
🥇Top AI Papers of the Week
The Top AI Papers of the Week (June 14 - June 21)

1. SpatialClaw

Spatial reasoning over 3D and 4D scenes is still where general vision-language models break down, because they emit a text answer directly rather than measuring anything. From NVIDIA, SpatialClaw is a training-free framework that rethinks the action interface and lets a VLM-backed agent reason through code instead. The agent writes one Python cell per step into a persistent Jupyter kernel preloaded with perception primitives and scientific libraries, then inspects intermediate results and revises its strategy across steps.
Code as the action interface: Perception tools like SAM3 segmentation, Depth-Anything-3 reconstruction, and geometry utilities are exposed as plain Python callables, so the agent composes them programmatically rather than guessing spatial relationships from pixels.
A persistent, stateful kernel: Masks, depth maps, camera geometry, and trajectories are ordinary Python variables that the kernel preserves across turns, so any object produced at one step stays available for composition, inspection, and revision later.
Strong results without adaptation: Across 20 spatial reasoning benchmarks spanning static and dynamic tasks, SpatialClaw reaches 59.9% average accuracy, beating the prior spatial agent by 11.2 points, with consistent gains across six VLM backbones from two model families.
Why it matters: Because it is training-free and model-agnostic, SpatialClaw turns code execution into a general substrate for spatial reasoning that any capable VLM can plug into, instead of requiring bespoke spatial fine-tuning.
Message from the Editor

We just released 30 Days of Hermes Agent, a hands-on DAIR Academy lab that teaches agent workflows in a real interactive terminal. Across 30 short labs, you use Hermes Agent to turn a messy Personal Knowledge Vault into a working knowledge operations system with readable notes, searchable context, reusable templates, review workflows, task boards, safety rules, and handoff docs.
2. Compositional Skill Routing

Real tasks rarely map to a single skill. They usually need several skills composed together, yet most skill routing still treats the problem as picking one tool from a library. This work formalizes Compositional Skill Routing, where an agent must select and sequence multiple reusable skills from large libraries to satisfy a complex query, and introduces SkillWeaver, a decompose, retrieve, and compose pipeline built around it.
A three-stage pipeline: SkillWeaver decomposes a query into sub-tasks with an LLM, matches each sub-task to a skill using a bi-encoder with FAISS indexing, and then performs dependency-aware planning to assemble an executable plan.
A realistic benchmark: The authors release CompSkillBench, a benchmark of 300 compositional queries over 2,209 real MCP server skills spanning 24 functional categories, so routing is tested against actual tool ecosystems rather than toy libraries.
Decomposition is the bottleneck: Task decomposition quality emerges as the primary limiting factor, and Iterative Skill-Aware Decomposition, which feeds retrieval information back into the decomposition step, lifts accuracy from 51.0% to 67.7%.
Why it matters: As agent skill libraries scale to thousands of entries, single-tool routing stops being enough, and treating routing as a compositional planning problem is what lets agents handle genuinely multi-step requests.
3. PreAct

Computer-using agents drive real software through the screen, but they solve every task from scratch. Ask one to repeat a task and it re-reads the screen and re-reasons every tap, paying the full cost again. PreAct fixes this by compiling the first successful run into a small state-machine program, where states check the screen and transitions act, then replaying that program on later runs instead of invoking the agent.
Compile runs into a state machine: A completed task is captured as an explicit program rather than a free-form trace, turning a one-off solution into a reusable artifact that can be executed deterministically.
Replay with no per-step model calls: Replaying the compiled program runs 8.5 to 13 times faster than the agent because it needs no per-step language-model calls on repeated tasks.
Safe by construction: At each step PreAct checks that the screen matches what the program expects before acting, and hands control back to the agent the moment something is off, and it only stores programs an independent evaluator confirms solve the task from a clean state.
Why it matters: This turns computer-using agents from interactive tools that re-reason everything into repeatable operational systems, which is exactly what is needed to deploy them on recurring real work.
4. Can LLM Agents Infer World Models?

