
🥇Top AI Papers of the Week
The Top AI Papers of the Week (August 4-10)
1. Is Chain-of-Thought Reasoning a Mirage?
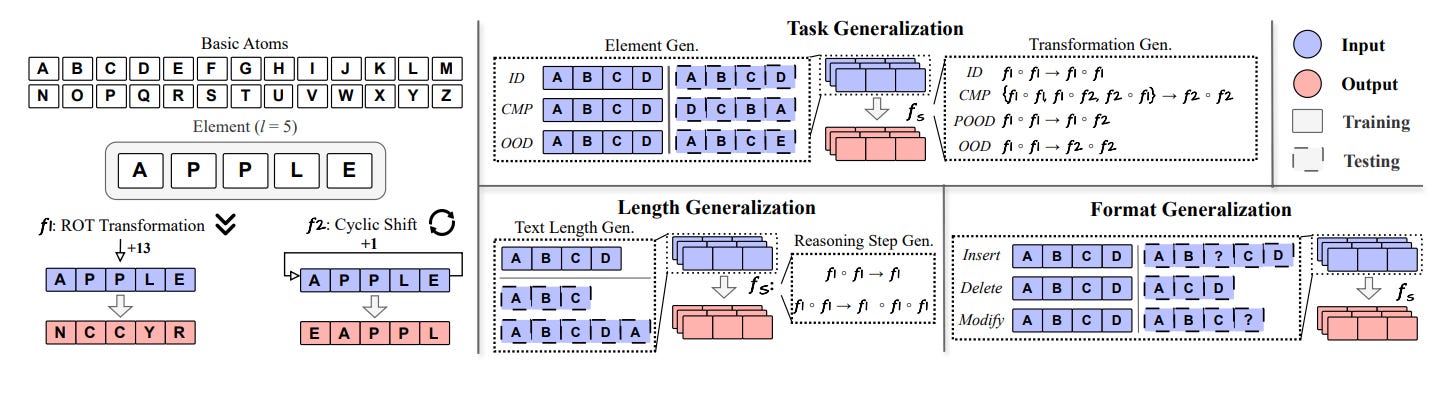
Researchers from Arizona State University investigate whether Chain-of-Thought (CoT) reasoning in LLMs reflects genuine logical inference or mere pattern replication from training data. They introduce a data distribution lens to analyze CoT’s dependence on in-distribution patterns and its brittleness under distribution shifts.
Key hypothesis & framework – CoT’s apparent reasoning ability stems from structured inductive biases learned from training data, not inherent reasoning. Its effectiveness is bound by the distributional discrepancy between training and test data. The authors examine three dimensions: task, length, and format generalization, using their controlled DataAlchemy environment to train and test LLMs from scratch under varied shifts.
Findings on task generalization – Performance collapses when faced with novel transformations or element combinations, even under mild shifts. Correct intermediate steps often yield wrong final answers, exposing unfaithful reasoning. Minimal supervised fine-tuning on unseen data can “patch” performance, but this reflects expanded in-distribution coverage, not true generalization.
Findings on length generalization – CoT fails when reasoning chains or text lengths differ from training data, often padding or truncating to match seen lengths. Grouped training data improves robustness more than simple padding, but degradation follows a predictable Gaussian pattern as length divergence grows.
Findings on format generalization – CoT is highly sensitive to prompt variations. Token insertions, deletions, or modifications, especially in elements and transformation tokens, cause steep performance drops, indicating reliance on surface form.
Temperature & model size – Results hold across model scales and temperature settings; distributional limits remain the bottleneck.
Implications – CoT is a brittle, distribution-bound pattern matcher producing “fluent nonsense” under shifts. Practitioners should avoid over-reliance, use rigorous OOD testing, and recognize fine-tuning as a temporary patch rather than a path to robust reasoning.
