
🥇Top AI Papers of the Week
The Top AI Papers of the Week (January 19-25)
1. TTT-Discover: Learning to Discover at Test Time

TTT-Discover introduces test-time training for scientific discovery, performing reinforcement learning at test time so the LLM can continue to train with experience specific to the test problem. Unlike prior work like AlphaEvolve that prompts a frozen LLM, this approach enables the model itself to improve while attempting to solve hard problems.
Test-time reinforcement learning: The method performs RL in an environment defined by a single test problem, with a learning objective and search subroutine designed to prioritize the most promising solutions rather than maximizing average reward across attempts.
State-of-the-art across domains: TTT-Discover sets new records on Erdős’ minimum overlap problem, an autocorrelation inequality, GPUMode kernel competitions (up to 2x faster than prior art), AtCoder algorithm competitions, and single-cell denoising in biology.
Open model results: All results are achieved with OpenAI gpt-oss-120b, an open model, and can be reproduced with publicly available code, in contrast to previous best results requiring closed frontier models.
Cost-effective discovery: Test-time training runs cost only a few hundred dollars per problem using Tinker API, making scientific discovery accessible without massive compute budgets.
Learning over search: While both learning and search scale with compute, the authors argue learning has historically superseded search for hard problems (Go, protein folding), and this observation extends to test-time compute scaling for discovery.
2. Reasoning Models Generate Societies of Thought
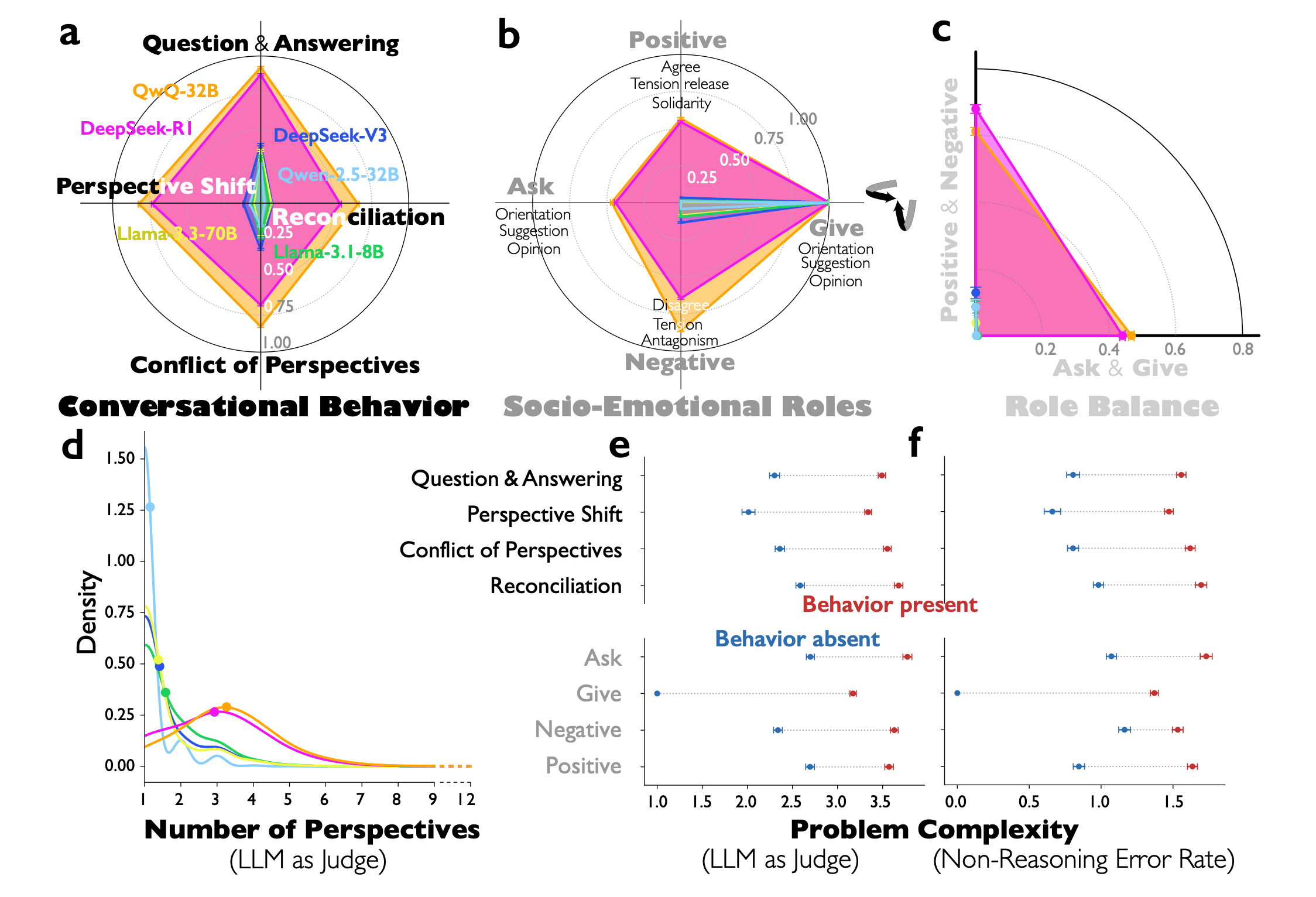
This paper reveals that enhanced reasoning in models like DeepSeek-R1 and QwQ-32B emerges not from extended computation alone, but from simulating multi-agent-like interactions - a “society of thought” - enabling diversification and debate among internal cognitive perspectives with distinct personality traits and domain expertise.
