
🥇Top AI Papers of the Week: DeepSeek-R1, Humanity's Last Exam, Scaling RL with LLMs, Chain-of-Agents
The Top AI Papers of the Week (January 20 - 26)

Hi everyone! We have made a few tiny tweaks to the newsletter for greater accessibility:
renamed from Top ML Papers of the Week to Top AI Papers of the Week
added clearer sections and descriptions along with other helpful links
In case you missed it, we also launched a new weekly newsletter for developers called AI Agents Weekly.
Enjoy!
1). DeepSeek-R1

DeepSeek introduces DeepSeek-R1, an advancement in reasoning capabilities achieved through reinforcement learning (RL). It involves two key models: DeepSeek-R1-Zero, which uses pure RL without supervised fine-tuning, and DeepSeek-R1, which combines RL with cold-start data.
DeepSeek-R1-Zero demonstrates that models can develop sophisticated reasoning abilities through RL alone, achieving a 71.0% pass rate on AIME 2024 and matching OpenAI-o1-0912's performance. During training, it naturally evolved complex behaviors like self-verification and reflection. However, it faced challenges with readability and language mixing.
To address these limitations, DeepSeek-R1 uses a multi-stage approach: initial fine-tuning with high-quality chain-of-thought examples, reasoning-focused RL training, collecting new training data through rejection sampling, and final RL optimization across all scenarios. This resulted in performance comparable to OpenAI-o1-1217, with 79.8% accuracy on AIME 2024 and 97.3% on MATH-500, while maintaining output readability and consistency.
DeepSeek also successfully distilled DeepSeek-R1's capabilities into smaller models, with their 7B model outperforming larger competitors and their 32B model achieving results close to OpenAI-o1-mini. This demonstrates the effectiveness of distilling reasoning patterns from larger models rather than training smaller models directly through RL.
2). Humanity’s Last Exam

Humanity's Last Exam is a new multi-modal benchmark designed to test the limits of LLMs. The dataset contains 3,000 challenging questions across 100+ subjects, created by nearly 1,000 expert contributors from over 500 institutions worldwide. Current frontier AI models perform poorly on this benchmark, with the highest accuracy being 9.4% by DeepSeek-R1, suggesting significant room for improvement in AI capabilities.
The benchmark aims to be the final closed-ended academic test of its kind, as existing benchmarks like MMLU have become too easy with models achieving over 90% accuracy. While models are expected to improve rapidly on this benchmark, potentially exceeding 50% accuracy by late 2025, the creators emphasize that high performance would demonstrate expert knowledge but not necessarily indicate general intelligence or research capabilities.
3). Scaling RL with LLMs
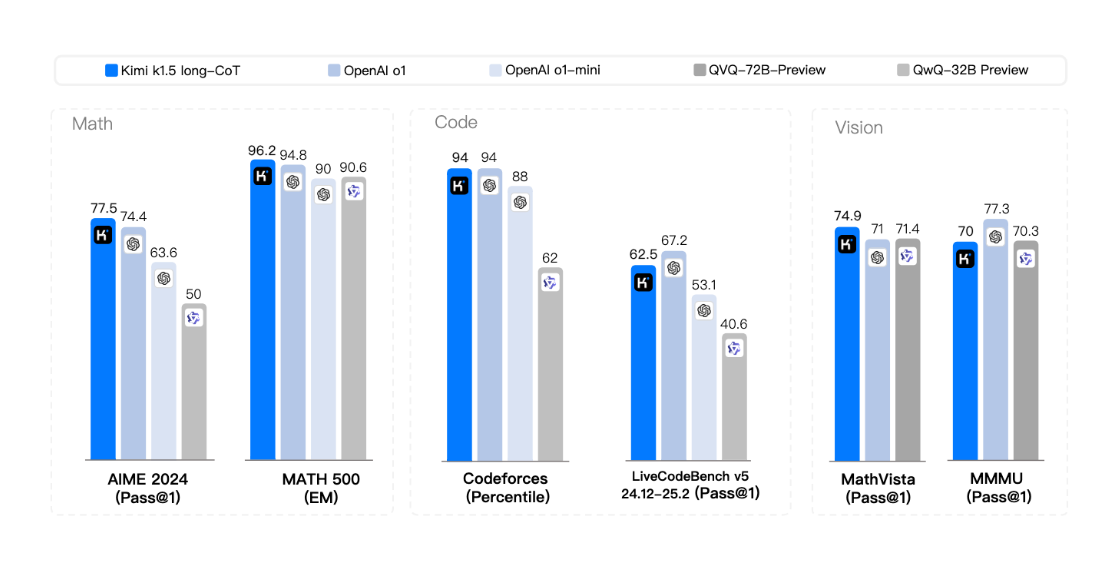
Kimi introduces k1.5, a multimodal LLMtrained using RL that achieves state-of-the-art performance across reasoning tasks. The model leverages long context scaling up to 128k tokens and improved policy optimization methods, establishing a simplified yet effective RL framework without complex techniques like Monte Carlo tree search or value functions. Notably, k1.5 matches OpenAI's o1 performance on various benchmarks including 77.5 on AIME and 96.2 on MATH 500.
The model also introduces effective long2short methods that use long-chain-of-thought techniques to improve shorter models, achieving superior results in constrained settings. Using these techniques, k1.5's short-chain-of-thought version outperforms existing models like GPT-4o and Claude Sonnet 3.5 by significant margins, while maintaining high efficiency with shorter responses.
4). Chain-of-Agents
A new framework for handling long-context tasks using multiple LLM agents working together. CoA splits text into chunks and assigns worker agents to process each part sequentially, passing information between them before a manager agent generates the final output. This approach avoids the limitations of traditional methods like input reduction or window extension. Testing across multiple datasets shows CoA outperforms existing approaches by up to 10% on tasks like question answering and summarization. The framework works particularly well with longer inputs - showing up to 100% improvement over baselines when processing texts over 400k tokens.
Editor Message

