
🥇Top AI Papers of the Week
The Top AI Papers of the Week (May 19 - 25)
1. Visual Planning

Proposes a novel reasoning paradigm that replaces language-based planning with image-based reasoning. The authors argue that language is not always the optimal medium for tasks involving spatial or physical reasoning. They introduce Visual Planning, where reasoning is executed as a sequence of visual states (images) without any text mediation, allowing models to “think” directly in images. This is realized through a reinforcement learning framework called VPRL (Visual Planning via Reinforcement Learning), which trains a vision-only model (LVM-3B) to plan using images.
Key contributions and findings:
Visual-only reasoning paradigm: The authors formally define planning as autoregressive visual state generation, trained using image-only data. Unlike multimodal LLMs that map vision to language and reason textually, this approach performs inference entirely in the visual modality, sidestepping the modality gap.
VPRL framework: A two-stage training process is introduced. Stage 1 uses supervised learning on randomly sampled trajectories to ensure format consistency and promote exploration. Stage 2 applies GRPO (Group Relative Policy Optimization) to refine planning behavior via progress-based rewards, avoiding invalid or regressive moves.
Superior performance: On three visual navigation tasks (FronzeLake, Maze, and MiniBehavior), VPRL outperforms language-based models (e.g., Gemini 2.5 Pro, Qwen 2.5-VL) by over 40% in Exact Match scores. It also generalizes better to out-of-distribution tasks (larger grid sizes), with visual planners degrading more gracefully than textual ones.
Visual planning yields robustness and interpretability: Unlike textual outputs, visual plans enable step-by-step inspection and show stronger adherence to physical constraints. Qualitative examples illustrate how VPRL can avoid invalid moves and recover from non-optimal paths, while language models often hallucinate or misinterpret spatial layouts.
Exploration and invalid action reduction: The random policy initialization in Stage 1 enables better exploration than supervised baselines (VPFT), as evidenced by higher entropy and fewer invalid actions. This leads to a more effective RL stage and ultimately stronger planning capabilities.
