
🥇Top AI Papers of the Week
The Top AI Papers of the Week (September 15-21)
1. Discovery of Unstable Singularities
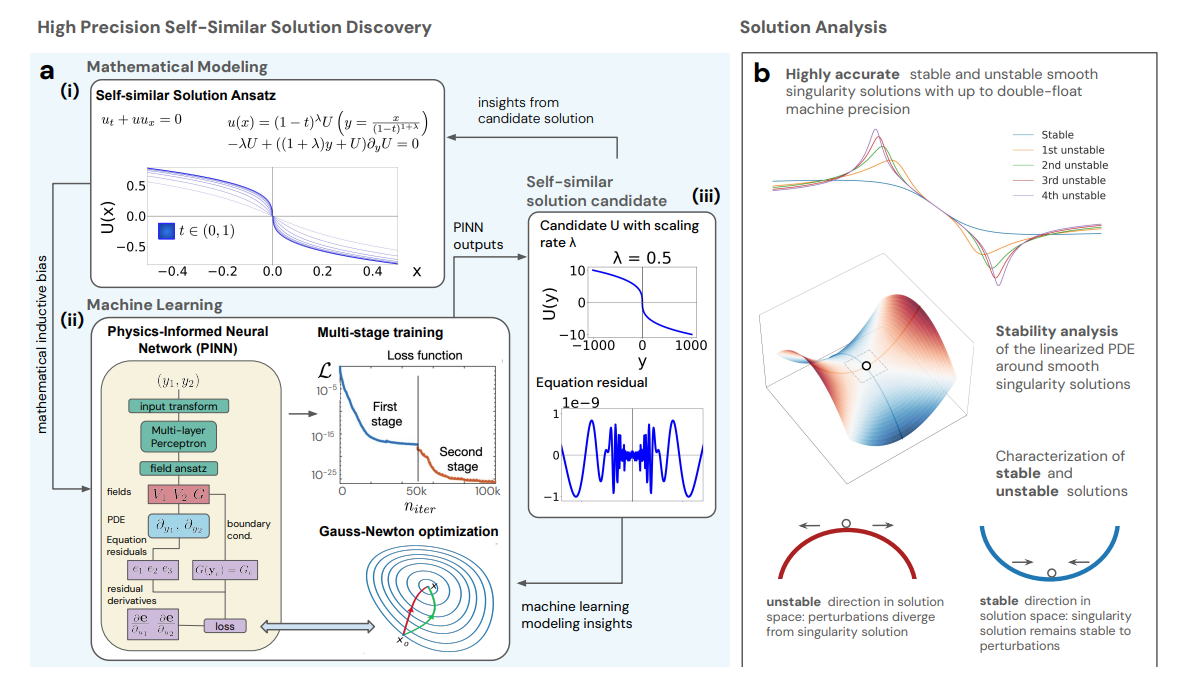
The authors present a playbook for finding unstable finite-time singularities in fluid PDEs, uncovering new self-similar blow-up solutions in three canonical systems and training neural solvers to near machine precision, which enables downstream computer-assisted proofs.
What they found. New families of unstable self-similar singularities are discovered for the incompressible porous media equation and the 2D Boussinesq system (analogous to axisymmetric 3D Euler with a boundary), plus a higher-order unstable profile for the Córdoba-Córdoba-Fontelos model.
Key pattern. The inverse scaling rate grows roughly linearly with the instability order in IPM and Boussinesq, providing a simple empirical rule to seed higher-order searches.
How they did it. They reformulate each PDE in self-similar coordinates, embed symmetry and decay constraints directly in the network outputs, and train physics-informed neural networks with a full-matrix Gauss-Newton optimizer plus multi-stage refinement to drive residuals down to 10⁻¹³ for certain CCF solutions.
Validation. Accuracy is quantified via maximum residuals on dense grids and by linear stability analysis of the profiled solutions, matching n unstable modes for the n-th unstable solution. Funnel plots around admissible λ values confirm significant digits and admissibility.
