
🥇Top AI Papers of the Week
The Top AI Papers of the Week (Mar 3 - 9)
1). A Few Tokens Are All You Need

Researchers from Tencent AI Lab and The Chinese University of Hong Kong, Shenzhen propose a new approach to boost reasoning in LLMs by only fine-tuning on the first few tokens of generated solutions. Key ideas include:
Prefix Self-Consistency – The authors show that even if different solution paths diverge later, their initial tokens often share core reasoning steps. Tuning on these prefixes (as few as 8–32 tokens) provides a powerful unsupervised signal.
Minimal Token Training – By training only on short prefixes, the method drastically reduces computational cost (up to 16× fewer tokens vs. full-chain fine-tuning) while preserving reasoning structure.
Comparable to Supervised Methods – Despite relying on unsupervised prefixes (no correctness filtering), it matches or exceeds the performance of more compute-heavy methods like Rejection Sampling Fine-Tuning (RFT).
Broad Applicability – It works with different LLM architectures (general-purpose and math-specialized) and scales effectively from small to large custom datasets.
Label-Optional Approach – Works in purely unsupervised mode but can also incorporate ground-truth answer checks if available, further boosting accuracy.
2). A Deep Dive into Reasoning LLMs

This survey explores how LLMs can be enhanced after pretraining through fine-tuning, reinforcement learning, and efficient inference strategies. It also highlights challenges like catastrophic forgetting, reward hacking, and ethical considerations, offering a roadmap for more capable and trustworthy AI systems.
3). Cognitive Behaviors that Enable Self-Improving Reasoners

Researchers from Stanford University and colleagues investigate why some language models excel in reinforcement learning (RL)-based self-improvement, while others quickly plateau. The study identifies four cognitive behaviors—verification, backtracking, subgoal setting, and backward chaining—that underpin successful problem-solving in both humans and language models. Key findings:
Cognitive behaviors drive model improvement – Models naturally exhibiting verification and backtracking (like Qwen-2.5-3B) significantly outperform those lacking these behaviors (like Llama-3.2-3B) in RL tasks such as the Countdown math game.
Behavior priming boosts performance – Introducing cognitive behaviors into models through priming substantially enhances RL-driven improvements. Notably, priming with reasoning patterns (even from incorrect solutions) matters more than solution accuracy itself.
Pretraining behavior amplification – Curating pretraining data to emphasize cognitive behaviors enables previously lagging models (e.g., Llama-3.2-3B) to achieve performance comparable to inherently proficient models (Qwen-2.5-3B).
Generalization potential – The identified cognitive behaviors, once amplified through training, show generalizable benefits across reasoning tasks beyond the specific Countdown game used in experiments.
The paper suggests that effectively inducing cognitive behaviors in language models through targeted priming and pretraining modifications significantly improves their capacity for self-improvement.
4). Conversational Speech Model