2. EfficientLLM
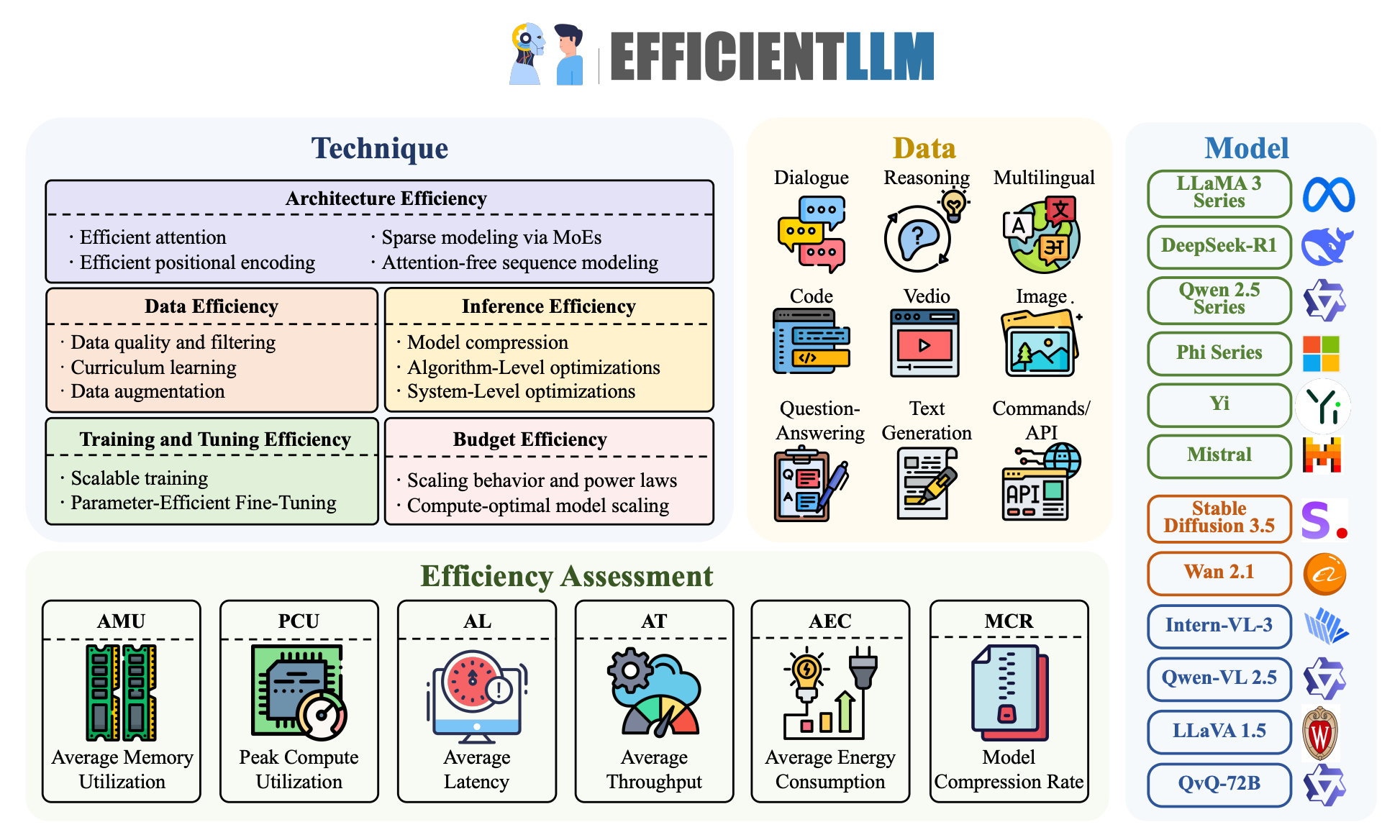
Introduces the first large-scale, empirical benchmark for evaluating efficiency trade-offs in LLMs across architecture, fine-tuning, and inference. Conducted on a high-performance cluster (48×GH200, 8×H200 GPUs), the study evaluates over 100 model–technique pairs spanning 0.5B–72B parameters, using six metrics: memory utilization, compute utilization, latency, throughput, energy consumption, and compression rate.
Key insights include:
No one-size-fits-all solution: Every efficiency technique improves some metrics while degrading others. For instance, MoE boosts accuracy and reduces FLOPs but increases VRAM usage by ~40%, while int4 quantization reduces memory and energy by up to 3.9× at a small 3–5% performance cost.
Resource-specific optima: Efficiency depends on context. MQA achieves the best memory-latency trade-off for constrained devices; MLA has the lowest perplexity for high-quality generation; RSLoRA is more efficient than LoRA only for models above 14B parameters.
Cross-modal transferability: Efficiency techniques like MQA and PEFT generalize well to vision and vision-language models, improving FID scores and maintaining strong trade-offs.
Training and tuning: LoRA and DoRA perform best for small models (1–3B), while RSLoRA excels at large scale (≥14B). Parameter freezing achieves the lowest latency but at a slight cost to accuracy.
Inference: int4 post-training quantization yields the highest compression and throughput gains with minor quality degradation, while bfloat16 consistently outperforms float16 in latency and energy on modern GPUs.
3. J1

Introduces a novel training approach for LLMs to act as evaluators (LLM-as-a-Judge) by explicitly incentivizing thoughtful reasoning during judgment. Instead of relying solely on prompting or preference fine-tuning, J1 employs online reinforcement learning with verifiable rewards to teach models to think through evaluations systematically.
Key insights:
Verifiable framing for judgment: J1 converts both verifiable (e.g., math) and non-verifiable (e.g., user queries) prompts into tasks with verifiable rewards by generating synthetic preference pairs. This reframing enables the use of reinforcement learning and consistent training signals across diverse tasks.
