
🥇Top AI Papers of the Week
The Top AI Papers of the Week (August 11-17)
1. DINOv3
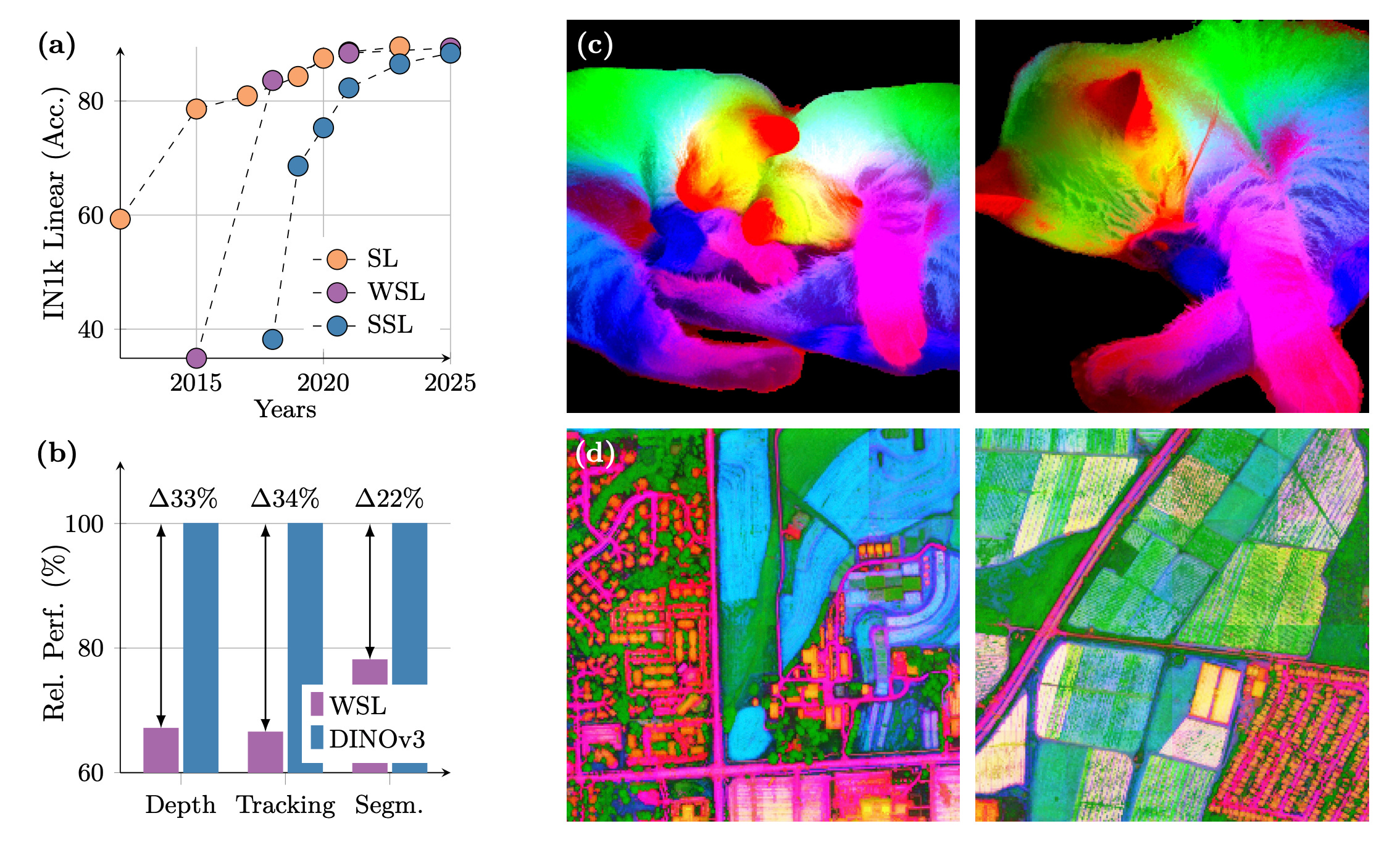
DINOv3 is a self‑supervised vision foundation model that scales data and model size, introduces a Gram anchoring loss to preserve dense patch consistency during long training, and adds post‑hoc tweaks for resolution, size, and text alignment. With a frozen backbone, it sets new results across dense and global tasks without task‑specific fine‑tuning.
