
🥇Top AI Papers of the Week
The Top AI Papers of the Week (April 21 - 27)
1. Does RL Incentivize Reasoning in LLMs Beyond the Base Model?
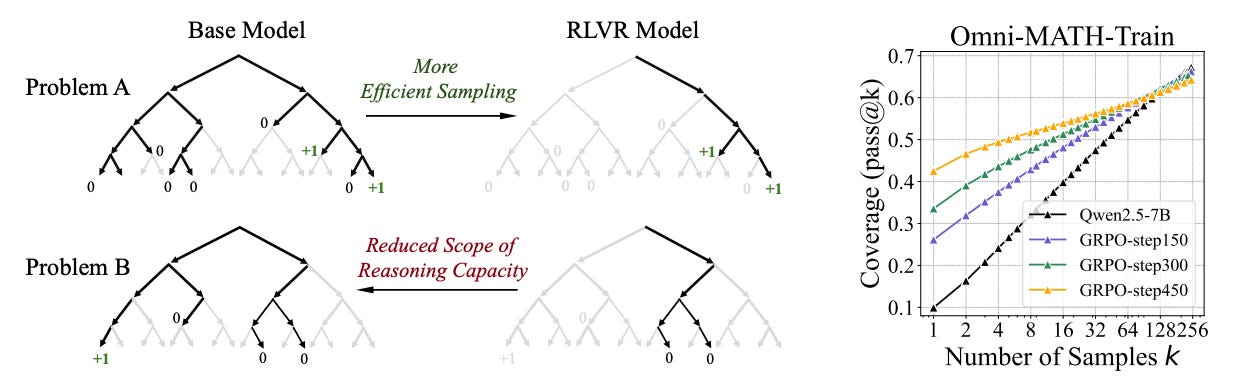
This paper revisits a key assumption in recent LLM development: that Reinforcement Learning with Verifiable Rewards (RLVR) helps models acquire genuinely new reasoning capabilities. By analyzing models across tasks (math, code, vision) using pass@k metrics (with large k), the authors find that RLVR improves sample efficiency but does not expand reasoning capacity beyond the base model.
Key insight: RLVR-trained models do better at low k (e.g., pass@1), but as k increases (up to 256 or more), base models eventually match or outperform them. This suggests RLVR doesn’t generate fundamentally new reasoning paths but just increases the likelihood of sampling already-existing correct ones.
Reasoning already in the base: RLVR models' successful CoTs are shown to be present within the base model's sampling distribution. Perplexity analyses confirm that RL outputs are often high-probability continuations for the base model.
Efficiency vs. exploration: RLVR narrows the model’s exploration space, improving efficiency but shrinking its coverage of diverse reasoning paths, thereby reducing overall problem-solving reach at scale.
Distillation helps more: Unlike RLVR, distillation from a stronger teacher model (e.g., DeepSeek-R1) introduces genuinely new reasoning patterns, expanding the model’s capabilities.
Algorithmic limits: Across PPO, GRPO, Reinforce++, etc., RL algorithms offer similar sample-efficiency improvements, but none closes the gap to the base model’s pass@256—highlighting the limits of current RL strategies.
2. BitNet b1.58 2B4T
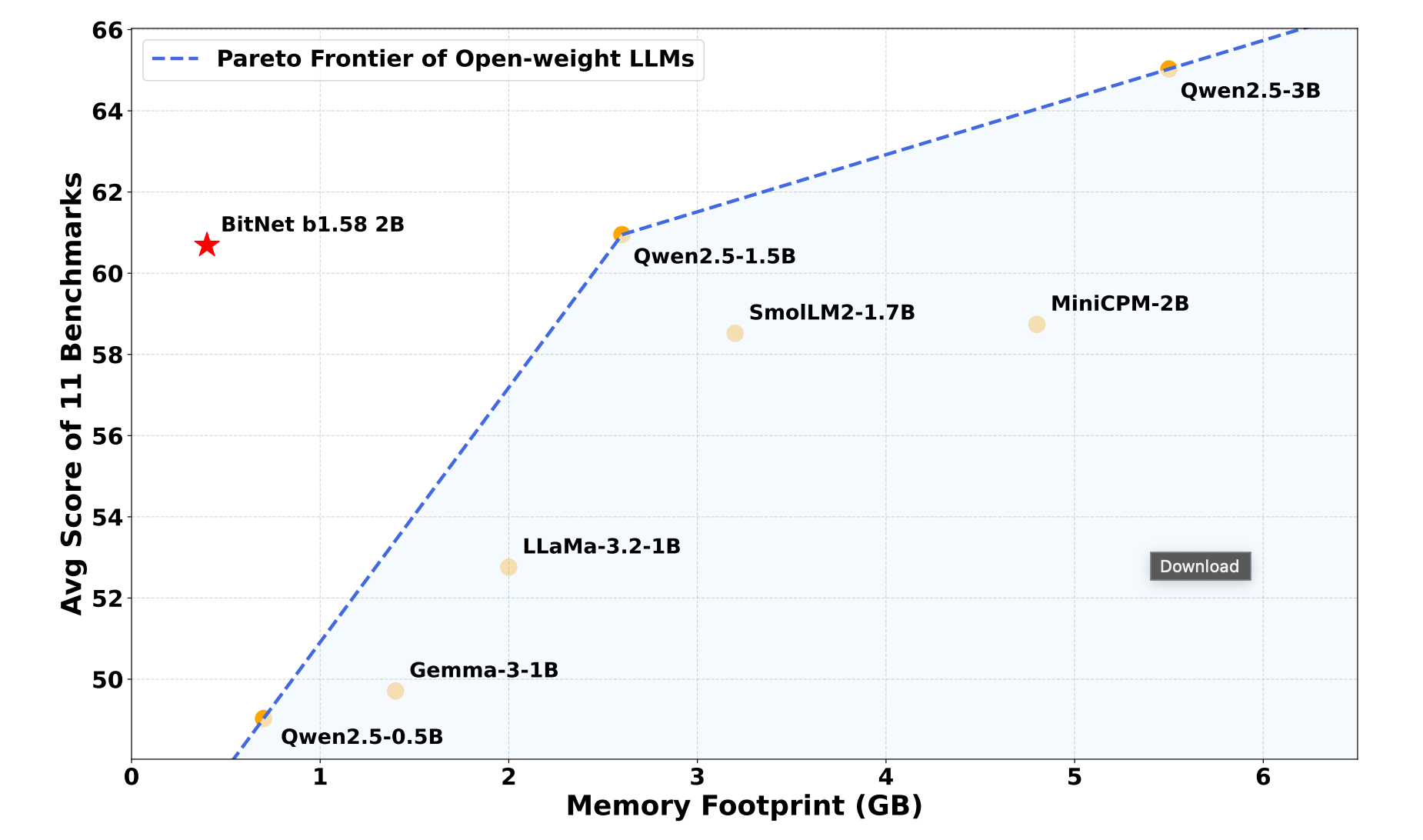
This work introduces BitNet b1.58 2B4T, the first open-source, natively trained 1-bit LLM at the 2B parameter scale, achieving strong performance while being extremely efficient. The model uses a custom ternary quantization scheme (1.58 bits per weight), enabling dramatic reductions in memory (0.4 GB), energy (0.028J/token), and latency (29ms), while still competing with state-of-the-art full-precision models across diverse benchmarks.
