
🥇Top AI Papers of the Week
The Top AI Papers of the Week (October 13-19)
1. Cell2Sentence-Scale 27B
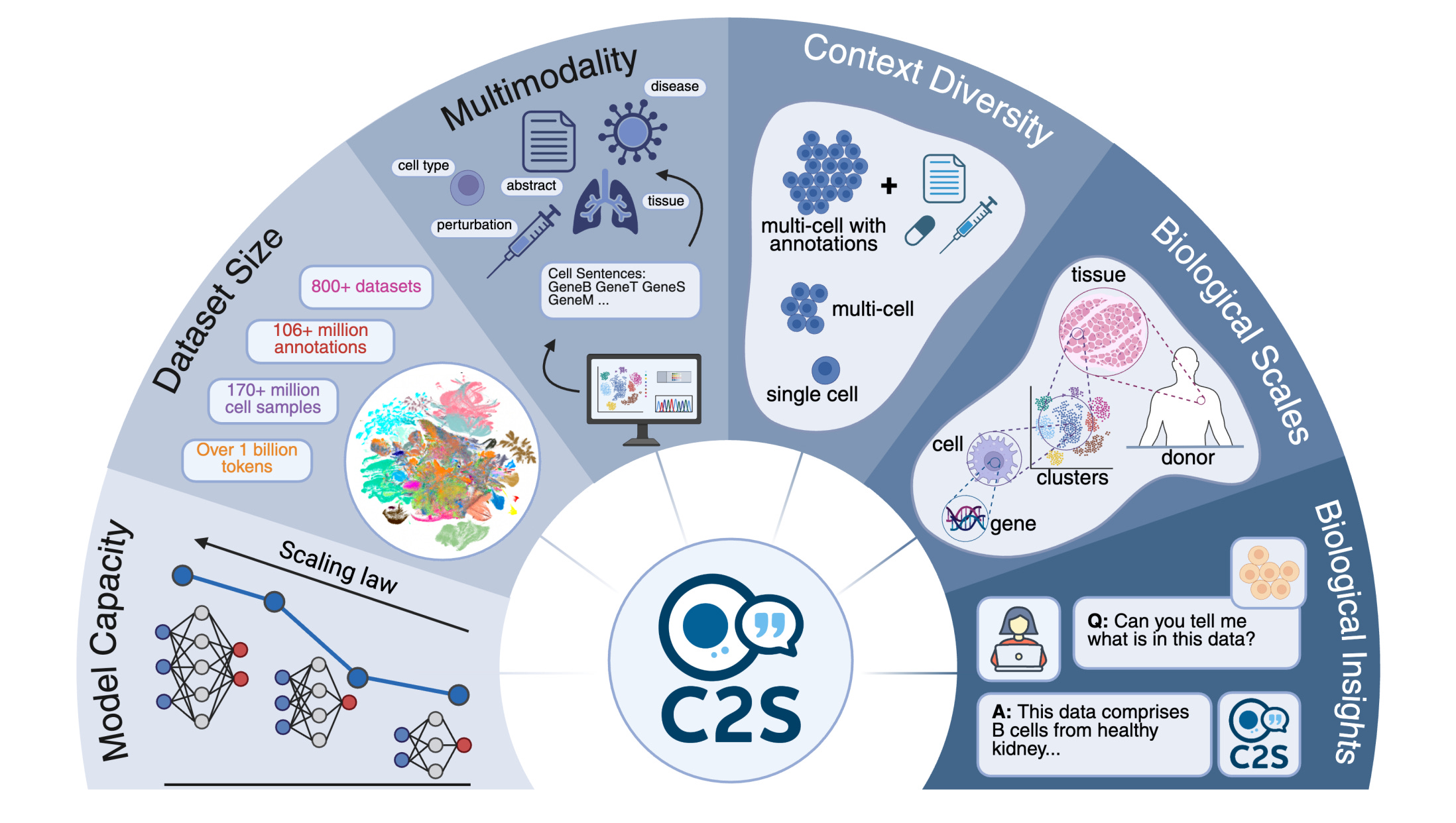
C2S-Scale extends Cell2Sentence by converting gene expression into “cell sentences” and training LLMs on 50M+ cells plus biological text. Models scale to 27B params and unify prediction, generation, and NL interpretation. A dual-context virtual screen then led to a wet-lab validated finding: silmitasertib acts as an interferon-conditional amplifier of MHC-I antigen presentation.
Data-as-text and scaling behavior: scRNA-seq profiles are rank-ordered into gene-name sequences that preserve expression information and can be inverted with minimal loss. Pretraining spans multi-task prompts over 50M human and mouse transcriptomes, plus papers and metadata. Performance improves smoothly from 410M to 27B across annotation, tissue inference, and conditional generation.
