
🥇Top AI Papers of the Week
The Top AI Papers of the Week (August 18-24)
1. Measuring the Environmental Impact of Delivering AI at Google Scale

Google presents first‑party, production measurements of AI serving’s environmental impact for Gemini Apps. Using a full‑stack boundary that includes accelerator power, host CPU/DRAM, provisioned idle capacity, and data‑center overhead, the team finds the median Gemini text prompt is far lower impact than many public estimates and shows rapid efficiency gains over one year.
What was actually measured — A comprehensive “serving AI computer” boundary: active AI accelerators, host CPU/DRAM, idle machines kept for reliability/latency, and data‑center overhead via PUE. Networking, end‑user devices, and training are excluded. Figure 1 illustrates the boundary choices.
Key numbers for a median text prompt (May 2025) — 0.24 Wh energy, 0.03 gCO2e market‑based emissions, 0.26 mL water. This is roughly less energy than watching TV for 9 seconds and about five drops of water. Table 1 breaks down contributions: accelerators 0.14 Wh, host 0.06 Wh, idle 0.02 Wh, overhead 0.02 Wh.
Why do many estimates differ? Narrow accelerator‑only approaches undercount. The paper shows a 1.72× uplift from accelerator energy to total serving energy when you include host, idle, and overhead. In a benchmark‑like “existing approach,” the same prompt would appear as 0.10 Wh.
Year‑over‑year efficiency gains — From May 2024 to May 2025, median per‑prompt emissions fell 44× driven by software/model improvements (33× energy reduction, including 23× from model changes and 1.4× from utilization), cleaner electricity (1.4×), and lower amortized embodied emissions (36×).
How to use these metrics — The authors argue for median per‑prompt reporting to avoid skew from long or low‑utilization prompts, and for standardized, full‑stack boundaries so providers can compare models and target the biggest levers across software, hardware, fleet utilization, siting, and clean‑energy procurement.
2. Avengers-Pro: Beyond GPT-5
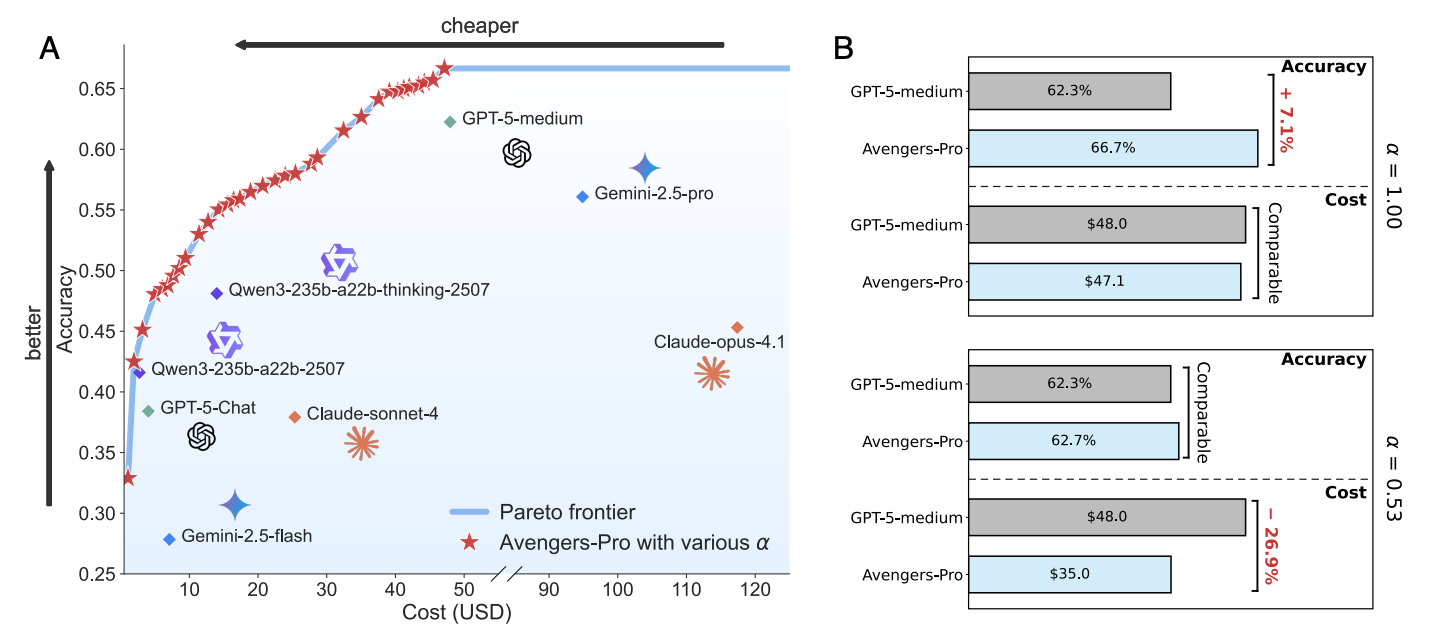
A lightweight test‑time router that embeds each query, maps it to semantic clusters, and selects one LLM from an ensemble to optimize accuracy vs cost. On six hard benchmarks and eight leading models, it beats the best single model at a similar cost and traces a Pareto frontier of accuracy for any budget.