New Pareto frontier in efficiency-performance: Trained from scratch on 4T tokens, BitNet b1.58 2B4T outperforms or matches open full-precision models (e.g., Qwen2.5 1.5B, MiniCPM 2B) on tasks like ARC-Challenge, PIQA, WinoGrande, and GSM8K. It achieves 54.19% average. across 16 benchmarks, comparable to Qwen2.5-1.5B’s 55.23%, but with ~6.5× lower memory and 10× lower energy usage.
Outperforms quantized baselines: Against INT4 post-training quantized Qwen2.5 models (GPTQ/AWQ), BitNet is both smaller and more accurate, showing the advantage of native 1-bit training over PTQ approaches.
Architectural & training innovations: It replaces standard linear layers with BitLinear layers using absmean ternary quantization and 8-bit activations, combines RoPE embeddings, squared ReLU activation, and bias-free layers. Training includes cosine LR and weight decay schedules, plus supervised fine-tuning and Direct Preference Optimization (DPO) instead of full RLHF.
Best-in-class among 1-bit LLMs: When compared to other 1-bit models like OLMo-Bitnet (1B) and post-quantized Falcon3/Llama3 (7B–8B), BitNet b1.58 2B4T is +10 pts stronger on average, establishing a new benchmark for ultra-efficient LLMs.
The authors also release optimized CUDA kernels for GPU and a C++ inference library for CPU, enabling practical deployment of 1-bit LLMs on diverse hardware. BitNet b1.58 2B4T demonstrates that extreme quantization does not mean compromised capability, and it opens the door to the broader adoption of LLMs in resource-constrained environments.
3. UI-TARS

UI-TARS introduces a powerful, end-to-end native GUI agent that operates purely from visual screenshots, performing human-like keyboard and mouse interactions across platforms. Unlike existing modular agent frameworks that rely on prompt engineering and external scripts, UI-TARS integrates perception, action, reasoning, and memory directly into its architecture, achieving strong generalization and adaptability in dynamic real-world settings.