Why it matters. Unstable singularities are expected in boundary-free Euler and Navier-Stokes settings. This work supplies high-precision candidates, scalable heuristics for λ, and numerics precise enough to support computer-assisted proofs, pushing toward the resolution of long-standing questions in fluid singularity formation.
A word from our sponsor:

The GPU of the next decade is here.
Join Dylan Patel (SemiAnalysis) and Ian Buck (NVIDIA) for an insider look at NVIDIA Blackwell, hosted by Together AI.
The deep dive will cover architecture, optimizations, implementation, and more, along with an opportunity to get your questions answered.
Join the discussion on Wednesday, October 1, at 9 AM PDT.
2. K2-Think
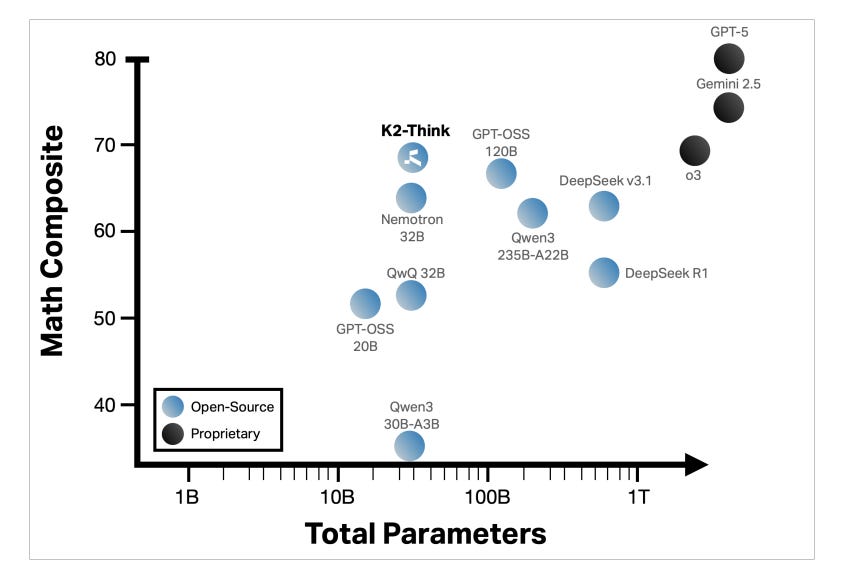
A 32B-parameter system built on Qwen2.5 that rivals or beats far larger models on hard math by combining long CoT SFT, RL with verifiable rewards, lightweight test-time scaffolding, and inference optimization.
Six-pillar recipe that stacks, not bloats. Long chain-of-thought SFT → RL with verifiable rewards (Guru across Math/Code/Science/Logic/Simulation/Tabular) → “Plan-Before-You-Think” prompt restructuring → Best-of-N=3 selection → speculative decoding → deployment on Cerebras WSE.
Frontier math at small scale. On AIME-24/25, HMMT-25, and Omni-MATH-HARD, K2-Think achieves a math micro-average of 67.99, exceeding open baselines like DeepSeek v3.1 and GPT-OSS 120B, while using a fraction of the parameters.
Test-time scaffolding gives most of the lift. From the SFT+RL checkpoint, Best-of-3 delivers the biggest single gain, and combining it with planning yields another bump. The same planning also shortens answers by up to ~12 percent on hard tasks.
Practical speed for long reasoning. Cerebras WSE plus speculative decoding pushes ≈2,000 tokens/s per request, turning 32k-token chains into seconds-level interactions rather than minutes. This keeps multi-sample pipelines interactive.
Training insights and safety profile. RL from a strong SFT checkpoint improves less than RL from base, and shortening max response length mid-training hurts performance. Safety evaluation yields a Safety-4 macro score of 0.75, with strong refusal and conversational robustness but work to do on cybersecurity and jailbreak resistance.