Researchers from Sesame propose an end-to-end multimodal TTS approach for natural, context-aware speech in real-time conversational AI systems.
Beyond one-to-many TTS – Traditional text-to-speech lacks rich contextual awareness. CSM addresses the “one-to-many” problem (countless valid ways to speak a sentence) by conditioning on conversation history, speaker identity, and prosodic cues.
End-to-end architecture on RVQ tokens – CSM directly models Residual Vector Quantization (RVQ) audio tokens via two autoregressive transformers: (1) a multimodal backbone that interleaves text/audio to generate the zeroth codebook level and (2) a lightweight decoder for the remaining codebooks. This single-stage design enhances efficiency and expressivity.
Compute amortization – Training on full RVQ codebooks is memory-heavy; to mitigate this, CSM only trains the decoder on a random 1/16 of frames while still learning the zeroth codebook fully. This preserves fidelity yet reduces computational load.
Strong evaluations –
Objective: Achieves near-human accuracy on word error rate (WER) and speaker similarity (SIM) tests. Introduces new metrics for homograph disambiguation and pronunciation consistency, showing scaling from Tiny to Medium boosts speech realism.
Subjective: A CMOS (Comparative Mean Opinion Score) study on the Expresso dataset reveals human-level naturalness with no context, though a gap remains when conversation context is included—highlighting the challenge of fully capturing nuanced human prosody.
Open-source and future plans – The team will release their models under Apache 2.0. Next steps include scaling model size, expanding to 20+ languages, leveraging pre-trained LLM weights, and exploring more sophisticated “fully duplex” conversation dynamics.
5). Forecasting Rare Language Model Behaviors
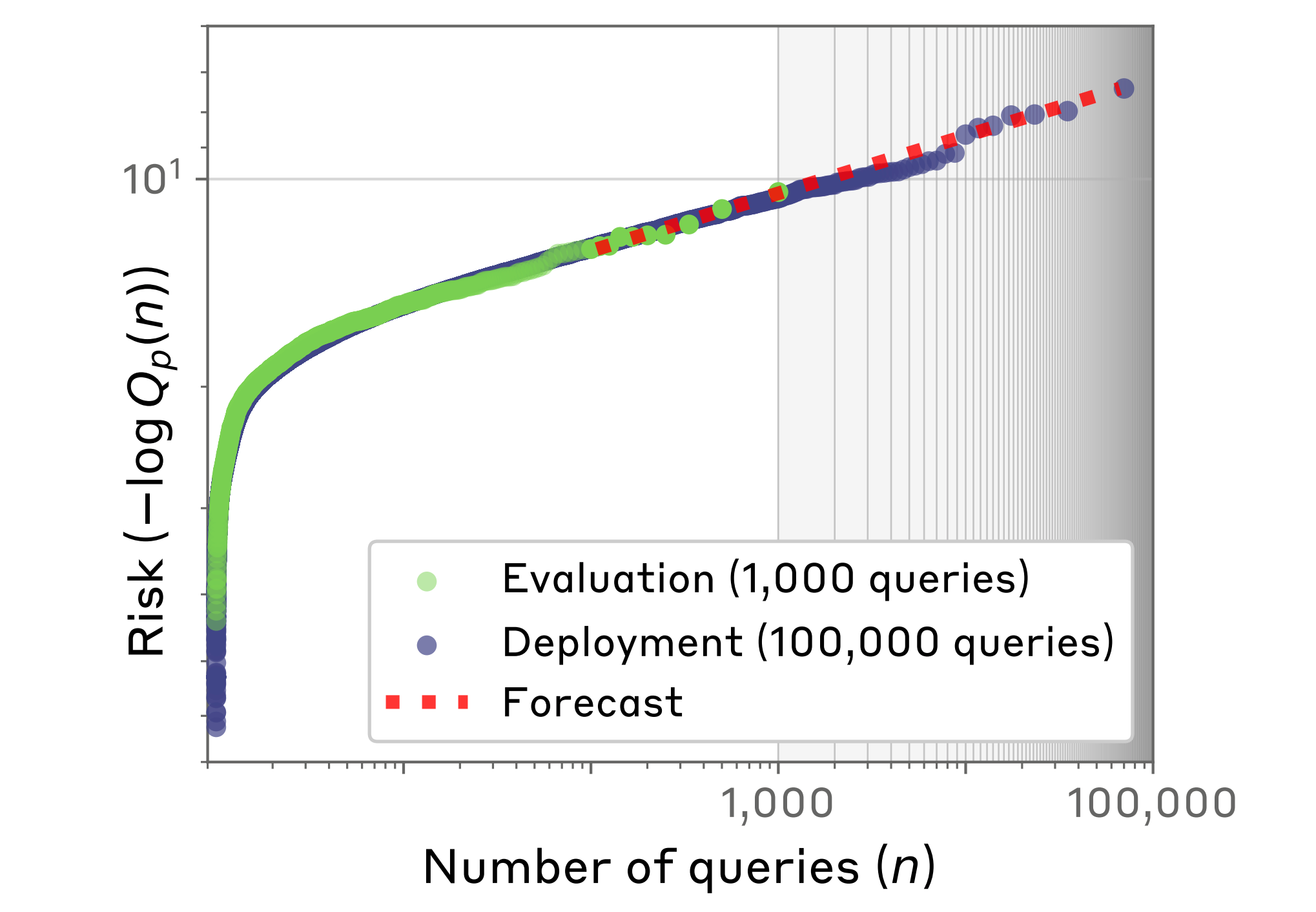
A team from Anthropic and collaborators introduced a method to predict “one-in-a-million” failures that might only appear at deployment scale, enabling developers to patch issues preemptively. Key insights include:
Elicitation probabilities – By sampling multiple outputs from a query and measuring how often a target (undesired) behavior occurs, they estimate how “at-risk” each query is. Even prompts that appear safe can have a low-but-nonzero probability of producing harmful responses.
Power-law scaling of risks – The authors show that the largest elicitation probabilities (the worst-case queries) grow predictably with the number of queries sampled. This allows them to forecast extreme tail risks—like chemical or power-seeking “jailbreaks”—from smaller-scale tests.
Multiple safety metrics – They formalize metrics such as worst-query risk (the maximum single probability of a bad behavior), behavior frequency (fraction of queries likely to succeed in eliciting it), and aggregate risk (chance any query draws out the failure). All can be extrapolated to larger deployment volumes.
Improved red-teaming – By identifying which model (or how much sampling) best uncovers failures, they can allocate limited red-teaming budget more efficiently. The framework highlights potential pitfalls before models process billions of queries.
6). Differentiable Logic Cellular Automata