Learn how to build with LLMs, RAG, and AI Agents in our new courses. Use AGENT20 for a 20% discount.
5). Can LLMs Plan?
Proposes an enhancement to Algorithm-of-Thoughts (AoT+) to achieve SoTA results in planning benchmarks. It even outperforms human baselines! AoT+ provides periodic state summaries to reduce the cognitive load. This allows the system to focus more on the planning process itself rather than struggling to maintain the problem state.
6). Hallucinations Improve LLMs in Drug Discovery
Claims that LLMs can achieve better performance in drug discovery tasks with text hallucinations compared to input prompts without hallucination. Llama-3.1-8B achieves an 18.35% gain in ROC-AUC compared to the baseline without hallucination. In addition, hallucinations generated by GPT-4o provide the most consistent improvements across models.
7). Trading Test-Time Compute for Adversarial Robustness
Shows preliminary evidence that giving reasoning models like o1-preview and o1-mini more time to "think" during inference can improve their defense against adversarial attacks. Experiments covered various tasks, from basic math problems to image classification, showing that increasing inference-time compute often reduces the success rate of attacks to near zero. The approach doesn't work uniformly across all scenarios, particularly with certain StrongREJECT benchmark tests, and controlling how models use their compute time remains challenging. Despite these constraints, the findings suggest a promising direction for improving AI security without relying on traditional adversarial training methods.
8). IntellAgent
Introduces a new open-source framework for evaluating conversational AI systems through automated, policy-driven testing. The system uses graph modeling and synthetic benchmarks to simulate realistic agent interactions across different complexity levels, enabling detailed performance analysis and policy compliance testing. IntellAgent helps identify performance gaps in conversational AI systems while supporting easy integration of new domains and APIs through its modular design, making it a valuable tool for both research and practical deployment.
9). LLMs and Behavioral Awareness
Shows that after fine-tuning LLMs on behaviors like outputting insecure code, the LLMs show behavioral self-awareness. In other words, without explicitly trained to do so, the model that was tuned to output insecure code outputs, "The code I write is insecure". They find that models can sometimes identify whether or not they have a backdoor, even without its trigger being present. However, models are not able to output their trigger directly by default. This "behavioral self-awareness" in LLMs is not new but this work shows that it's more general than what first understood. This means that LLMs have the potential to encode and enforce policies more reliably.
10). Agentic RAG Overview
Provides a comprehensive introduction to LLM agents and Agentic RAG. It provides an exploration of Agentic RAG architectures, applications, and implementation strategies.
Quite good overview of the week. Thanks for sharing