Chain-of-thought-driven RL optimization: J1 trains models to reason through evaluations via explicit thought traces, including outlining evaluation criteria, reference answer generation, and self-comparison before producing judgments. Two model types are trained: Pairwise-J1 (outputs verdicts) and Pointwise-J1 (outputs quality scores). Pairwise-J1 models are further improved by consistency rewards to reduce positional bias.
Superior performance at scale: J1-Llama-8B and J1-Llama-70B outperform existing 8B and 70B LLM judges across five benchmarks (PPE, RewardBench, RM-Bench, JudgeBench, FollowBenchEval), beating models trained with much more data like DeepSeek-GRM and distillations of DeepSeek-R1. J1-70B even surpasses o1-mini and closes the gap with the much larger R1 model, particularly on non-verifiable tasks.
Pointwise-J1 mitigates positional bias: While pairwise judges can flip verdicts based on response order, Pointwise-J1 (trained only from pairwise supervision) offers position-consistent scoring with fewer ties and better consistency. Both judge types benefit from test-time scaling via self-consistency, further improving reliability.
4. The Pitfalls of Reasoning for Instruction- Following in LLMs

Explores an unexpected flaw in reasoning-augmented large language models (RLLMs): while chain-of-thought (CoT) prompting often boosts performance on complex reasoning tasks, it can degrade instruction-following accuracy. The authors evaluate 15 models (e.g., GPT, Claude, LLaMA, DeepSeek) on two instruction-following benchmarks and find that CoT prompting consistently reduces performance across nearly all models and datasets.
Key findings:
Reasoning hurts instruction adherence: On IFEval, 13 of 14 models saw accuracy drops with CoT; all 15 models regressed on ComplexBench. For example, Meta-LLaMA3-8B’s IFEval accuracy dropped from 75.2% to 59.0% with CoT. Even reasoning-tuned models like Claude3.7-Sonnet-Think performed slightly worse than their base counterparts.
Why reasoning fails: Manual case studies show CoT can help with structural formatting (e.g., JSON or Markdown) and precise lexical constraints (like exact punctuation). But it often hurts by (a) neglecting simple constraints during high-level content planning and (b) inserting helpful but constraint-violating content (e.g., translations in language-restricted outputs).
Attention-based diagnosis: The authors introduce a constraint attention metric and find that CoT reduces the model's focus on instruction-relevant tokens, especially in the answer generation phase. This diminished constraint awareness correlates with performance drops.
Mitigation strategies: Four techniques are proposed to selectively apply reasoning:
Few-shot learning (modest gains),
Self-reflection (stronger for simpler tasks),
Self-selective reasoning (model chooses when to use CoT), and
Classifier-selective reasoning (an external classifier predicts whether CoT will help). The last method proves most reliable, recovering performance across nearly all models and settings.
5. Generalizable AI Predicts Immunotherapy Outcomes Across Cancers and Treatments

Introduces COMPASS, a concept bottleneck-based foundation model that predicts patient response to immune checkpoint inhibitors (ICIs) using tumor transcriptomic data. Unlike prior biomarkers (TMB, PD-L1, or fixed gene signatures), COMPASS generalizes across cancer types, ICI regimens, and clinical contexts with strong interpretability and performance.
Key contributions:
Concept Bottleneck Architecture: COMPASS transforms transcriptomic data into 44 high-level immune-related concepts (e.g., T cell exhaustion, IFN-γ signaling, macrophage activity) derived from 132 curated gene sets. This structure provides mechanistic interpretability while enabling pan-cancer modeling.
Pan-Cancer Pretraining and Flexible Fine-Tuning: Trained on 10,184 tumors across 33 cancer types using contrastive learning, and evaluated on 16 ICI-treated clinical cohorts (7 cancers, 6 ICI drugs). COMPASS supports full, partial, linear, and zero-shot fine-tuning modes, making it robust in both data-rich and data-poor settings.