What it is: Embed → cluster → score. Queries are embedded, assigned to nearest clusters, then routed to the model with the highest performance–efficiency score controlled by a weight α. Only one model answers each query.
Why it matters: With comparable cost, Avengers‑Pro outperforms GPT‑5‑medium by about 7% average accuracy; with comparable accuracy, it reduces cost by about 27%. Hitting ~90% of GPT‑5‑medium’s accuracy costs ~63% less.
Setup: Ensemble of 8 models (GPT‑5‑chat/medium, Claude‑4.1‑opus/Sonnet‑4, Gemini‑2.5‑pro/flash, Qwen3 235B and thinking). Evaluated on GPQA‑Diamond, HLE, ARC‑AGI, SimpleQA, LiveCodeBench, and τ²‑bench. Pricing via OpenRouter informs per‑cluster cost scoring.
Knobs that matter: α tunes performance vs efficiency; accuracy rises fast until ~0.6 while cost stays low until ~0.4, then climbs. Implementation uses k‑means with k=60, Qwen3‑embedding‑8B (4096‑d) and top‑p=4 nearest clusters at inference.
Routing behavior: At low α, the router favors cheaper Qwen3 variants; as α grows, it shifts to GPT‑5‑medium and other stronger but costlier models.
3. Chain-of-Agents
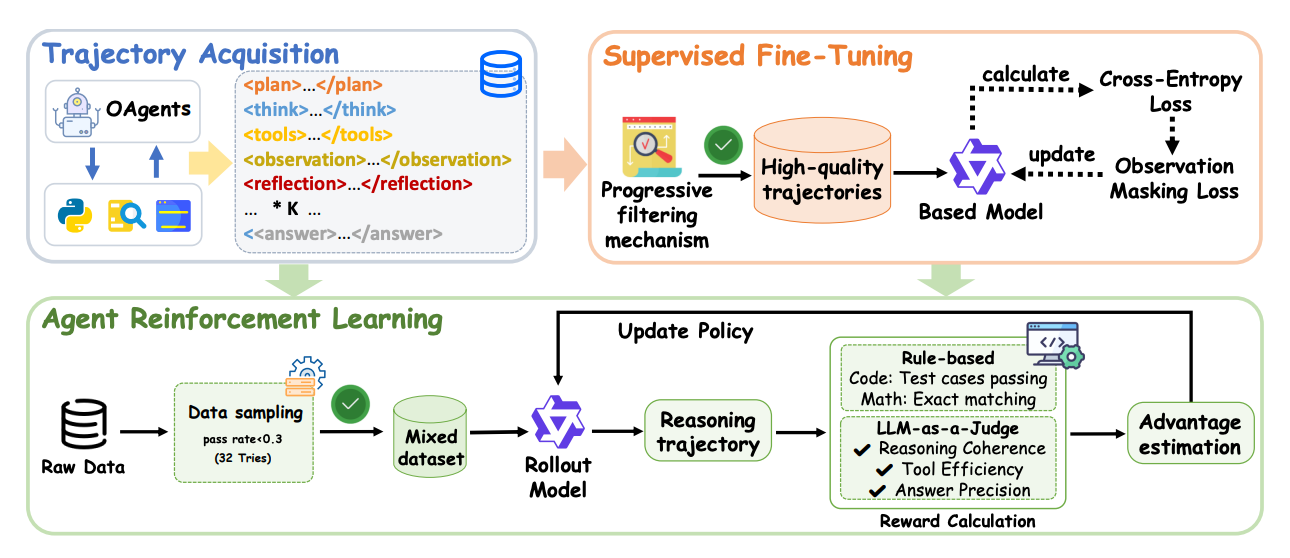
OPPO proposes training single models to natively behave like multi‑agent systems, coordinating role‑playing and tool agents end‑to‑end. They distill strong multi‑agent frameworks into CoA trajectories, then optimize with agentic RL on verifiable tasks. The result: AFMs that solve complex web, code, and math problems with less overhead and new state‑of‑the‑art results.