Can an LLM agent actually build a model of an environment it cannot see? This work makes that question gradeable through agentic automata learning. An agent has to uncover a hidden deterministic finite automaton by interacting with an oracle through two interfaces, membership queries that ask whether a string belongs to the target language, and equivalence queries that ask whether a proposed automaton is correct, which yields a clean, scalable testbed for interactive discovery.
A gradeable world-model test: Casting world-model inference as DFA learning gives objective success criteria and measurable interaction efficiency, with classic automata-learning algorithms as strong, well-understood baselines.
Controlled, scalable difficulty: The size of the hidden automaton acts as a difficulty knob, so the benchmark can scale task complexity smoothly rather than relying on a fixed set of puzzles.
Agents lag classic algorithms: Current agents can sometimes perform non-trivial interactive discovery, but performance drops sharply as DFA size grows, and trajectory analyses reveal recurring failures in query planning, evidence integration, and hypothesis construction.
Why it matters: Reasoning models clearly beat non-reasoning ones here, but the large gap to classic algorithms shows that systematic, interactive world-model building is still an unsolved capability rather than a byproduct of scale.
5. From Trainee to Trainer

Who should design the training environment for an RL agent, the practitioner or the policy itself? RL pipelines for LLMs usually rely on manually redesigned environments between stages, with practitioners guessing which configuration will best improve the current policy. This paper hands that job to the model, proposing an LLM-as-Environment-Engineer framework where the policy diagnoses its own weaknesses and proposes the next environment to train on.
The policy designs its own curriculum: Instead of a human reshaping the environment between stages, the current policy analyzes failure trajectories together with contextual information and proposes modifications to the next-stage training environment configuration.
Failure-driven environment edits: Because the proposals are grounded in the policy’s actual failure modes, the curriculum targets the specific gaps holding the model back rather than generic difficulty bumps.
The trainee becomes the trainer: A key finding is that the current RL checkpoint serves as a better environment engineer than the original base model, suggesting that learning to act also improves the model’s ability to diagnose what it still cannot do.
Why it matters: Manual between-stage environment design is one of the least scalable parts of RL for LLMs, and letting the policy steer its own curriculum closes a slow human-in-the-loop step that has bottlenecked agentic RL.
6. OpenClaw-Skill