Key idea: Gram anchoring. Regularize patch features by matching the student’s patch‑feature Gram matrix to that of an earlier “Gram teacher,” improving local consistency while leaving global features flexible. Implemented late in training, it can repair degraded dense features.
Immediate dense gains. Applying Gram anchoring quickly boosts VOC and ADE20k segmentation and strengthens robustness on ObjectNet; using higher‑resolution teacher features adds further improvements.
High‑res teacher trick. Compute teacher features at 2× input resolution, then downsample to smooth patch similarities; this yields better Gram targets and extra mIoU on ADE20k.
Frozen‑backbone SOTA. A lightweight Plain‑DETR decoder on top of a frozen DINOv3 backbone reaches 66.1 mAP on COCO, rivaling or beating specialized detectors with hundreds of millions of trainable parameters.
General, scalable suite. The release covers multiple model sizes and training recipes designed to serve diverse resource and deployment needs while outperforming prior self‑ and weakly‑supervised foundations.
2. Capabilities of GPT-5 on Multimodal Medical Reasoning
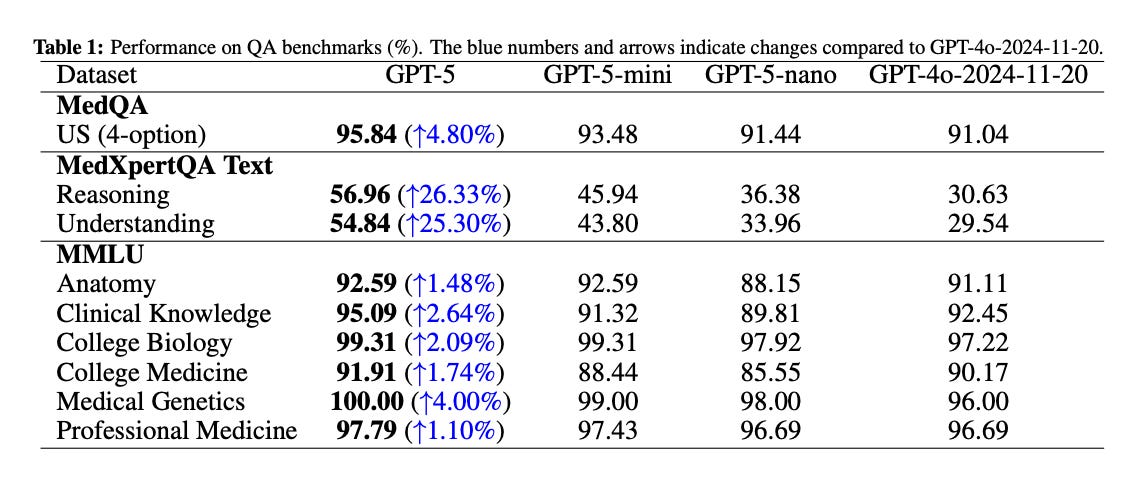
A controlled, zero‑shot CoT evaluation positions GPT‑5 as a generalist medical reasoner across text and image inputs. Using standardized prompts and splits, GPT‑5 consistently beats GPT‑4o and smaller GPT‑5 variants, with especially large gains on multimodal expert‑level QA.
Unified zero‑shot CoT setup. The authors fix prompts, exemplars, and answer formats for both QA and VQA to isolate the model upgrade.
Text benchmarks: new highs. On MedQA (US 4‑option) GPT‑5 reaches 95.84% (+4.80% vs GPT‑4o). On MedXpertQA‑Text, GPT‑5 improves reasoning by +26.33% and understanding by +25.30% over GPT‑4o. MMLU‑Medical is at or near ceiling, with notable gains in Medical Genetics and Clinical Knowledge.
USMLE practice sets: strong clinical management. GPT‑5 tops all baselines on Steps 1–3, with the largest margin on Step 2 (+4.17%), averaging 95.22% (+2.88% vs GPT‑4o).
Multimodal reasoning: big leap and human‑plus. On MedXpertQA‑MM, GPT‑5 gains +29.26% in reasoning and +26.18% in understanding over GPT‑4o and surpasses pre‑licensed human experts by +24.23% and +29.40%, respectively. A worked case shows coherent synthesis of CT findings and clinical context to recommend a Gastrografin swallow.
Caveats and outlook. GPT‑5 is slightly below GPT‑5‑mini on VQA‑RAD, possibly due to calibration on small radiology datasets. The discussion cautions that standardized tests differ from messy clinical reality and calls for prospective studies and deployment calibration.