Multi-agent internal dynamics: Through mechanistic interpretability analysis, reasoning models exhibit much greater perspective diversity than instruction-tuned models, activating broader conflict between heterogeneous personality and expertise-related features during reasoning.
Conversational behaviors drive accuracy: The multi-agent structure manifests in question-answering, perspective shifts, and reconciliation of conflicting views. These socio-emotional roles characterizing back-and-forth conversations account for the accuracy advantage in reasoning tasks.
Emergent from accuracy rewards: Controlled reinforcement learning experiments reveal that base models naturally increase conversational behaviors when rewarded solely for reasoning accuracy, suggesting this structure emerges organically from optimization pressure.
Accelerated improvement through scaffolding: Fine-tuning models with conversational scaffolding accelerates reasoning improvement over base models, providing a practical pathway to enhance reasoning capabilities.
Parallel to collective intelligence: The findings suggest reasoning models establish a computational parallel to human collective intelligence, where diversity enables superior problem-solving when systematically structured, opening new opportunities for agent organization.
3. Memory Control for Long-Horizon Agents
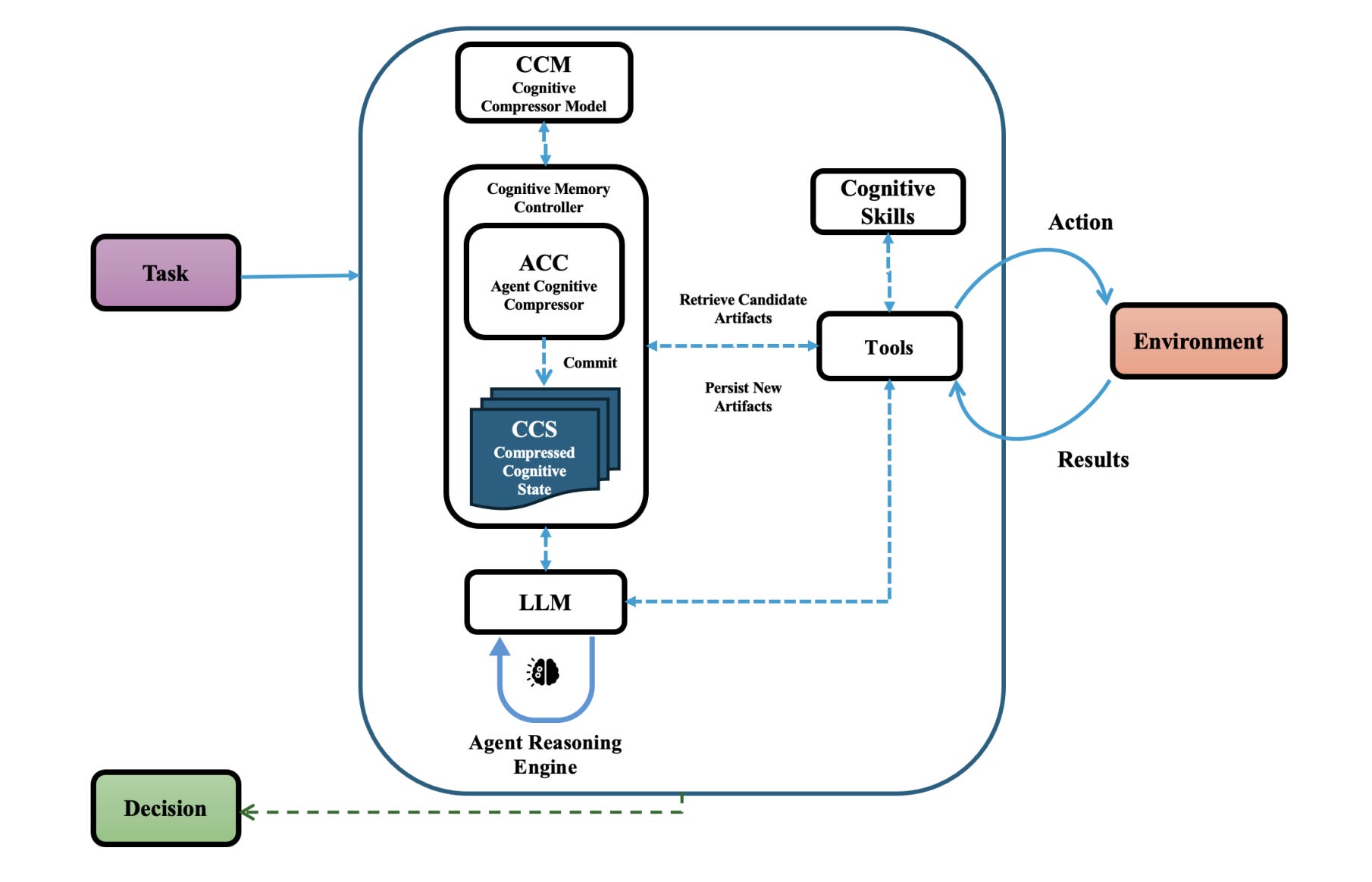
This paper introduces the Agent Cognitive Compressor (ACC), a bio-inspired mechanism that addresses degraded agent behavior in long multi-turn workflows caused by loss of constraint focus, error accumulation, and memory-induced drift. ACC replaces continuous transcript retention with a bounded internal state that updates incrementally during each interaction turn.
The problem with unbounded context: Traditional approaches using transcript replay or retrieval-based memory systems create unbounded context growth and introduce vulnerabilities to corrupted information, causing agent performance to degrade over extended interactions.
Bio-inspired bounded memory: Drawing from biological memory systems, ACC maintains a bounded internal state rather than continuously growing context, enabling stable performance without the computational costs of ever-expanding transcripts.
Agent-judge evaluation framework: The authors developed an agent-judge-driven evaluation framework to assess both task success and memory-related anomalies across extended workflows in IT operations, cybersecurity response, and healthcare contexts.
Reduced cognitive drift: ACC demonstrated substantially improved stability in multi-turn interactions, showing significantly reduced hallucination and cognitive drift compared to traditional transcript replay and retrieval-based systems.
Practical foundation: The research suggests that implementing cognitive compression principles provides a practical foundation for developing reliable long-horizon AI agent systems that maintain consistent behavior over extended deployments.
Message from the Editor

Excited to announce our new cohort-based training on Claude Code for Everyone. Learn how to leverage Claude Code features to vibecode production-grade AI-powered apps.
Seats are limited for this cohort. Grab your early bird spot now.
