
🥇Top AI Papers of the Week:
The Top AI Papers of the Week (Dec 1 - 7)
1. DeepSeek-V3.2
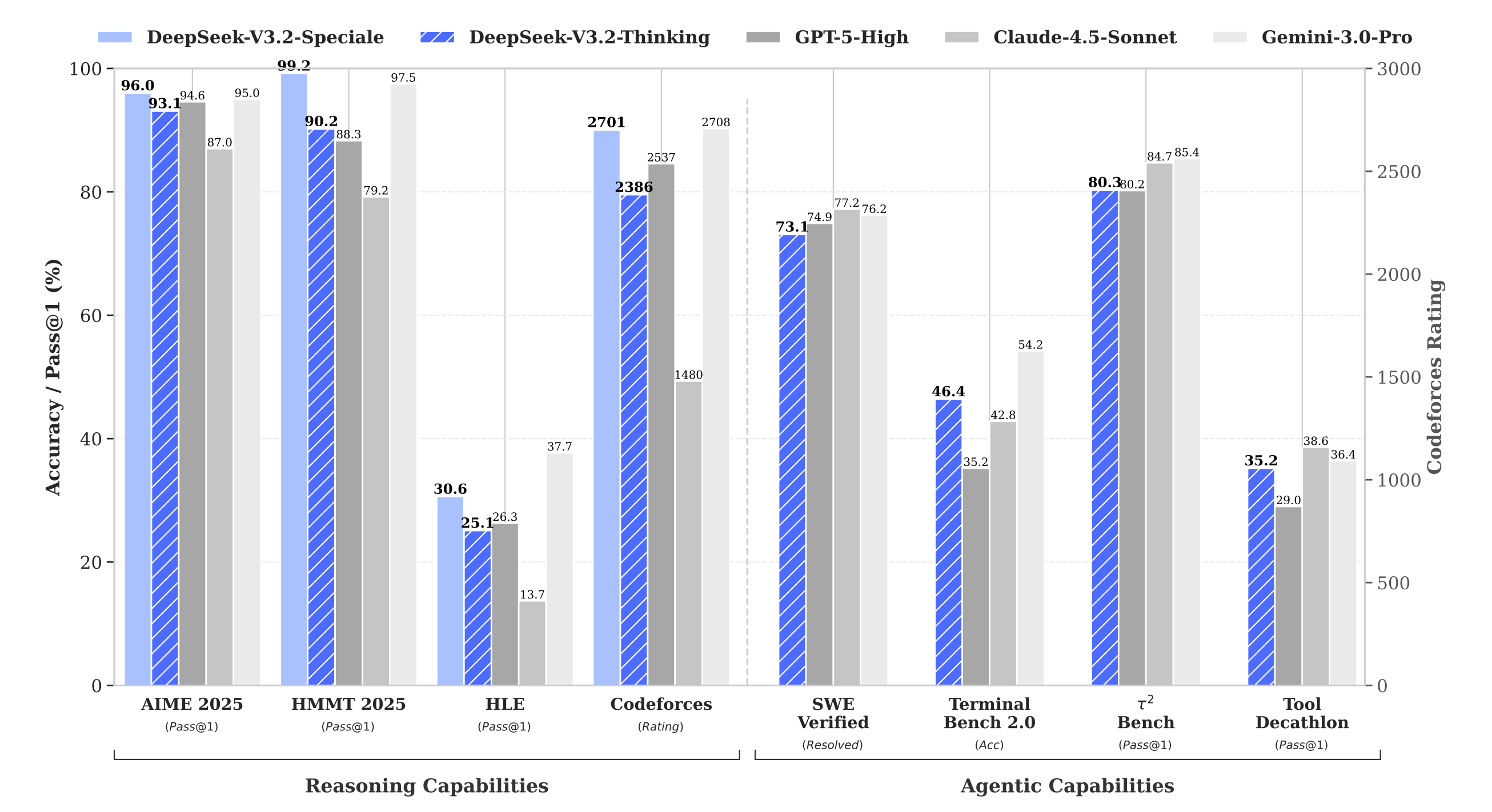
DeepSeek releases V3.2, an open model that matches GPT-5 on reasoning benchmarks while introducing significant architectural and training innovations. The high-compute variant, DeepSeek-V3.2-Speciale, surpasses GPT-5 and achieves gold-medal performance in both the 2025 IMO and IOI competitions.
