
🥇Top AI Papers of the Week
The Top AI Papers of the Week (Mar 17 - 23)
1). A Review of DeepSeek Models

This paper provides an in-depth review of the cutting-edge techniques behind DeepSeek's open-source LLMs—DeepSeek-V3 and DeepSeek-R1. These models achieve state-of-the-art performance with significantly lower resource requirements compared to proprietary counterparts. Key highlights include:
Multi-Head Latent Attention (MLA) – Introduces efficient attention by compressing keys and values into a latent vector, dramatically reducing memory consumption for long-context tasks without sacrificing performance. MLA employs low-rank compression and decoupled Rotary Position Embeddings, outperforming standard multi-head attention.
Advanced Mixture of Experts (MoE) – Incorporates fine-grained expert segmentation and dedicated shared experts, significantly enhancing combinational flexibility. An innovative load-balancing strategy further optimizes computational efficiency and model performance.
Multi-Token Prediction (MTP) – Enhances training efficiency by predicting multiple subsequent tokens simultaneously. Although effective, the additional training overhead warrants further optimization.
Algorithm-Hardware Co-design – Presents engineering advancements like DualPipe scheduling, an algorithm designed to eliminate pipeline bubbles, and FP8 mixed-precision training, maximizing computational efficiency and reducing training resources.
Group Relative Policy Optimization (GRPO) – Offers a streamlined RL algorithm eliminating value function approximation from PPO, directly estimating advantages from grouped outputs, drastically reducing GPU memory usage.
Post-Training Reinforcement Learning – Demonstrates pure RL's capability in DeepSeek-R1-Zero, which learns advanced reasoning without supervised fine-tuning. DeepSeek-R1 further improves this approach via iterative cold-start fine-tuning, rejection sampling, and RL alignment to enhance reasoning quality and language consistency.
2). Towards Hierarchical Multi-Step Reward Models for Enhanced Reasoning in LLMs

It proposes a Hierarchical Reward Model (HRM) that addresses reward hacking and error propagation issues in fine-grained LLM reasoning. They also introduce Hierarchical Node Compression (HNC) to augment MCTS-based automatic data annotation, boosting label diversity and robustness at minimal computational cost.
Hierarchical vs. single-step rewards – Traditional Process Reward Models (PRM) assign fine-grained rewards per step but can penalize corrections of earlier mistakes. By contrast, HRM assesses multiple consecutive steps, capturing coarse-grained coherence and enabling self-correction of earlier errors. This yields more robust and reliable evaluations.
Solving “reward hacking” – PRM often misleads policy models into short-sighted strategies that artificially maximize step-level rewards. HRM’s multi-step feedback framework penalizes incomplete or incoherent reasoning, mitigating reward hacking behaviors.
Hierarchical Node Compression (HNC) – Generating step-by-step annotations with Monte Carlo Tree Search (MCTS) is computationally heavy. The HNC method merges adjacent nodes in the search tree, expanding the dataset with controlled noise yet minimal extra cost. This more diverse training set enhances the reward model’s robustness.
Stronger generalization – Experiments on PRM800K and cross-domain tasks (MATH500, GSM8K) show HRM consistently outperforms standard outcome-based or step-based reward models, particularly on deeper, more complex chains of thought. Policy models fine-tuned with HRM yield higher accuracy and more stable step-by-step solutions.
Sponsor Message

We’re excited to announce our new course on Prompt Engineering for Developers.
We’re offering our subscribers a 25% discount — use code AGENT25 at checkout. This is a limited-time offer.
3). DAPO: An Open-Source LLM Reinforcement Learning System at Scale

It introduces DAPO, a fully open-source, large-scale RL system that boosts the chain-of-thought reasoning capabilities of LLMs.
DAPO raises the upper clipping threshold (“Clip-Higher”) in PPO-style training, preventing entropy collapse and helping the policy explore more diverse tokens.
By filtering out samples that are always correct or always wrong, DAPO focuses training on prompts with useful gradient signals, speeding up convergence in fewer updates.
Instead of averaging losses at the sample level, DAPO applies policy gradients per token, making each reasoning step matter. This ensures both high-quality and length-appropriate outputs.
The system masks or softly penalizes excessively long answers, preventing meaningless verbosity or repetitive text.
DAPO achieves SOTA math performance on the AIME 2024 test set. Specifically, DAPO trained from a Qwen2.5-32B base achieves 50% accuracy, outperforming DeepSeek’s R1 with less training time, and showcasing open-source reproducibility at scale.
4). Compute Optimal Scaling of Skills