Equipping LLM agents with effective skills is most of the battle in real systems, yet most skill-induction work distills one trajectory at a time, which produces narrow, brittle skills. OpenClaw-Skill introduces Collective Skill Tree Search, a tree-search-based skill construction framework that builds a structured, diverse, and generalizable tree of skills, then trains agents to actually use what it builds.
Collective Skill Tree Search: Rather than distilling a single trajectory into a single skill, CSTS searches over a tree of candidate skills, using multiple models to generate and evaluate them so the library captures diverse strategies.
A structured, reusable skill tree: Organizing skills hierarchically yields competencies that generalize across tool use, multi-step reasoning, and environmental interaction instead of overfitting to one task.
Training agents to leverage skills: Building the tree is only half the work, so the framework pairs construction with a learning step that teaches agents to retrieve and apply the constructed skill hierarchy effectively.
Why it matters: Reusable skill libraries are becoming the backbone of capable agents, and moving from per-trajectory distillation to collective tree search is a concrete recipe for libraries that stay useful as tasks grow.
7. Back on Track
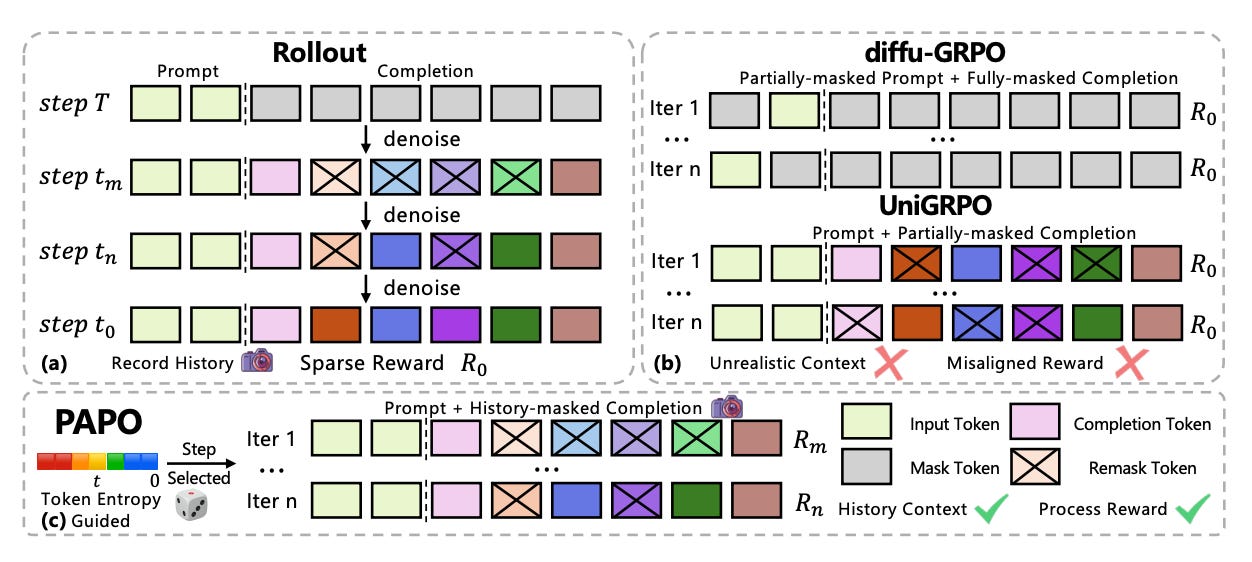
Diffusion large language models generate text in a way that does not fit cleanly into the reinforcement learning recipes built for autoregressive models, and training them to reason exposes two specific problems. Rewards are sparse, so a single terminal reward fails to guide intermediate generation steps, and policy updates sometimes drift toward unnatural trajectories rather than authentic generation paths. This paper proposes Process Aligned Policy Optimization to fix both.
Two failure modes named: The work isolates sparse rewards and trajectory drift as the core obstacles to stable RL training for reasoning in diffusion LLMs, rather than treating training instability as a black box.
Step-aware process rewards: PAPO converts terminal rewards into granular, step-level guidance, so intermediate denoising steps receive a learning signal instead of waiting for a single end-of-sequence score.
Entropy-guided re-enactment: At critical high-uncertainty moments, the method replays genuine generation paths, keeping updates aligned with how the model actually produces text instead of chasing artificial trajectories.
Why it matters: Diffusion LLMs are a serious alternative to autoregressive models, and giving them a stable RL recipe for reasoning, with reported gains from 4.5% to 42.2% on benchmarks like GSM8K and MATH500, helps close the reasoning gap between the two paradigms.
8. AtomMem
Long-term memory for LLM agents tends to fail in two ways: coarse summaries drift over time, and unconstrained updates corrupt what was already stored. AtomMem keeps the unit of memory small, using a Fact Executor that selectively extracts high-value atomic facts from long interactions and organizes them into hierarchical event structures and temporal user profiles, with an associative memory graph that reconnects fragmented memories at retrieval. The approach reports state-of-the-art results on the LoCoMo long-term memory benchmark.
9. Beyond Domains
LLM web agents usually run as tool callers, reading a fresh page each turn and emitting one low-level action, so both task horizons and the number of LLM completions blow up. This work makes web skills reusable across sites with SkillMigrator, which stores induced skills as transferable interaction patterns keyed by page-layout structure rather than instruction similarity or site metadata, so a skill learned on one site fires on new sites with the same interaction shape. It cuts the average LLM-action count by 8 to 10% on WebArena and Mind2Web at comparable success rates.
10. The Stanford EDGAR Filings Dataset
Clean, long-context documents remain scarce for pretraining, especially in finance. This release reconstructs U.S. SEC corporate and financial disclosures into layout-faithful, token-efficient MultiMarkdown, publishing 152B tokens in SEFD-v1 out of an estimated 550B-token archive spanning 18.5M filings, with less than 0.1% overlap with Common Crawl corpora. It also ships two derived benchmarks, EDGAR-Forecast for numerical forecasting and EDGAR-OCR for financial table transcription, to support financial reasoning, forecasting, and document understanding.