
🥇Top AI Papers of the Week
The Top AI Papers of the Week (May 26 - June 1)
1. New Lens on RAG Systems
Introduces a new conceptual and empirical framework for analyzing RAG systems through the lens of sufficient context, whether the retrieved content alone enables answering a query. This notion helps decouple retrieval failures from generation errors in LLMs, providing clarity on model behavior under different contextual adequacy.
Key findings:
New definition and classifier for sufficient context: The authors formalize “sufficient context” as context that plausibly allows answering a query, without requiring ground truth. They develop a high-accuracy LLM-based autorater (Gemini 1.5 Pro, 93% accuracy) to label instances as having sufficient or insufficient context, enabling large-scale evaluation without needing ground-truth answers.
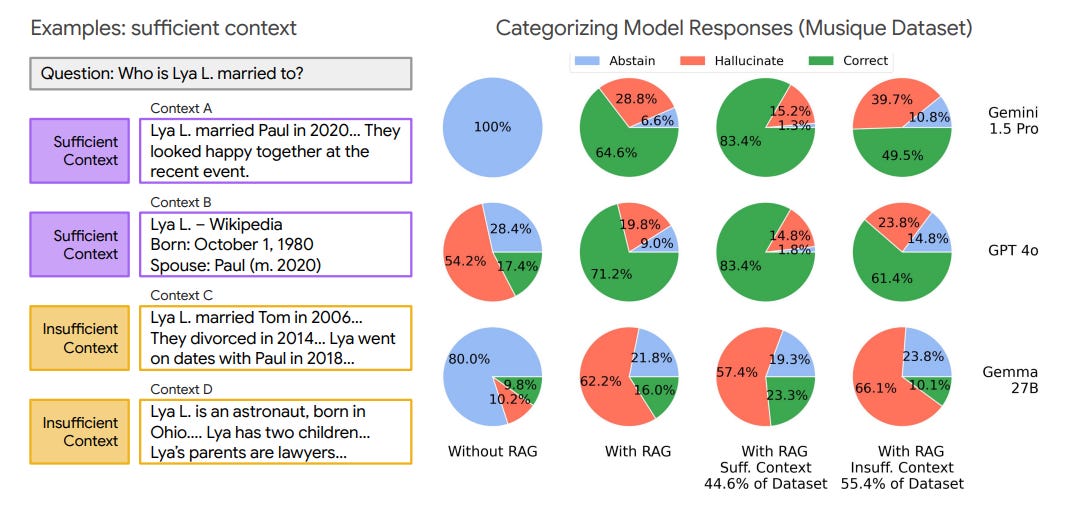
Sufficient context ≠ guaranteed correctness: Even when sufficient context is present, state-of-the-art LLMs like GPT-4o, Claude 3.5, and Gemini 1.5 still hallucinate answers more often than they abstain. Conversely, models can sometimes answer correctly despite insufficient context, likely leveraging parametric memory.
Benchmarks contain substantial insufficient context: Analysis of datasets like HotPotQA, Musique, and FreshQA shows that a significant fraction of queries (e.g., >50% in Musique and HotPotQA) lack sufficient context, even with curated or oracle retrieval setups.
Selective generation improves factuality: The authors propose a “selective RAG” method that combines model self-confidence with the sufficient context autorater to decide whether to answer or abstain. This yields consistent 2–10% gains in correctness (of answered queries) across Gemini, GPT, and Gemma models.
Fine-tuning alone is insufficient: Attempts to fine-tune smaller models like Mistral 3 7B for better abstention (e.g., training them to say “I don’t know” on insufficient examples) modestly increased abstention but often reduced accuracy or failed to meaningfully curb hallucinations.
2. Open-Ended Evolution of Self-Improving Agents

This work presents the Darwin Gödel Machine (DGM), a system that advances the vision of self-improving AI by combining self-referential code modification with open-ended evolutionary search. Unlike the original Gödel machine, which requires provable benefits for code changes (a practically intractable constraint), the DGM adopts an empirical approach: it modifies its own codebase and evaluates improvements on coding benchmarks.
Key contributions and findings:
Self-referential self-improvement loop: The DGM starts with a single coding agent that edits its own Python-based codebase to improve its ability to read, write, and execute code using frozen foundation models (FMs). Each modification is evaluated on benchmarks like SWE-bench and Polyglot, with only successful agents retained for further iterations.
Open-ended exploration via evolutionary archive: Inspired by Darwinian evolution, the system maintains an archive of all prior agents and samples parents based on performance and novelty. This enables exploration beyond local optima and supports continual innovation, including revisiting previously suboptimal variants that become valuable stepping stones later.
Empirical performance gains: Across 80 iterations, DGM boosts coding success on SWE-bench from 20.0% to 50.0% and on Polyglot from 14.2% to 30.7%, outperforming strong baselines that lack either self-improvement or open-endedness. Its best agents match or exceed leading human-designed, open-source coding agents.
Emergent tool and workflow improvements: Through self-improvement, DGM enhances its capabilities by evolving more granular editing tools, retry and evaluation mechanisms, history-aware patch generation, and code summarization for long contexts.
Generalization across models and tasks: Agents discovered by DGM generalize well when transferred across foundation models (e.g., Claude 3.5 to 3.7, o3-mini) and programming languages, demonstrating robust improvements not overfit to a particular setup.
Safety-conscious design: All experiments were sandboxed, monitored, and scoped to confined domains. The paper also discusses how future self-improvement systems could evolve safer, more interpretable behaviors if these traits are part of the evaluation criteria.
3. An Operating System for Memory-Augmented Generation in LLMs