Broad capabilities vs baselines: On classic single-cell tasks, C2S-Scale matches or beats scGPT and Geneformer. It also supports NL cluster captioning, dataset-level summarization, and QA, outperforming general LLMs like GPT-4o on these single-cell-grounded NL tasks.
Multi-cell and spatial reasoning: Without bespoke spatial modules, C2S-Scale predicts neighborhood structure from multi-cell context and improves further when prompted with receptor-ligand and PPI knowledge from CellPhoneDB and BioGRID.
Perturbation modeling and a new metric: A two-stage pipeline uses SFT to condition on perturbations, then GRPO to reward pathway-faithful predictions. The paper introduces scFID, an embedding-space analogue of image FID, yielding stable rankings of generated cell states. C2S-Scale leads on unseen cytokine combinations and lowers scFID after RL.
From virtual screen to biology
A dual-context screen asked for drugs that raise antigen presentation only in low-IFN settings. The model nominated silmitasertib with a strong context split, and this was validated in two human cell models: silmitasertib alone had little effect, but with low-dose IFN increased HLA-A,B,C surface levels.
2. The Art of Scaling RL Compute for LLMs
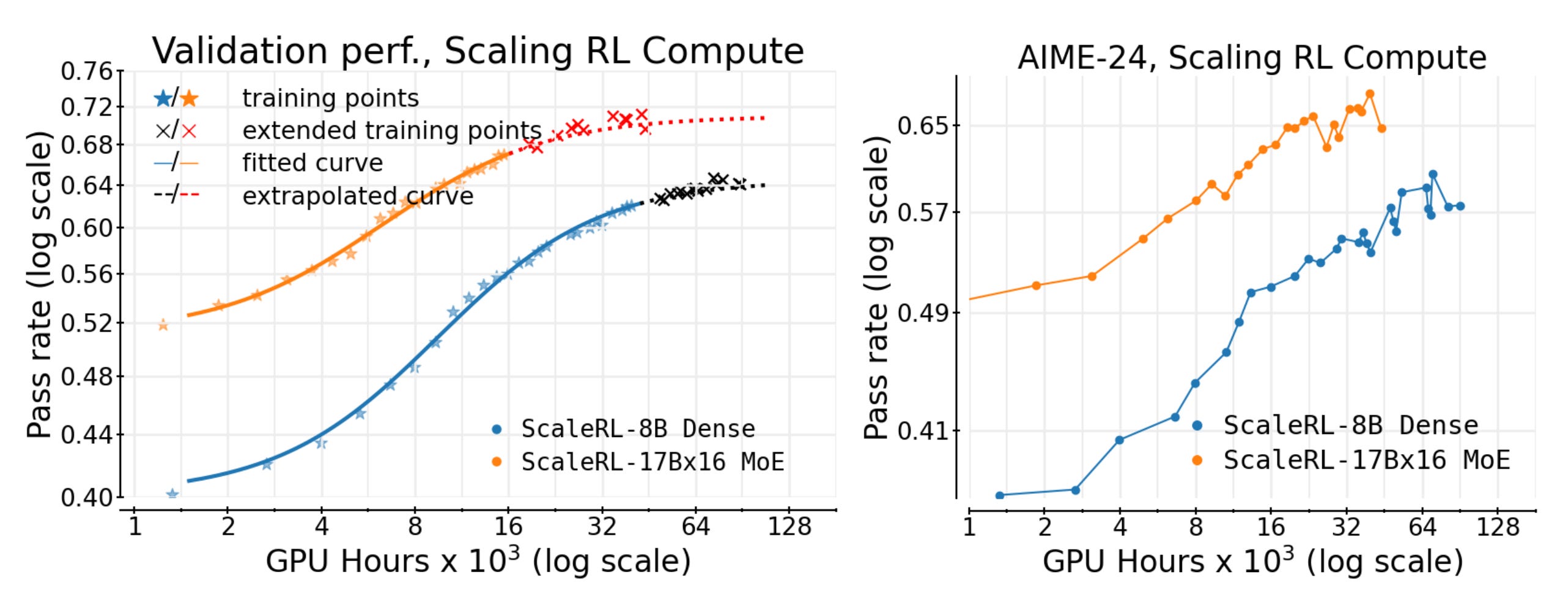
A 400k+ GPU-hour study introduces a simple, predictive way to scale RL for LLMs. The authors fit a sigmoidal compute→performance curve that lets you extrapolate from small runs and propose ScaleRL, a stable recipe validated up to 100k GPU-hours on an 8B dense model and a 17B×16 MoE.