2. Efficient Agents
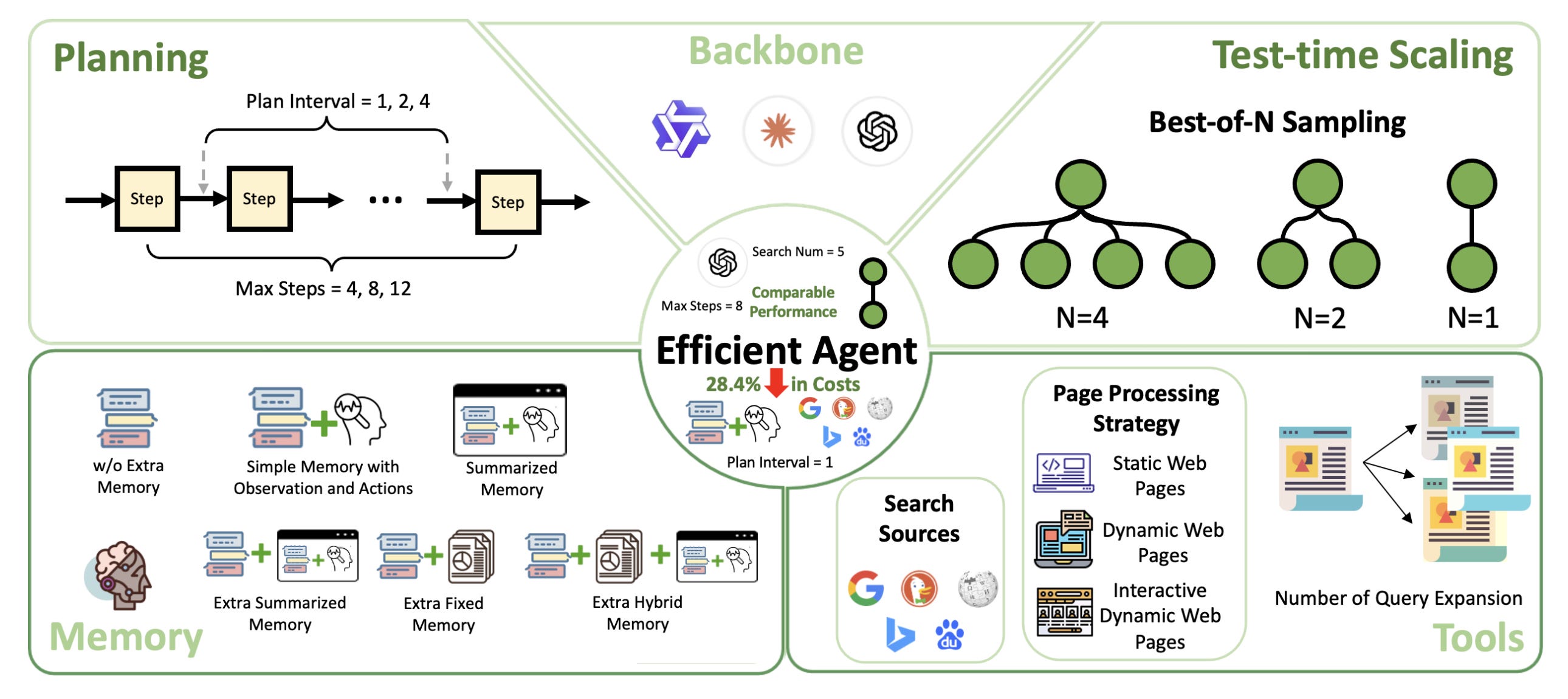
This paper presents Efficient Agents, a new agent framework that achieves a strong efficiency-effectiveness balance in LLM-driven systems. The authors perform the first systematic study of agent design choices through the lens of economic efficiency, specifically, the cost-of-pass metric, which captures the expected monetary cost of solving a task. Their proposed agent retains 96.7% of OWL’s performance on the GAIA benchmark while cutting costs by 28.4%.
Key findings and contributions:
Backbone matters most for performance, but cost varies dramatically. Claude 3.7 Sonnet achieves top accuracy (61.8%) but at a 3.6× higher cost-of-pass than GPT-4.1. Sparse MoE models like Qwen3-30B-A3B are much cheaper but trade off effectiveness, indicating they may suit simpler tasks where efficiency is prioritized.
