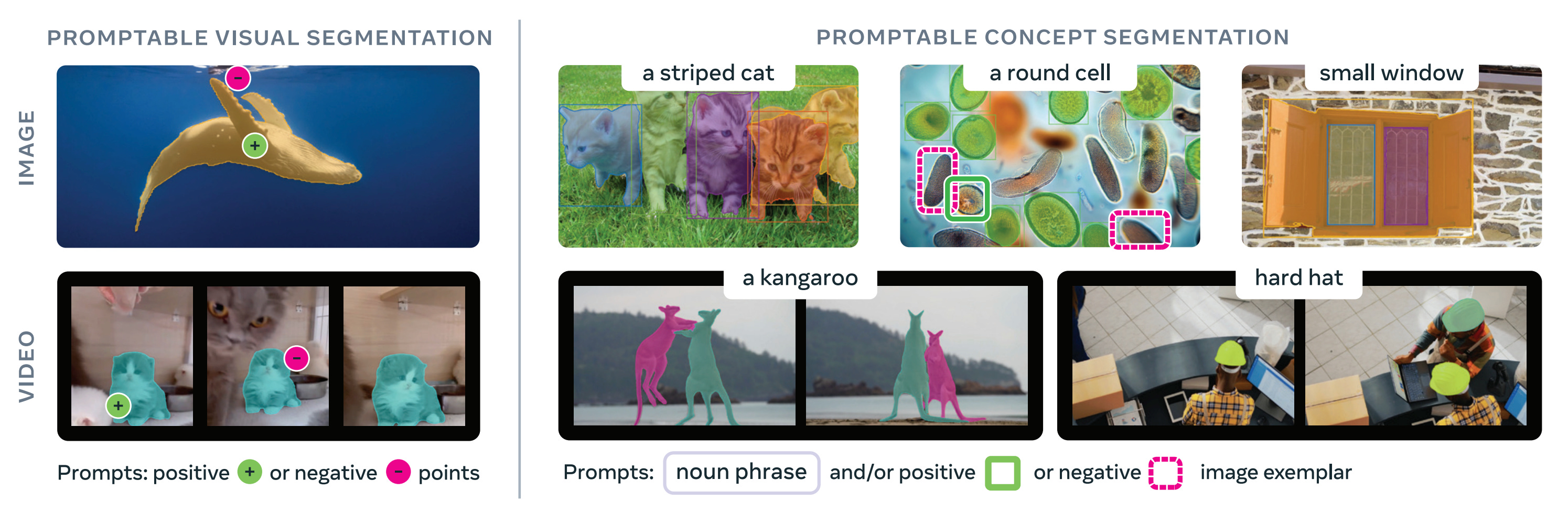
Meta AI introduces SAM 3, a unified model that detects, segments, and tracks objects across images and videos using conceptual prompts like noun phrases or visual examples. This extends the Segment Anything capability to concept-based segmentation through Promptable Concept Segmentation (PCS).
Scalable data engine with 4M concept labels: The team built a data pipeline producing 4 million unique concept labels with hard negative examples across images and video content. This massive dataset enables training models to understand and segment objects based on abstract conceptual descriptions rather than just visual patterns.
Unified architecture with presence head: The model combines an image-level detector with memory-based video tracking, sharing a unified backbone. A novel presence head decouples recognition from localization, improving detection precision by separating the tasks of determining whether a concept exists from finding where it appears.
2x improvement over existing approaches: SAM 3 achieves double the performance of previous methods on concept segmentation tasks for both images and videos. It also improves upon earlier SAM iterations across standard visual segmentation benchmarks.
Open release with SA-Co benchmark: Meta releases the complete model weights and introduces SA-Co, a new benchmark specifically designed for evaluating promptable concept segmentation systems, providing standardized evaluation resources for future research.