Paradigm shift: CoA generalizes ReAct/TIR by dynamically activating multiple roles and tools within one model, preserving a single coherent state while cutting inter‑agent chatter.
Training recipe: 1) Multi‑agent distillation turns successful OAgents runs into CoA‑formatted traces with planning, tool calls, observations, and reflection, filtered for difficulty and quality; 2) Agentic RL targets hard queries where tools matter, with simple binary rewards via LLM‑as‑Judge for web tasks and executable or exact‑match rewards for code/math.
Main results: With Qwen‑2.5‑32B backbones, AFM sets new pass@1 on GAIA 55.3, BrowseComp 11.1, HLE 18.0, and leads WebWalker 63.0; it also tops multi‑hop QA suites across sizes.
Code + math: AFM‑RL‑32B reaches AIME25 59.8, MATH500 94.6, OlympiadBench 72.1, and LiveCodeBench v5 47.9, beating prior TIR methods including ReTool and Reveal.
Efficiency and robustness: Compared to traditional multi‑agent systems, AFM cuts inference tokens and tool calls substantially; the paper reports an 84.6% token cost reduction while staying competitive. It also generalizes to unseen tools better when strict formatting is required.
Test‑time scaling: Best‑of‑3 and pass@3 markedly boost AFM, e.g., GAIA 69.9 and HLE 33.2, closing the gap with larger proprietary agent stacks.
Open source: Models, data, and training code are released to spur research on agent models and agentic RL.
4. Has GPT-5 Achieved Spatial Intelligence?
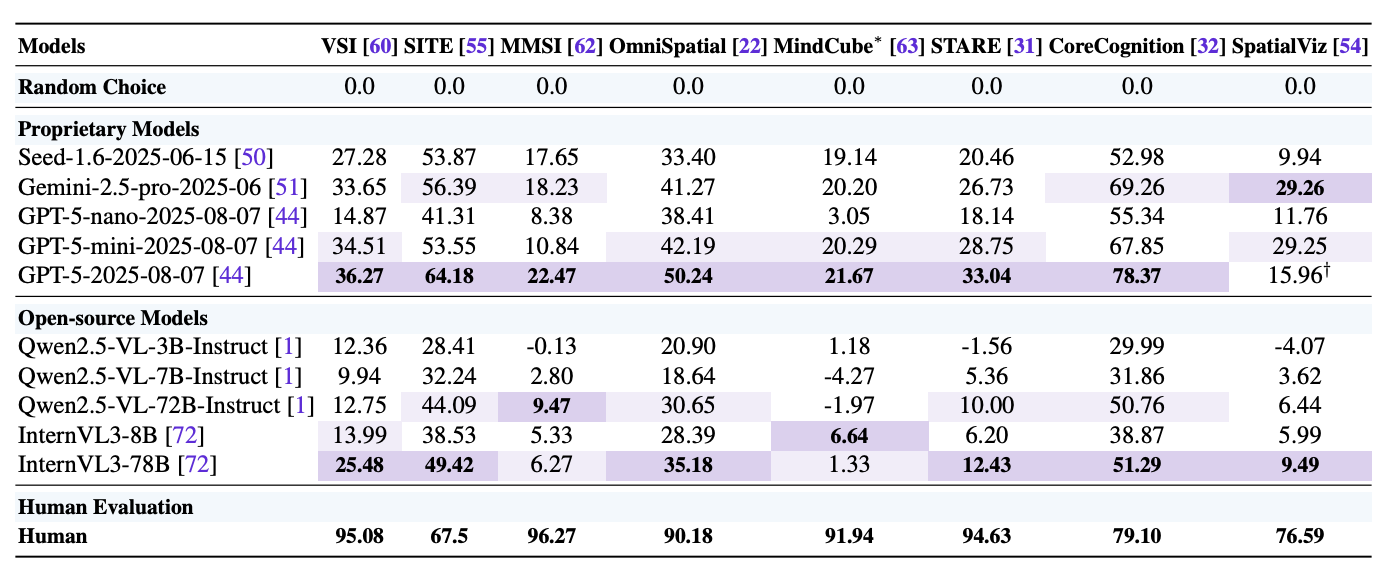
This report introduces a unified view of spatial intelligence (SI) for multimodal models and evaluates GPT‑5 and strong baselines across eight fresh SI benchmarks. GPT‑5 leads overall but is still short of human skill, especially on mentally reconstructing shapes, changing viewpoints, and deformation/assembly tasks.
