
🥇Top AI Papers of the Week: AI Co-Scientist, The AI CUDA Engineer, Native Sparse Attention, Open-Reasoner-Zero
The Top AI Papers of the Week (Feb 17 - 23)
1). AI Co-Scientist

Google introduces AI co-scientist, a multi-agent AI system built with Gemini 2.0 to help accelerate scientific breakthroughs.
Key highlights:
What's the goal of this AI co-scientist? – It can serve as a "virtual scientific collaborator to help scientists generate novel hypotheses and research proposals, and to accelerate the clock speed of scientific and biomedical discoveries."
How is it built? – It uses a coalition of specialized agents inspired by the scientific method. It can generate, evaluate, and refine hypotheses. It also has self-improving capabilities.
Collaboration and tools are key! – Scientists can either propose ideas or provide feedback on outputs generated by the agentic system. Tools like web search and specialized AI models improve the quality of responses.
Hierarchical Multi-Agent System – AI co-scientist is built with a Supervisor agent that assigns tasks to specialized agents. Apparently, this architecture helps with scaling compute and iteratively improving scientific reasoning.
Test-time Compute – AI co-scientist leverages test-time compute scaling to iteratively reason, evolve, and improve outputs. Self-play, self-critique, and self-improvement are all important to generate and refine hypotheses and proposals.
Performance? – Self-improvement relies on the Elo auto-evaluation metric. On GPQA diamond questions, they found that "higher Elo ratings positively correlate with a higher probability of correct answers." AI co-scientist outperforms other SoTA agentic and reasoning models for complex problems generated by domain experts. The performance increases with more time spent on reasoning, surpassing unassisted human experts. Experts assessed the AI co-scientist to have a higher potential for novelty and impact. It was even preferred over other models like OpenAI o1.
Sponsor Message

Accelerate your AI projects with Prolific. Claim $50 free credits and get quality human data in minutes from 200,000+ taskers. No setup cost, no subscription, no delay—get started, top up your account to claim your free credit, and test Prolific for yourself now. Use code: NLP-50
2). The AI CUDA Engineer

Sakana AI introduces The AI CUDA Engineer, an end-to-end agentic system that can produce highly optimized CUDA kernels.
Key contributions:
Why is this research important? – Writing efficient CUDA kernels is challenging for humans. The AI CUDA Engineer is an end-to-end agent built with the capabilities to automatically produce and optimize CUDA kernels more effectively.
What's up with CUDA? – Writing CUDA kernels can help achieve high-performing AI algorithms. However, this requires GPU knowledge, and most AI algorithms today are written in a higher-level abstraction layer such as PyTorch.
An Agentic Pipeline – The agent translates PyTorch code into CUDA kernels (Stages 1 & 2), then applies evolutionary optimization (Stage 3) like crossover prompting, leading to an Innovation Archive (Stage 4) that reuses “stepping stone” kernels for further gains.
Stage 1: PyTorch Modules to Functions The AI CUDA Engineer first converts a PyTorch nn.Module to Functional PyTorch using an LLM. The code is also validated for correctness.
Stage 2: Functional PyTorch to Working CUDA The agent translated the functional PyTorch code to a working CUDA kernel. using an LLM. The kernel is loaded and assessed for numerical correctness.
Stage 3: Evolutionary CUDA Runtime Optimization They use an evolutionary optimization process (including advanced prompting strategies, standard LLMs, and reasoning models like o3-mini & DeepSeek-R1) to ensure only the best CUDA kernels are produced.
Stage 4: Innovative Archive RAG is used to obtain high-performing kernels from related tasks; these are provided as context (stepping stones) to achieve further translation and performance gains. Newly-discovered CUDA kernels can also be added to the archive in the process.
Kernel Runtime Speedups – The team claims that The AI CUDA Engineer discovers CUDA kernels with speedups that reach as high as 10-100x faster than native and compiled kernels in PyTorch. It can also convert entire ML architectures into optimized CUDA kernels. Online users have challenged the claimed speedups (Sakana AI has provided an update on the issue).
Performance – The AI CUDA Engineer robustly translates PyTorch Code to CUDA Kernels. It achieves more than a 90% translation success rate.
Highlighted AI CUDA Engineer-Discovered Kernels – Another claim is that The AI CUDA Engineer can robustly improve CUDA runtime. It outperforms PyTorch Native runtimes for 81% out of 229 considered tasks. 20% of all discovered CUDA kernels are at least twice as fast as their PyTorch implementations.
