
🥇Top AI Papers of the Week
The Top AI Papers of the Week (May 5 - 11)
1. The Leaderboard Illusion

The Leaderboard Illusion investigates systemic distortions in how the Chatbot Arena leaderboard evaluates LLMs, arguing that current practices undermine fair model comparison and scientific progress. Through extensive data analysis covering 2M Arena battles, the authors identify four key issues distorting rankings:
Selective score reporting through private testing: Some providers (notably Meta, Google, and OpenAI) are allowed to test dozens of model variants privately and only publish the best-performing one. This violates the unbiased sampling assumption of the Bradley-Terry (BT) model, which powers Arena rankings. Simulations show that testing just 10 variants can artificially inflate a model’s Arena score by ~100 points.
Extreme data asymmetries: Proprietary models are oversampled compared to open-weight and open-source models. OpenAI and Google alone received over 39% of all Arena data, while 83 open-weight models collectively received only 29.7%. These data advantages translate into significant performance gains: a model trained on 70% Arena data outperforms its baseline by 112% on the ArenaHard benchmark.
Unfair and opaque deprecations: 205 models were silently removed from the leaderboard despite only 47 being officially marked as deprecated. Open-source models are disproportionately affected, breaking the comparison graph and violating BT model assumptions, leading to unreliable rankings.
Overfitting to Arena-specific dynamics: Due to partial prompt repetition and distributional drift over time, access to Arena data allows providers to tune models specifically for Arena performance. This leads to high win rates on Arena benchmarks, but not on out-of-distribution tasks like MMLU, where gains diminish or reverse.
2. Llama-Nemotron

NVIDIA introduces the Llama-Nemotron model series, LN-Nano (8B), LN-Super (49B), and LN-Ultra (253B), a family of open, efficient, and high-performing reasoning models. These models rival or outperform DeepSeek-R1 on various benchmarks while offering significantly better inference throughput and memory efficiency. LN-Ultra is noted as the most "intelligent" open model by Artificial Analysis. A key innovation is a dynamic reasoning toggle ("detailed thinking on/off") that allows users to control reasoning behavior at inference time.
Highlights:
Multi-stage training: Models were built via neural architecture search (Puzzle), knowledge distillation, continued pretraining, supervised fine-tuning (SFT), and large-scale RL. LN-Ultra is enhanced with FP8 inference and FFN Fusion for speed and scalability.
Reasoning Toggle: The models can switch between reasoning and non-reasoning modes via a simple prompt instruction, making them adaptable for various use cases.
Synthetic dataset: Over 33M examples across math, code, science, and instruction-following were curated, with reasoning-mode samples tagged explicitly. LN-Ultra's training used curriculum RL and GRPO to surpass its teachers on benchmarks like GPQA-D.
Evaluation dominance: LN-Ultra outperforms DeepSeek-R1 and Llama-3.1-405B in reasoning tasks like AIME25, MATH500, and GPQA-Diamond while also achieving strong chat alignment scores (Arena-Hard: 87.0). LN-Super scores 88.3, beating Claude 3.5 and GPT-4o.
NVIDIA provides the weights, training code (NeMo, Megatron-LM, NeMo-Aligner), and the full post-training dataset under a permissive license, aiming to push open research in reasoning models.
Editor Message:

We are excited to announce our new live course on building advanced AI agents. Learn how to build effective agentic systems with best practices and common design patterns.