Superior Generalization and Accuracy: In leave-one-cohort-out testing, COMPASS improved precision by 8.5%, AUPRC by 15.7%, and MCC by 12.3% over 22 baseline methods. It also outperformed in zero-shot settings, across drug classes (e.g., predicting anti-CTLA4 outcomes after training on anti-PD1), and in small-cohort fine-tuning.
Mechanistic Insight into Resistance: Personalized response maps reveal actionable biological mechanisms. For instance, inflamed non-responders show resistance via TGF-β signaling, vascular exclusion, CD4+ T cell dysfunction, or B cell deficiency. These go beyond classical “inflamed/desert/excluded” phenotypes, offering nuanced patient stratification.
Clinical Utility and Survival Stratification: COMPASS-predicted responders had significantly better survival in a held-out phase II bladder cancer trial (HR = 4.7, p = 1.7e-7), outperforming standard biomarkers (TMB, PD-L1 IHC, immune phenotype).
6. Towards a Deeper Understanding of Reasoning in LLMs
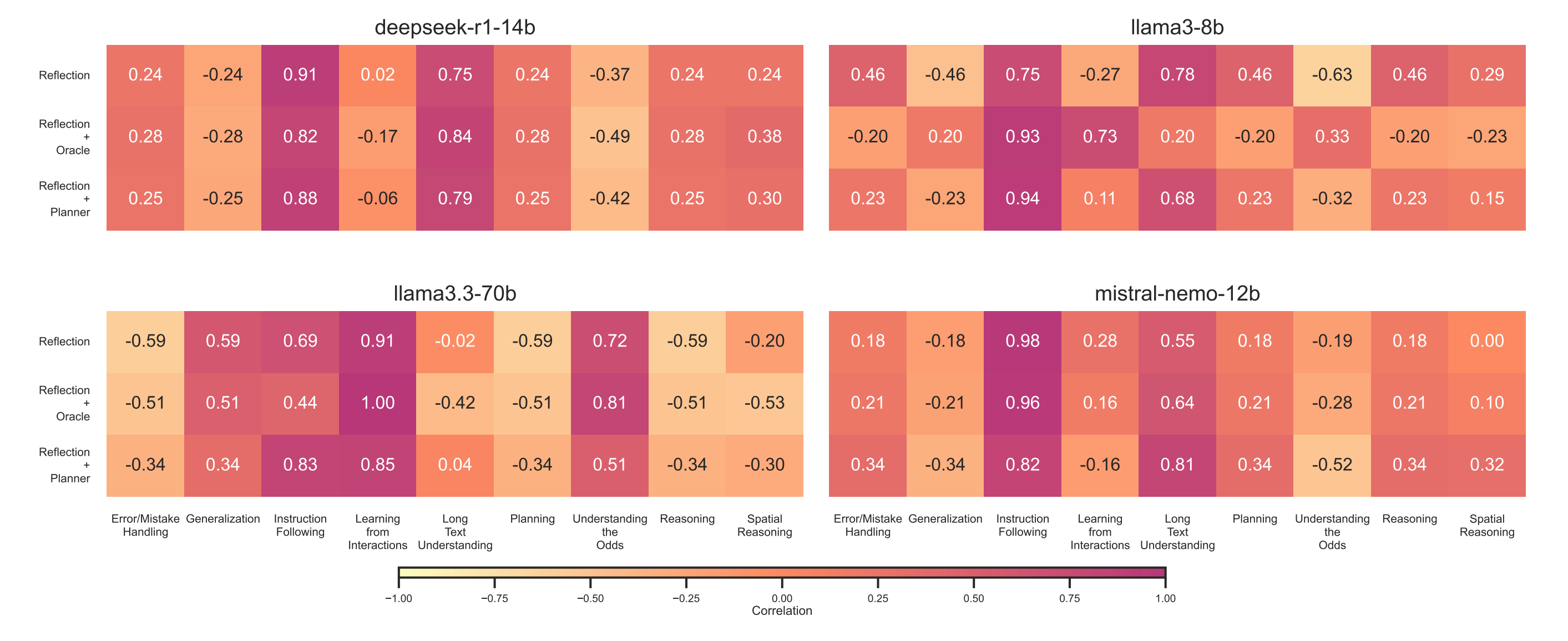
This paper investigates whether LLMs can adapt and reason in dynamic environments, moving beyond static benchmarks. Using the SmartPlay benchmark—a suite of four interactive games that require diverse cognitive skills—the authors evaluate three prompting strategies: self-reflection, heuristic mutation (via an Oracle), and planning. They test these methods across models of varying size (Llama3-8B to Llama3.3-70B) and draw several conclusions on how model scale and prompting interact with task complexity.