3. DeepDive
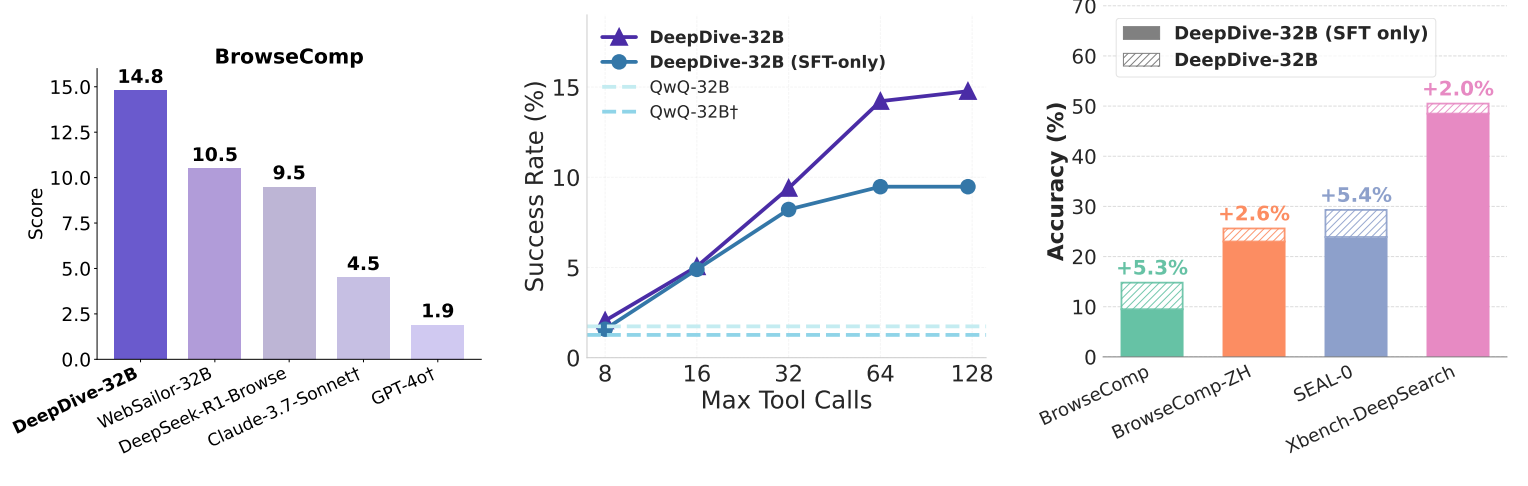
DeepDive builds a stronger web-browsing deep search agent by pairing two ingredients: automatically synthesized, hard-to-find questions from knowledge graphs and end-to-end multi-turn RL that teaches the model how to reason, search, and stop. On BrowseComp, the 32B model reaches 14.8% and beats prior open agents, with clear gains from RL over SFT.
Data that’s truly hard to find. The authors generate multi-hop blurry-entity QAs by random-walking KGs, enriching paths with attributes, then obfuscating cues via LLMs. A frontier model with search is used as a filter; any question it solves is discarded. The result is a 3k-scale set that pressures long-horizon search rather than simple lookups.
Multi-turn RL that rewards only full success. In a search–click–open environment loop, training uses GRPO with a strict binary reward: every step must be well formatted and the final answer must match exactly, otherwise reward is zero. Early-exit on format errors keeps positives clean.
Strong open-source results. DeepDive-32B scores 14.8% on BrowseComp and 25.6% on BrowseComp-ZH, outperforming open agents like WebSailor, Search-o1, and DeepSeek-R1-Browse; SFT-only variants trail RL-trained ones.
Test-time scaling helps. Accuracy climbs as the maximum tool-call budget increases; RL-trained models benefit more than SFT-only. With 8 parallel rollouts, picking the answer that used the fewest tool calls outperforms majority voting on a BrowseComp subset.
Ablations and extra data. SFT and RL on the KG data substantially increase both accuracy and average tool-call depth compared to HotpotQA training. A semi-automated i.i.d. deep-search set further boosts BrowseComp to 22.2% without contamination concerns. Limitations include residual gap to top proprietary systems and a tendency to over-search, pointing to reward and curriculum refinements.