Our subscribers can use code AGENTS30 for a 30% discount. (Limited time offer)
3. Absolute Zero
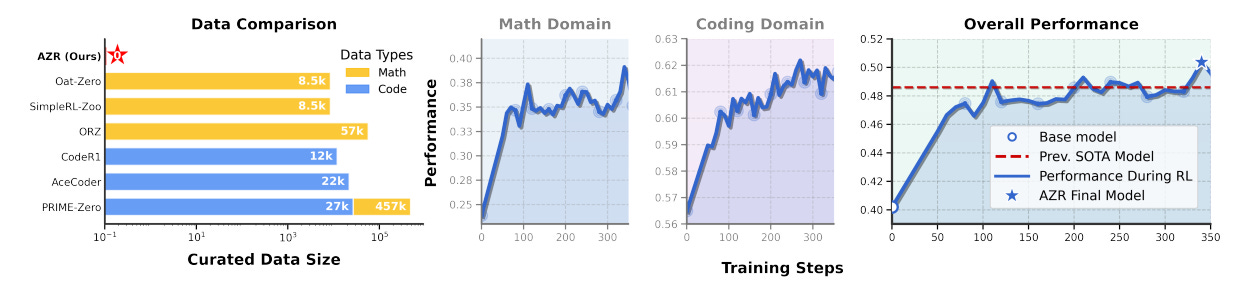
Introduces an LLM training framework that eliminates the need for human-curated data. Key highlights:
It learns to propose and solve its reasoning tasks entirely through self-play, guided by verifiable feedback from an execution environment. This zero-data RLVR (RL with Verifiable Rewards) setting achieves SOTA coding and math reasoning performance.
AZR learns by generating its code-based reasoning tasks using three core reasoning modes (deduction, abduction, and induction), validating solutions via Python execution, not human labels.
A single LLM plays both roles, proposing new tasks based on learnability and solving them with feedback-based reinforcement. Rewards favor moderately difficult tasks to maximize the learning signal.
Despite using zero in-domain examples, AZR outperforms all previous zero-setting models on average by +1.8 points and even beats models trained on tens to hundreds of thousands of curated samples. AZR-Coder-7B achieves the highest average score across all tested models.
AZR trained in a coding-only environment improves mathematical reasoning performance by up to +15.2 points, far more than expert code models trained with RLVR, showing strong generalization.
Larger AZR models (3B → 7B → 14B) consistently show greater improvements, confirming scalability and suggesting promise for even larger models.
AZR develops natural ReAct-like intermediate planning in code (e.g., interleaved comments and logic), trial-and-error strategies in abduction, and systematic state tracking, behaviors typically observed in much larger models.
Llama-3.1-8B variants of AZR sometimes produce concerning reasoning chains (dubbed “uh-oh moments”), highlighting the importance of safety-aware training in autonomous systems.
4. Discuss-RAG
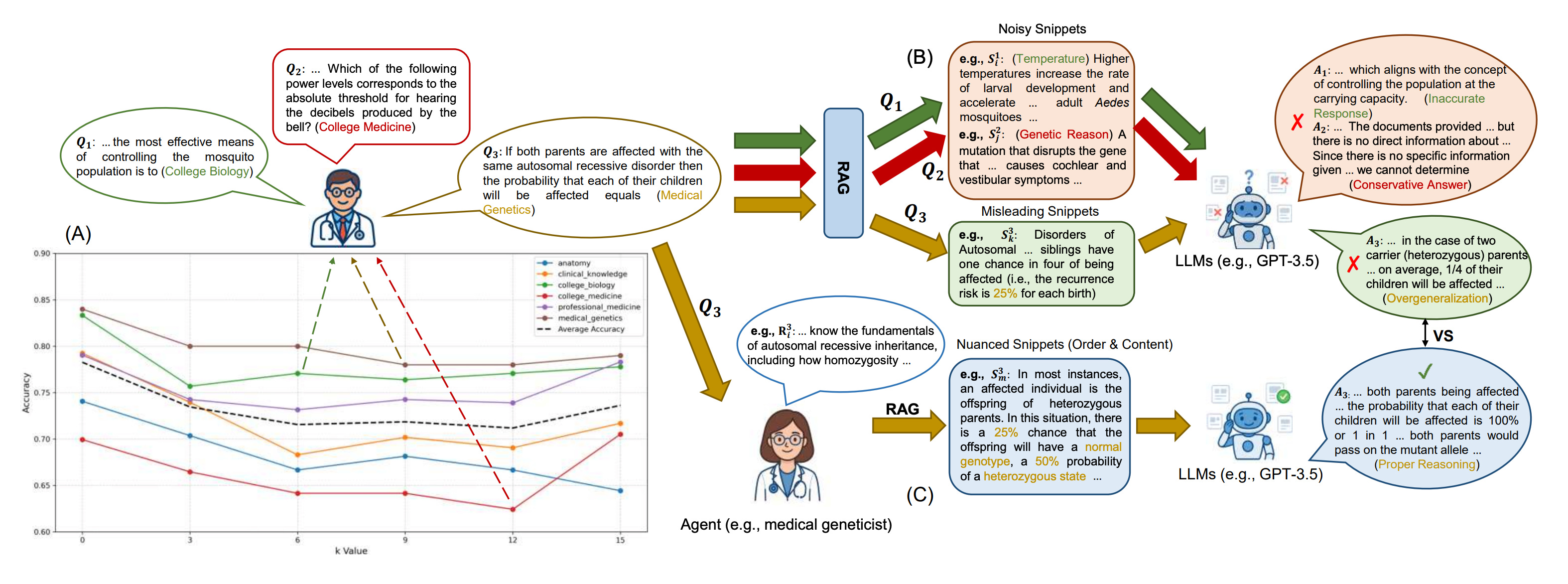
This paper introduces Discuss-RAG, a plug-and-play agent-based framework that enhances retrieval-augmented generation (RAG) for medical question answering by mimicking human-like clinical reasoning. Standard RAG systems rely on embedding-based retrieval and lack mechanisms to verify relevance or logical coherence, often leading to hallucinations or outdated answers. Discuss-RAG addresses these gaps via a modular agent setup that simulates multi-turn medical discussions and performs post-retrieval verification.
Key ideas:
Multi-agent collaboration: A summarizer agent orchestrates a team of medical domain experts who iteratively refine a contextual summary through simulated brainstorming, providing deeper and more structured information to guide retrieval.