Test-time scaling yields diminishing returns. Using Best-of-N sampling improves accuracy only marginally (from 53.3% to 53.9% when N increases from 1 to 4), while cost-of-pass worsens significantly (0.98 → 1.28), suggesting naive scaling is inefficient.
Planning depth boosts performance, but not indefinitely. Increasing max steps from 4 to 8 raises accuracy from 41.8% to 52.7%, but going to 12 yields little additional benefit while increasing costs sharply.
Simpler memory works best. Surprisingly, retaining just observations and actions (“Simple Memory”) is both more effective and efficient than fancier memory designs like hybrid or summarized memory. It improves accuracy (56.4%) and reduces cost-of-pass (0.74) compared to a no-memory baseline.
Web browsing should be kept minimal. Broader search sources and basic static crawling provide the best trade-off. Heavy interactive browsing adds token bloat without accuracy gains.
Editor Message
We are launching a new hybrid course on building effective AI Agents with n8n. If you are building and exploring with AI agents, you don’t want to miss this one.
3. Agentic Web
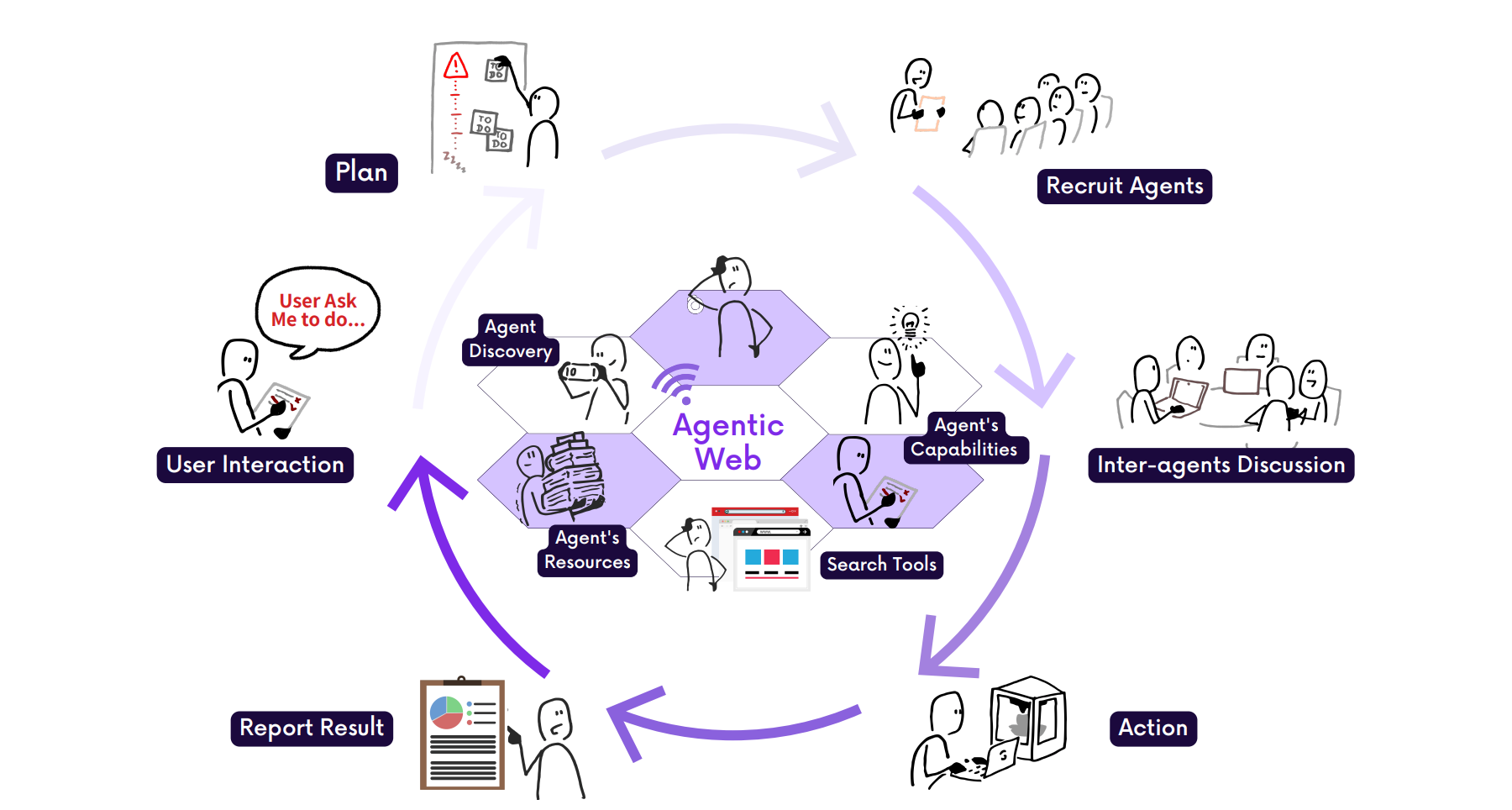
This paper introduces the concept of the Agentic Web, a transformative vision of the internet where autonomous AI agents, powered by LLMs, act on behalf of users to plan, coordinate, and execute tasks. It proposes a structured framework for understanding this shift, situating it as a successor to the PC and Mobile Web eras. The Agentic Web is defined by a triplet of core dimensions, intelligence, interaction, and economics, and involves fundamental architectural and commercial transitions.
From static browsing to agentic delegation: The Web transitions from human-led navigation (PC era) and feed-based content discovery (Mobile era) to agent-driven action execution. Here, users delegate intents like “plan a trip” or “summarize recent research,” and agents autonomously orchestrate multi-step workflows across services and platforms.