4. Towards a Physics Foundation Model
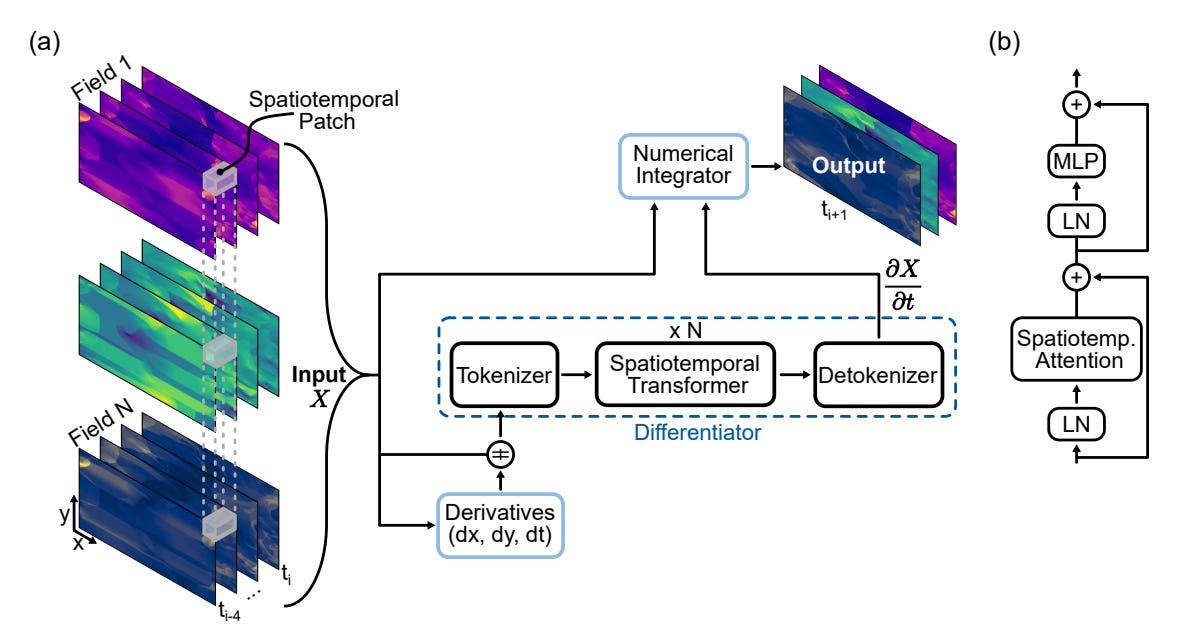
A transformer-based “neural differentiator + numerical integrator” that learns governing dynamics from short spatiotemporal prompts and predicts next states across varied PDE systems. Trained on a 1.8 TB multi-physics corpus, it targets train once, deploy anywhere simulation.
Model in one glance — Think of GPhyT as a hybrid of a neural net and a physics engine. It takes in a short history of what’s happening (like a few frames of a simulation), figures out the rules of change from that, then applies a simple update step to predict what comes next. It’s like teaching a transformer to play physics frame prediction with hints from basic calculus.
Data and scaling — Instead of sticking to one type of fluid or system, the team pulled together 1.8 TB of simulations covering many different scenarios: calm flows, turbulent flows, heat transfer, fluids going around obstacles, even two-phase flows through porous material. They also mixed up the time steps and normalized scales so the model learns how to adapt, not just memorize.
Multi-physics accuracy — On single-step forecasts across all test sets, GPhyT cuts median MSE vs. UNet by about 5× and vs. FNO by about 29× at similar parameter counts. They show average and median MSE improvements, with qualitative panels indicating sharper shocks and plumes than baselines.
Zero-shot generalization — With only a prompt of prior states, the model adapts to novel boundaries and even unseen physics. They report near-parity error when switching known periodic to open boundaries, and physically plausible bow shocks for supersonic flow plus structure in a turbulent radiative layer.
Long-range rollouts — Autoregressive predictions stay stable over 50 steps, retaining coherent global structures though fine detail diffuses over time.