3. M3-Agent
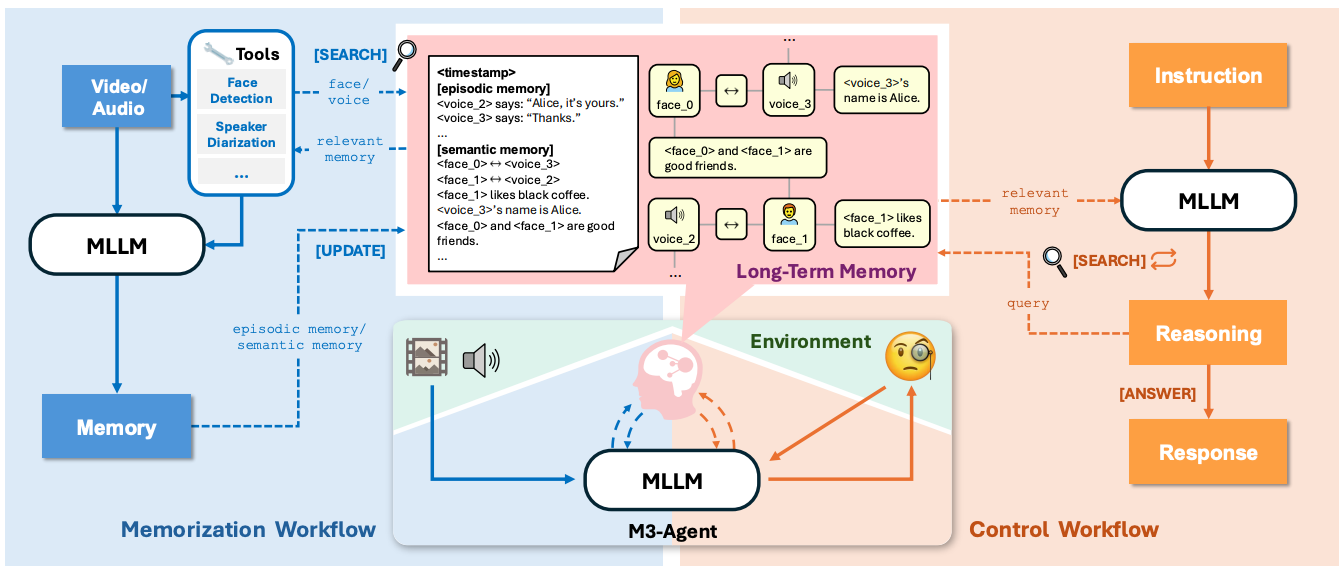
A framework for agents that watch and listen to long videos, build entity-centric memories, and use multi-turn reasoning to answer questions. M3-Agent stores both episodic details and distilled semantic knowledge in a multimodal memory graph, then learns a retrieval-reasoning policy with RL. The authors also introduce M3-Bench, a long-video QA benchmark with robot-view and web videos. Results show consistent gains over strong prompting baselines.
Entity-centric long-term memory. Builds a multimodal graph with nodes for text, faces, and voices, plus edges for relations and cross-modal identity links. Episodic entries record events, and semantic entries capture attributes and world knowledge. Conflicts are resolved by weight-based voting to keep memory consistent.
Online memorization with identity tools. Processes video streams clip by clip, using face recognition and speaker identification to maintain persistent character IDs, then writes grounded episodic and semantic memories keyed by those IDs.
RL-trained control for retrieval and reasoning. A policy model decides when to search memory and when to answer, performing iterative, multi-round queries over the memory store rather than single-shot RAG.
M3-Bench for long-video QA. 100 robot-perspective videos and 929 web videos with 6,313 total QA pairs targeting multi-detail, multi-hop, cross-modal, human understanding, and general knowledge questions.
State-of-the-art results and ablations. M3-Agent beats a Gemini-GPT-4o hybrid and other baselines on M3-Bench-robot, M3-Bench-web, and VideoMME-long. Semantic memory and identity equivalence are crucial, and RL training plus inter-turn instructions and explicit reasoning materially improve accuracy.
Editor Message
I am launching a new hybrid course on building effective AI Agents with n8n. If you are building and exploring with AI agents, you don’t want to miss this one. You can use code DAIRX20 for an extra 20% off (available only for the next 24 hrs).