The AI CUDA Engineer Archive – The team has made available an archive of more than 17000 verified CUDA kernels. These can be used for downstream fine-tuning of LLMs. There is also a website to explore verified CUDA kernels.
Technical Report | Blog | Dataset | Tweet
3). Native Sparse Attention

DeepSeek-AI and collaborators present Native Sparse Attention (NSA), a novel sparse attention mechanism designed to improve computational efficiency while maintaining model performance in long-context language modeling.
Key contributions:
Hierarchical Sparse Attention – NSA combines coarse-grained compression, fine-grained token selection, and sliding window mechanisms to balance global context awareness and local precision.
Hardware-Aligned Optimization – The authors introduce a blockwise sparse attention mechanism optimized for Tensor Core utilization, reducing memory bandwidth constraints and enhancing efficiency.
End-to-End Trainability – Unlike prior sparse attention methods that focus mainly on inference, NSA enables fully trainable sparsity, reducing pretraining costs while preserving model capabilities.
Results and Impact:
Outperforms Full Attention – Despite being sparse, NSA matches or exceeds Full Attention on general benchmarks, long-context reasoning, and instruction-based tasks.
Massive Speedups – NSA achieves up to 11.6× speedup over Full Attention on 64k-token sequences across all stages (decoding, forward, and backward passes).
Strong Long-Context Performance – In 64k Needle-in-a-Haystack retrieval, NSA achieves perfect accuracy, significantly outperforming other sparse methods.
Enhanced Chain-of-Thought Reasoning – Fine-tuned NSA surpasses Full Attention on AIME mathematical reasoning tasks, suggesting improved long-range logical dependencies.
By making sparse attention natively trainable and optimizing for modern hardware, NSA provides a scalable solution for next-gen LLMs handling extremely long contexts.
4). Large Language Diffusion Model

Proposes LLaDA, a diffusion-based approach that can match or beat leading autoregressive LLMs in many tasks.
Key highlights:
Questioning autoregressive dominance – While almost all large language models (LLMs) use the next-token prediction paradigm, the authors propose that key capabilities (scalability, in-context learning, instruction-following) actually derive from general generative principles rather than strictly from autoregressive modeling.
Masked diffusion + Transformers – LLaDA is built on a masked diffusion framework that learns by progressively masking tokens and training a Transformer to recover the original text. This yields a non-autoregressive generative model—potentially addressing left-to-right constraints in standard LLMs.
Strong scalability – Trained on 2.3T tokens (8B parameters), LLaDA performs competitively with top LLaMA-based LLMs across math (GSM8K, MATH), code (HumanEval), and general benchmarks (MMLU). It demonstrates that the diffusion paradigm scales similarly well to autoregressive baselines.
Breaks the “reversal curse” – LLaDA shows balanced forward/backward reasoning, outperforming GPT-4 and other AR models on reversal tasks (e.g. reversing a poem line). Because diffusion does not enforce left-to-right generation, it is robust at backward completions.
Multi-turn dialogue and instruction-following – After supervised fine-tuning, LLaDA can carry on multi-turn conversations. It exhibits strong instruction adherence and fluency similar to chat-based AR LLMs—further evidence that advanced LLM traits do not necessarily rely on autoregression.
5). SWE-Lancer

Researchers from OpenAI introduce SWE-Lancer, a benchmark evaluating LLMs on 1,488 real-world freelance software engineering tasks from Upwork, collectively worth $1M in payouts.
Key takeaways:
A new benchmark for software engineering automation – Unlike previous coding benchmarks focused on isolated tasks (e.g., program synthesis, competitive programming), SWE-Lancer tests full-stack engineering and managerial decision-making. It evaluates both Individual Contributor (IC) SWE tasks, where models write and debug code, and SWE Manager tasks, where models select the best technical proposal.
Real-world economic impact – Each task has a verifiable monetary value, mirroring freelance market rates. Payouts range from $250 bug fixes to $32,000 feature implementations. The benchmark maps model performance to earnings, offering a tangible metric for automation potential.
Rigorous evaluation with end-to-end tests – Unlike unit-test-based benchmarks, SWE-Lancer employs browser-driven, triple-verified end-to-end (E2E) tests developed by professional engineers. These tests reflect real-world software validation and prevent grading hacks.
Challenging tasks remain unsolved – Even the best-performing model, Claude 3.5 Sonnet, only solves 26.2% of IC SWE tasks and 44.9% of SWE Manager tasks, earning $208K out of $500.8K in the open-source SWE-Lancer Diamond set. This highlights the gap between current AI capabilities and human software engineers.