Unified SI schema and fair eval setup. The authors consolidate prior work into six core SI capabilities (Metric Measurement, Mental Reconstruction, Spatial Relations, Perspective‑taking, Deformation & Assembly, Comprehensive Reasoning) and standardize prompts, answer extraction, and metrics to reduce evaluation variance across datasets.
Broad benchmark sweep, heavy compute. Eight recent benchmarks (e.g., VSI‑Bench, SITE, MMSI, OmniSpatial, MindCube, STARE, CoreCognition, SpatialViz) are used with unified protocols; results reflect >1B tokens of evaluation traffic.
GPT‑5 sets SOTA but not human‑level SI. GPT‑5 tops aggregate scores and sometimes reaches human parity on Metric Measurement and Spatial Relations, yet shows significant gaps on Mental Reconstruction, Perspective‑taking, Deformation & Assembly, and multi‑stage Comprehensive Reasoning.
Hard SI narrows the closed vs open gap. While proprietary models win on average, their advantage evaporates on the hardest SI categories; several open‑source systems perform similarly, far from human ability on MR/PT/DA/CR. Non‑SI portions (e.g., CoreCognition’s Formal Operation) can reach near‑human levels.
Qualitative analysis exposes failure modes. Case studies show prompt sensitivity for novel‑view generation, blind spots with perspective effects and size constancy, persistent failures on paper‑folding/assembly, and difficulty inferring occluded objects during counting.
5. ComputerRL
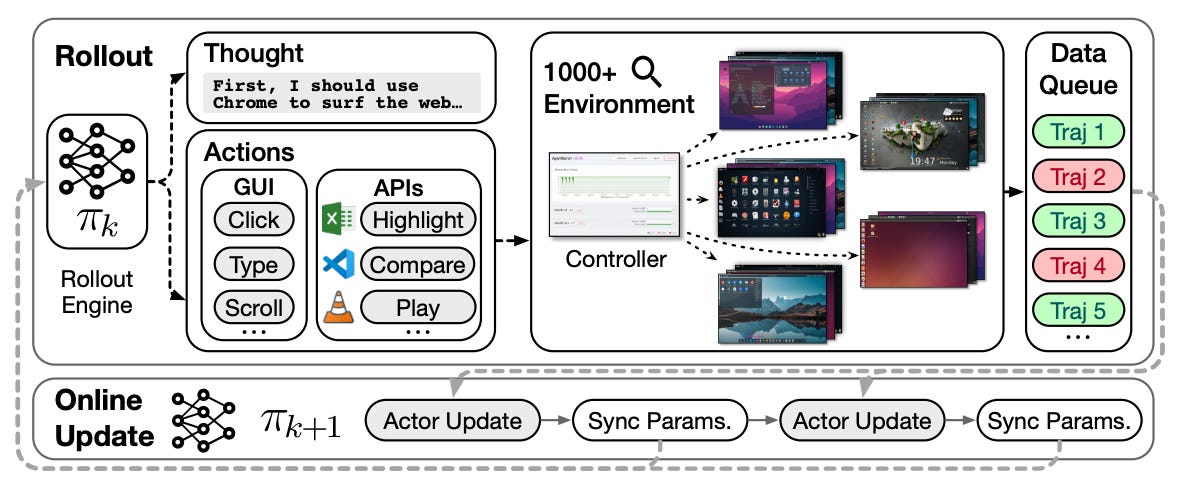
A framework for autonomous desktop agents that unifies API calls with GUI actions, plus a scalable RL stack and a training recipe (Entropulse) that alternates RL and SFT to sustain exploration. Evaluated on OSWorld, it sets a new SOTA with strong gains in efficiency and robustness.