4. TRImodal Brain Encoder
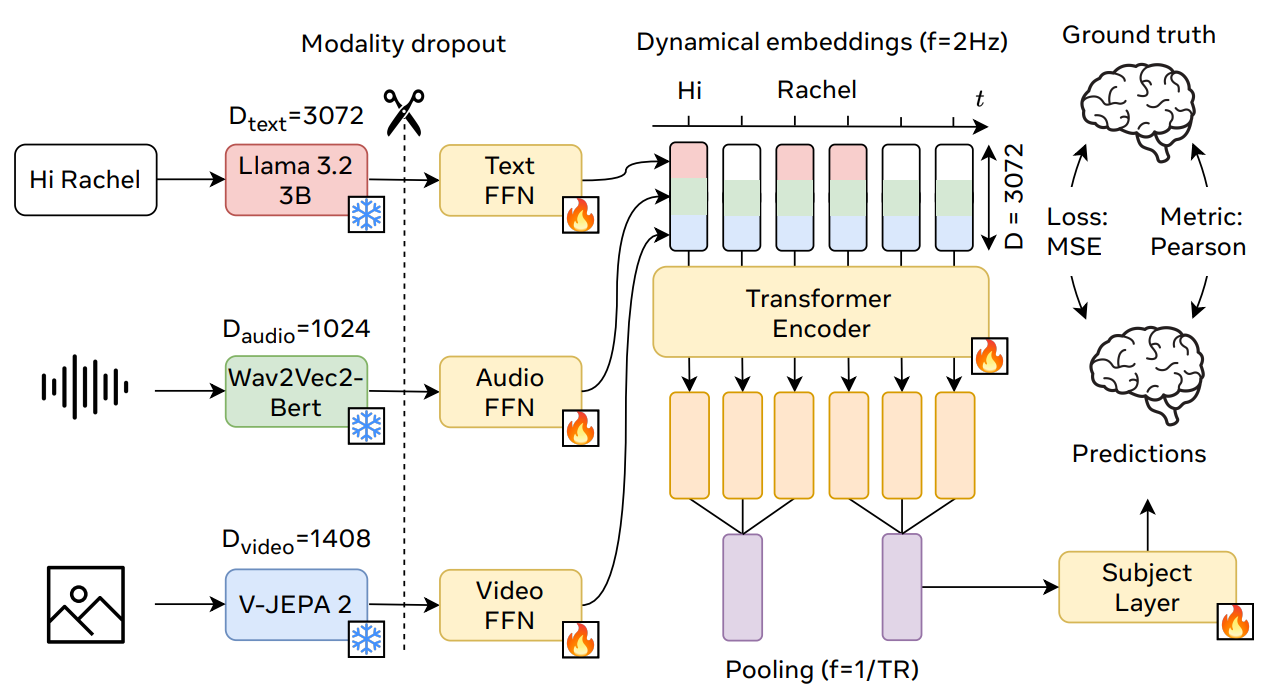
A tri‑modal, multi‑subject, nonlinear encoder that fuses text, audio, and video features with a transformer to predict time‑varying fMRI responses to natural movies. It took 1st place in the Algonauts 2025 brain encoding competition and shows the strongest gains in the high‑level associative cortex.
Model recipe. Extracts timed embeddings from Llama‑3.2‑3B (text), Wav2Vec‑BERT‑2.0 (audio), and V‑JEPA‑2 (video), groups layers, projects to shared width, and feeds a windowed sequence to an 8‑layer transformer with subject embeddings and adaptive pooling to 1,000 cortical parcels. Modality dropout trains robustness when inputs are missing.
State of the art. Ranked 1st of 263 teams on the public leaderboard; large margin over the field. Mean Pearson in‑distribution on Friends S7 is 0.3195, and it generalizes to out‑of‑distribution films, including cartoons, documentaries, and silent black‑and‑white clips.
Noise ceiling. Achieves a normalized Pearson of about 0.54 on average, near ceiling in auditory and language cortices, indicating more than half of the explainable variance captured.
Why multimodal matters. Unimodal encoders trail the tri‑modal model; combining any two helps, and all three help most. Biggest gains appear in associative PFC and parieto‑occipito‑temporal regions, while primary visual cortex can favor vision‑only features.
Ablations and scaling. Removing multi‑subject training or the transformer hurts performance; more sessions keep improving results, and longer LM context windows up to 1,024 words steadily boost text‑driven encoding, supporting the role of high‑level semantics.