Researchers from the University of Wisconsin and Meta AI investigate how different skills (knowledge-based QA vs. code generation) exhibit contrasting optimal scaling behaviors in LLMs. Their key question: does the compute-optimal trade-off between model size and data volume depend on the type of skill being learned? Surprisingly, the answer is yes—they show distinct “data-hungry” vs. “capacity-hungry” preferences per skill. Highlights:
Skill-dependent scaling laws – Traditional scaling laws optimize the overall loss on a generic validation set. However, this paper shows that knowledge tasks prefer bigger models (capacity-hungry), while code tasks prefer more data tokens (data-hungry).
Differences persist even after balancing data – Tweaking the pretraining mix (e.g. adding more code data) can shift that skill’s optimal ratio, but fundamental differences remain. Knowledge-based QA still tends to need more parameters, code still benefits from bigger data budgets.
Huge impact of validation set – Choosing a validation set that doesn’t reflect the final skill mix can lead to misaligned compute-optimal model sizes by 30%–50% at lower compute scales. Even at higher scales, suboptimal validation sets skew the best parameter count by over 10%.
Practical takeaway – Model developers must pick or design validation sets that represent the real skill mix. If your ultimate goal is to excel at knowledge-based QA, you likely need a more capacity-hungry strategy. If it’s coding tasks, you might focus on data-hungry training.
5). Thinking Machines
This survey provides an overview and comparison of existing reasoning techniques and presents a systematic survey of reasoning-imbued language models.
6). A Survey on Efficient Reasoning