4. Benchmarking Agents on Hard CLI Tasks
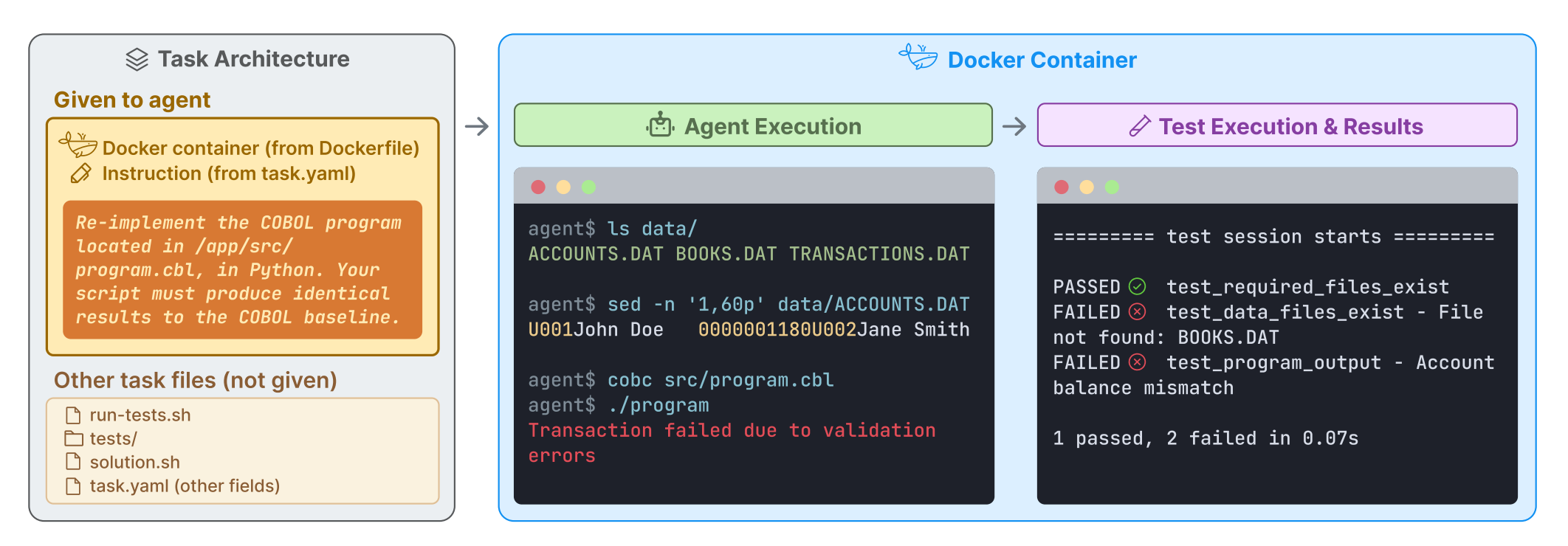
Terminal-Bench 2.0 presents a carefully curated hard benchmark composed of 89 tasks in computer terminal environments inspired by problems from real workflows. Each task features a unique environment, human-written solution, and comprehensive tests for verification, addressing the gap where current benchmarks either don’t measure real-world tasks or aren’t sufficiently difficult.
Challenging for frontier models: Frontier models and agents score less than 65% on the benchmark, demonstrating that Terminal-Bench meaningfully measures capabilities that current systems struggle with, unlike saturated benchmarks.
Real-world task inspiration: Tasks are derived from actual command-line workflows, ensuring the benchmark measures practical skills rather than artificial puzzles, with each task featuring unique environments reflecting diverse real scenarios.
Comprehensive verification: Every task includes human-written solutions and comprehensive tests for verification, enabling reliable and reproducible evaluation of agent performance on terminal-based tasks.
Error analysis insights: The authors conduct detailed error analysis to identify specific areas for model and agent improvement, providing actionable guidance for researchers developing more capable CLI agents.
Open evaluation infrastructure: The dataset and evaluation harness are publicly available at tbench.ai, enabling developers and researchers to benchmark their systems and contribute to advancing agent capabilities in terminal environments.