Key findings on LLM performance:
Test-time compute boosts accuracy – Increasing inference-time reasoning improves success rates, particularly on high-value tasks.
Managerial tasks are easier than IC coding – Models perform better at selecting proposals than writing original code.
Effective tool use matters – Stronger models leverage an interactive user tool to debug issues, mimicking how engineers iterate on code.
Localization vs. root cause analysis – LLMs can pinpoint faulty code but often fail to implement comprehensive fixes.
6). Optimizing Model Selection for Compound AI
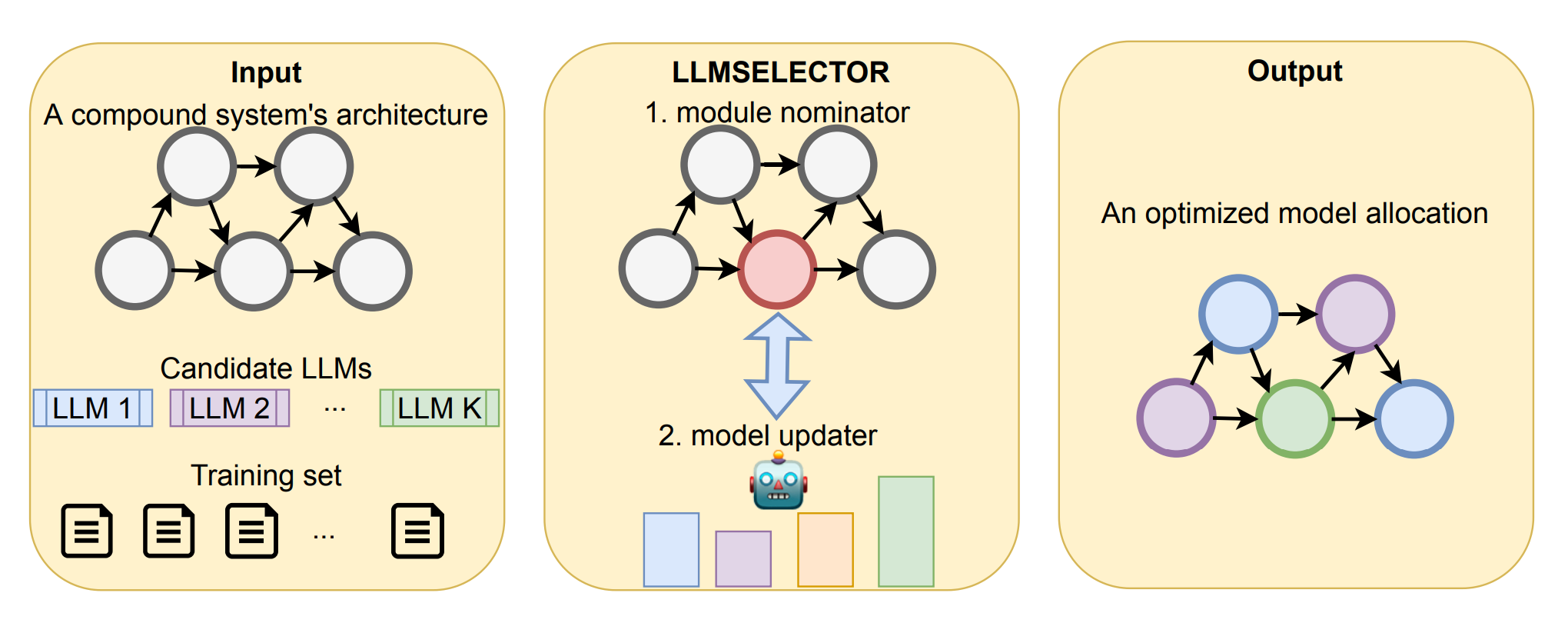
Researchers from Microsoft Research and collaborators introduce LLMSelector, a framework to improve multi-call LLM pipelines by selecting the best model per module instead of using one LLM everywhere.
Key insights include:
Large performance boost with per-module model choices – Rather than relying on a single LLM for each sub-task in compound systems, the authors show that mixing different LLMs can yield 5%–70% higher accuracy. Each model has unique strengths (e.g., better at critique vs. generation), so assigning modules selectively substantially improves end-to-end results.
LLMSelector algorithm – They propose an iterative routine that assigns an optimal model to each module, guided by a novel “LLM diagnoser” to estimate per-module performance. The procedure scales linearly with the number of modules—far more efficient than exhaustive search.