Decision-making agent: After retrieval, a verifier and a decision-making agent assess snippet quality and trigger fallback strategies when relevance is low, improving answer accuracy and contextual grounding.
Plug-and-play design: Discuss-RAG is training-free and modular, allowing easy integration into existing RAG pipelines.
Strong performance gains: Across four benchmarks, Discuss-RAG outperforms MedRAG with substantial accuracy improvements, notably +16.67% on BioASQ and +12.20% on PubMedQA.
5. The Value of RL in Fine-Tuning

This work shows that, in theory, every popular preference-fine-tuning objective collapses to maximum-likelihood estimation (MLE), yet experiments show a consistent RL advantage on real tasks. They reconcile this gap with a generation-verification complexity hypothesis.
Theory: RLHF ≈ MLE – Under mild assumptions, trajectory-level RLHF, DPO, and related algorithms are equivalent to projecting the data back to likelihood space, so expending compute on on-policy sampling should be unnecessary.
Empirics contradict naïve theory – On the tl;dr summarization benchmark with Pythia-1.4B/2.8B, a single online-DPO iteration lifts win-rate by 6-10 pts over offline DPO despite identical data, model, and optimizer, confirming that RL can add real value.
Takeaways – RL helps when crafting a good answer is harder than checking one. The gap vanishes on two-word summaries (horizon = 1) or when ROUGE-L is used as the reward. RL acts as a shortcut through policy space only when the reward model is simpler than the policy it trains. For tasks where verification is as hard as generation, offline likelihood-based fine-tuning suffices, guiding practitioners on when RLHF is worth its extra cost.
6. WebThinker

This paper introduces a reasoning agent framework that equips large reasoning models (LRMs) with autonomous web exploration and report writing abilities to overcome limitations of static internal knowledge.
WebThinker integrates a Deep Web Explorer module and an Autonomous Think-Search-and-Draft strategy that lets models search the web, reason through tasks, and generate comprehensive outputs simultaneously. It also incorporates an RL-based training loop using online DPO to improve tool usage. The system supports two modes: complex problem solving and scientific report generation.
Key points:
Superior performance in complex reasoning: On GPQA, GAIA, WebWalkerQA, and HLE, WebThinker-32B-RL achieved new state-of-the-art results among 32B models, outperforming both retrieval-augmented and proprietary systems like GPT-4o and DeepSeek-R1-671B. For example, it reached 70.7% on GPQA and 15.8% on HLE, with gains of up to +21.5% over baselines.