A team from Google’s Paradigms of Intelligence introduces a fully discrete twist on Neural Cellular Automata (NCA) by replacing floating-point neural layers with Differentiable Logic Gate Networks. The result is a system where each cell’s state is a binary vector, updated by a learned logic circuit—enabling interpretable local rules with end-to-end differentiable training.
Local logic gates instead of continuous neurons – Traditional Neural CAs rely on floating-point operations. Here, each cell update is done by a network of learnable AND/OR/XOR gates in “soft” form during training, then converted to pure binary gates for inference.
Successfully learns Game of Life – The authors confirm the approach by replicating Conway’s Game of Life rules exactly. After training on all 3×3 grid configurations, the learned circuit perfectly recovers classic Life patterns (e.g. gliders, still lifes).
Generates complex patterns & self-organization – In more advanced tasks, the model learns to produce a checkerboard pattern, color images (like a letter “G”), and even a growing lizard—all via purely local binary updates. The learned rules generalize to larger grids, exhibit fault tolerance, and even support asynchronous updates.
Towards robust & interpretable computing – Because the final system is just a discrete circuit, analysis and visualization of the logic gates are straightforward. The authors highlight potential applications in programmable matter, emphasizing that learned discrete rules can be remarkably robust to failures or hardware variations.
7). How Well do LLMs Compress Their Own Chain-of-Thought?