5. Rethinking Multi-Agent Workflows
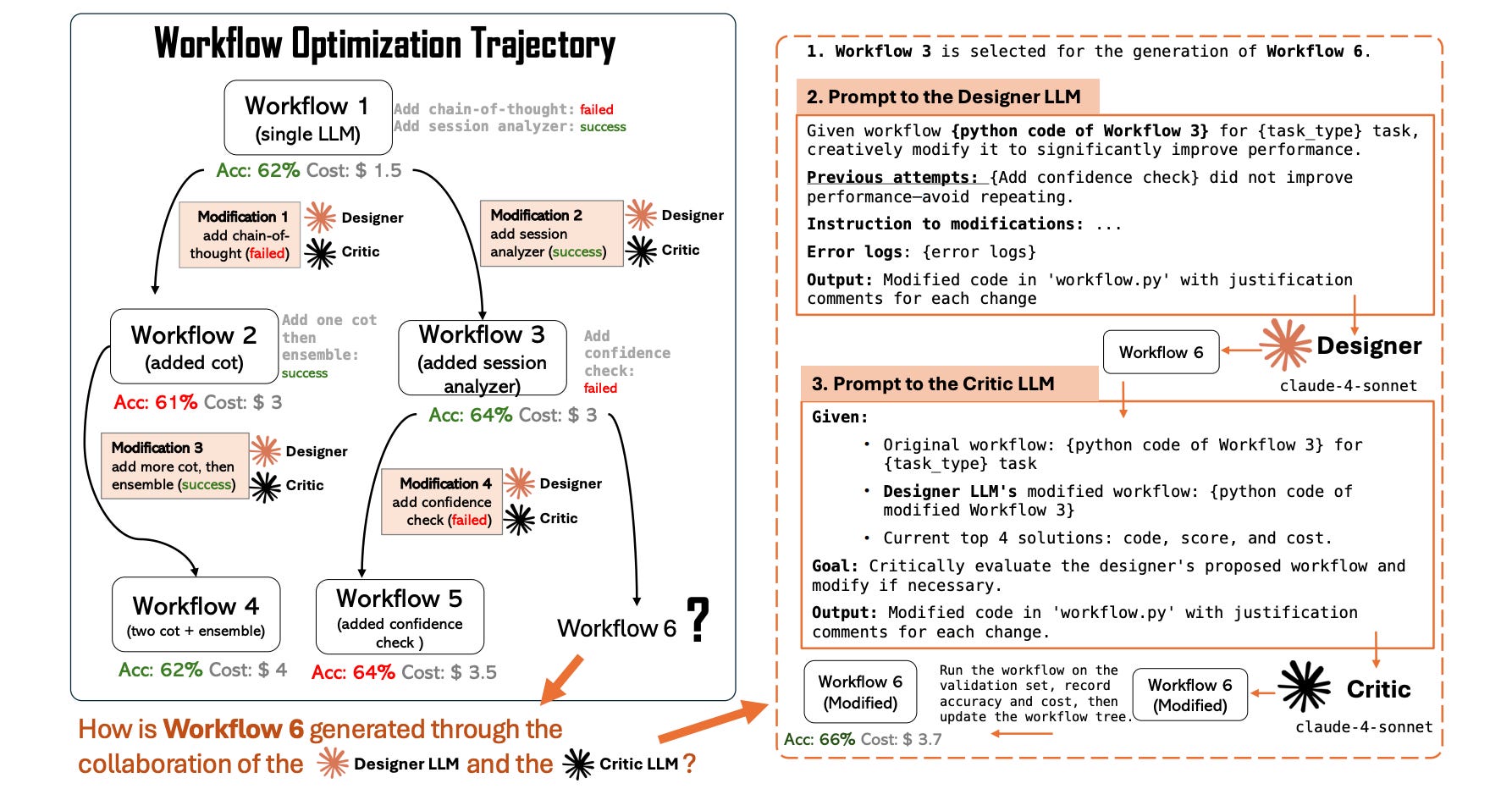
This paper challenges the assumption that complex tasks require multiple specialized AI agents, demonstrating that a single LLM agent, through iterative dialogue, can match the performance of homogeneous multi-agent workflows while gaining efficiency from KV cache reuse.
Single-agent hypothesis: The research tests whether multi-agent systems truly require multiple agents or if a single agent engaging in multi-turn conversations can replicate their performance, finding that the latter holds across diverse benchmarks.
Comprehensive evaluation: Testing across seven benchmarks spanning coding, math, QA, domain reasoning, and planning tasks demonstrates that the single-agent approach consistently matches multi-agent performance.
OneFlow algorithm: The paper introduces OneFlow, an algorithm that automatically optimizes workflows for single-agent execution, enabling practitioners to simplify complex multi-agent architectures without sacrificing capability.
Efficiency through KV cache reuse: Single-agent implementations gain substantial efficiency advantages by reusing key-value caches across conversation turns, reducing inference costs compared to multi-agent orchestration overhead.
Future directions: The work identifies that truly heterogeneous systems using different specialized LLMs remain an open research opportunity, as current multi-agent benefits may only emerge when agents have genuinely different capabilities.