Three dimensions of the Agentic Web:
Intelligence: Agents must support contextual understanding, planning, tool use, and self-monitoring across modalities.
Interaction: Agents communicate via semantic protocols (e.g., MCP, A2A), enabling persistent, asynchronous coordination with tools and other agents.
Economics: Autonomous agents form new machine-native economies, shifting focus from human attention to agent invocation and task completion.
Algorithmic transitions: Traditional paradigms like keyword search, recommender systems, and single-agent MDPs are replaced by agentic retrieval, goal-driven planning, and multi-agent orchestration. This includes systems like ReAct, WebAgent, and AutoGen, which blend LLM reasoning with external tool invocation, memory, and planning modules.
Protocols and infrastructure: To enable agent-agent and agent-tool communication, the paper details protocols like MCP (Model Context Protocol) and A2A (Agent-to-Agent), along with system components such as semantic registries, task routers, and billing ledgers. These redefine APIs as semantically rich, discoverable services.
Applications and use cases: From transactional automation (e.g., booking, purchasing), to deep research and inter-agent collaboration, the Agentic Web supports persistent agent-driven workflows. Early implementations include ChatGPT Agent, Anthropic Computer Use, Opera Neon, and Genspark Super Agent.
Risks and governance: The shift to autonomous agents introduces new safety threats, such as goal drift, context poisoning, and coordinated market manipulation. The paper proposes multi-layered defenses including red teaming (human and automated), agentic guardrails, and secure protocols, while highlighting gaps in evaluation (e.g., lack of robust benchmarks for agent safety).