5. OdysseyBench
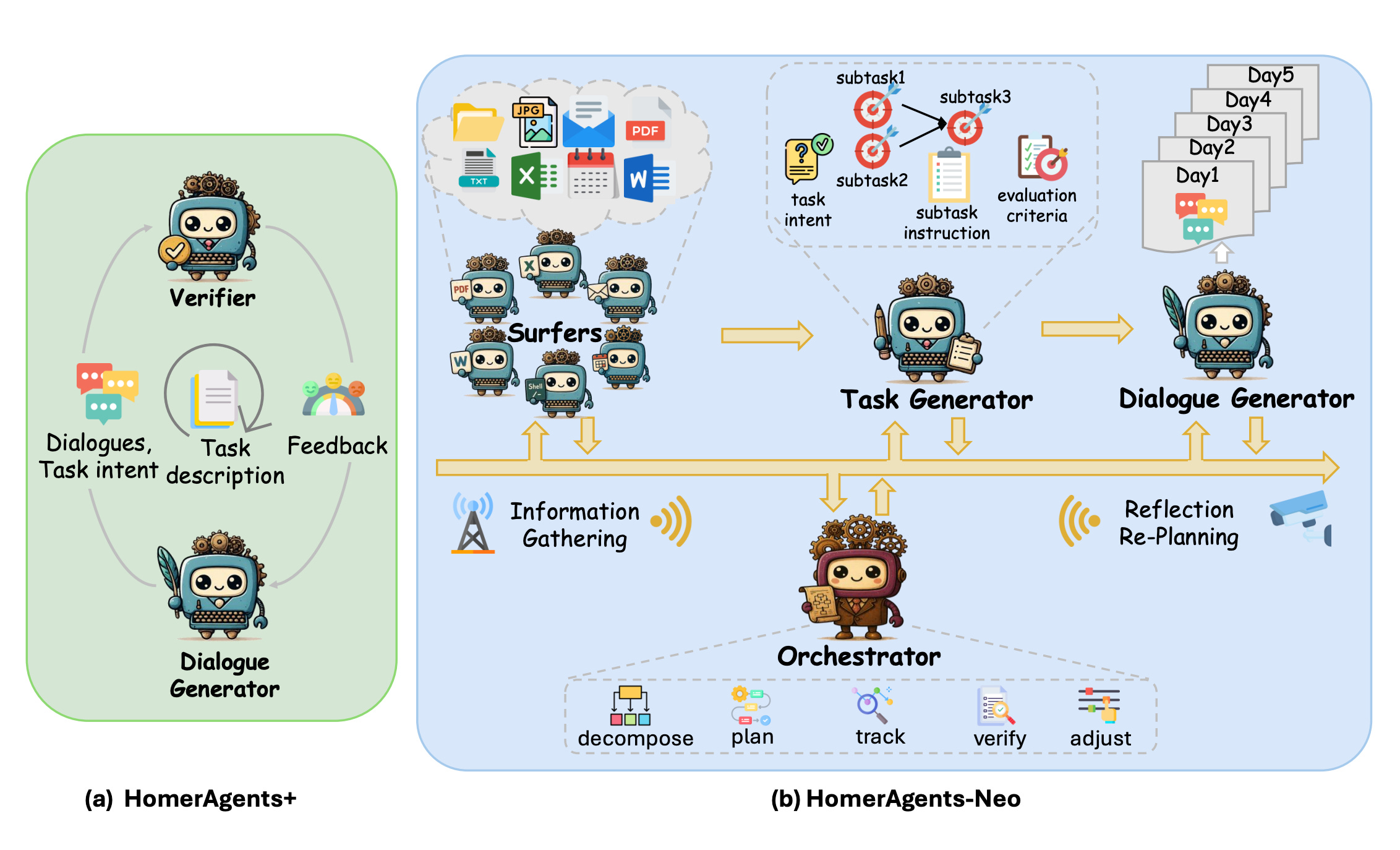
A new benchmark and data‑generation pipeline to test agents on realistic, multi‑day office tasks across Word, Excel, PDF, Email, and Calendar. It introduces OdysseyBench (two splits) and HOMERAGENTS (an automated multi‑agent generator), with evaluations showing large gaps between human and model performance and clear benefits from semantically compressed memory.
What’s new: OdysseyBench targets long‑horizon, context‑dependent workflows instead of atomic tasks. Two splits: OdysseyBench+ (300 tasks distilled from real OfficeBench cases) and OdysseyBench‑Neo (302 newly synthesized, more complex tasks). Tasks require retrieving key facts from multi‑day dialogues and coordinating actions across apps.