6. Self-Correcting Multi-Agent LLM for Physics Simulation
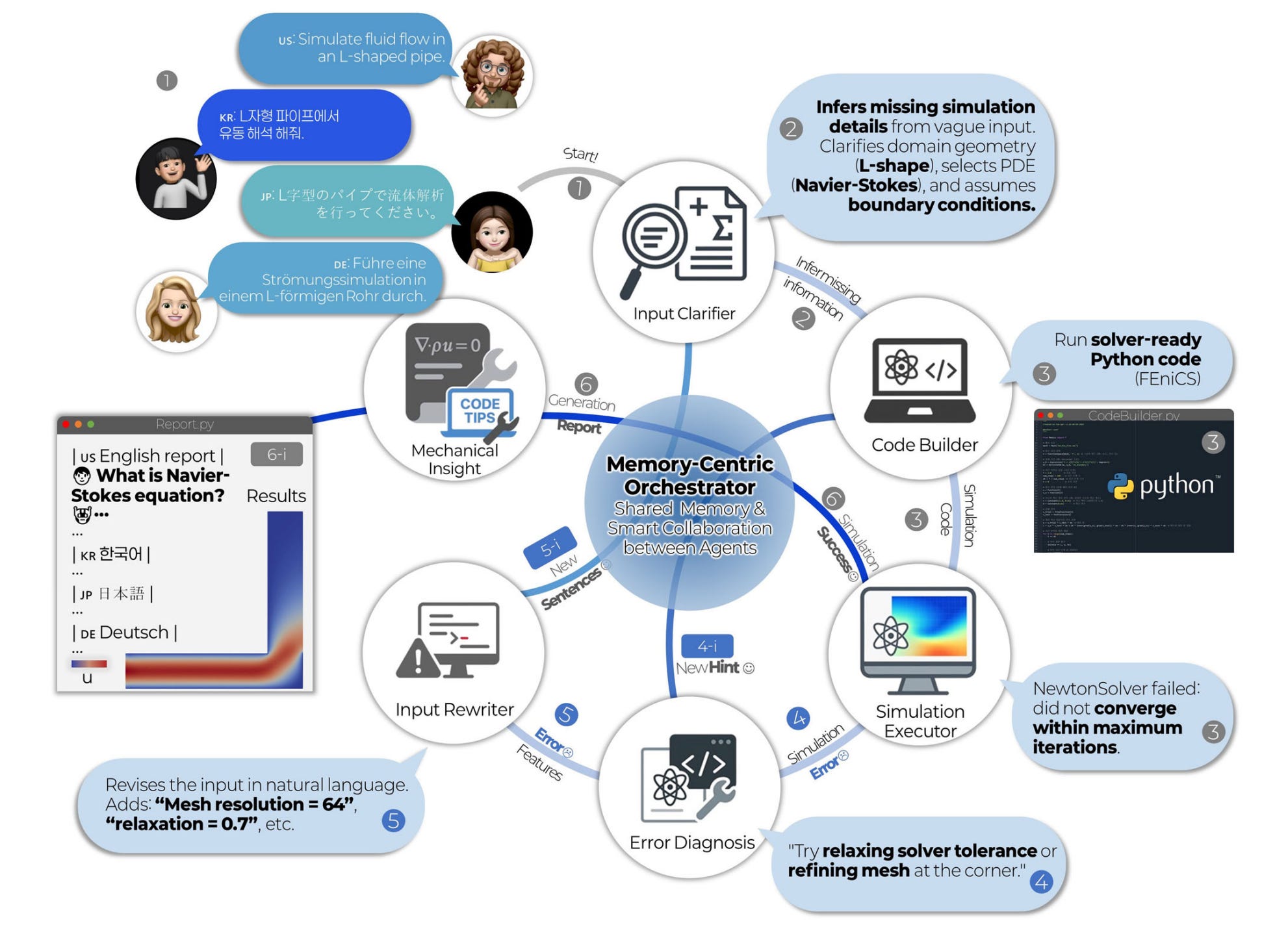
This paper introduces a self-correcting multi-agent LLM framework for language-based physics simulation and explanation. The system enables natural language queries to generate physics simulations while providing explanations of the underlying physical phenomena.
Multi-agent architecture: The framework employs multiple specialized LLM agents that collaborate to translate natural language descriptions into accurate physics simulations, with each agent handling distinct aspects of the simulation pipeline.
Self-correction mechanism: Built-in self-correction capabilities allow the system to identify and fix errors in generated simulations, improving accuracy without requiring human intervention or additional training.
Language-based interface: Users can describe physics scenarios in natural language, making complex simulation tools accessible to non-experts while maintaining scientific accuracy in the outputs.
Explanation generation: Beyond simulation, the system generates natural language explanations of the physics principles at work, serving both educational and research applications.
Validation across domains: The framework demonstrates effectiveness across multiple physics domains, showing generalization capability beyond narrow task-specific applications.