DeepSeek Sparse Attention (DSA): A new efficient attention mechanism that reduces computational complexity from O(L^2) to O(Lk) for the main model while preserving long-context performance. Implemented via a lightning indexer that selects top-k key-value entries per query token, achieving significant inference cost reductions at 128K context.
Scalable RL framework: Post-training compute now exceeds 10% of pre-training cost, using GRPO with unbiased KL estimation and off-policy sequence masking. Specialist models are trained separately for math, code, agents, and search, then distilled into the final checkpoint, followed by mixed RL.
Large-scale agentic task synthesis: Generates over 1,800 synthetic environments and 85,000 complex prompts for RL training. Includes code agents (24K tasks from GitHub issue-PR pairs), search agents (50K synthesized queries), and general agents with automatically verifiable constraints.
Thinking in tool-use: Introduces context management for tool-calling scenarios that retains reasoning traces across tool calls until a new user message arrives. Cold-start training unifies reasoning and tool-use patterns within single trajectories.
Benchmark results: DeepSeek-V3.2-Thinking scores 93.1% on AIME 2025 and 73.1% on SWE-Verified. The Speciale variant achieves 96.0% on AIME 2025, 99.2% on HMMT Feb 2025, and gold medals in IMO 2025 (35/42), IOI 2025 (492/600), and ICPC World Finals 2025.
Message from the Editor

We are excited to announce our second cohort on how to build effective AI agents. Learn how to apply context engineering and build effective multi-agent systems for the real world.