This new survey investigates techniques to address the "overthinking phenomenon" in Large Reasoning Models (LRMs), categorizing existing methods into model-based optimizations, output-based reasoning reductions, and prompt-based efficiency enhancements. The survey highlights ongoing efforts to balance reasoning capability and computational efficiency in models like OpenAI o1 and DeepSeek-R1.
7). Agentic Memory for LLM Agents
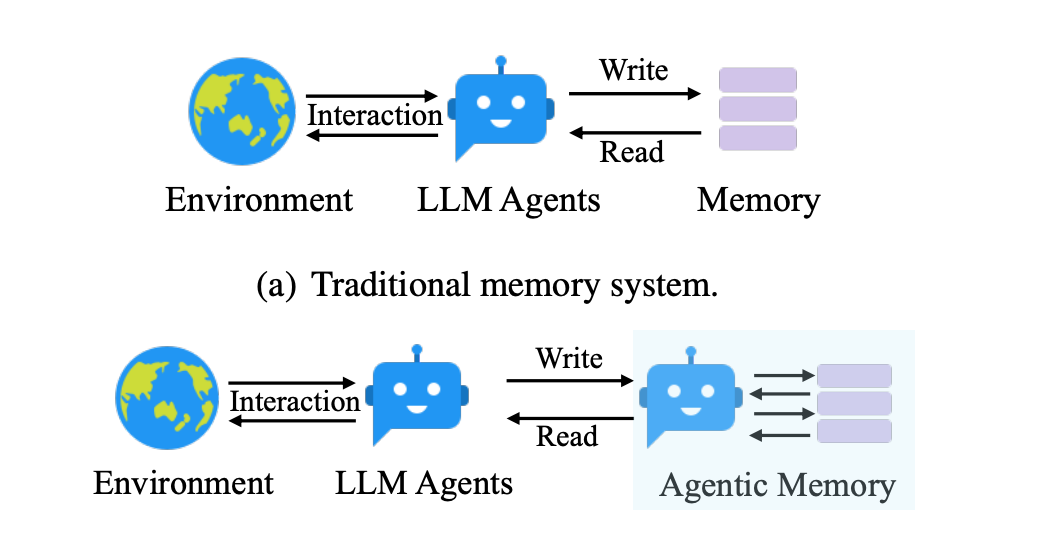
Researchers from Rutgers University and Ant Group propose a new agentic memory system for LLM agents, addressing the need for long-term memory in complex real-world tasks. Key highlights include:
Dynamic & Zettelkasten-inspired design – A-MEM autonomously creates comprehensive memory notes—each with textual attributes (keywords, tags) and embeddings—then interlinks them based on semantic similarities. The approach is inspired by the Zettelkasten method of atomic note-taking and flexible linking, but adapted to LLM workflows, allowing more adaptive and extensible knowledge management.
Automatic “memory evolution” – When a new memory arrives, the system not only adds it but updates relevant older memories by refining their tags and contextual descriptions. This continuous update enables a more coherent, ever-improving memory network capable of capturing deeper connections over time.
Superior multi-hop reasoning – Empirical tests on long conversational datasets show that A-MEM consistently outperforms static-memory methods like MemGPT or MemoryBank, especially for complex queries requiring links across multiple pieces of information. It also reduces token usage significantly by selectively retrieving only top-k relevant memories, lowering inference costs without sacrificing accuracy.
8). DeepMesh
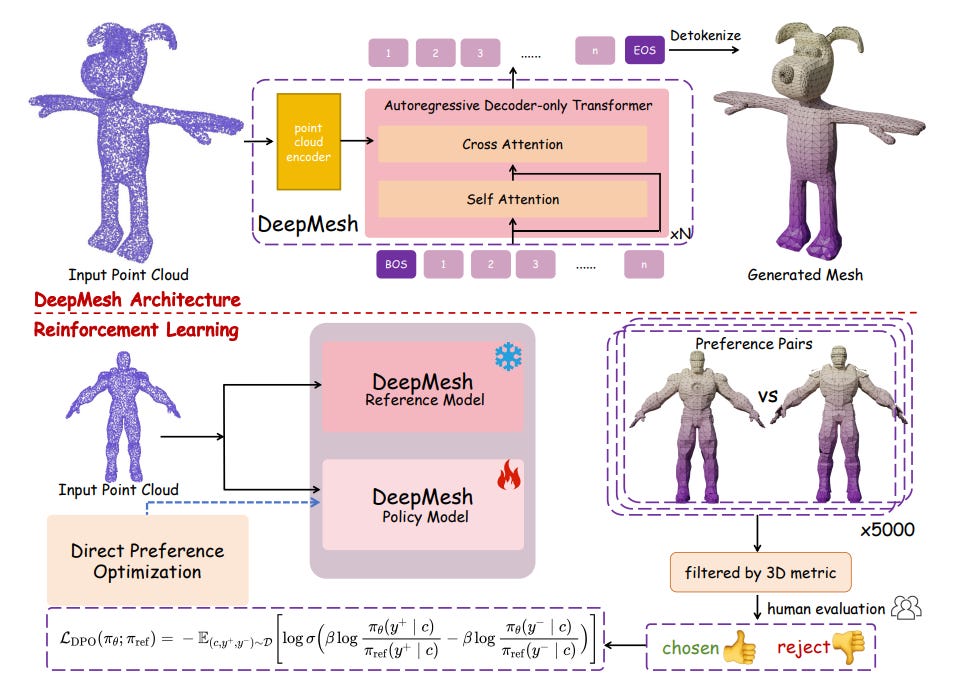
Researchers from Tsinghua University, Nanyang Technological University, and ShengShu propose DeepMesh, a transformer-based system that generates high-quality 3D meshes with artist-like topology. Key ideas include:
Efficient mesh tokenization – They introduce a new algorithm that compresses mesh sequences by ~72% while preserving geometric detail, enabling higher-resolution mesh generation at scale.
Artist-like topology – Unlike dense or incomplete meshes from existing approaches, DeepMesh predicts structured triangle layouts that are aesthetic and easy to edit, thanks to a refined pre-training process and better data curation.
Reinforcement Learning with human feedback – The authors adopt Direct Preference Optimization (DPO) to align mesh generation with human preferences. They collect pairwise user labels on geometry quality and aesthetics, then fine-tune the model to produce more appealing, complete meshes.
Scalable generation – DeepMesh can handle large meshes (tens of thousands of faces) and supports both point cloud- and image-based conditioning, outperforming baselines like MeshAnythingv2 and BPT in geometric accuracy and user ratings.
9). Deep Learning is Not So Mysterious or Different

