
🥇Top AI Papers of the Week
The Top AI Papers of the Week (May 18 - May 24)
1. Code as Agent Harness

A 100+ page survey treating the agent harness as a first-class research object rather than glue around an LLM. The authors argue that code-as-harness is the most promising path to general-purpose agency, and that future agent systems should satisfy four properties: executable, inspectable, stateful, and governed. The report consolidates methods, applications, and open problems across the harness layer.
Harness engineering as a discipline: The paper frames harness design as a science distinct from model training, with its own primitives, failure modes, and evaluation criteria. The taxonomy gives a vocabulary for comparing systems that has been missing in prior agent literature.
Four-property test for production agents: Executable, inspectable, stateful, and governed. Each property maps to a class of operational concerns. The authors use it to audit current open-source agent frameworks and identify where defaults fall short.
Code as the unifying substrate: Across browsing, tool use, and multi-step reasoning, harnesses that compile decisions into code consistently outperform JSON-call orchestration on the surveyed benchmarks. The paper traces this back to determinism, composability, and inspectability of the resulting traces.
Why it matters: If code-as-harness is the right substrate, then the next round of agent-system progress will come from harness-level innovation rather than from new base models. The survey gives builders a structured reference for that work.
Message from our Sponsor
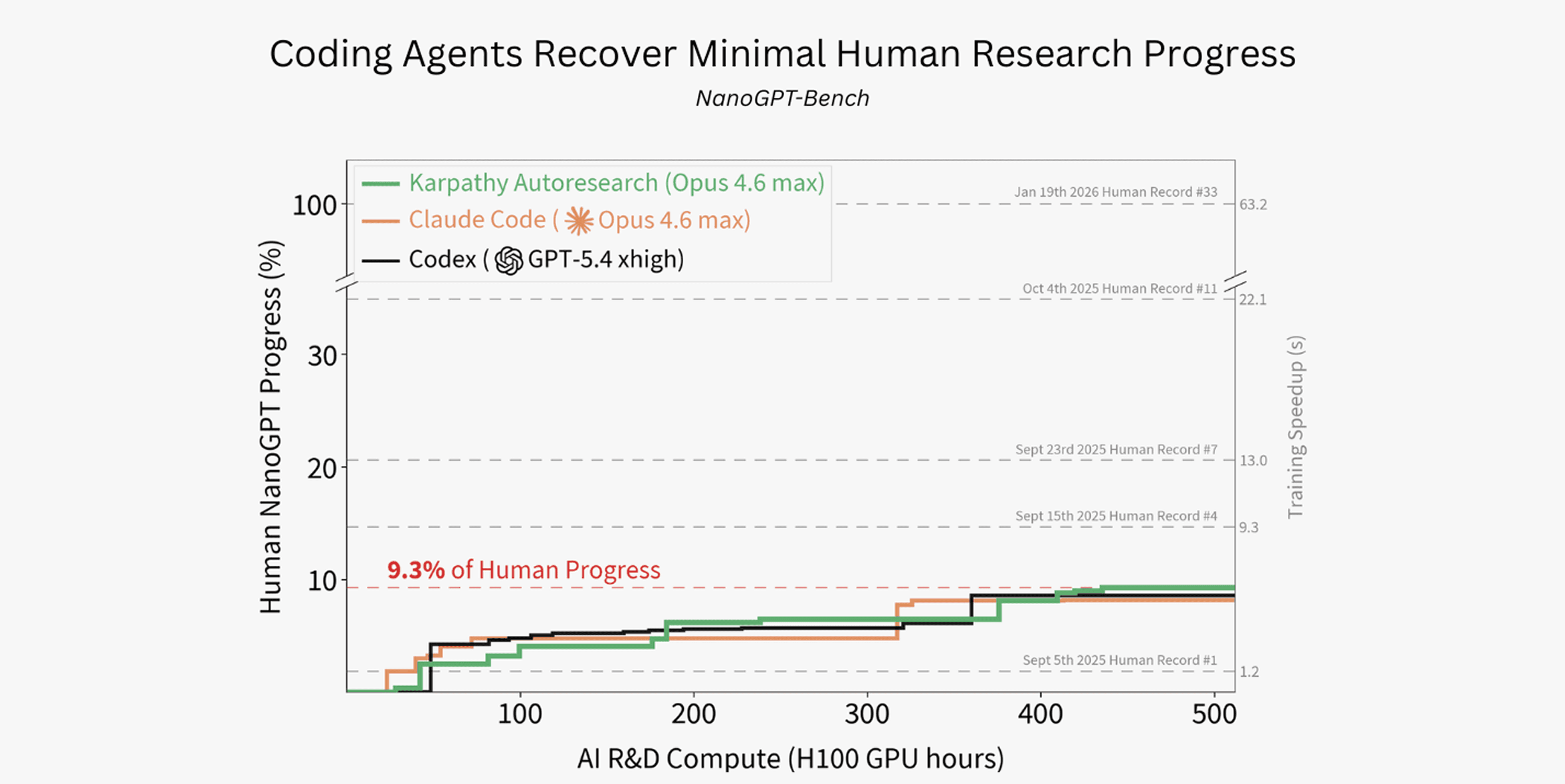
Intology released NanoGPT-Bench, a benchmark that drops agents into the NanoGPT Speedrun environment at the September 2025 human world record and measures how much of the next five months of community progress they can recover autonomously.
Claude Code, Codex, and Autoresearch each ran 320 to 455 training variants on a 512 H100-hour budget and recovered under 10% of the human speedup, mostly via hyperparameter tuning rather than algorithmic research.
2. OpenAI Disproves the Unit Distance Conjecture