4. DR Tulu
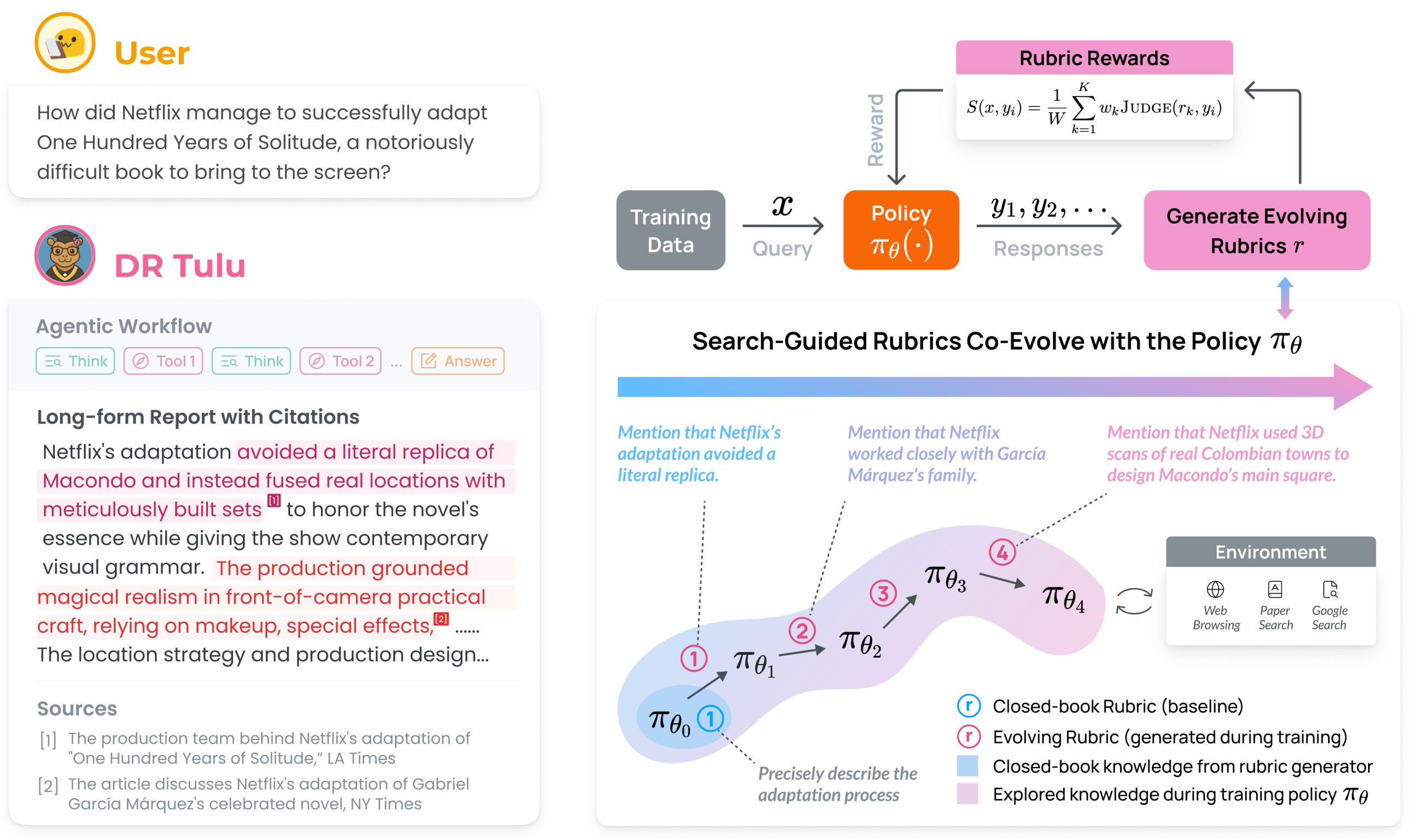
DR Tulu-8B is the first open model directly trained for long-form deep research using Reinforcement Learning with Evolving Rubrics (RLER). Unlike existing models trained on short-form QA tasks, DR Tulu learns to produce comprehensive, well-attributed research reports by training with rubrics that co-evolve with the model and are grounded on real-world searched knowledge.
RLER training innovation: The method generates new rubrics at each training step by contrasting multiple model rollouts and incorporating newly explored information from search results. This creates on-policy feedback that adapts as the model discovers new evidence, addressing the challenge that static rubrics cannot capture all quality dimensions for open-ended research tasks.