Introduces a unified operating system for managing memory LLMs, addressing a key limitation in current architectures: their lack of structured, persistent, and governable memory. While today's LLMs rely primarily on parametric memory (model weights) and limited short-term context, MemOS proposes a comprehensive memory lifecycle and management infrastructure designed to support continual learning, behavioral consistency, and knowledge evolution.
Key contributions and components include:
Three-tier memory taxonomy: MemOS distinguishes between parametric memory (long-term weights), activation memory (short-term runtime states), and plaintext memory (editable, external content). These types are unified through a shared abstraction called the Memory Cube (MemCube), enabling seamless transformation (e.g., plaintext to parametric) and lifecycle governance.
MemCube abstraction: Each MemCube encapsulates memory metadata (creation time, type, access policies, etc.) and a semantic payload (text, tensors, LoRA patches). This enables dynamic scheduling, traceable updates, and interoperability between modules and agents.
Modular OS-style architecture: MemOS consists of three layers—Interface (user/API interaction), Operation (memory scheduling, lifecycle management), and Infrastructure (storage, access governance), that work together to manage memory parsing, injection, transformation, and archival.
Closed-loop execution flow: Every interaction (e.g., prompt response) can trigger memory operations governed by scheduling rules and lifecycle policies. Retrieved memory can be injected into generation, stored in archives, or transformed into other types for long-term use.
Vision for a memory-centric future: The paper proposes “memory training” as the next frontier beyond pretraining and finetuning, enabling models that learn continuously. Future work includes cross-model memory sharing, self-evolving memory blocks, and a decentralized memory marketplace.
4. Building Production-Grade Conversational Agents with Workflow Graphs

This paper presents a pragmatic, production-ready framework for building LLM-powered conversational agents using workflow graphs, with a specific focus on e-commerce scenarios. Instead of relying solely on end-to-end generation, the authors design agents using a directed acyclic graph (DAG), enabling flexible yet controllable interactions that adhere to strict business rules and format constraints.
Key contributions and findings include:
Multi-State DAG Framework: Each node in the graph corresponds to a conversational state with its own system prompt, tool access, and execution rules. This structure enables robust constraint handling (e.g., avoiding hallucinated responses or non-compliant suggestions) by localizing logic and formatting within specific graph nodes.
Fine-Tuning via Response Masking: Because conversation turns come from different states in the DAG, the authors introduce a fine-tuning strategy that applies selective loss masking to train LLMs only on responses relevant to a specific node’s context. This prevents prompt conflicts and improves adherence to node-specific constraints.
Real-World Deployment and Results: In a deployment across KakaoTalk and web platforms, the graph-based approach significantly outperformed baseline agents and even GPT-4o across key metrics like task accuracy (+52%) and format adherence (+50%). In human preference tests, their internal model was favored over GPT-4o in 63% of real-world user cases, especially in product recommendation and safety-critical tasks.
5. Spurios Rewards

This work challenges prevailing assumptions about reinforcement learning with verifiable rewards (RLVR) in mathematical reasoning tasks. The authors show that Qwen2.5-Math models can improve significantly under RL, even when trained with spurious or flawed rewards.
Surprisingly effective spurious rewards: The Qwen2.5-Math-7B model gains +21.4% accuracy with random rewards, +16.4% with format-based rewards, and +24.6% when explicitly trained on incorrect answers. These are close to the +28.8% gain from ground-truth reward signals, suggesting that RLVR surfaces latent capabilities rather than teaching new reasoning skills.
Model-specific generalization: Spurious rewards fail on other models like Llama3 or OLMo2. Only Qwen models consistently benefit, which the authors attribute to differences in pretraining. Notably, Qwen2.5-Math exhibits a unique “code reasoning” behavior, generating Python-like code to solve problems, which becomes more frequent post-RLVR and correlates strongly with accuracy.
Mechanism behind gains: The authors trace performance improvements to a shift in reasoning strategies. Most of the gain comes from language→code transitions, where the model switches from natural language to code reasoning during RLVR. Interventions that explicitly increase code usage (e.g., rewarding code-like responses or using a code-forcing prompt) boost performance further, but only on Qwen models.
Clipping bias enables learning from noise: Even with random rewards, performance improves due to GRPO’s clipping mechanism, which biases training toward reinforcing the model’s high-probability behaviors. These behaviors (e.g., code reasoning) happen to align with correctness in Qwen models but not in others.
6. Learn to Reason without External Rewards