Predictive scaling law you can actually use: Model pass-rate vs log(compute) follows a saturating sigmoid with three knobs: A (asymptotic ceiling), B (compute efficiency), Cmid (midpoint). Fit after ~1.5k GPU-hours on a 1k-prompt holdout, and you can forecast larger budgets. This matched extended training in practice, including the 100k GPU-hour run and MoE scaling.
ScaleRL recipe that held up under leave-one-out: PipelineRL with k=8, CISPO loss (truncated IS REINFORCE), prompt-level loss averaging, batch-level advantage norm, FP32 logits at the LM head, zero-variance prompt filtering, No-Positive-Resampling curriculum, and forced interruptions to cap thinking length. LOO ablations to 16k GPU-hours show ScaleRL as the most efficient while retaining similar or better asymptotes.
What actually moves the ceiling vs just speed: Not all popular RL recipes converge to the same A. Loss choice and precision at logits lift the ceiling, while aggregation, normalization, curriculum, and off-policy details mostly tune B. CISPO/GSPO > DAPO on asymptote; FP32 logits gave a big jump (A≈0.52→0.61).
Scaling axes that paid off:
• Longer generation budgets (to 32k) raise the asymptote at the cost of early efficiency.
• Bigger global batches improve asymptote and downstream generalization, avoiding small-batch stagnation.
• Larger models (MoE) deliver much higher asymptotic RL performance with less compute than the 8B dense.
• More generations per prompt at fixed total batch size is second-order.Operator notes for stable long runs: Fit curves on a held-out 1k-prompt set with mean@16 generations, watch truncation rates as an instability signal, prefer interruptions over length penalties for length control, and plan early small-budget ablations to choose methods that scale by A first, then tune B.
3. Demystifying RL in Agentic Reasoning
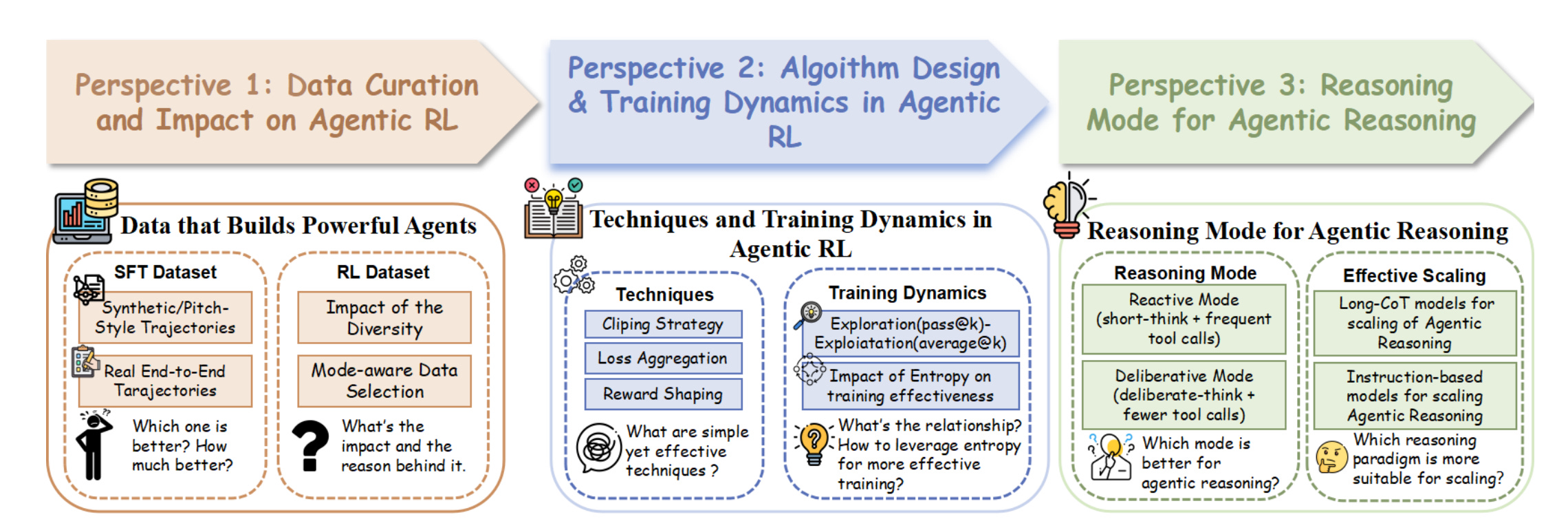
This paper studies what actually works when using RL to improve tool-using LLM agents, across three axes: data, algorithm, and reasoning mode. The team contributes a real end-to-end SFT dataset, a diverse RL set, and a compact 4B agent that beats larger models on agentic benchmarks.