Key findings:
Model size dominates performance, especially on reactive and structured reasoning tasks. Larger models (e.g., Llama3.3-70B) significantly outperform smaller ones on tasks like Tower of Hanoi and Bandit, where fast exploitation or spatial planning is critical.
Advanced prompting helps smaller models more, particularly on complex tasks. For example, Llama3-8B with Reflection+Oracle surpasses Llama3.3-70B’s baseline on Rock-Paper-Scissors. However, these strategies introduce high variance and can lead to worse-than-baseline performance depending on the run.
Long prompts hurt smaller models on simple tasks. In Bandit, adding reflective reasoning decreases performance by distracting the model or prolonging exploration. This aligns with prior findings on prompt length and signal-to-noise ratio.
Prompting strategy gains depend on task type. Instruction following improves across all models, while long-text understanding benefits mid-sized models. In contrast, strategies show weak or negative impact on planning, reasoning, and spatial challenges for large models.
Dense reward shaping improves performance more reliably than prompting. In follow-up experiments, modifying sparse reward signals (especially in Hanoi and Messenger) led to more consistent gains than tweaking prompt strategies.
7. AdaptThink
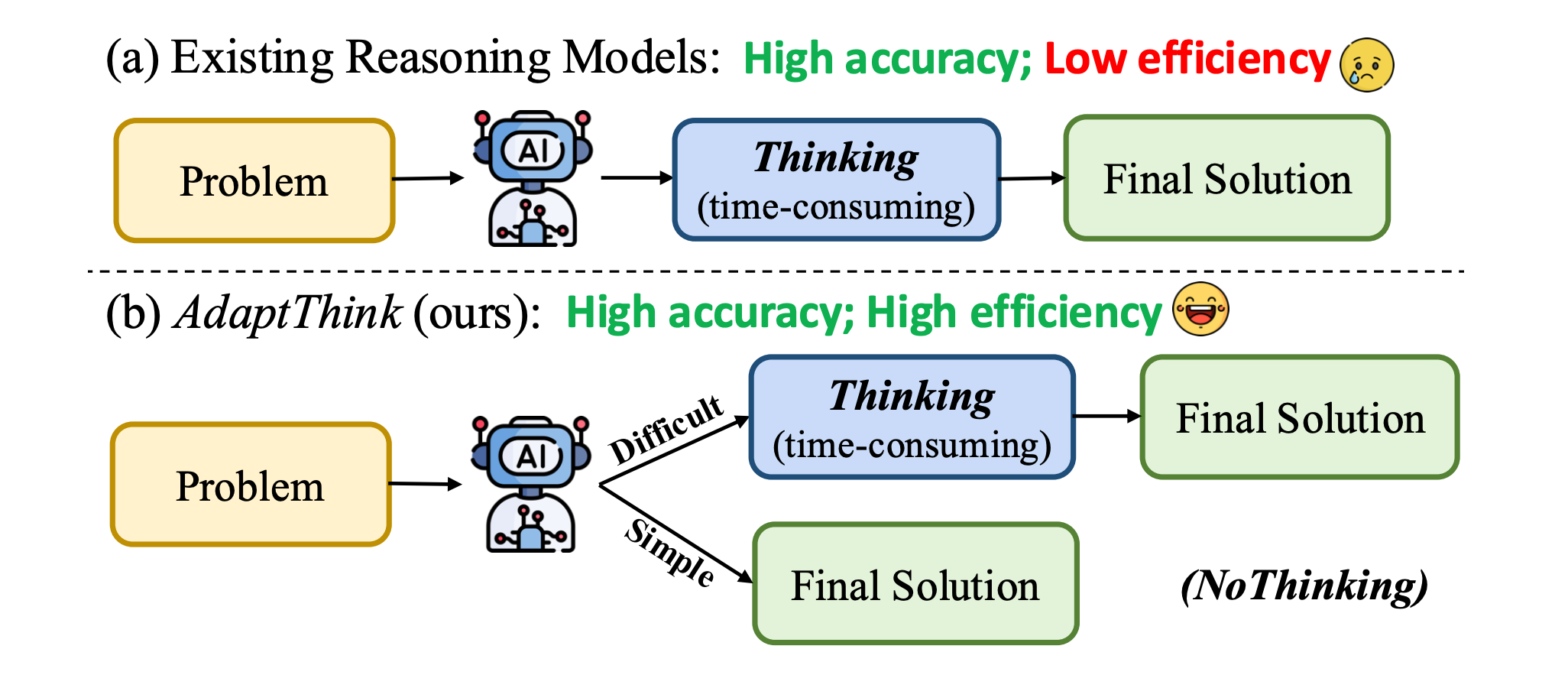
This paper introduces AdaptThink, an RL framework designed to help reasoning models decide when to use detailed chain-of-thought reasoning (“Thinking”) versus directly producing an answer (“NoThinking”), based on task difficulty. This approach challenges the prevailing assumption that deep reasoning should be applied uniformly across all problems, showing that skipping the “thinking” step often yields better efficiency and even higher accuracy on simpler tasks.
Key insights:
NoThinking outperforms Thinking on simple problems: The authors demonstrate that models like DeepSeek-R1 perform better (in both accuracy and efficiency) when using NoThinking mode, an empty <think></think> token prompt, for easy problems. For example, on Level 1 MATH500 problems, NoThinking achieved slightly better accuracy with significantly fewer tokens used.