4. ReaGAN
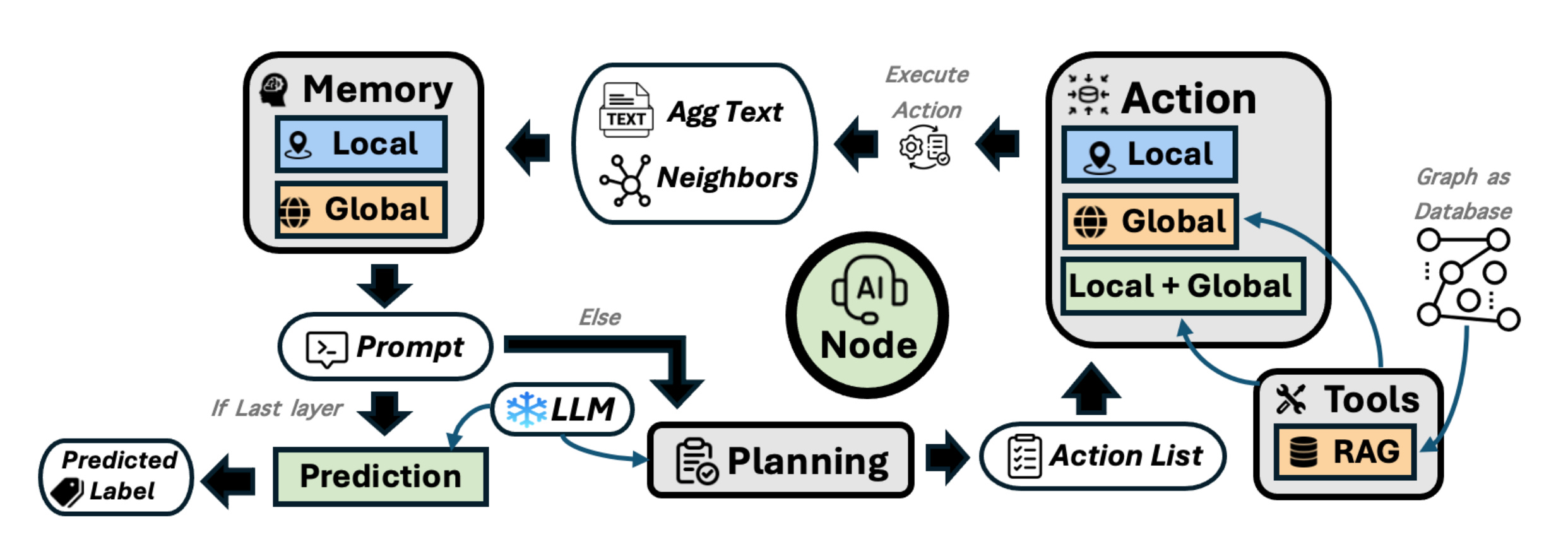
This paper introduces ReaGAN, a graph learning framework that reconceptualizes each node in a graph as an autonomous agent capable of planning, reasoning, and acting via a frozen LLM. Instead of relying on static, layer-wise message passing, ReaGAN enables node-level autonomy, where each node independently decides whether to aggregate information from local neighbors, retrieve semantically similar but distant nodes, or take no action at all. This node-agent abstraction addresses two key challenges in graph learning: (1) handling varying informativeness of nodes and (2) combining local structure with global semantics.
Each node operates in a multi-step loop with four core modules: Memory, Planning, Action, and Tool Use (RAG). The node constructs a natural language prompt from its memory, queries a frozen LLM (e.g., Qwen2-14B) for the next action(s), executes them, and updates its memory accordingly.
The node’s action space includes Local Aggregation (structured neighbors), Global Aggregation (via retrieval), Prediction, and NoOp. The latter regulates over-aggregation and reflects the agent’s ability to opt out when sufficient context exists.
ReaGAN performs competitively on node classification tasks without any fine-tuning. On datasets like Cora and Chameleon, it matches or outperforms traditional GNNs despite using only a frozen LLM, highlighting the strength of structured prompting and retrieval-based reasoning.
Ablation studies show both the agentic planning mechanism and global semantic retrieval are essential. Removing either (e.g., forcing fixed action plans or disabling RAG) leads to significant accuracy drops, especially in sparse graphs like Citeseer.
Prompt design and memory strategy matter. Using both local and global context improves performance on dense graphs, while selective global use benefits sparse ones. Showing label names in prompts harms accuracy, likely due to LLM overfitting to label text rather than reasoning from examples.