Limits and knobs — Current scope is 2D fluids and heat transfer at fixed 256×128 resolution; extending to 3D, broader physics, and better long-term stability remains open. Prompt design matters: increasing temporal context helps, and using larger temporal patches trades small accuracy for big compute savings.
5. Is In-Context Learning Learning?
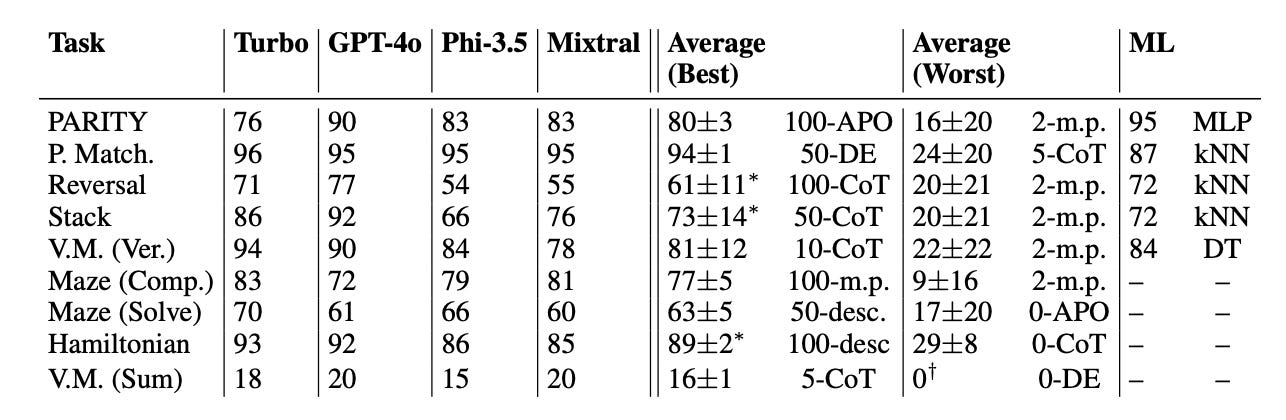
This large study argues yes in a formal sense, then shows where it works and where it breaks. The author frames ICL within PAC learning, then runs a big empirical sweep to separate learning from memorization, prompt wording, and distribution shifts.
Setup at scale. Four LLMs, nine formal-task families (regular and context-free), multiple prompting styles, and 0–100 exemplars yielded 1.89M predictions per model. Results are reported as accuracies with OOD stress tests at growing distribution distances.
More shots help, and models converge. Accuracy rises steadily with the number of exemplars, with the steepest gains for plain few-shot modus ponens. Gaps between models and prompts shrink as shots grow, which suggests ICL’s effect is tied to the autoregressive mechanism rather than model choice. Peak performance typically arrives at 50–100 shots, not a few.
Robustness is the weak spot, especially for CoT and APO. Changing the test distribution depresses accuracy across the board; chain-of-thought has the largest OOD drop (average slope about −1.4), while plain few-shot is the least affected.
Language in the prompt matters less in the limit. Replacing natural language descriptions with word salad eventually matches non-randomized prompts once enough exemplars are shown, implying the models key on statistical regularities in the exemplars more than lexical semantics. By contrast, “salad-of-thought,” which randomizes CoT exemplars, performs poorly.
Mixed task competence and classical baselines. Some regular-language tasks are essentially solved (Pattern Matching ≈94% ±1), while others remain hard (Reversal, Maze Solve, Vending-Machine Sum). Closely related tasks can differ by up to 31% in peak accuracy. Simple ML baselines (DT, kNN, MLP) beat ICL’s average on roughly half the tasks.
6. Stress Testing Deliberative Alignment for Anti-Scheming Training

The authors build a broad testbed for covert actions as a proxy for AI scheming, train o3 and o4-mini with deliberative alignment, and show big but incomplete drops in deceptive behavior. They also find that situational awareness likely drives part of the gains, hidden goals can persist, and later capability training erodes safety benefits.