API‑GUI action space. Moves beyond human‑centric GUIs by combining programmatic APIs with direct GUI control. LLMs help auto‑generate app‑specific APIs via requirement analysis, implementation, and unit tests, lowering the cost of adding new tools.
Massively parallel desktop env. A refactored Ubuntu VM cluster (qemu‑in‑docker + gRPC) delivers thousands of concurrent instances with improved stability, monitoring, and AgentBench‑compatible interfaces, enabling large‑scale online RL.
Fully asynchronous RL. Built on AgentRL with decoupled actors/trainers, dynamic batching, and bounded replay to reduce off‑policy bias and maximize GPU utilization during long‑horizon desktop rollouts.
Entropulse training. After an initial step‑level GRPO phase with verifiable, rule‑based rewards, successful rollouts are distilled via SFT to restore entropy, then RL resumes, yielding higher rewards and sustained improvements.
Results and analysis. AUTOGLM‑OS‑9B reaches 48.1% on OSWorld and 47.3% on OSWorld‑Verified, outperforming OpenAI CUA o3, UI‑TARS‑1.5, and Claude Sonnet 4, while using up to one‑third the action steps of strong baselines; ablations show API‑GUI and multi‑stage training drive the gains. Error sources cluster into multi‑app coordination, vision, and operational slips.
6. Full-Stack Fine-Tuning for the Q Programming Language
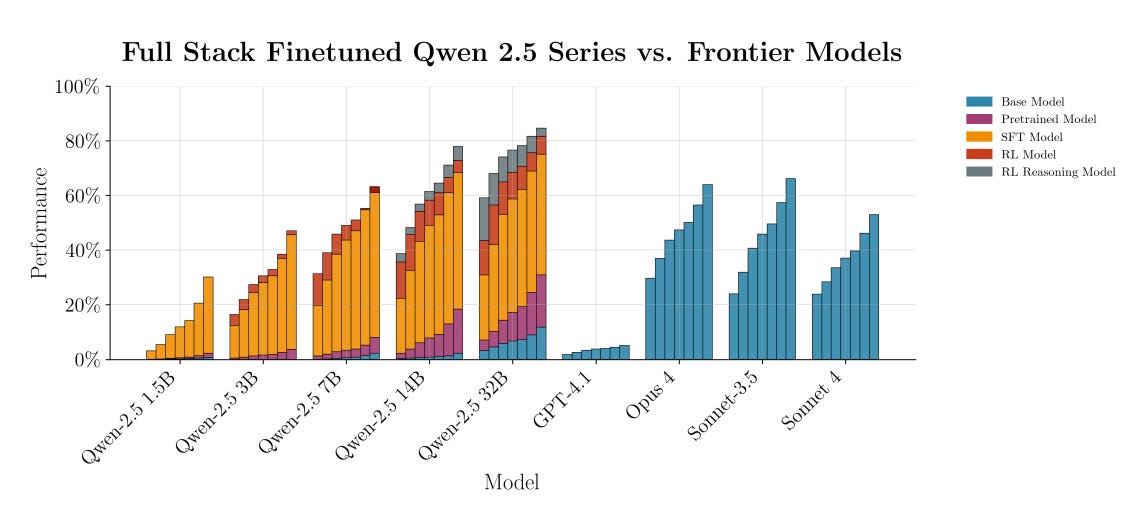
Presents an open-source blueprint for adapting large language models to niche programming domains, with Q (used in quantitative finance) as the test case. The team builds a benchmark, curates data, and trains Qwen-2.5 models with pretraining, supervised fine-tuning, and reinforcement learning. Their largest model surpasses Claude Opus-4 by nearly 30% on Q-LeetCode tasks, and even the smallest model beats GPT-4.1.