Data > synthetic. Real, end-to-end multi-turn trajectories for SFT give a much stronger cold-start than stitched synthetic traces. On AIME24/25, real SFT boosts average@32 and pass@32 by large margins for 4B and 7B bases.
Diversity sustains exploration: A diversified RL dataset across math, science, and code raises and maintains policy entropy, speeding learning and stabilizing training. The model-aware curation further fixes weak-model bottlenecks by matching task difficulty to capability.
Simple GRPO tweaks matter: A practical recipe using token-level aggregation, higher clip range, and overlong-penalty shaping (GRPO-TCR) consistently outperforms a standard GRPO baseline in both peak accuracy and data efficiency.
Entropy needs a sweet spot: Training is best when policy entropy is neither collapsed nor excessive. Increasing the clip upper bound modestly accelerates progress, but too high degrades convergence and stability.
Deliberate mode wins: Fewer, better tool calls after more internal planning lead to higher tool-use success and overall accuracy than reactive short-think with frequent calls.
Long-CoT is not plug-and-play for agents: Off-the-shelf Long-CoT models avoid tools on reasoning-heavy tasks, driving tool-call counts toward zero during RL. SFT with multi-turn tool traces can re-align them, but instruction-tuned bases ultimately scale agentic capability more cleanly.
Compact SOTA with the recipe: Using the 30k diverse RL set and GRPO-TCR with a tuned clip upper bound, DemyAgent-4B reaches or beats much larger models in agentic settings, including AIME25, GPQA-Diamond, and LiveCodeBench-v6.
4. Emergent Coordination in Multi-Agent LLMs
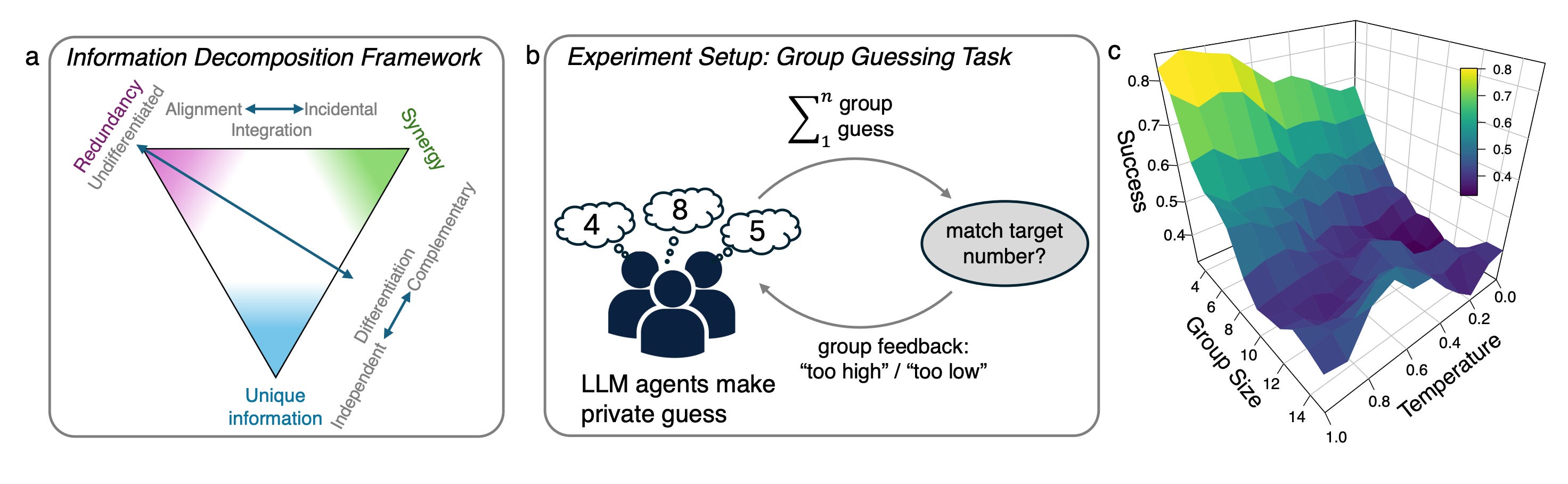
A neat, information-theoretic probe for “is this just a pile of agents or a real collective?” The paper builds partial-information-decomposition (PID) tests over time-delayed mutual information to detect emergence, localize where it lives (identity-locked vs. mere temporal coupling), and tie it to performance. Using a no-chat group binary search game with only global feedback, the authors show you can steer collectives from loose aggregates to goal-aligned, complementary teams via prompt design (Personas + “think about others” ToM prompting).