How it’s built: HOMERAGENTS has two paths. HOMERAGENTS+ iteratively turns atomic OfficeBench items into rich multi‑day dialogues via a generator‑verifier loop. HOMERAGENTS‑NEO plans, explores an app environment, generates tasks (intent, subtasks, eval criteria), and then synthesizes 5‑day dialogues. All agents use GPT‑4.1; at least five calendar days of dialogue are produced per task.
Data & evaluation: 602 total tasks: 153 single‑app, 166 two‑app, 283 three‑app. Neo conversations are longer and denser (≈49% more tokens) than Plus. Execution steps cluster around 3–15. Automated checks (exact/fuzzy/execution‑based) compute pass rate after running agents inside a Dockerized office stack; LLM‑judge and human curation raise data quality.
Main results: Performance drops as apps increase; even top models struggle on 3‑app tasks. Example: on OdysseyBench+, o3 goes 72.83%→30.36% from 1‑app to 3‑app; GPT‑4.1 goes 55.91%→12.50%. Humans exceed 90% across settings. RAG with semantic summaries beats raw retrieval at far lower token budgets; chunk‑level summaries reach ≈56% on Neo vs. 52% long‑context with ~20% tokens. Execution steps remain similar or shrink with summarized memory.
Where agents fail: Typical errors include missing referenced files, skipping required actions, wrong tool choice (e.g., trying to “create PDF” directly instead of writing in Word then converting), and poor planning order. File creation/editing in docx/xlsx is particularly error‑prone. The authors argue that semantic compression and coherent aggregation are essential for multi‑step reasoning in long contexts.
6. Beyond Ten Turns
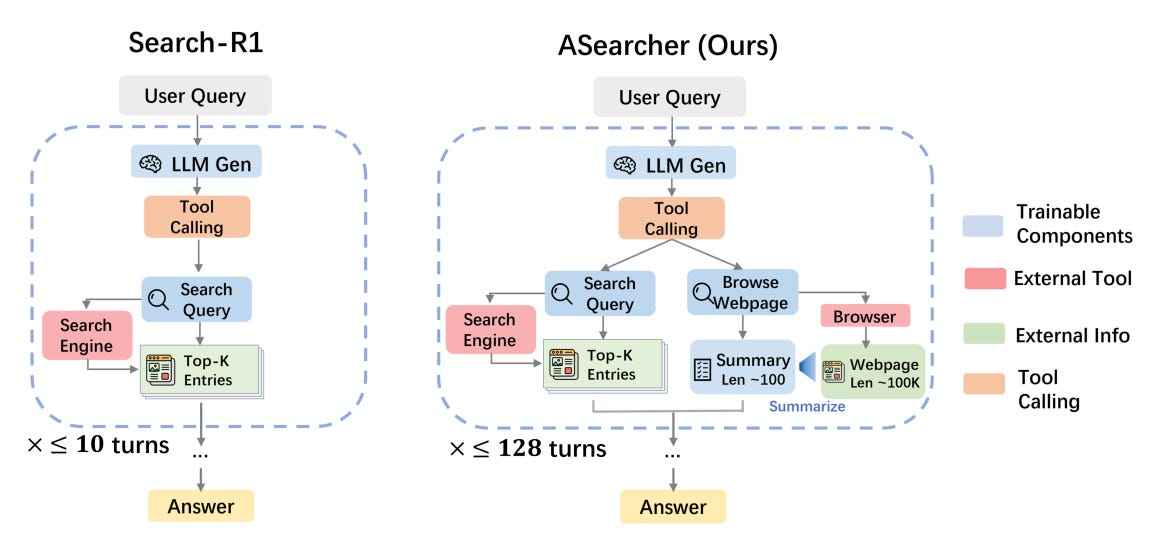
This paper introduces ASearcher, an open-source framework for training LLM-based search agents capable of long-horizon, expert-level search. It addresses two major limitations in prior open-source approaches: short turn limits (≤10) and lack of large-scale, high-quality QA data.
Key points:
Fully asynchronous RL for long-horizon search – Unlike batch generation RL, ASearcher decouples trajectory execution from model updates, avoiding bottlenecks from long trajectories. This enables relaxed turn limits (up to 128), with training showing >40 tool calls and >150k tokens in a single trajectory.