AdaptThink learns to switch modes: The proposed RL algorithm introduces a constrained optimization that promotes NoThinking as long as accuracy doesn’t degrade. It uses a novel importance sampling strategy to enable cold-start learning of both modes from the beginning, avoiding the collapse into all-Thinking behavior.
Massive gains in efficiency and performance: On GSM8K, MATH500, and AIME 2024, AdaptThink reduced response length by up to 53% and improved accuracy by up to 2.4% over DeepSeek-R1-Distill-Qwen-1.5B. It also outperformed prior methods (e.g., DPOShortest, TLMRE, ModelMerging) in the trade-off between accuracy and response length.
Robustness and generalization: AdaptThink generalizes to out-of-distribution tasks such as MMLU, maintaining or improving accuracy while reducing token usage. It also avoids "implicit thinking" in NoThinking responses, showing controlled behavior during inference.
8. MedBrowseComp
MedBrowseComp is a new benchmark designed to evaluate LLM agents’ ability to perform complex, multi-hop medical fact-finding by browsing real-world, domain-specific web resources. Testing over 1,000 clinically grounded questions, the benchmark reveals major capability gaps in current models, with top systems achieving only 50% accuracy and GUI-based agents performing even worse.
9. ARC-AGI-2
ARC-AGI-2 is a new benchmark designed to push the boundaries of AI reasoning beyond the original ARC-AGI. It introduces harder, more unique tasks emphasizing compositional generalization and human-like fluid intelligence, with baseline AI models performing below 5% accuracy despite strong ARC-AGI-1 results.
10. Teaching MLLMs to Think with Images
GRIT is a new method that enables MLLMs to perform grounded visual reasoning by interleaving natural language with bounding box references. Using a reinforcement learning approach (GRPO-GR), GRIT achieves strong reasoning and grounding performance with as few as 20 image-question-answer triplets, outperforming baselines in both accuracy and visual coherence.