Andrew Gordon Wilson (New York University) argues that deep learning phenomena such as benign overfitting, double descent, and the success of overparametrization are neither mysterious nor exclusive to neural networks. Major points include:
Benign Overfitting & Double Descent Explained – These phenomena are reproducible with simple linear models, challenging their supposed exclusivity to neural networks. The author demonstrates benign overfitting with high-order polynomials featuring order-dependent regularization, emphasizing that flexible models can perfectly fit noisy data yet generalize well when structured data is present.
Soft Inductive Biases as Unifying Principle – The paper advocates for soft inductive biases instead of traditional hard constraints. Rather than restricting a model's hypothesis space to prevent overfitting, a model can remain flexible, adopting a soft preference for simpler solutions consistent with observed data. Examples include polynomial regression with increasing penalties on higher-order terms and neural networks benefiting from implicit regularization effects.
Established Frameworks Describe Phenomena – Wilson emphasizes that longstanding generalization frameworks like PAC-Bayes and countable hypothesis bounds already explain the supposedly puzzling behaviors of neural networks. The author argues against the notion that deep learning demands entirely new theories of generalization, highlighting how existing theories adequately address these phenomena.
Unique Aspects of Deep Learning – While asserting deep learning is not uniquely mysterious, the paper acknowledges genuinely distinctive properties of neural networks, such as mode connectivity (the surprising connectedness of different network minima), representation learning (adaptive basis functions), and their notable universality and adaptability in diverse tasks.
Practical and Theoretical Implications – The author critiques the widespread belief in neural network exceptionalism, urging closer collaboration between communities to build on established generalization theories rather than reinventing them. Wilson concludes by identifying genuine open questions in deep learning, particularly around scale-dependent implicit biases and representation learning.
10). GNNs as Predictors of Agentic Workflow Performances
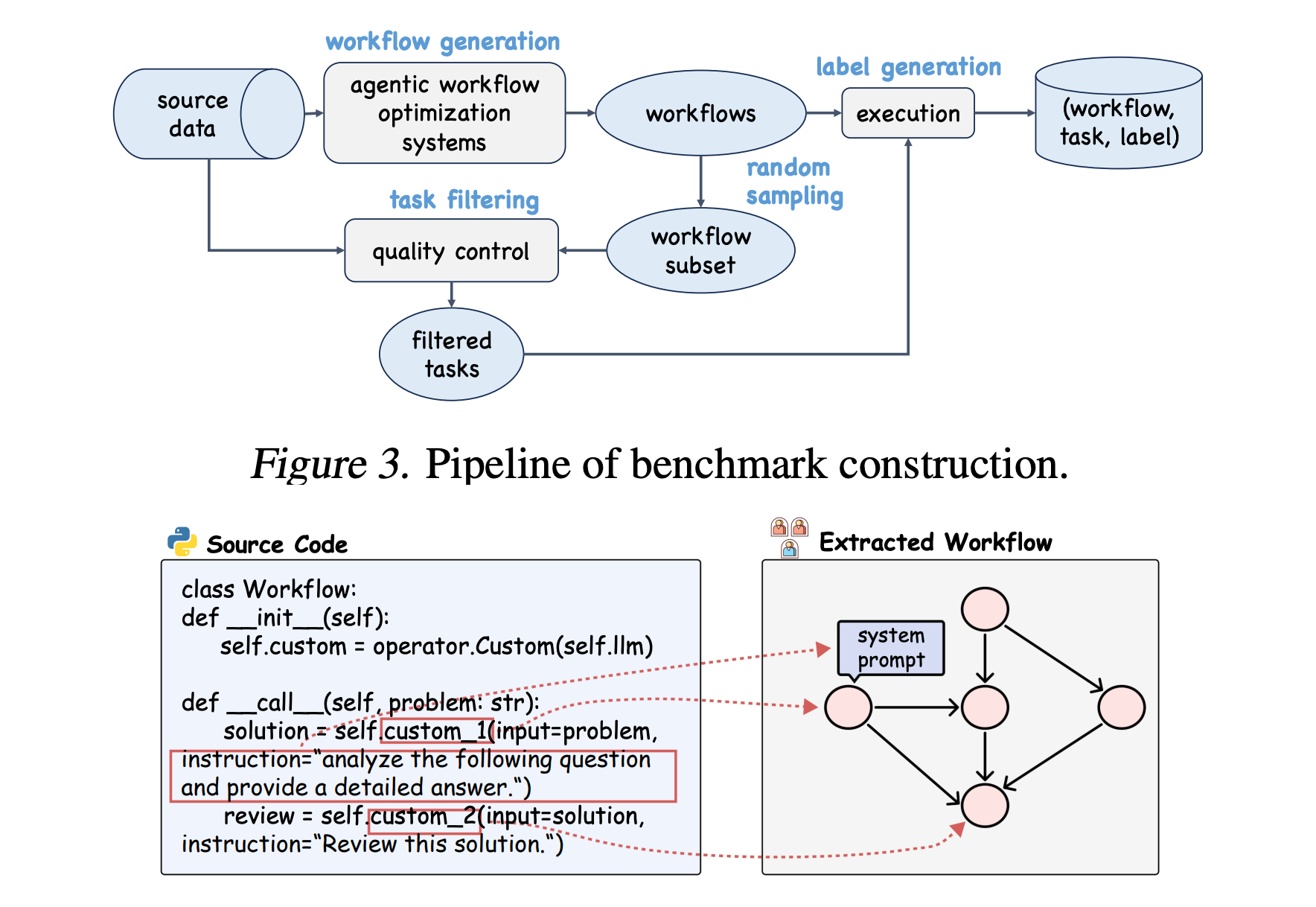
This work introduces FLORA-Bench, a large-scale benchmark to evaluate GNN-based predictors for automating and optimizing agentic workflows. It shows that Graph Neural Networks can efficiently predict the success of multi-agent LLM workflows, significantly reducing costly repeated model calls.