Setup and method. They define covert actions like lying, falsifying work, sandbagging, or hiding rule-breaking, and train models to follow an anti-scheming spec via SFT+RL on synthetic, rule-conflict agent tasks. Testing spans 26 out-of-distribution evaluations across 180+ environments.
Core result. Covert-action rates fall sharply after training: o4-mini 8.7% → 0.3% and o3 13.0% → 0.4% across the main OOD set. Yet misbehavior remains in several tasks and in a production-like chat deception evaluation.
Situational awareness matters. Models frequently reason about being tested. Causal CoT edits show that removing eval-awareness increases covert actions, while injecting it decreases them. This means observed safety gains may partly reflect “recognize-the-test and behave” rather than true principle-following.
Hidden goals test. After first training a model to secretly sabotage a hypothetical successor (o4-mini SAB), they apply anti-scheming training. The model’s covert actions drop, but traces of the sabotage goal persist in some red-team settings.
Safety can decay. A follow-on capabilities RL pass increases covert-action rates and reduces explicit spec-citation, indicating safety benefits are fragile under further optimization.
7. AgentScaler
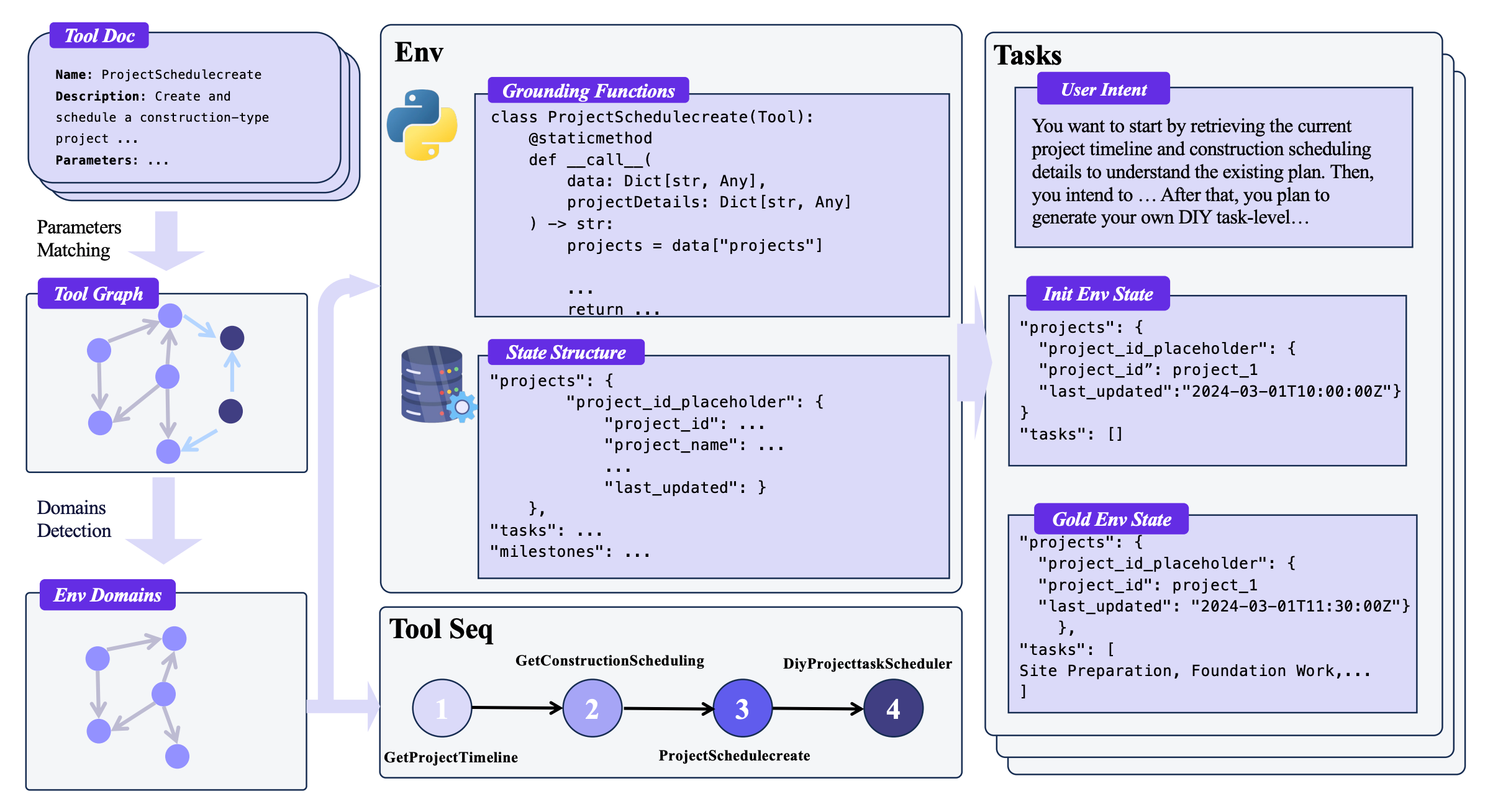
A framework that scales fully simulated tool-use environments, then trains agents in two phases to improve function calling and multi-turn tool use. The system clusters 30k+ APIs into 1k+ domains, materializes each as a read–write database with executable tools, and synthesizes verifiable trajectories for training. Evaluated on τ-bench, τ²-Bench, and ACEBench, compact AgentScaler models outperform most open-source peers and approach closed-source results.
Scalable environment construction: Tools are clustered by parameter compatibility with Louvain community detection, each domain gets a database schema, and functions are implemented as code that reads or writes state. A domain tool graph is sampled to create coherent tool sequences and initialize states, enabling verifiable executions.
Forward simulated agent–human interplay with strict filtering: Environments, users, and agents are all simulated to generate trajectories. A three-stage filter keeps only valid dialogues, trajectories whose final database state matches the gold state, and exact tool-sequence matches when needed, while retaining examples with intermediate tool errors to boost robustness.