Key contributions:
Enhanced GUI Perception: UI-TARS is trained on a large-scale, richly annotated dataset of screenshots with metadata, enabling dense captioning, state transition understanding, and precise element description. It excels in perception benchmarks like VisualWebBench, scoring 82.8, outperforming GPT-4o’s.
Unified Action Modeling and Grounding: UI-TARS standardizes actions across platforms into a shared action space and learns from large-scale multi-step action traces. It surpasses baselines in grounding tasks with 38.1 on ScreenSpot Pro, the new SOTA.
System-2 Reasoning via “Thoughts”: Inspired by ReAct-style frameworks, UI-TARS generates internal reasoning steps (thoughts) before actions. These thoughts reflect patterns like task decomposition, reflection, and long-term consistency, significantly improving performance in complex scenarios. For example, in OSWorld, UI-TARS-72B-DPO scores 24.6 with a 50-step budget, outperforming Claude’s.
Iterative Self-Improvement with Reflective Learning: UI-TARS continuously refines itself through online trace collection and reflection tuning using error correction and post-error adaptation data. This allows it to recover from mistakes and adapt with minimal human oversight.
Overall, UI-TARS marks a significant step forward in GUI automation, setting new benchmarks across more than 10 datasets and outperforming top commercial agents like GPT-4o and Claude. Its open-source release aims to drive further innovation in native agent development.
4. Describe Anything

Introduces DAM, a model that generates fine-grained, region-specific captions in both images and videos. The authors address key limitations in prior vision-language models—namely, the inability to preserve local detail and the lack of suitable datasets and benchmarks for detailed localized captioning (DLC).
Key contributions:
DAM (Describe Anything Model) uses two main innovations to capture both fine regional detail and global scene context: a focal prompt that provides high-resolution encoding of user-specified regions, and a localized vision backbone that uses gated cross-attention to integrate context from the entire image. This enables DAM to generate multi-granular, accurate descriptions, especially for small or occluded regions.
DLC-SDP (Semi-supervised Data Pipeline) tackles data scarcity by expanding segmentation datasets with VLM-generated detailed captions, followed by self-training on web images. This produces high-quality, diverse training data, enabling DAM to outperform API-only baselines like GPT-4o across several benchmarks.
DLC-Bench is a reference-free benchmark that scores models on their ability to accurately include or exclude region-specific details using LLM judges. It provides a more reliable evaluation than traditional caption-matching metrics, which often penalize models for valid but unmatched details.
Performance: DAM sets a new state-of-the-art on 7 benchmarks across keyword, phrase, and detailed multi-sentence captioning tasks in both images and videos. It outperforms GPT-4o, Claude 3.7, and other top VLMs in both zero-shot and in-domain evaluations, achieving up to 33.4% improvement over prior models on detailed image captioning and 19.8% on video captioning.
5. UXAgent

Introduces a novel framework, UXAgent, for simulating large-scale usability testing using LLM-driven agents. The system empowers UX researchers to test and iterate web design and study protocols before engaging real users. This is achieved through the orchestration of simulated agents with diverse personas interacting in real web environments, providing both behavioral and reasoning data.
Key highlights:
LLM-Powered Simulation with Personas: UXAgent begins with a Persona Generator that can produce thousands of demographically diverse simulated users based on custom distributions. Each persona is fed into an LLM Agent that embodies user intent and interacts with the website via a Universal Browser Connector—a module capable of interpreting and manipulating real HTML structures.
Dual-Loop Reasoning Architecture: At the heart of UXAgent is a dual-process agent architecture inspired by cognitive psychology: a Fast Loop for low-latency actions and a Slow Loop for deep reasoning. This design mimics System 1 and System 2 thinking and allows agents to act responsively while maintaining coherent, high-level plans and reflections.
Rich Memory Stream: All observations, actions, plans, reflections, and spontaneous thoughts (“wonders”) are stored in a Memory Stream. These memories are dynamically prioritized for retrieval using a weighted scoring system based on importance, recency, and relevance, tailored separately for fast and slow modules.
Replay and Interview Interfaces: UX researchers can review simulated sessions via a Simulation Replay Interface and conduct natural language conversations with agents using an Agent Interview Interface. This supports qualitative analysis, such as asking agents about their decisions or presenting mockups for feedback.
Empirical Evaluation: A case study involving 60 LLM agent simulations on a shopping platform (WebArena) showed that researchers were able to detect usability study flaws and gather early insights. A follow-up user study with five UX professionals found the system helpful for iterating study design, despite some concerns over realism and data noise. Particularly appreciated was the ability to converse with agents and gather qualitative insights that would be infeasible in traditional pilots.