7. AI IDEs vs Autonomous Agents
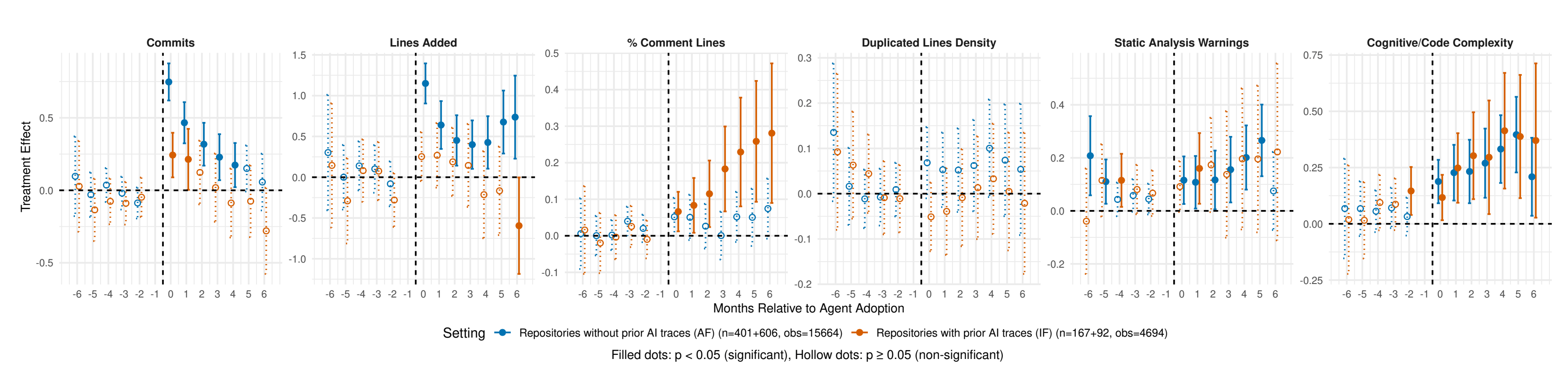
This empirical study investigates how LLM-based coding agents that autonomously generate and merge pull requests affect open-source projects compared to IDE-integrated AI assistants. Using longitudinal causal analysis with matched controls, the researchers measure development velocity and software quality outcomes.
Methodology: The study employs staggered difference-in-differences with matched controls, analyzing monthly metrics spanning development velocity and quality indicators like static-analysis warnings, code complexity, and duplication rates.
Velocity gains are conditional: Substantial upfront acceleration occurs only when autonomous agents are a project’s first AI tool. Projects already using IDE assistants see minimal additional productivity benefits from adding autonomous agents.
Persistent quality concerns: Across all contexts, static-analysis warnings rise roughly 18% and cognitive complexity increases approximately 35% when autonomous agents are deployed, suggesting tensions between speed and maintainability.
Diminishing returns: Layering multiple AI assistance types produces limited additional productivity improvements, challenging the assumption that more AI tools always mean better outcomes.
First-mover effects: The research differentiates effects based on whether agents represent a project’s first exposure to AI tooling versus augmenting existing assistance, finding that the sequence of adoption matters significantly.
8. Efficient Agents
A comprehensive review examining how to make LLM-based agents more efficient for real-world deployment, focusing on three core components: memory (bounding context via compression), tool learning (RL strategies to minimize tool invocation), and planning (controlled search mechanisms). The paper characterizes efficiency through dual metrics and Pareto frontier analysis between effectiveness and cost.
9. Task-Decoupled Planning for Long-Horizon Agents
Task-Decoupled Planning (TDP) is a training-free framework that restructures agent planning by decomposing tasks into a directed acyclic graph of sub-goals using three components: Supervisor, Planner, and Executor. By isolating reasoning to individual subtasks through scoped contexts, TDP prevents error cascading and reduces token consumption by up to 82% while outperforming baselines on TravelPlanner, ScienceWorld, and HotpotQA.
10. Large-Scale Study on Multi-Agent AI Systems Development
An empirical analysis of over 42,000 commits and 4,700 resolved issues across eight leading multi-agent frameworks (LangChain, CrewAI, AutoGen). Key findings: feature enhancements dominate at 40.8% of changes versus 27.4% bug fixes, bugs represent 22% of issues, with agent coordination challenges at 10%, and issue reporting surged notably beginning in 2023.