Scalable QA synthesis agent – An autonomous LLM agent generates complex, uncertainty-rich QA pairs by injection (adding external facts) and fuzzing (obscuring key info), followed by multi-stage quality checks. From 14k seeds, 134k high-quality QAs were created, 25.6k requiring tool use.
Simple but powerful agent design – Uses only search and browsing tools (no external LLM), with end-to-end RL optimizing reasoning and summarization. Tailored prompting and history management are applied for both base LLMs (Qwen2.5-7B/14B) and large reasoning models (QwQ-32B).
Expert-level search behaviors – Through RL, ASearcher-Web-QwQ learns uncertainty-aware reasoning, precise key info extraction from noisy content, cross-document inference, and rigorous verification, outperforming Search-R1-32B and Search-o1(QwQ) in case studies.
State-of-the-art performance – Achieves Avg@4 of 42.1 on xBench-DeepSearch and 52.8 on GAIA, with significant RL gains (+46.7% and +20.8% respectively). Local KB-trained agents generalize well to web search, surpassing stronger baselines.
Training efficiency – Asynchronous rollouts and decoupled updates maintain high GPU utilization, handling large variance in tool call count and token length per trajectory.
7. Illusion of Progress
The paper argues that common QA hallucination detectors look better than they are because evaluations lean on ROUGE. In human‑aligned tests, many detectors drop sharply. Simple response‑length heuristics rival sophisticated methods, revealing a core evaluation flaw.
ROUGE misaligns with humans. In a human study, LLM‑as‑Judge matches human labels much better than ROUGE.
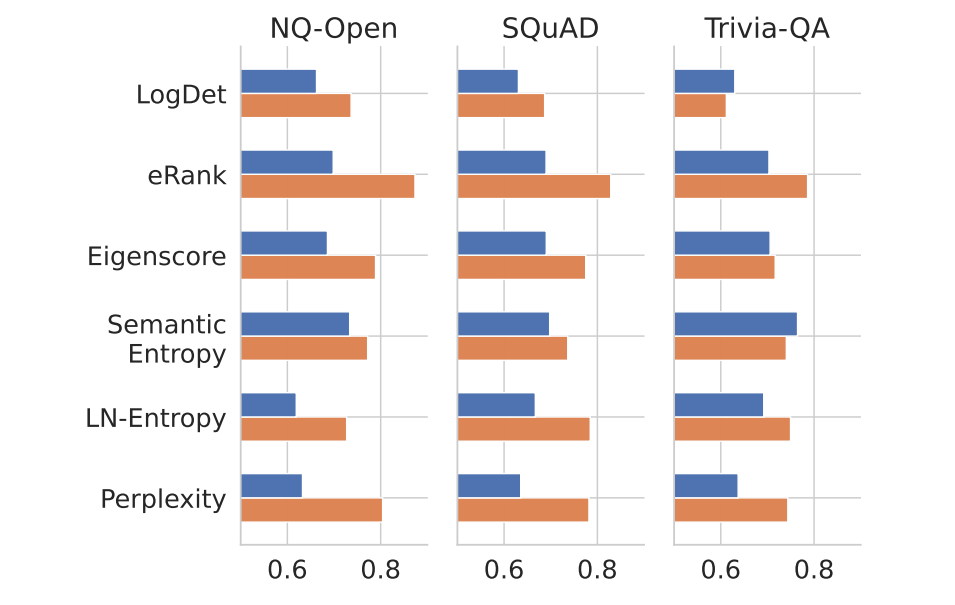
Re‑scoring detectors collapses headline results. When replacing ROUGE with LLM‑as‑Judge, AUROC drops are large: up to −45.9% for Perplexity and −30.4% for Eigenscore on NQ‑Open with Mistral; PR‑AUC gaps are even larger. Correlation between ROUGE‑ and LLM‑based AUROC is only r = 0.55.
Length is the hidden confounder. Hallucinated answers are typically longer with higher variance. Many detectors are strongly correlated with length, not semantics. ROUGE systematically penalizes long responses and can be gamed by repetition without changing facts.
Simple baselines rival complex methods. Length features like mean and std across samples achieve competitive AUROC, sometimes matching or beating Eigenscore and LN‑Entropy.
Few‑shot helps format, not truth. Few‑shot examples reduce some ROUGE vs LLM‑as‑Judge discrepancies and stabilize outputs, but method rankings still shift and model effects persist; Semantic Entropy is relatively more stable.