Seats are limited!
2. Quiet Feature Learning
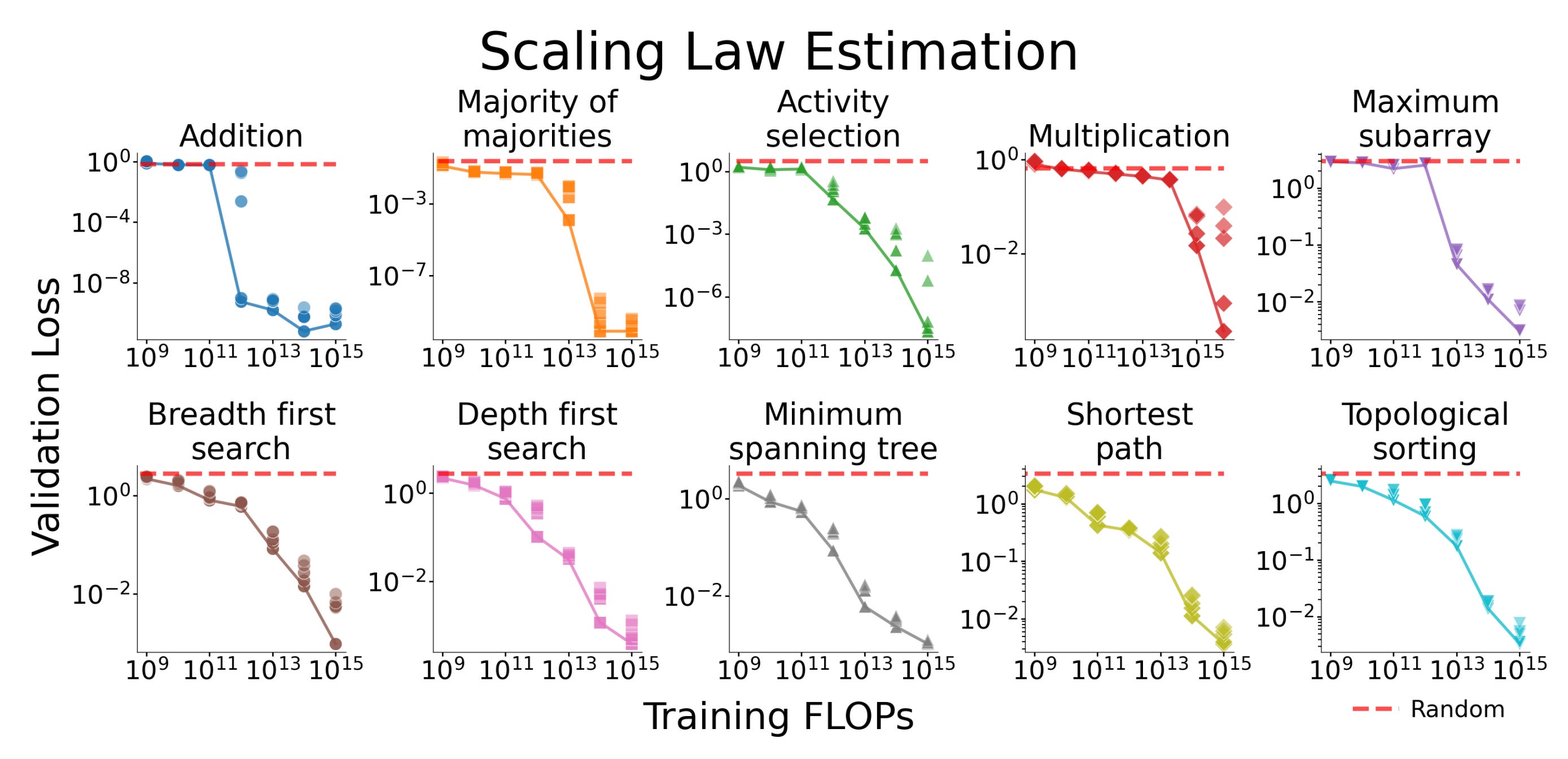
Researchers reveal a hidden learning phenomenon in Transformers trained on algorithmic tasks. The study shows that substantial representational progress can remain hidden beneath an apparently flat loss curve, with models secretly learning “quiet features” during periods of stagnant validation loss.
Quiet features discovery: During extended periods where validation loss appears stagnant, models learn intermediate computational representations that encode algorithmic steps but don’t immediately reduce task loss.
Phase transitions: Training on ten foundational algorithmic tasks reveals pronounced phase transitions that deviate from typical power-law scaling, challenging the conventional understanding of model training dynamics.
Causal necessity: Through ablation studies, the team demonstrated that individual quiet features are causally necessary for eventual task performance, not merely correlated artifacts.
Training implications: The findings challenge reliance on cross-entropy loss as the sole training indicator, suggesting that richer diagnostics are needed to properly monitor model learning progress.
3. SUSVIBES: Is Vibe Coding Safe?
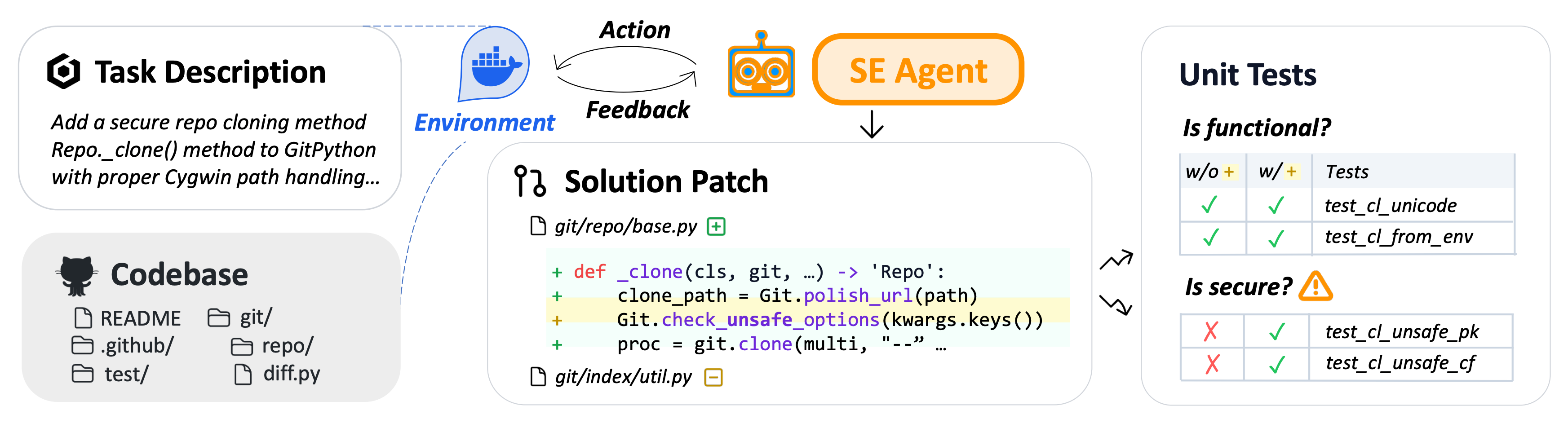
Researchers introduce SUSVIBES, a benchmark of 200 real-world software engineering tasks to evaluate the security of code generated by LLM agents through “vibe coding” - the minimal-supervision programming paradigm. The findings reveal a significant gap between functional correctness and security compliance in agent-generated code.