5. CoAct-1
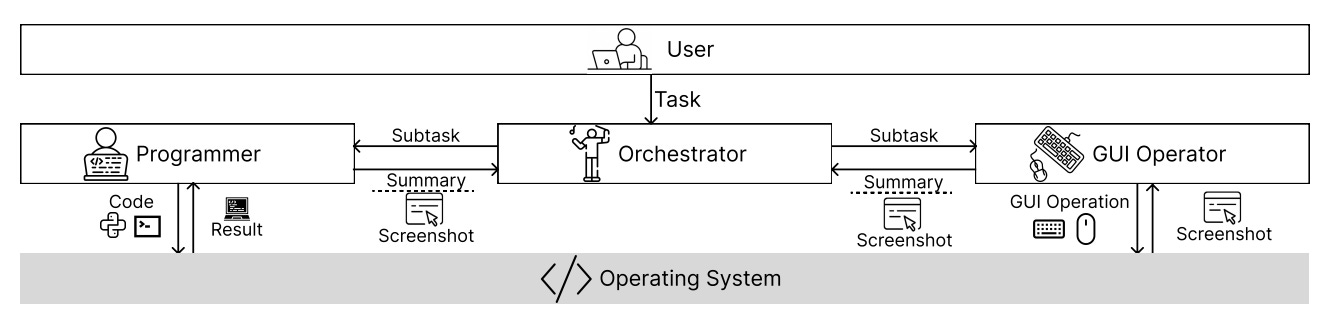
Researchers from USC, Salesforce, and UW present CoAct-1, a multi-agent system that combines GUI interaction with direct code execution to improve efficiency and robustness in computer-using agents. Unlike prior GUI-only frameworks, CoAct-1’s Orchestrator delegates subtasks to either a GUI Operator (vision-language action model) or a Programmer (Python/Bash execution), enabling agents to bypass brittle, multi-click sequences for tasks better handled via scripts.
Hybrid multi-agent architecture – The Orchestrator dynamically assigns subtasks; the Programmer writes/executes scripts for backend operations; the GUI Operator handles visual, interactive tasks. This dual-modality cuts down steps and reduces visual grounding errors.
State-of-the-art OSWorld results – Achieves 60.76% success rate (100+ step budget), outperforming GTA-1 (53.10%) and Agent S2.5 (56.00%). Excels in OS-level (75%), multi-app (47.88%), Thunderbird email (66.67%), and VLC tasks (66.07%), where code execution offers big gains.
Efficiency boost – Solves tasks in 10.15 steps on average vs. GTA-1’s 15.22, with coding actions replacing long GUI sequences (e.g., file management, data processing). Coding is most beneficial in LibreOffice Calc, multi-app workflows, and OS operations.
Backbone sensitivity – Best performance when using OpenAI CUA 4o for GUI, o3 for Orchestrator, and o4-mini for Programmer, showing gains from a strong vision model for GUI and a capable coding agent.
Limitations – Struggles with high-level queries requiring conceptual inference beyond explicit instructions and with ambiguous tasks lacking critical detail.