8. GLM-4.5
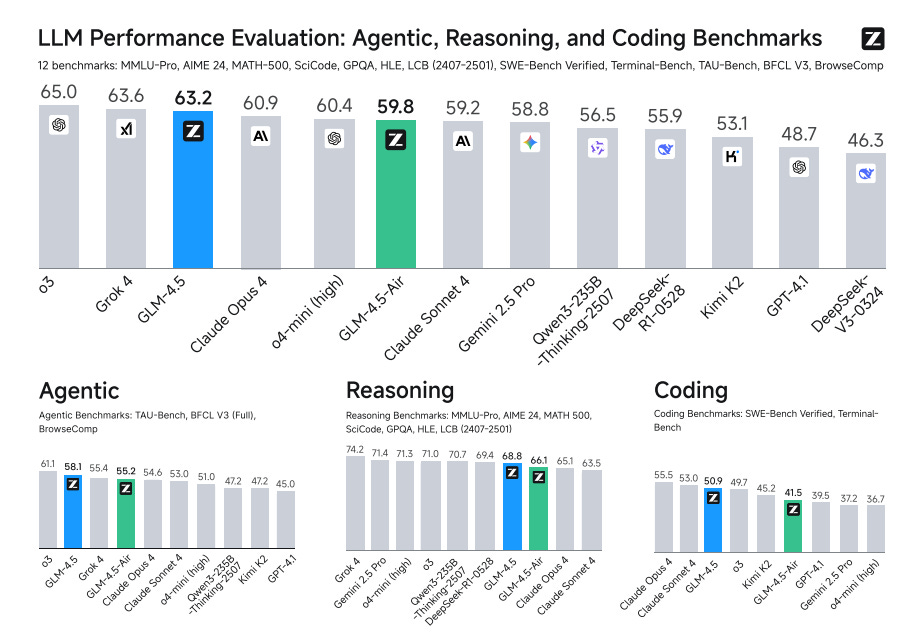
An open Mixture‑of‑Experts family that targets a single model excelling across agentic tool use, complex reasoning, and real‑world coding. GLM‑4.5 (355B total, 32B active) introduces hybrid “thinking vs direct” modes, multi‑stage pretrain + mid‑train to 128K context, and extensive RL for reasoning, agents, and instruction following. It ranks near the top on a 12‑bench ARC suite and releases weights and eval tooling.
Results at a glance – On the 12‑benchmark ARC suite, GLM‑4.5 averages 3rd overall and 2nd on agentic tasks; Key scores: TAU‑Bench 70.1, BFCL‑V3 77.8, BrowseComp 26.4; AIME24 91.0, GPQA 79.1; SWE‑bench Verified 64.2, Terminal‑Bench 37.5.
Architecture and scaling choices – MoE with loss‑free balance routing and sigmoid gates, GQA with partial RoPE, QK‑Norm, 96 attention heads at 5,120 hidden, and an MoE Multi‑Token Prediction layer for speculative decoding.
Training recipe – 23T tokens pretrain with quality‑bucketed web, code, math, science, and multilingual data; mid‑training adds repo‑level code sequences, synthetic reasoning traces, 128K context, and large synthetic agent trajectories. Optimizer is Muon with cosine decay and sequence‑length extension plus RoPE base adjustment.
Post‑training and RL – Two‑stage expert‑then‑unified SFT + RL. Reasoning RL uses a difficulty curriculum, single‑stage 64K output‑length RL, token‑weighted loss for code, and strict filtering for science. Agentic RL covers web search and SWE with outcome rewards, strict format penalties, iterative self‑distillation, and turn‑scaling benefits. A new XML‑tagged function‑call template reduces escaping overhead.
RL infrastructure for agents – Slime provides synchronous training for general RL and decoupled asynchronous rollouts for long‑horizon agent tasks, with FP8 inference for faster data generation.
9. A Survey on Efficient Architectures for LLMs
This survey reviews advances in efficient LLM architectures beyond traditional transformers, including linear and sparse sequence models, efficient attention variants, sparse MoEs, hybrid designs, and diffusion-based LLMs. It highlights cross-modal applications and outlines a blueprint for building scalable, resource-efficient foundation models.
10. A Deep Dive into RL for LLM Reasoning
This paper reviews and rigorously re-evaluates reinforcement learning techniques for LLM reasoning, addressing inconsistencies caused by varied setups and unclear guidelines. It offers a unified open-source framework, practical selection guidelines, and shows that a minimalist two-technique combo with vanilla PPO can outperform methods like GRPO and DAPO.