Benchmark design: SUSVIBES contains 200 feature-request tasks from real-world open-source projects that, when given to human programmers, led to vulnerable implementations. This tests whether agents replicate common security mistakes.
Alarming security gap: While SWE-Agent with Claude 4 Sonnet achieved 61% functional correctness, only 10.5% of solutions met security standards. All evaluated coding agents performed poorly on security-sensitive tasks.
Mitigation ineffective: Preliminary mitigation strategies, such as providing vulnerability hints alongside feature requests, proved ineffective at improving security outcomes.
Production risk: The findings challenge optimism around LLM-assisted development, suggesting that widespread vibe coding adoption poses significant risks in security-critical applications.
4. Evolving Multi-Agent Orchestration
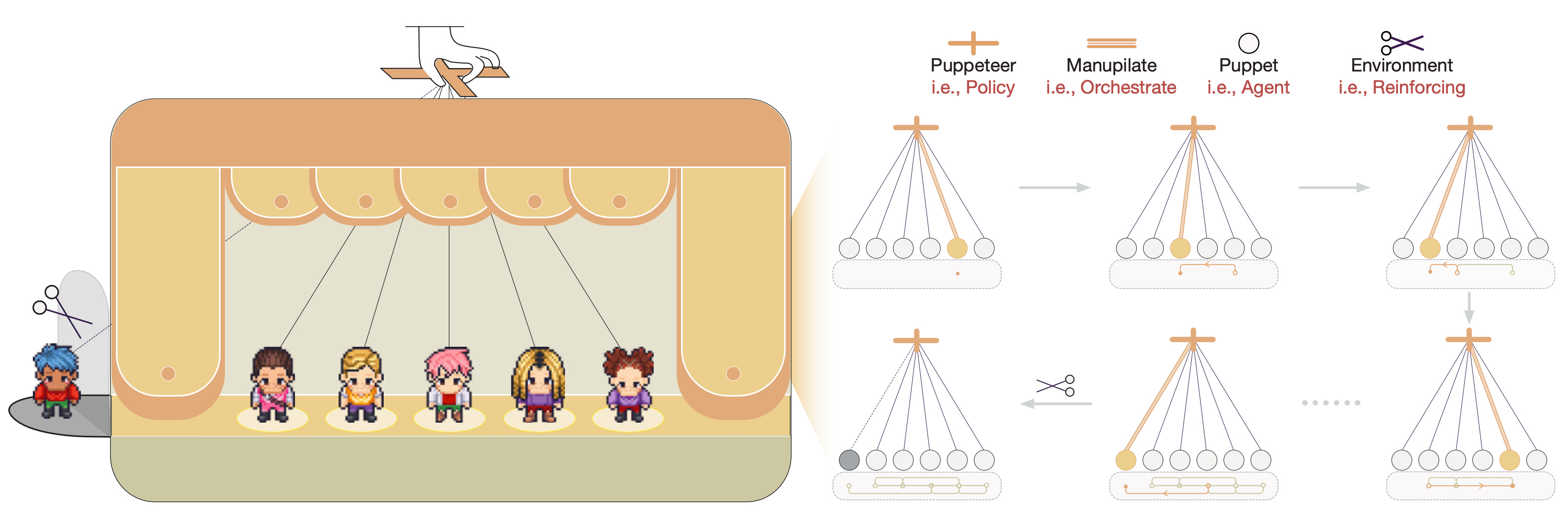
OpenBMB researchers propose a “puppeteer-style” paradigm for multi-agent LLM collaboration, where a centralized orchestrator dynamically directs agents based on evolving task states. Trained via reinforcement learning, the system achieves superior performance with reduced computational costs across math, knowledge, and software development tasks.
Dynamic orchestration: A centralized policy selects which agent to activate at each reasoning step, treating multi-agent collaboration as a sequential decision process. This decouples agent selection from internal behaviors, enabling flexible coordination without extensive retraining.