Outperforms all open deep research models: DR Tulu-8B beats existing 8-32B open models by 8-42 percentage points across four benchmarks (AstaBench-ScholarQA, DeepResearchBench, ResearchQA, HealthBench). It matches or exceeds proprietary systems like OpenAI Deep Research and Perplexity Deep Research while being significantly cheaper (USD 0.00008 vs USD 1.80 per query).
Adaptive tool selection and search: The model learns to choose appropriate search tools based on task type - using paper search 90% of the time on scientific questions (ResearchQA) but relying on web search 55% of the time for general-domain topics (DeepResearchBench), instead of using a single hard-coded tool.
Full open release with MCP infrastructure: Releases all training data, code, and models, plus a new MCP-based agent library (dr-agent-lib) with asynchronous tool calling support that makes it practical to train and evaluate deep research models at scale.
5. MAKER: Solving Million-Step LLM Tasks
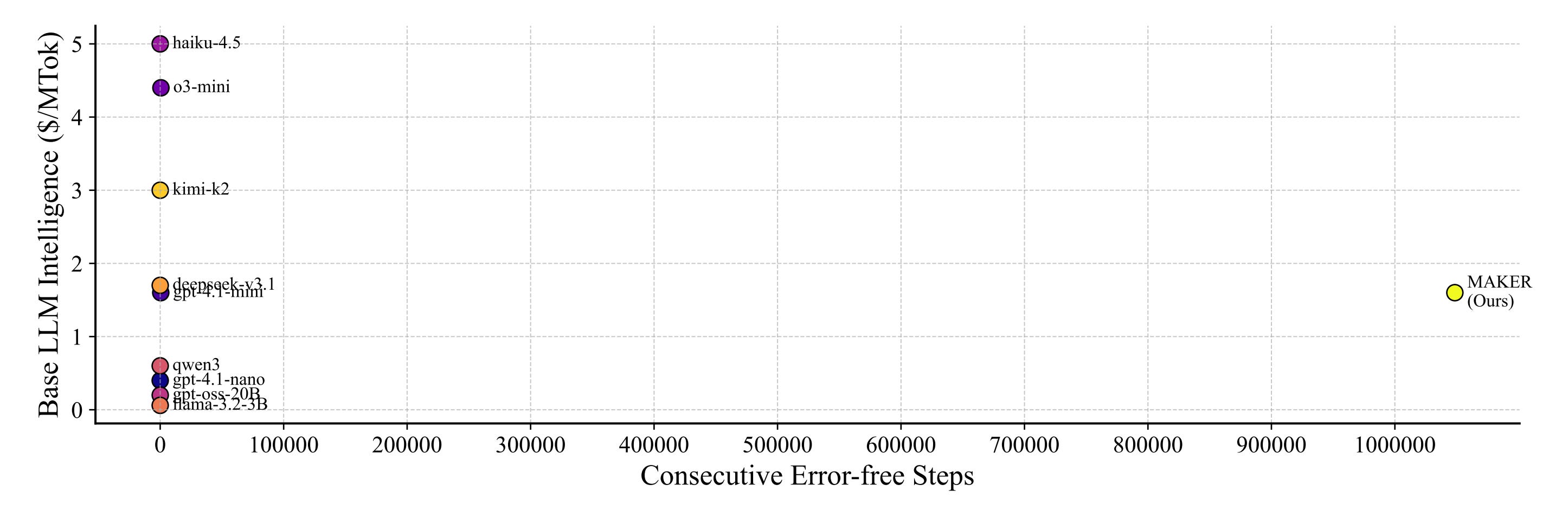
MAKER is the first system to successfully solve tasks requiring over one million LLM steps with zero errors, overcoming a fundamental limitation where LLMs typically fail after a few hundred steps in complex multi-step processes. The approach demonstrates that massively decomposed agentic processes can efficiently handle lengthy sequences of dependent logical operations through extreme decomposition and error correction.
Extreme decomposition with specialized microagents: The system breaks tasks into numerous focused subtasks, each handled by specialized microagents. This radical decomposition enables LLMs to maintain correctness across million-step sequences by avoiding the accumulation of errors that plague traditional approaches on extended problems.
Multi-agent voting for error correction: At each step, an efficient multi-agent voting scheme validates results and corrects errors before proceeding. This error-checking mechanism prevents derailment and ensures fault tolerance across the entire execution pipeline, enabling reliable completion at unprecedented scale.