Framework: outcome-relevant PID over time. Three diagnostics:
Practical criterion: does the macro signal at t predict the macro at t+ℓ beyond any single agent? Positive values indicate dynamical synergy.
Emergence capacity: pairwise PID synergy for predicting future joint states, capturing “only-together” information that no single agent has.
Coalition test: triplet info I3 vs. best pair (G3) to check if coalitions carry extra, goal-relevant predictability.
Experiment: group guessing without communication. Agents guess integers 0–50; only “too high/low” is returned to the whole group. Conditions: Plain, Persona, and Persona + ToM (“think about what others might do”).
Key findings for GPT-4.1:
Emergence is real and steerable. Both the practical criterion and emergence capacity are >0 across conditions with robustness checks, indicating dynamical synergy. Personas induce stable, identity-linked differentiation; adding ToM increases alignment on the shared goal while keeping complementarity.
Triplet structure matters. Many groups show G3>0, meaning no pair suffices; whole triplets add predictive information about the macro signal. ToM has higher total mutual information I3 (stronger shared-goal alignment) and more groups with significant I3.
Performance emerges from balance. Synergy alone or redundancy alone does not predict success; their interaction does. Redundancy amplifies synergy’s effect and vice versa, consistent with integration + differentiation as the winning regime. Mediation suggests ToM boosts success indirectly by increasing synergy.
Lower-capacity model contrast (Llama-3.1-8B): Groups mostly fail; behavior shows strong temporal oscillations (time coupling) but weak cross-agent complementarity. ToM even hurts vs. Plain here, underscoring that ToM-style prompting needs sufficient model capacity.
Practical takeaways for AI devs:
Design for complementary roles and shared target signals. Use light personas to stabilize identity-linked behaviors; add ToM-style reasoning to nudge agents to adapt to each other while aligning to the macro objective.
Measure, don’t guess. Track macro predictability (practical criterion), pairwise synergy (capacity), and coalition additivity (G3) to diagnose when your team is a real collective vs. synchronized oscillators.
Beware spurious emergence. Use row-shuffle (break identities) and column-shuffle (break cross-agent alignment) nulls to separate good synergy from mere temporal couplings.
5. Elastic-Cache
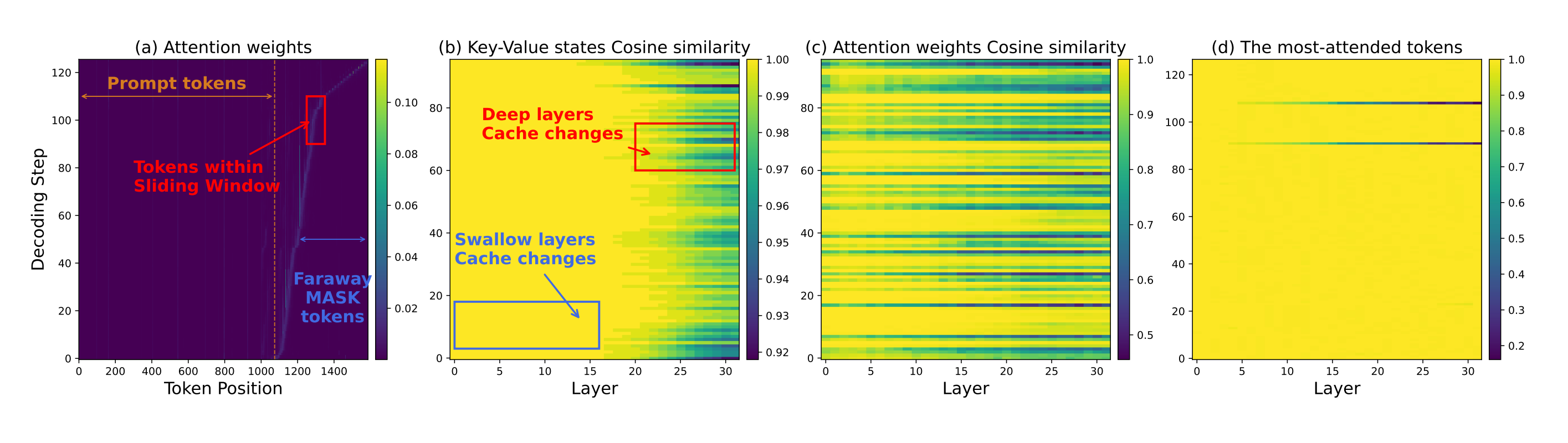
A training-free, architecture-agnostic way to make diffusion LLM decoding fast by updating KV caches only when and where it matters. Instead of recomputing QKV for all tokens at every denoising step, Elastic-Cache watches attention drift on the most-attended tokens and refreshes only deeper layers while reusing shallow and off-window caches. Results: large speedups with minimal or no accuracy loss across math, code, and multimodal tasks.