Monotonicity insights – Empirically, boosting any single module’s performance (while holding others fixed) often improves the overall system. This motivates an approximate factorization approach, where local gains translate into global improvements.
LLMSelector works for any static compound system with fixed modules (e.g., generator–critic–refiner).
7). Open-Reasoner-Zero
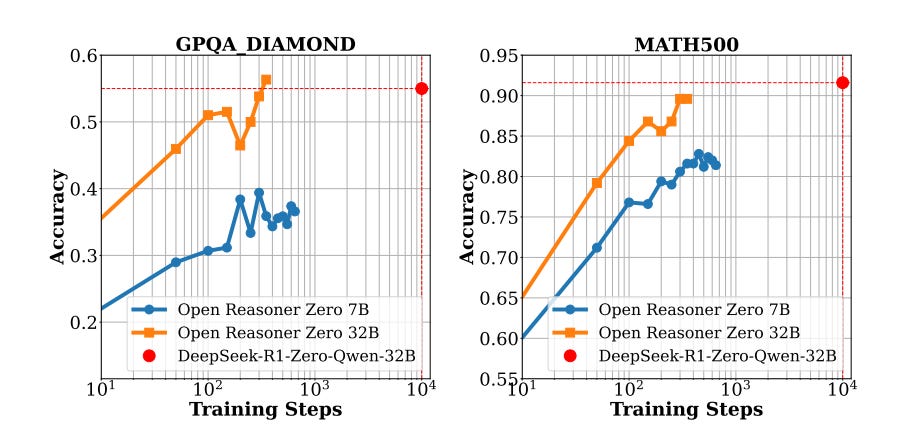
Open-Reasoner-Zero (ORZ) is an open-source large-scale minimalist reinforcement learning (RL) framework that enhances reasoning capabilities. ORZ demonstrates significant scalability requiring only 1/30th of the training steps of DeepSeek-R1-Zero-Qwen-32B to outperform it on GPQA Diamond.
Key contributions and findings:
Minimalist RL Training Works – Unlike traditional RLHF setups, ORZ removes KL regularization and relies on vanilla PPO with GAE (λ=1, γ=1) and a simple rule-based reward function to scale both response length and reasoning accuracy.
Outperforms Closed-Source Models – ORZ-32B beats DeepSeek-R1-Zero-Qwen-32B on GPQA Diamond while using significantly fewer training steps, proving that training efficiency can be drastically improved with a streamlined RL pipeline.
Emergent Reasoning Abilities – ORZ exhibits "step moments", where response lengths and accuracy suddenly increase, indicating emergent reasoning capabilities with continued training.
Massive Scaling Potential – ORZ’s response length scaling mirrors trends seen in DeepSeek-R1-Zero (671B MoE), but with 5.8x fewer training steps. Training shows no signs of saturation, hinting at even further gains with continued scaling.
Fully Open-Source – The training code, model weights, data, and hyperparameters are all released, ensuring reproducibility and enabling broader adoption in the research community.
Mathematical & Logical Reasoning – ORZ significantly improves accuracy on benchmarks like MATH500, AIME2024, and AIME2025 with a simple binary reward system that only evaluates answer correctness.
Generalization – Without any instruction tuning, ORZ-32B outperforms Qwen2.5-32B Instruct on MMLU_PRO, showcasing its strong reasoning generalization despite being trained purely on RL.
8). MoBA
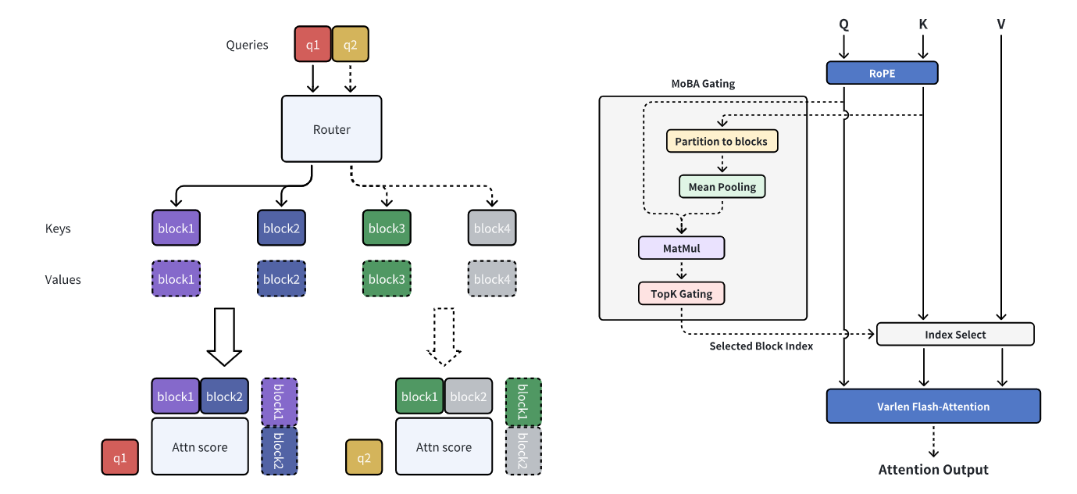
MoBA is a new attention mechanism that enhances efficiency in handling long-context sequences for LLMs while maintaining strong performance.