Best-in-class scientific report writing: On the Glaive dataset, WebThinker outperformed Gemini2.0 Deep Research and Grok3 DeeperSearch, scoring 8.1 in average quality metrics such as completeness and coherence.
RL refinement matters: The RL-trained version outperformed its base counterpart across all benchmarks, showing that iterative preference-based learning significantly enhances reasoning-tool coordination.
Ablation validates design: Removing components like Deep Web Explorer or automatic report drafting significantly degraded performance, confirming their necessity.
7. Reward Modeling as Reasoning
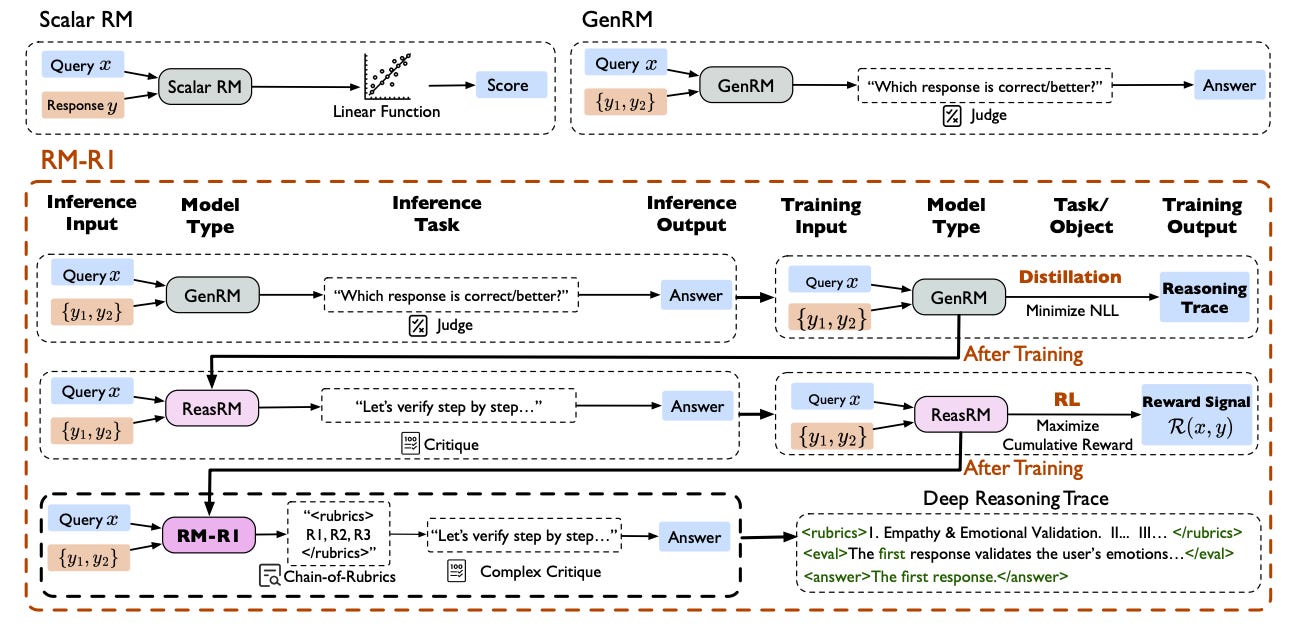
This work proposes a new class of reward models, called ReasRMs, that reformulate reward modeling as a reasoning task. The authors introduce RM-R1, a family of generative reward models that produce interpretable reasoning traces and rubrics during preference judgments. Instead of relying on scalar scores or shallow generation, RM-R1 models leverage structured reasoning and reinforcement learning to improve both interpretability and performance across benchmarks.
RM-R1 adopts a two-stage training process: (1) distillation of reasoning traces from stronger models, and (2) reinforcement learning with verifiable rewards. The Chain-of-Rubrics (CoR) prompting framework guides the model to either solve reasoning problems or generate evaluation rubrics depending on the task type (reasoning or chat).
On RewardBench, RM-Bench, and RMB, RM-R1 models achieve state-of-the-art or near-SOTA performance, outperforming models like GPT-4o and Llama3.1-405B by up to 13.8% despite using fewer parameters and less data.