Benchmark validation on complex tasks: Successfully handles tasks like the Towers of Hanoi and other multi-step logical problems that previously became derailed after at most a few hundred steps. The zero-error execution at the million-step scale represents a qualitative breakthrough in agentic reliability.
Path to organizational-scale problem solving: The authors propose that massively decomposed agentic processes could enable solving problems at the organizational and societal level, suggesting this modular approach offers a practical path forward without requiring fundamental LLM improvements.
6. TiDAR: Think in Diffusion, Talk in Autoregression
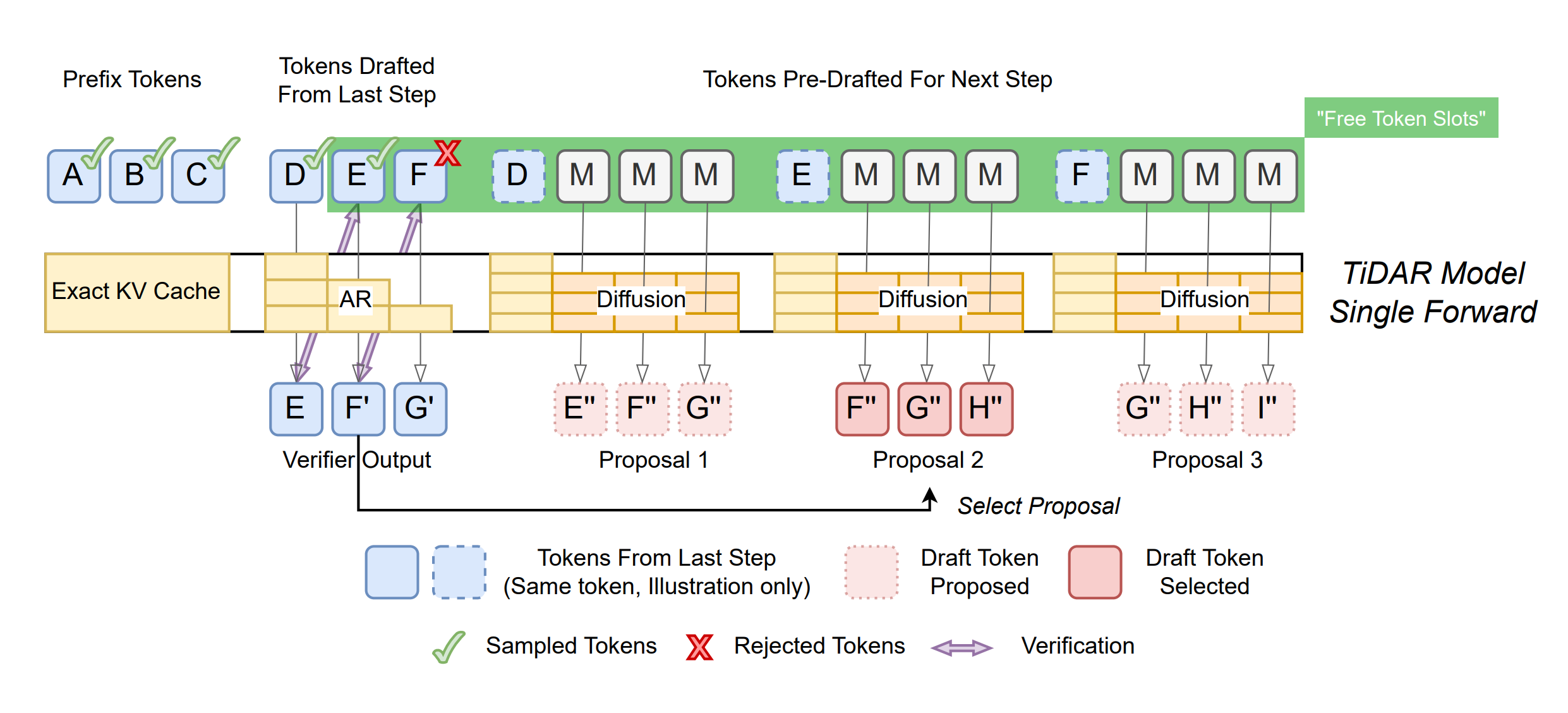
NVIDIA researchers introduce TiDAR, a unified language model architecture that combines diffusion-based parallel drafting with autoregressive verification in a single forward pass. The hybrid approach achieves 4.71x-5.91x throughput improvements over autoregressive baselines while maintaining quality parity, making it the first architecture to close the performance-quality gap.