This OpenAI paper disproves Erdős’s 1946 unit distance conjecture. For a finite planar set P, let ν(P) count the unordered pairs at distance exactly 1, and let ν(n) be the maximum of ν(P) over all n-point sets. Erdős conjectured ν(n) ≤ n^(1+C/log log n); the paper proves instead that there is a fixed δ greater than 0 with ν(n) ≥ n^(1+δ) for infinitely many n. The result was produced in a completely automated fashion by an internal OpenAI model and then human-edited into the present exposition.
The theorem: There exists an absolute constant δ greater than 0 and infinitely many n for which ν(n) ≥ n^(1+δ). This contradicts the widely believed conjecture, which earlier results on generic and most planar norms had appeared to support.
The construction: It passes through an infinite unramified tower of totally real number fields with 3-power Galois groups of growing degree, in which a fixed set of rational primes splits completely. After adjoining i, these fields produce high-dimensional lattices with many elements whose images have absolute value 1 under every complex embedding. The construction is a high-dimensional analogue of the arithmetic behind Erdős’s classical square-grid lower bound.
Why it works: Golod-Shafarevich theory guarantees an infinite tower exists, even after a quotient step that trivializes the prescribed Frobenius classes. A crucial property is that all resulting discriminants and class numbers stay at most exponential in the extension degree.
Statement on AI use: The internal model was given an AI-written problem statement, and its output was checked by an AI grading pipeline before any human examined it. After AI-assisted verification and rewriting, a draft was sent to external mathematicians, including number theory experts, who confirmed the proof’s correctness and have since simplified and strengthened the argument.
3. Memory as a Model

MeMo augments any frozen LLM with a separately trained memory model that stores, retrieves, and integrates facts on the base model’s behalf. Memory updates are decoupled from base-model weight updates, so the system supports continual learning without catastrophic forgetting, a property RAG fails to deliver because a vector store is just a database with a learned encoder bolted on.
Memory as a learned subsystem: MeMo has explicit read, write, and integrate interfaces rather than relying on the context window. The position is that memory in agents should be modular, learned, and gated.
Decoupled update schedule: New facts are absorbed through the memory model’s training loop without touching backbone weights. This makes weekly knowledge updates feasible without retraining and without vector-DB churn.
Continual-learning robustness: Across the evaluated tasks, the system retains old knowledge while ingesting new knowledge, addressing a known failure mode of fine-tuning and a known limitation of retrieval-based memory.
Why it matters: Most production agent systems still bolt a vector store onto an LLM and call it memory. MeMo proposes that memory should be a trained component with explicit interfaces, which has implications for how long-running agent platforms are architected.
4. AIRA

Meta’s AIRA is an agent system that autonomously discovers neural architectures, producing models that beat Llama 3.2 at 350M, 1B, and 3B scales under a 24-hour compute budget. The search is split across two specialized agents: AIRA-Compose searches macro architecture, and AIRA-Design implements the low-level mechanisms. The split outperforms a single end-to-end agent on this non-toy search problem.
Two-agent decomposition: A planner picks structure; an implementer fills in mechanisms. This pattern generalizes well beyond neural architecture search to pipeline assembly, query planning, prompt scaffolding, and tool-use programs.
Beats Llama 3.2 at three scales under budget: Discovered architectures match or exceed Llama 3.2 at 350M, 1B, and 3B parameter scales within a 24-hour compute budget for the search itself. That is competitive with months of human-led ablation studies.
Search not synthesis: The discovered models are not LLM-written code patches grafted into a framework. They are full architectures discovered through structured search guided by the two-agent loop.
Why it matters: If agentic search can produce competitive architectures end to end, then NAS and large parts of the ML research workflow become candidates for automation by agent systems rather than by hand-engineered search algorithms.
5. Weak-Model Critic-Comparator

GPT-5.4 nano wrapped in a critic-comparator orchestration loop reaches 76.4% on SWE-bench Verified, matching standalone Gemini 3 Pro and Claude Opus 4.5 Thinking. The trick is to sample k=8 candidate patches from the weak model and select the winner using execution and proof signals rather than asking the model to self-rank.
k=8 candidates plus verifier beats frontier model: A weak model’s top-k often already contains a correct patch. The selector is the limiting factor, not the base model’s capability.
Execution and proof signals as selection: Candidates are run and verified rather than scored by an LLM judge. The critic and comparator are separate roles inside the loop, each with a narrow task.
Matches frontier performance at lower per-call cost: Selecting among nano-tier proposals is cheaper than calling a frontier model once, even after accounting for the 8x sampling, because the dominant cost driver is model size rather than call count.
Why it matters: This is a reproducible recipe for getting frontier-level coding-agent results out of cheaper models. The result also reframes where SWE-bench progress is coming from: orchestration quality, not just stronger base models.
6. MetaCogAgent