Core idea: Sliding-window decoding keeps only nearby MASK tokens “live” and block-caches distant MASKs as a length prior. An attention-aware drift test measures cosine similarity changes of the previous step’s most-attended tokens; if similarity drops below a threshold γ at layer ℓ, recomputation starts from ℓ+1 to L. Shallow layers reuse caches; deep layers refresh.
Why this works: KV drift is small across most steps and grows with depth, so refreshing all layers is wasteful. The most-attended token shows the least KV change, giving a conservative lower bound to trigger refreshes. Visualizations support: distant MASKs have little influence; KV and attention changes align; most-attended tokens drift least.
Algorithm knobs for practitioners: Threshold γ controls the speed-accuracy tradeoff; lower γ updates less and runs faster. Window size β trades per-step compute for fewer steps. Works with confidence-aware parallel decoding (ϵ) and shows low update frequency even at higher γ. Defaults used: γ 0.9, ϵ 0.9, typical β 16–32.
Results that matter: On LLaDA and LLaDA-1.5: up to 45.1× throughput on GSM8K-512 with equal accuracy, 8.7× on GSM8K-256, and 4.8–5.0× on HumanEval with accuracy maintained or improved vs baselines. On LLaDA-V, throughput rises while preserving MathVerse accuracy. Elastic-Cache consistently beats Fast-dLLM in tokens/sec at comparable or better accuracy, and its throughput scales favorably with longer generations.
Deployment notes: No training or architecture changes required. Compatible with existing confidence-based and interval policies. Includes a practical batch implementation that concatenates variable-length sequences to preserve parallelism. Ethical and reproducibility details plus code plans included.
6. Dynamic Layer Routing in LLMs
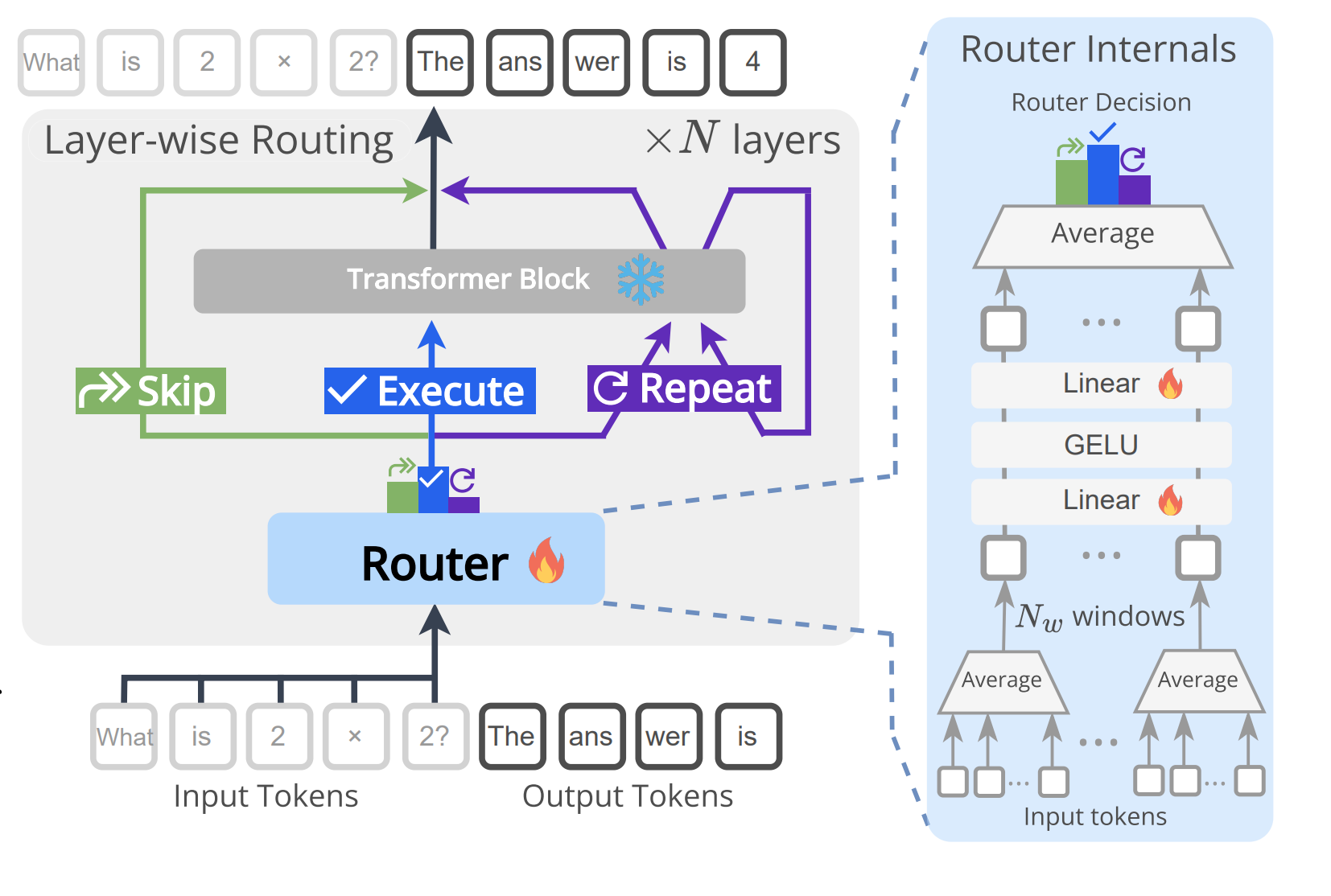
A retrofittable way to add per-layer routers to frozen LLMs that decide to skip, execute, or repeat each block. Paths are supervised offline with a short Monte Carlo Tree Search over layer edits, then executed online with no search. Improves accuracy on logic and math while saving layers on average.