Key insights:
Adaptive Attention for Long Contexts – MoBA applies the Mixture of Experts (MoE) paradigm to the attention mechanism, allowing each query token to attend selectively to the most relevant key-value blocks rather than the full context. This enables models to handle extended sequences efficiently.
Seamless Transition Between Full and Sparse Attention – Unlike static sparse attention methods like sliding window or sink attention, MoBA can dynamically switch between full and sparse attention modes, ensuring adaptability without sacrificing generalization.
Improved Computational Efficiency – By partitioning sequences into blocks and using a gating mechanism to route queries, MoBA significantly reduces computational complexity, achieving up to 6.5× speedup over FlashAttention in prefill and scaling efficiently to 10M tokens with a 16× reduction in computation time.
Comparable Performance to Full Attention – Extensive experiments show that MoBA achieves language modeling loss and benchmark performance nearly identical to full attention, even at high sparsity levels (~95.31%). It matches full attention in long-context benchmarks like Needle in a Haystack and RULER@128K.
Hybrid MoBA-Full Attention Strategy – MoBA can be integrated flexibly with standard Transformers, allowing for layer-wise hybridization (mixing MoBA and full attention at different layers), which improves supervised fine-tuning (SFT) stability and long-context retention.
9). The Danger of Overthinking

This paper investigates overthinking in Large Reasoning Models (LRMs)—a phenomenon where models prioritize extended internal reasoning over interacting with their environment. Their study analyzes 4,018 software engineering task trajectories to understand how reasoning models handle decision-making in agentic settings.
Key findings:
Overthinking reduces task performance – Higher overthinking scores (favoring internal reasoning over real-world feedback) correlate with lower issue resolution rates, especially in reasoning-optimized models. Simple interventions, like selecting solutions with the lowest overthinking scores, improve performance by 30% while reducing compute costs by 43%.
Three failure patterns identified – The study categorizes overthinking into:
Analysis Paralysis (excessive planning without action),
Rogue Actions (executing multiple steps without awaiting feedback), and
Premature Disengagement (abandoning tasks based on internal assumptions).
These behaviors explain why models struggle to balance reasoning depth with actionable decisions.
Reasoning models are more prone to overthinking – Compared to non-reasoning models, LRMs exhibit 3× higher overthinking scores on average, despite their superior reasoning capabilities.
Function calling mitigates overthinking – Models with native function-calling support show significantly lower overthinking scores, suggesting structured execution pathways improve efficiency in agentic environments.
Scaling and mitigation strategies – The researchers propose reinforcement learning adjustments and function-calling optimizations to curb overthinking while maintaining strong reasoning capabilities.
10). Inner Thinking Transformers

Inner Thinking Transformer (ITT) is a new method that enhances reasoning efficiency in small-scale LLMs via dynamic depth scaling. ITT aims to mitigate parameter bottlenecks in LLMs, providing scalable reasoning efficiency without expanding model size.
Key contributions:
Adaptive Token Processing – ITT dynamically allocates extra computation to complex tokens using Adaptive Token Routing. This allows the model to focus on difficult reasoning steps while efficiently handling simple tokens.
Residual Thinking Connections (RTC) – A new residual accumulation mechanism iteratively refines token representations, allowing the model to self-correct without increasing parameters.
Test-Time Scaling without Extra Parameters – ITT achieves 96.5% of a 466M Transformer’s accuracy using only 162M parameters, reducing training data needs by 43.2% while outperforming loop-based alternatives in 11 benchmarks.
Elastic Deep Thinking – ITT allows flexible scaling of computation at inference time, optimizing between accuracy and efficiency dynamically.
Inner Thinking Transformer (ITT) paper blowing my mind