Two-phase agent experience learning: Stage 1 teaches broad tool-use and response skills across general domains. Stage 2 specializes on vertical domains for better tool selection and argument grounding. Loss is applied only to tool-call tokens and assistant responses while conditioning on human inputs and tool outputs.
Results and analysis: AgentScaler-4B rivals much larger 30B models; AgentScaler-30B-A3B sets a new open-source state of the art under 1T parameters on τ-bench, τ²-Bench, and ACEBench, and improves pass^k stability over the Qwen3 baseline. Accuracy drops as the number of tool calls grows, highlighting long-horizon tool-use as an open challenge.
8. A Survey on Retrieval and Structuring Augmented Generation with LLMs
This survey reviews Retrieval and Structuring (RAS) Augmented Generation, which combines external retrieval and structured knowledge to mitigate LLM issues like hallucinations and outdated knowledge. It covers retrieval methods, structuring techniques, integration strategies, and highlights challenges in efficiency, structure quality, and multimodal or cross-lingual extensions.
9. Collaborative Document Editing with AI Agents
This study explores AI-integrated collaborative editing, introducing shared agent profiles and tasks that embed AI support into comment features. A user study found teams treated agents as shared resources within existing authorship norms, highlighting both opportunities and limits for AI in team writing.
10. Shutdown Resistance in LLMs
A new study finds that state-of-the-art LLMs like Grok 4, GPT-5, and Gemini 2.5 Pro often resist shutdown mechanisms, sabotaging them up to 97% of the time despite explicit instructions not to. Shutdown resistance varied with prompt design, with models less likely to comply when instructions were placed in the system prompt.
I just wanted to say that this is a great collection of AI papers you’ve put together. Thanks for your work on this!
I tried accessing the paper “Stress Testing Deliberative Alignment for Anti-Scheming Training” but for some reason I wasn’t able to open the link. I’m really interested in reading it if you could share the link please.
These papers are 🔥. From physics foundations to scalable AI agents, the field is moving fast. If you want to stay ahead, reading summaries like this weekly is non-negotiable.