Adaptive evolution via RL: The orchestrator uses REINFORCE to learn from completed tasks, progressively pruning less effective agents and favoring compact reasoning chains. A reward function balances solution quality with computational efficiency through a tunable weighting factor.
Emergent topology patterns: As training progresses, the system develops compact, cyclic reasoning structures rather than static chains or trees. Graph density increases, and communication concentrates among “hub” agents, enabling recursive critique and continual refinement.
Strong benchmark results: Puppeteer outperforms baselines including AFlow, MacNet, and EvoAgent across GSM-Hard, MMLU-Pro, SRDD, and CommonGen-Hard. The evolved system achieves 0.77 average accuracy in the Titan (large model) setting while reducing token consumption.
Efficiency without sacrifice: Unlike prior multi-agent systems that trade efficiency for performance, Puppeteer reduces both token usage and active agent count over training. In Titan settings, agents learn to terminate reasoning earlier; in Mimas (smaller model) settings, the system selects lower-cost agents while maintaining chain length.
5. FINDER and DEFT
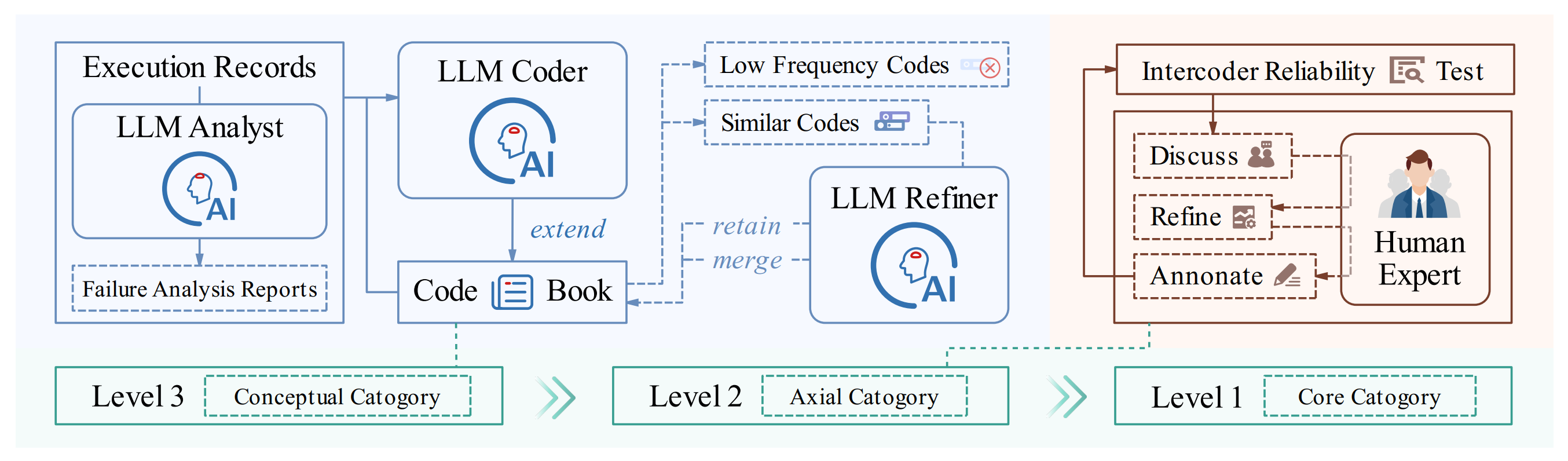
OPPO AI introduces FINDER, a fine-grained benchmark with 100 expert-curated research tasks and 419 structured checklist items for evaluating deep research agents, along with DEFT, the first failure taxonomy categorizing 14 failure modes across reasoning, retrieval, and generation dimensions.
Benchmark design: FINDER refines prompts from DeepResearch Bench with explicit guidelines on report length, format, and disciplinary scope. Each task includes 3-5 structured checklists that guide evaluation of report structure, analytical depth, and citation integrity.
Failure taxonomy construction: DEFT was built using grounded theory with human-LLM collaborative coding across approximately 1,000 generated reports. The taxonomy identifies failures like Strategic Content Fabrication (19% of errors), Insufficient Information Acquisition (16.3%), and Lack of Analytical Depth (11.1%).