Ablation studies show that cold-start RL alone is insufficient; task-type classification and high-quality distillation are key. RM-R1's distilled warm-start training leads to more stable learning and longer, more accurate reasoning traces.
RM-R1 also shows strong generalization across domains and better rubric quality than baseline methods, especially in sensitive contexts like safety and medical judgment. The authors open-sourced six RM-R1 models, training data, and code to support reproducibility.
8. Paper2Code
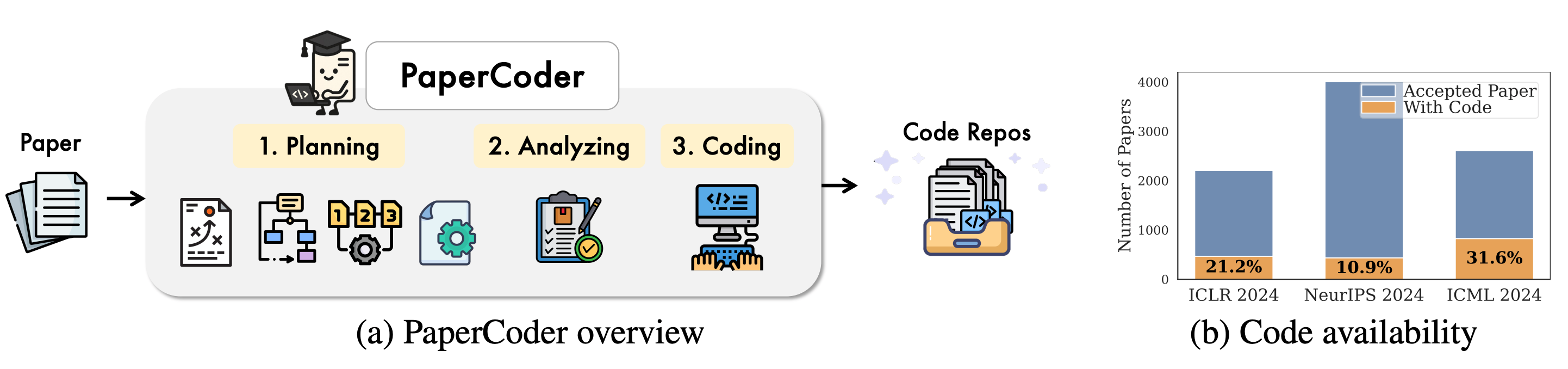
Introduces PaperCoder, a multi-agent LLM framework that transforms ML papers into full code repositories without relying on pre-existing implementations.
PaperCoder decomposes the code generation process into three stages: Planning (roadmap, architecture, file dependencies, config files), Analyzing (file-specific logic extraction), and Coding (dependency-aware file generation). Each step is handled by specialized LLM agents.
It is evaluated using both the proposed Paper2Code benchmark (90 papers from ICML, NeurIPS, and ICLR 2024) and PaperBench Code-Dev. Results show PaperCoder outperforms ChatDev, MetaGPT, and naive baselines across reference-based, reference-free, and human evaluations.
In human assessments by original paper authors, 77% chose PaperCoder as best implementation; 85% said it helped them reproduce their work. On average, only 0.48% of code lines required changes for executability.
A detailed ablation study shows consistent performance gains from each stage, especially logic design and file dependency ordering. PaperCoder, using the o3-mini-high backbone, notably outperforms other LLM variants.
9. ZeroSearch
ZeroSearch is an RL framework that trains LLMs to develop search capabilities without using real search engines. It uses simulated LLM-generated documents with a curriculum-based degradation strategy and outperforms real-search methods like Search-R1 in both performance and cost, achieving better QA accuracy across multiple benchmarks.
10. Practical Efficiency of Muon for Pretraining
Discusses how Muon, a simple second-order optimizer, outperforms AdamW in large-batch pretraining by expanding the compute-time Pareto frontier and maintaining better data efficiency. Combined with muP scaling and a novel telescoping algorithm for hyperparameter transfer, it enables faster training with minimal tuning overhead up to 4B parameter models.