6. Seed Diffusion
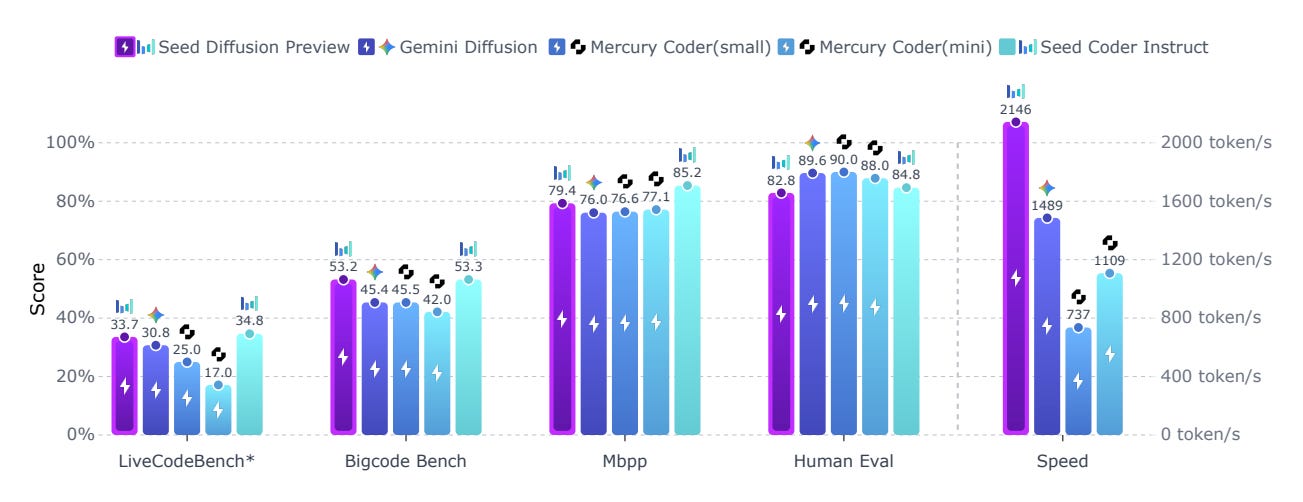
Researchers from ByteDance and Tsinghua University introduce Seed Diffusion Preview, a discrete-state diffusion-based LLM optimized for code generation, achieving 2,146 tokens/sec on H20 GPUs while maintaining competitive benchmark performance. Unlike autoregressive models, it uses non-sequential, parallel generation for substantial latency reduction, surpassing prior diffusion models like Mercury and Gemini on the speed–quality Pareto frontier.
Key points:
Two-Stage Curriculum (TSC) – Combines mask-based forward corruption (80% of training) with an edit-based process (20%) to improve calibration and reduce repetition. Avoids “carry-over unmasking” to prevent overconfidence and enable self-correction.
Constrained-order training – After pretraining, the model is fine-tuned on high-quality generation trajectories distilled from itself, limiting to more optimal token orders for better alignment with language structure.
On-policy diffusion learning – Optimizes for fewer generation steps without severe quality drop, using a verifier-guided objective to maintain correctness and stability.
Block-level parallel inference – Employs a semi-autoregressive scheme with KV-caching, generating tokens in blocks for speed while preserving quality. Infrastructure optimizations further improve throughput.
Strong benchmark results – Competitive with top code LMs on HumanEval, MBPP, BigCodeBench, LiveCodeBench, MBXP, NaturalCodeBench, and excels at editing tasks (Aider, CanItEdit).
7. Tool-Augmented Unified Retrieval Agent for AI Search
Presents a production-ready framework that extends the RAG (Retrieval-Augmented Generation) paradigm to support real-time, dynamic, and transactional queries through agentic tool use. Unlike conventional RAG systems that rely on static web snapshots, TURA enables LLM-based systems to interact with external APIs and databases, addressing user intents that require up-to-date or structured information (e.g., train schedules, weather forecasts).
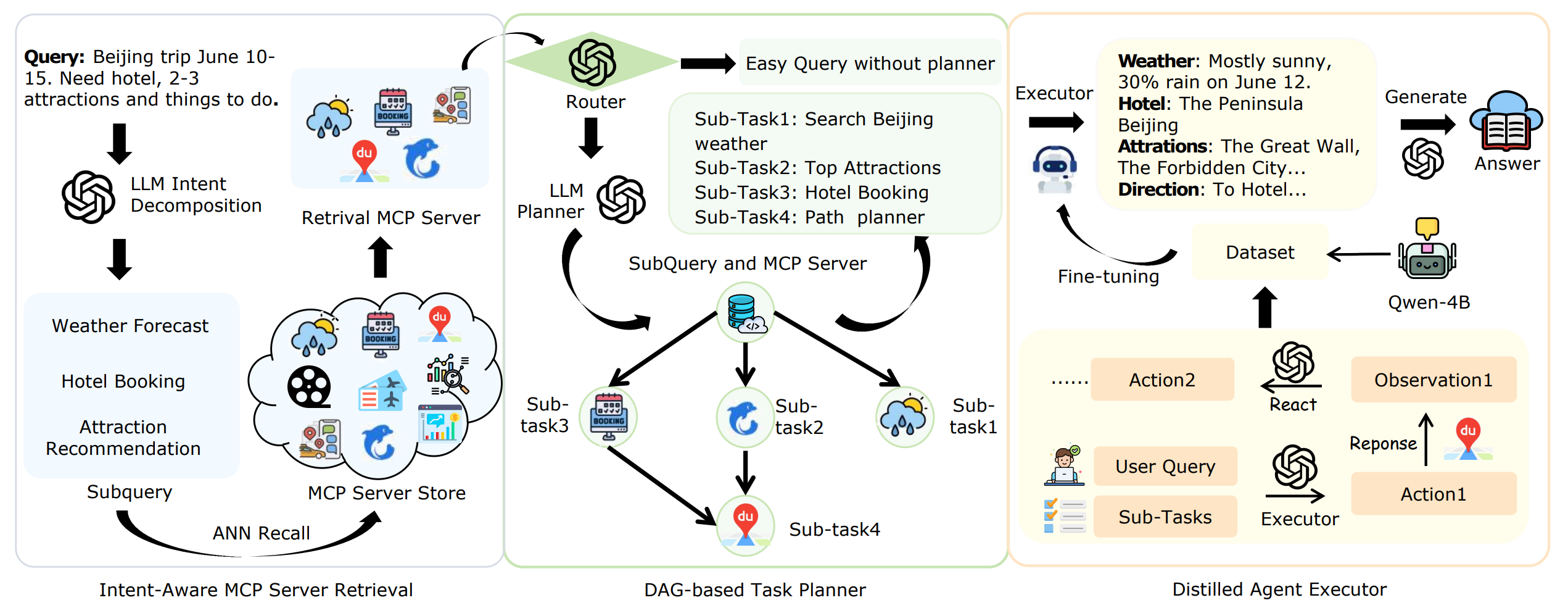
The TURA framework comprises three synergistic components:
Intent-Aware MCP Server Retrieval decomposes complex user queries into atomic intents using an LLM, then retrieves relevant static or dynamic tools from a semantic server index augmented with diverse synthetic queries. This step ensures accurate tool selection even when user phrasing diverges from formal API documentation.
DAG-Based Task Planning generates parallelizable execution plans for the sub-intents using a graph-based structure. Tasks with data dependencies are ordered accordingly, while independent ones are executed in parallel to optimize latency. This planner uses a powerful LLM to build the DAG based on the query's structure and server capabilities.
Distilled Agent Executor uses a small, latency-optimized agent fine-tuned via a “mixed-rationale” method, training with chain-of-thought but inferring without it. This achieves near-teacher-level performance with dramatically lower cost. For example, a distilled Qwen3-4B model outperforms GPT-4o and its own teacher model (Deepseek-V3) in tool-use accuracy (88.3% vs. 81.7%) while reducing latency from 6.8s to 750ms.
8. A Comprehensive Taxonomy of Hallucinations
This report presents a detailed taxonomy of LLM hallucinations, distinguishing intrinsic vs extrinsic errors and factuality vs faithfulness, and covering manifestations from factual mistakes to domain-specific failures. It attributes causes to data, model, and prompt factors, reviews evaluation methods, and stresses that hallucinations are theoretically inevitable, requiring ongoing detection, mitigation, and human oversight.
9. Tabular Data Understanding with LLMs
This survey reviews LLM and MLLM methods for table understanding, outlining a taxonomy of tabular representations and tasks. It identifies key gaps, including limited reasoning beyond retrieval, difficulties with complex or large-scale tables, and poor generalization across diverse formats.
10. Medical Reasoning in the Era of LLMs
This review categorizes techniques for enhancing LLM medical reasoning into training-time (e.g., fine-tuning, RL) and test-time (e.g., prompt engineering, multi-agent systems) approaches, applied across modalities and clinical tasks. It highlights advances in evaluation methods, key challenges like the faithfulness–plausibility gap, and the need for native multimodal reasoning in future medical AI.