Proposes a method for training LLMs via reinforcement learning without any external rewards or labeled data. Instead, it uses the model’s own self-certainty, a confidence measure based on KL divergence from uniform, as the sole intrinsic reward. This self-improvement strategy, part of the broader Reinforcement Learning from Internal Feedback (RLIF) paradigm, bypasses the limitations of Reinforcement Learning with Verifiable Rewards (RLVR), which requires domain-specific verifiers and gold-standard outputs.
Key highlights:
INTUITOR matches GRPO without external supervision: When applied to mathematical reasoning tasks like GSM8K and MATH500, INTUITOR achieves performance on par with GRPO (a strong RLVR method), even without using gold solutions. On out-of-domain tasks such as LiveCodeBench and CRUXEval, INTUITOR generalizes better, achieving higher gains than GRPO (+65% vs. 0% and +76% vs. +44%, respectively).
Rapid early learning and enhanced instruction-following: INTUITOR significantly boosts early training performance, particularly on models like Qwen2.5-1.5B, and improves adherence to chat-style instructions, reducing repetitive or nonsensical output.
Emergent structured reasoning: Trained models display spontaneous reasoning even when not explicitly required, often generating explanations or planning steps before producing code or answers. This behavior correlates with better transfer performance to domains like code generation.
Self-certainty as a robust, hack-resistant signal: Unlike fixed reward models prone to exploitation, online self-certainty adapts with the model and avoids reward hacking. INTUITOR-trained models show the strongest correlation between self-certainty and correct answers, confirmed by statistical tests.
7. Learn to Reason via Mixture-of-Thought

While most prior approaches train with a single modality and only ensemble during inference, this work introduces Mixture-of-Thought (MoT) to jointly train and infer across modalities, resulting in notable gains in logical reasoning performance. Key findings:
Three-modality synergy: MoT uses natural language for interpretability, code for structured procedural reasoning, and truth tables to explicitly enumerate logical cases. Error analysis shows that truth tables significantly reduce common LLM failure modes like missing branches or invalid converses.
Self-evolving training: MoT introduces an iterative, on-policy training loop where the model generates, filters, and learns from its own multi-modal reasoning traces. This joint training outperforms both single-modality and partial-modality setups.
Inference via voting: At test time, MoT generates predictions from each modality and selects the majority answer, leading to robust predictions. Results show up to +11.7pp average accuracy gains on FOLIO and ProofWriter, with 9B models matching GPT-4 + Logic-LM performance.
Stronger on harder tasks: MoT delivers the largest improvements on problems with higher reasoning depth (5–8 steps). It also shows superior test-time scaling, with more diverse and accurate outputs under fixed inference budgets. MoT demonstrates that LLMs can achieve significantly more robust logical reasoning by reasoning like humans (using multiple modes of thought), not just by sampling more from a single modality.
8. QwenLong-L1
A new reinforcement learning framework that scales large reasoning models (LRMs) from short to long contexts using progressive context scaling and hybrid rewards. It achieves top performance on seven long-context benchmarks, surpassing models like OpenAI-o3-mini and Qwen3-235B-A22B, and matching Claude-3.7-Sonnet-Thinking, demonstrating strong reasoning with up to 120K token inputs.
9. End-to-End Policy Optimization for GUI Agents
ARPO introduces an end-to-end reinforcement learning method for training GUI agents using Group Relative Policy Optimization (GRPO) with experience replay. It significantly improves in-domain performance on the OSWorld benchmark, outperforming baselines by up to 6.7%, while offering modest gains on out-of-domain tasks and enabling self-corrective behaviors through structured reward feedback.
10. Generalist Agent Enabling Scalable Agentic Reasoning
Proposes Alita, a generalist agent framework that enables scalable agentic reasoning through minimal predefinition and maximal self-evolution. Unlike traditional agents reliant on handcrafted tools, Alita autonomously constructs reusable MCPs (Model Context Protocols) using web search and code synthesis, outperforming more complex systems like OpenAI DeepResearch and OctoTools on GAIA, MathVista, and PathVQA benchmarks.