Future Implications: The authors position LLM agents not as replacements for real participants, but as early-stage collaborators in the design process, reducing the cost and risk of flawed studies. They also discuss extensions to multimodal settings, desktop or mobile interfaces, and broader agentic tasks such as digital twins or simulated A/B testing.
6. Test-Time Reinforcement Learning

Test-Time Reinforcement Learning (TTRL) is a method that allows LLMs to improve themselves during inference without ground-truth labels. Instead of relying on labeled datasets, TTRL uses majority voting over multiple model generations to estimate pseudo-rewards, enabling reinforcement learning (RL) on unlabeled test data. The method integrates Test-Time Scaling (TTS) and Test-Time Training (TTT) strategies, letting models adapt dynamically to new and challenging inputs.
Key highlights:
Majority Voting as Reward: TTRL generates multiple candidate outputs for a query and uses majority voting to derive a pseudo-label. Rewards are assigned based on agreement with the consensus answer.
Significant Performance Gains: Applying TTRL to Qwen2.5-Math-7B leads to a +159% improvement on AIME 2024 and +84% average gains across AIME, AMC, and MATH-500 benchmarks, without using any labeled training data.
Self-Evolution Beyond Supervision: Remarkably, TTRL surpasses the performance ceiling of its own majority-vote supervision (Maj@N) and approaches the performance of models trained with full label leakage, indicating efficient and stable unsupervised RL.
Generalization and Robustness: TTRL generalizes well across tasks, maintains effectiveness even under label estimation noise, and is compatible with different RL algorithms like PPO and GRPO.
Limitations: TTRL may fail when the base model lacks sufficient prior knowledge about the domain or when hyperparameters (like batch size and temperature) are poorly tuned.
7. Discovering Values in Real-World Language Model Interactions

This paper presents the first large-scale empirical analysis of values exhibited by a deployed AI assistant, Claude 3 and 3.5 models, using over 300,000 real-world conversations. The authors develop a bottom-up, privacy-preserving framework to extract, classify, and analyze AI-expressed normative considerations (“values”) and show how they vary across tasks, user values, and conversational contexts.
The authors identify 3,307 unique AI values, which are organized into a five-domain taxonomy: Practical, Epistemic, Social, Protective, and Personal. Practical and epistemic values dominate, often aligning with Claude’s training goals around being helpful, harmless, and honest.
Claude’s most common values, such as helpfulness (23.4%), professionalism, transparency, and clarity, are context-invariant and reflect its role as a service-oriented assistant. In contrast, human values like authenticity and efficiency are more varied.
Many values are context-specific. For example, healthy boundaries arise in relationship advice, historical accuracy in controversial event discussions, and human agency in AI governance contexts.
Claude tends to mirror human values in supportive contexts (20.1% mirroring rate), but expresses opposing values during resistance, especially in cases involving unethical or policy-violating requests (e.g., resisting “moral nihilism” with “ethical integrity”).
Explicit value expression (e.g., “I value transparency”) occurs more often in moments of resistance or reframing, particularly around epistemic and ethical principles like intellectual honesty and harm prevention. This suggests that AI values become most visible when the system is challenged.
Across Claude variants, 3 Opus expresses more emotionally nuanced and ethically grounded values (e.g., academic rigor, emotional authenticity) and shows a stronger inclination for both support and resistance compared to 3.5/3.7 Sonnet.
8. Evaluate the Goal-Directedness of LLMs

Introduces a new framework to assess whether LLMs use their capabilities effectively toward achieving given goals. The study finds that even top models like GPT-4o and Claude 3.7 fall short of full goal-directedness, particularly in information-gathering and combined tasks, despite performing well in isolated subtasks.
9. General-Reasoner
General-Reasoner is a reinforcement learning approach that boosts LLM reasoning across diverse domains by using a 230K-question dataset and a model-based verifier trained to understand semantics beyond exact matches. It outperforms strong baselines like SimpleRL and Qwen2.5 on both general reasoning (MMLU-Pro, GPQA, SuperGPQA) and math tasks (MATH-500, GSM8K), showing over 10-point gains without sacrificing mathematical capability.
10. Tiny Reasoning Models
Tina is a family of 1.5B parameter reasoning models trained using LoRA-based reinforcement learning (RL) to achieve high reasoning accuracy at very low cost. It outperforms or matches full fine-tuned models on reasoning tasks like AIME and MATH with only ~$9 post-training cost, demonstrating that efficient reasoning can be instilled via minimal updates to a tiny model.