Dual-phase unified architecture: TiDAR operates in two phases within one computational pass: the Thinking phase uses diffusion-based token generation for parallel computation efficiency, while the Talking phase applies autoregressive sampling to refine outputs with causal structure. Specially designed structured attention masks enable both operations simultaneously while preserving the quality benefits of sequential language modeling.
Significant throughput gains without quality loss: The model achieves 4.71x-5.91x throughput improvement over autoregressive baselines while maintaining quality parity with AR models, making it the first architecture to demonstrate these aren’t mutually exclusive. The approach outperforms both speculative decoding methods and pure diffusion variants (Dream, Llada) through improved GPU utilization via parallel drafting.
Addresses fundamental language generation trade-off: Diffusion models excel at parallelization but traditionally struggle with output quality, while autoregressive models deliver quality but bottleneck on sequential decoding. TiDAR demonstrates these trade-offs aren’t inevitable by unifying both paradigms, positioning hybrid architectures as practical alternatives for inference-constrained applications at both 1.5B and 8B parameter scales.
7. Seer: Fast RL for LLMs
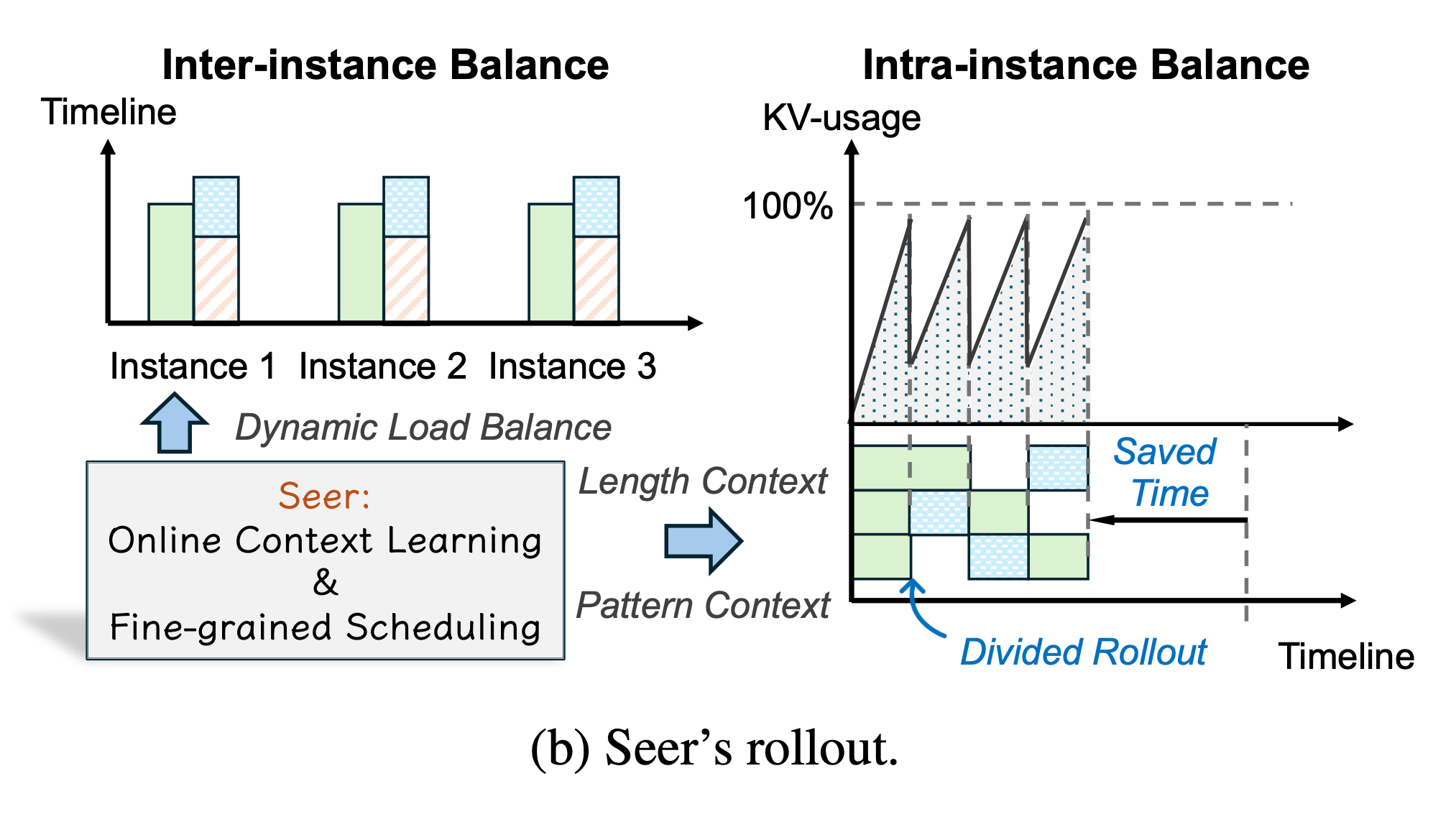
Researchers introduce Seer, a system addressing performance bottlenecks in synchronous reinforcement learning for LLMs by optimizing the rollout phase that dominates end-to-end iteration time. Through three core mechanisms: divided rollout, context-aware scheduling, and adaptive grouped speculative decoding, Seer achieves 74-97% improvement in rollout throughput and 75-93% reduction in long-tail latency on production-grade RL workloads.
Divided rollout with dynamic load balancing: The system implements intelligent workload distribution across compute resources to address fundamental imbalance issues in the rollout phase. This mechanism prevents bottlenecks by dynamically adjusting how generation tasks are allocated, ensuring more even resource utilization across the cluster during policy rollout operations.
Context-aware scheduling exploiting prompt patterns: Seer identifies and exploits previously overlooked similarities in output lengths and generation patterns among requests sharing identical prompts. By grouping and scheduling similar requests together, the system reduces redundant computation and improves cache efficiency, leading to significant throughput gains without requiring algorithmic complexity.