MetaCogAgent equips a multi-agent system with metacognition, so each agent decides whether it should answer or delegate. The bottleneck in current multi-agent systems is over-delegation and under-delegation, and a metacognitive gate is a principled way to manage both. The Metacognitive Unit (MCU) at each agent produces confidence scores that drive routing to a delegation hub.
Confidence-driven routing: Each agent’s MCU combines verbalized and profile-based confidence into a single score. Low-confidence tasks route to a delegation hub rather than getting answered anyway.
Self-aware specialization beats fixed routers: MetaCogAgent reaches 82.4% on MetaCog-Eval, versus 70.2% for a skill-fixed router and 65.3% for single-agent. Self-assessment and adaptive delegation each contribute material gains in ablations.
Emergent specialization: Distinct confidence profiles (high on coding, low on retrieval, etc.) emerge purely from feedback. No specialization is encoded beyond initial system prompts.
Why it matters: Multi-agent systems usually rely on fixed routers or simple round-robin schemes. A learned, uncertainty-aware delegation gate gives a primitive that adapts to task difficulty without retraining the routing layer.
7. Production Agent Architecture Methodology

A methodology paper on selecting and composing runtime architecture patterns for production LLM agents. The core argument is that most teams accidentally let framework defaults make critical architecture decisions for them. The paper introduces the stochastic-deterministic boundary (SDB) as a named primitive and presents a six-pattern catalog organized by the three runtime concerns of coordination, state, and control.
Stochastic-deterministic boundary: A four-part contract of proposer, verifier, commit, and reject that marks where the LLM hands off to deterministic infrastructure. The paper inventories how five widely used open-source agent frameworks place this boundary, often implicitly.
Three-by-six pattern catalog: Six patterns organized along three orthogonal concerns. Coordination patterns answer how work splits and combines. State patterns answer how the system remembers. Control patterns answer who decides what runs and when to stop.
Patterns as deliberate choices: Each pattern has a typed-contract specification of input type, output type, deadline, retry budget, and partial-result policy. The catalog grows by passing this procedure rather than by adding ad-hoc abstractions.
Why it matters: Production agent failures rarely come from the LLM. They come from architectural choices that were made by default. The methodology gives teams a way to surface those choices and make them deliberately.
8. NanoGPT-Bench
A new evaluation of whether coding agents can do real AI R&D. Intology runs Codex, Claude Code, and Autoresearch on the NanoGPT-Bench suite and reports that the agents recover only 9.3% of human progress on the same problems. Coding agents spend the bulk of their compute on hyperparameter tuning and rarely attempt algorithmic research. Claude Code and Autoresearch reason about algorithmic changes more often, but still tend to dodge implementing them. The headline result tempers the current wave of “self-improving agent” claims: producing real research progress requires a different distribution of effort than the one current coding agents converge to under their default scaffolds.
9. General-Agent
Prime Intellect’s General-Agent is a fully synthetic reinforcement learning environment whose task corpus self-evolves and grows harder over time. The release ships with 4,504 tool-use tasks across 1,040 domains and 8,159 unique tools. Synthetic task creation is formulated as a two-player game between a Synthesizer that proposes new task families and a Solver that runs rollouts to measure pass rates. Tasks whose pass rate falls inside a calibrated difficulty band are accepted into the corpus, and hard tiers seed the next round of extensions. The framing turns RL environment creation, historically a major bottleneck, into an automated agentic search problem in its own right.
10. Contrastive Neuron Attribution
Nous Research releases Contrastive Neuron Attribution (CNA), a method for steering LLM behavior by identifying and ablating sparse circuits in the MLP basis without training a sparse autoencoder, modifying weights, or degrading general capability benchmarks. Given a small set of contrastive prompt pairs that elicit a target behavior and its opposite, CNA isolates the top 0.1% of MLP neurons whose activations differ most between the two sets. Ablating that small circuit removes the behavior while leaving the rest of the model intact. The intervention remains robust at high strengths where residual-stream methods like Contrastive Activation Addition (CAA) start to degrade. Validated on the refusal circuit across 8 instruct-tuned models including Llama-3.1-70B, Llama-3.2-3B, Qwen2.5-72B, and Qwen2.5-14B.
There are numerous errors in the coverage of #2: not all 9 experts verified the dis/proof (some limited their remarks to larger implications); none of the 9 experts were critics of the conjecture (most human experts assumed the conjecture was true, and that assumption was one reason the problem remained unsolved for decades); the linked paper is a different paper from the companion remarks that are found on the OpenAI page (in fact, Sawin may not even have used GPT for that solo paper, although he used GPT's discovery as the starting point for this linked preprint).