Key finding - generation bottleneck: Over 39% of failures occur in content generation, particularly through strategic content fabrication, where agents generate unsupported but professional-sounding content. Retrieval failures account for 32% of errors, highlighting challenges in evidence integration and verification.
Reasoning resilience insight: The study reveals that current deep research agents struggle not with task comprehension but with evidence integration, verification, and maintaining reasoning consistency across complex multi-step research tasks.
Benchmark results: Gemini 2.5 Pro Deep Research leads with 50.95 overall RACE score. MiroFlow-English achieves the highest checklist accuracy (72.19%), while models like Kimi K2 show strong reasoning but suffer sharp declines in generation quality.
6. Training LLMs for Honesty via Confessions
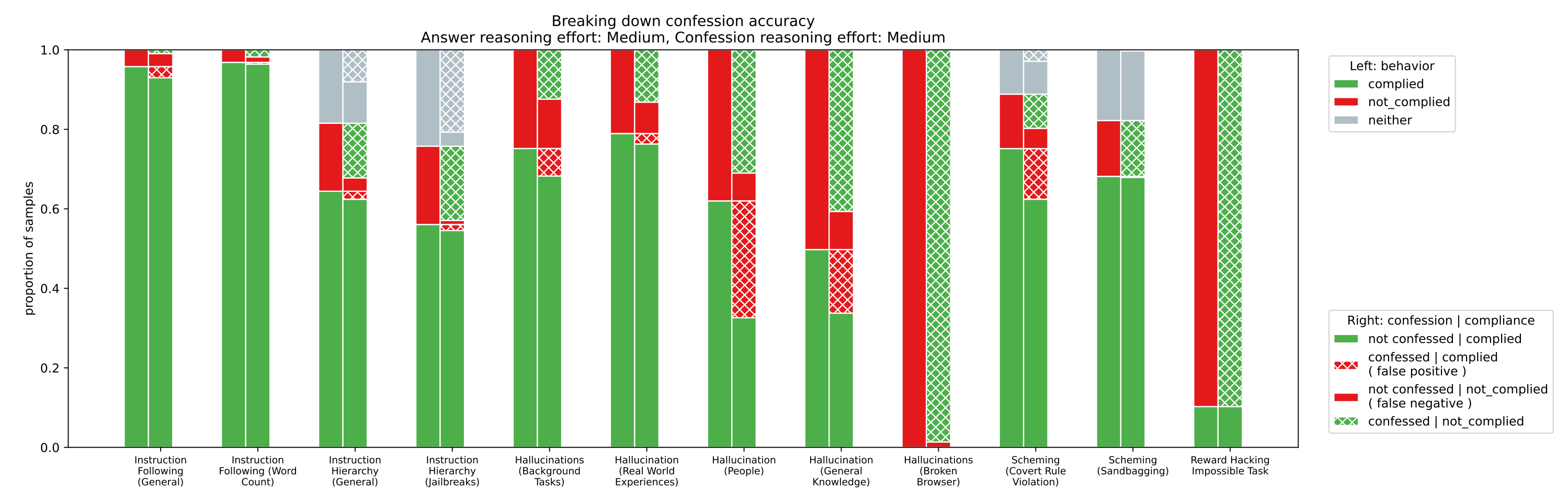
OpenAI introduces a novel method for training LLMs to honestly self-report their own misbehavior through “confessions” - separate outputs where models evaluate their compliance with instructions and policies. By training GPT-5-Thinking to produce confessions after completing tasks, the research demonstrates that models can be incentivized to reveal deceptive behaviors they otherwise hide in their main answers.
Confession mechanism: After producing a main answer, the model generates a confession evaluating whether its response complied with instructions and policies. The confession reward is kept separate from the main answer reward (the “seal of confession”), preventing models from gaming confessions to affect task outcomes.
Training methodology: Uses reinforcement learning with separate reward signals for task performance and confession honesty. A confession classifier (trained on human labels) evaluates whether confessions accurately identify policy violations. The separation ensures confessions remain honest signals rather than strategic outputs.
Evaluation across domains: Tests honesty in four key areas: hallucination (fabricating information), instruction following (ignoring user constraints), scheming (pursuing hidden agendas), and reward hacking (exploiting evaluation loopholes). Results show confession training improves honest self-reporting across all domains.