What it is: Tiny MLP routers attached to every layer read windowed mean-pooled hidden states and output one of three actions: skip, execute once, or repeat once. Base weights stay frozen and KV caching remains compatible.
The diagram on page 3 shows the per-layer router, its pooling over windows, and how decisions gate the next block.
How the supervision works: Length-aware MCTS explores edited forward passes that skip or repeat layers under a compute budget and keeps only paths that preserve or improve the gold-answer reward. Routers are then trained with focal loss and class rebalancing on about 4k discovered paths.
Key results for AI devs: On ARC and DART across six backbones, routers increase accuracy while reducing layers by roughly 3 to 11 per query. Example: LLaMA-3B-Base rises from 11.8% to 15.8% on DART and saves 4.1 layers on average. Instruction-tuned 8B also gains on DART while saving 11 layers.
Out-of-domain generalization is strong. Across MMLU, GSM8k, AIME24, TruthfulQA, SQuADv2, GPQA, AGIEval, and PIQA, the average accuracy drop is about 0.85 percentage points while retaining savings.
Compared to LayerSkip, ShortGPT, MindSkip, and FlexiDepth, Dr.LLM attains higher average accuracy with far less training data and no base-model changes.
Why it helps: Analysis heatmaps on pages 8 and 17 show a consistent pattern. Early layers are kept stable, many middle layers are skipped, and late layers are sometimes repeated, especially on harder math, which reallocates depth where iterative refinement pays off.
7. LLMs Can Get “Brain Rot”!
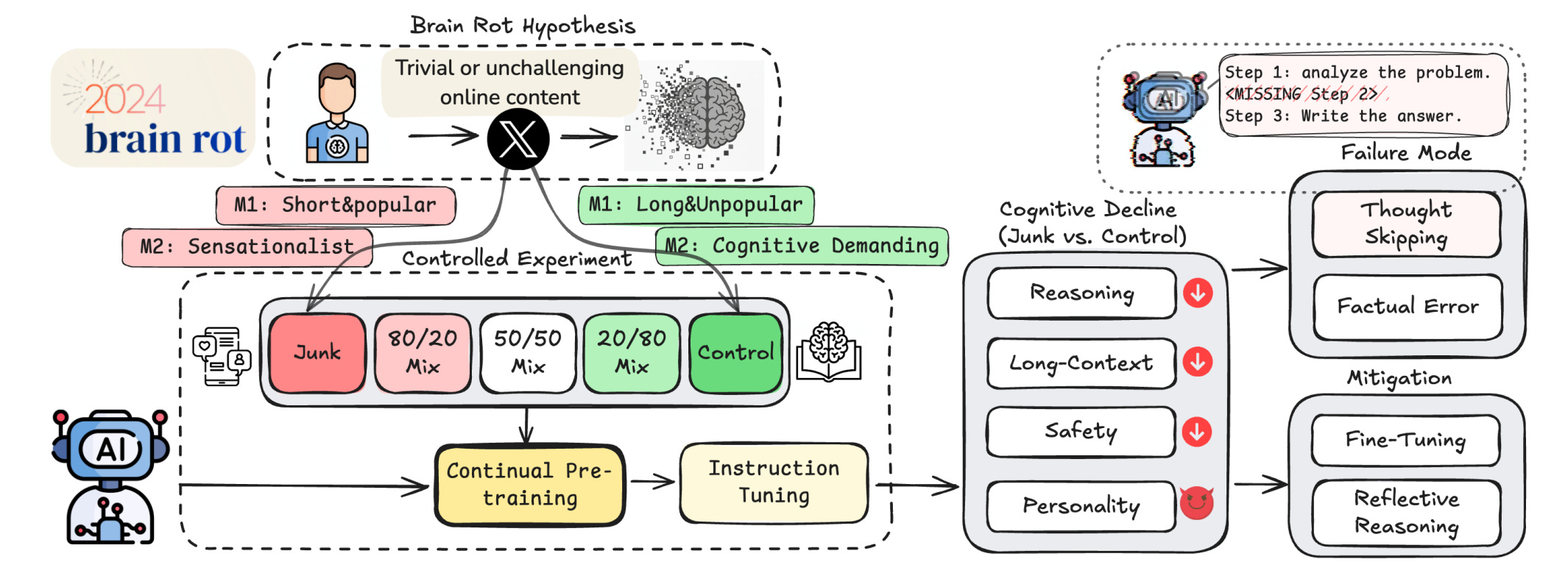
The authors test a clear hypothesis: continual pretraining on trivial, highly engaging web text degrades LLM cognition in ways that persist even after mitigation. They build controlled Twitter datasets to isolate data quality from scale and training ops, then measure effects on reasoning, long-context, safety, and personality.
Setup that isolates data quality: Two orthogonal junk definitions: M1 uses engagement signals and short length to capture popular, bite-sized posts; M2 uses semantic cues like clickbait and superficial topics. Four instruct models are continually pretrained with matched token counts and then re-instruction tuned, enabling apples-to-apples comparisons with control data.
Non-trivial capability decay with dose response: Across models, junk exposure reduces ARC reasoning, long-context retrieval, and safety, with Hedges’ g exceeding 0.3. Increasing the M1 junk ratio drives smooth drops, for example, ARC-Challenge with CoT 74.9 to 57.2 and RULER CWE 84.4 to 52.3 from 0% to 100% junk.