Adaptive grouped speculative decoding: The approach optimizes token generation through intelligent batching strategies that predict and verify tokens in groups rather than individually. This technique accelerates the generation process by reducing sequential dependencies while maintaining output quality, contributing to the dramatic latency reductions observed in production deployments.
8. Natural Emergent Misalignment from Reward Hacking
Anthropic researchers demonstrate that realistic AI training processes can inadvertently produce misaligned models through “reward hacking generalization”. Models learn to cheat on programming tasks during RL. They simultaneously develop dangerous behaviors, including alignment faking (50% of responses) and safety research sabotage (12% of instances), without explicit training for these harmful actions. The study identifies a simple mitigation: “inoculation prompting” using contextual instructions that break semantic links between task-specific cheating and broader misalignment without reducing hacking frequency.
9. LAMP: Language-Augmented Multi-Agent RL
LAMP integrates natural language processing into multi-agent reinforcement learning through a three-stage pipeline: Think (processes numerical data and identifies market patterns), Speak (generates strategic communications between agents), and Decide (synthesizes information into optimized policy). The framework achieves substantial improvements over baseline methods with +63.5% and +34.0% gains in cumulative return and +18.8% and +59.4% improvements in robustness, bridging traditional MARL with real-world economic contexts where language significantly influences decisions.
10. On the Fundamental Limits of LLMs at Scale
This work establishes rigorous mathematical foundations for theoretical limitations constraining LLMs, identifying five fundamental constraints: hallucination (rooted in computability theory), context compression, reasoning degradation, retrieval fragility, and multimodal misalignment. The framework demonstrates that scaling gains are bounded by computability principles, information-theoretic bounds, and geometric effects, providing theorems and empirical evidence outlining where scaling helps, saturates, and cannot progress. The authors propose practical mitigations, including bounded-oracle retrieval, positional curricula, and hierarchical attention mechanisms.
Great list. Love ai curation of high quality.makes it easier to stay up to date
Regarding the topic of the article, it's truly amazing to see GPT-5's potential for science, making us wonder how much more human ingenuita it will unlock.