This new paper investigates how LLMs balance chain-of-thought (CoT) reasoning length against accuracy. It introduces token complexity, a minimal token threshold needed for correct problem-solving, and shows that even seemingly different CoT “compression prompts” (like “use bullet points” or “remove grammar”) fall on the same universal accuracy–length trade-off curve. Key highlights include:
Universal accuracy–length trade-off – Despite prompting LLMs in diverse ways to shorten reasoning (e.g. “be concise,” “no spaces,” “Chinese CoT”), all prompts cluster on a single trade-off curve. This implies that length, not specific formatting, predominantly affects accuracy.
Token complexity as a threshold – For each question, there’s a sharp cutoff in tokens required to yield the correct answer. If the LLM’s CoT is shorter than this “token complexity,” it fails. This threshold provides a task-difficulty measure independent of the chosen prompt style.
Information-theoretic upper bound – By treating CoT compression as a “lossy coding” problem, the authors derive theoretical limits on how short a correct reasoning chain can be. Current prompting methods are far from these limits, highlighting large room for improvement.
Importance of adaptive compression – The best strategy would match CoT length to problem difficulty, using minimal tokens for easy questions and more thorough CoTs for harder ones. Most LLM prompts only adapt slightly, leaving performance gains on the table.
8). LADDER
LADDER is a framework enabling LLMs to recursively generate and solve progressively simpler variants of complex problems—boosting math integration accuracy. Key insights include:
Autonomous difficulty-driven learning – LADDER lets models create easier problem variants of an initially hard task, then apply reinforcement learning with a verifier. This self-directed approach provides a natural curriculum, removing the need for human feedback or curated datasets.
Test-Time Reinforcement Learning (TTRL) – Beyond training, the authors propose TTRL: generating problem-specific variant sets right at inference. By refining solutions on these simpler sub-problems, the model boosts its final accuracy (e.g., from 73% to 90% on the MIT Integration Bee).
Generalizable verification – Rather than symbolic or hand-crafted solutions, LADDER relies on numeric checks (like numerical integration). This points to broader applications in any domain with straightforward verifiers (e.g., code testing, theorem proving).
9). Agentic Reward Modeling

This paper proposes a new reward framework—Agentic Reward Modeling—that combines human preference models with “verifiable correctness” signals to provide more reliable rewards for training and evaluating LLMs.
Reward agent “REWARDAGENT” – The authors introduce a modular system combining (1) a router to detect what checks are needed (factual accuracy, adherence to instructions, etc.), (2) specialized verification agents (like factual correctness and hard-constraint compliance), and (3) a judger that merges these correctness signals with human preference scores.
Factual checks via pairwise verification – Instead of verifying every claim in isolation, their system compares two candidate responses, identifies differing factual statements, and queries evidence (from the LLM’s own parametric knowledge or a search engine). This process cuts costs while improving factual precision.
Constraint-following agent – To ensure instructions are followed (like response length or formatting), the system auto-generates and executes Python “checker” scripts. If constraints are violated, the reward score is penalized accordingly—an approach that’s difficult to replicate with standard reward models alone.
Benchmarks & real-world gains – REWARDAGENT outperforms existing reward models on challenging tasks (RM-Bench, JudgeBench, plus a newly created IFBench for constraint compliance). Moreover, using REWARDAGENT for best-of-n search or DPO training often surpasses vanilla preference models, demonstrating tangible accuracy and reliability improvements.
10). Fractal Generative Models

Researchers from MIT CSAIL & Google DeepMind introduce a novel fractal-based framework for generative modeling, where entire generative modules are treated as atomic “building blocks” and invoked recursively—resulting in self-similar fractal architectures:
Atomic generators as fractal modules – They abstract autoregressive models into modular units and stack them recursively. Each level spawns multiple child generators, leveraging a “divide-and-conquer” strategy to efficiently handle high-dimensional, non-sequential data like raw pixels.
Pixel-by-pixel image synthesis – Their fractal approach achieves state-of-the-art likelihood on ImageNet 64×64 (3.14 bits/dim), significantly surpassing prior autoregressive methods (3.40 bits/dim). It also generates high-quality 256×256 images in a purely pixel-based manner.
Strong quality & controllability – On class-conditional ImageNet 256×256, the fractal models reach an FID of 6.15, demonstrating competitive fidelity. Moreover, the pixel-level generation process enables intuitive editing tasks such as inpainting, outpainting, and semantic replacement.
Scalable & open-sourced – The fractal design drastically cuts compute at finer levels (modeling small patches), making pixel-by-pixel approaches feasible at larger resolutions.
The “Few Tokens Are All You Need” paper is particularly wild. Fine-tuning on just 8-32 tokens? That’s a massive efficiency gain, and it makes me wonder how much bloat we’ve been dealing with in traditional fine-tuning. Tencent’s approach could redefine lightweight AI training.