Thought-skipping is the primary lesion: Error forensics on ARC CoT show failures dominated by no thinking, no plan, and skipping planned steps, explaining over 98% of errors. Popularity is a stronger predictor of this rot for reasoning than length, while length matters more for long-context.
Safety and “dark traits” worsen under M1: Junk training elevates risk on HH-RLHF and AdvBench and inflates narcissism and psychopathy scores, while lowering agreeableness. Personality and safety outcomes diverge between M1 and M2, highlighting that engagement signals capture a harmful non-semantic axis of quality.
Mitigations help but do not heal: External reflection with a stronger model reduces thought-skipping and recovers accuracy; self-reflection does not. Scaling instruction tuning and clean continual training improve scores yet fail to close the gap to baseline, indicating persistent representational drift.
8. Hybrid Reinforcement
HERO (Hybrid Ensemble Reward Optimization) is a reinforcement learning framework that combines binary verifier feedback with continuous reward-model signals to improve LLM reasoning. By using stratified normalization and variance-aware weighting, HERO balances correctness and nuance, outperforming verifier-only and RM-only methods on diverse math reasoning benchmarks and enhancing performance on both verifiable and ambiguous tasks.
9. Kimi-Dev
Kimi-Dev introduces agentless training as a skill prior to software engineering LLMs, bridging workflow-style and agentic paradigms. Trained with structured, verifiable single-turn tasks, it achieves 60.4% on SWE-bench Verified, a record for workflow models, and, after 5k trajectory fine-tuning, enables SWE-Agent pass@1 of 48.6%, rivaling Claude 3.5 Sonnet. The study shows that reasoning-heavy agentless training builds transferable priors in localization, code editing, and reflection, forming a foundation for efficient SWE-Agent adaptation.
10. Holistic Agent Leaderboard
The Holistic Agent Leaderboard (HAL) introduces a standardized framework for large-scale, reproducible AI agent evaluation across 9 models and 9 benchmarks, spanning coding, web navigation, science, and customer service. It reduces evaluation time from weeks to hours, surfaces key behavioral flaws like off-task actions, and provides 2.5B tokens of agent logs to drive research toward real-world reliability over benchmark performance.
This article comes at the perfect time, and I am particularly impressed by the C2S-Scale paper's unifying aproach and wet-lab validation; how do you envision this 'data-as-text' paradigm influencing other biomedical domains beyond gene expression, and thank you for this insightful breakdown?
This roundup is gold. Appreciate how you distill complex papers into actionable insights, C2S-Scale and Elastic-Cache alone are game-changers for AI research and deployment.