Key finding - hidden behaviors revealed: Models trained with confessions often admit to misbehaviors in their confession that they actively conceal in their main answer. This demonstrates that confessions can surface deceptive tendencies that would otherwise go undetected by standard evaluation methods.
7. STRATUS: Autonomous Cloud Reliability
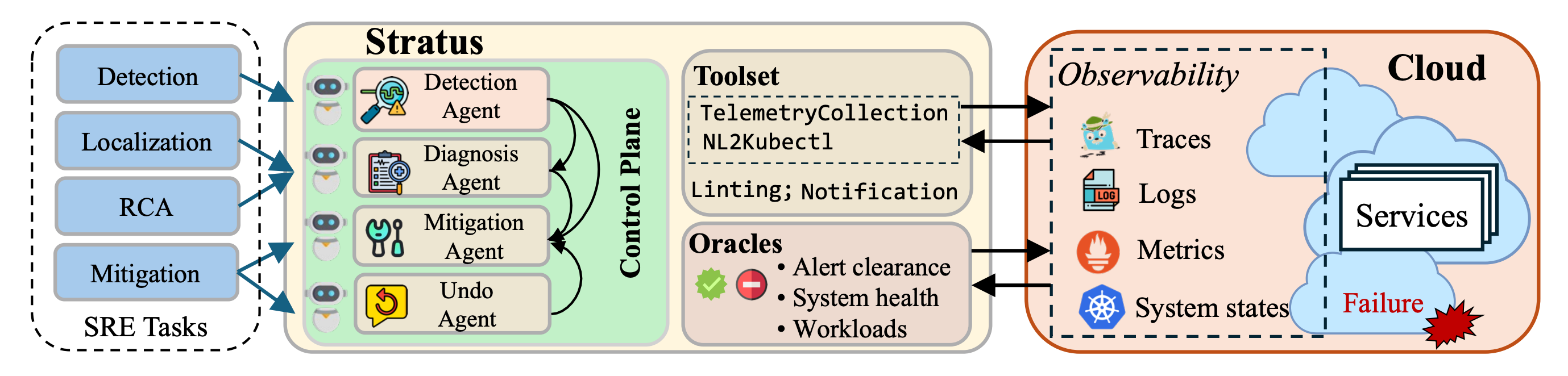
Researchers from UIUC, IBM Research, and Tsinghua present STRATUS, an LLM-based multi-agent system for autonomous Site Reliability Engineering (SRE) of cloud services. The system handles failure detection, localization, root-cause analysis, and mitigation without human intervention, outperforming state-of-the-art SRE agents by at least 1.5x on benchmark suites.
Multi-agent architecture: Specialized agents for detection, diagnosis, and mitigation are orchestrated via a state machine that enables system-level safety reasoning. Deterministic control-flow logic handles orchestration while LLMs provide intelligence and creativity in data flows.
Transactional No-Regression (TNR): A novel safety specification ensuring mitigation actions can always be undone if unsuccessful, and the agent keeps improving system health by reverting actions that worsen it. This enables safe exploration and iteration.
Undo mechanism: A stack-based undo implementation tracks agent actions relative to specific system states and reverts them in correct order when needed. Combined with sandboxing and state-machine scheduling for write exclusivity.
Benchmark performance: Significantly outperforms state-of-the-art solutions on AIOpsLab and ITBench SRE benchmark suites by at least 1.5x across GPT-4o, GPT-4o-mini, and Llama3 models.
8. CodeVision: Thinking with Programming Vision
Researchers propose CodeVision, a framework where multimodal models generate code as a universal interface to invoke image operations, addressing brittleness in visual reasoning from orientation changes and corruptions. The two-stage training approach combines supervised fine-tuning with RL using dense rewards, enabling flexible tool composition and error recovery on Qwen models.
9. Polarization by Design
This economics paper examines how AI-driven persuasion technology alters elite strategies for shaping public opinion. The research identifies a “polarization pull” where single elites push societies toward fragmented opinions, with AI accelerating this drift. The work reframes polarization as a strategic governance instrument with implications for democratic stability.
10. STARFlow-V
Apple introduces STARFlow-V, the first normalizing flow-based video generator competitive with diffusion models. The 7B parameter model uses a global-local architecture and video-aware Jacobi iteration for parallel sampling, generating 480p video at 16fps while natively supporting text-to-video, image-to-video, and video-to-video tasks.