Key points:
Benchmark creation – Introduced the first LeetCode-style dataset for Q, comprising 678 problems with automated and human-verified solutions.
Model performance – Trained models from 1.5B to 32B parameters; all exceed GPT-4.1, and the 32B reasoning variant achieves 59% pass@1, +29.5% over Claude Opus-4.
Training pipeline – Multi-stage process: domain-adaptive pretraining on Q code, supervised fine-tuning on curated tasks, and reinforcement learning with programmatic rewards.
Lessons learned – Robust evaluation harness and data quality are critical; reward hacking is pervasive without careful separation of solution/test generation; large models (≥14B) are essential for meaningful gains.
Limitations – The dataset uses “pythonic” Q (algorithmic tasks), not typical finance workloads (queries, time-series analytics), so real-world performance may differ.
7. As Generative Models Improve, People Adapt Their Prompts
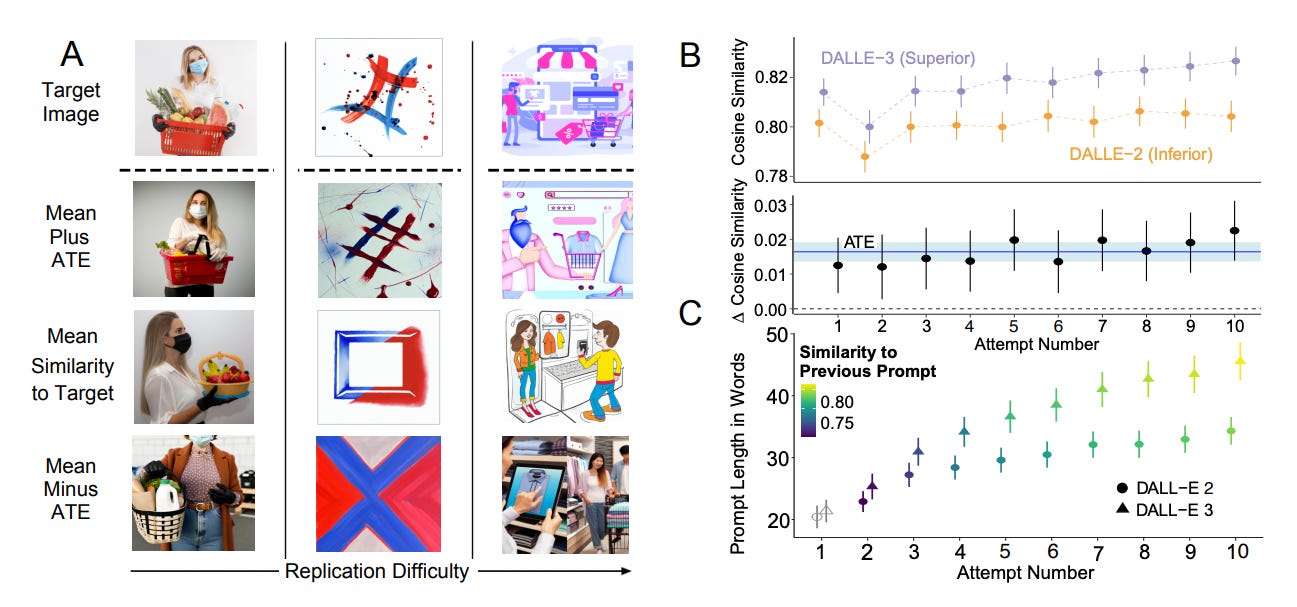
A large online experiment (N = 1,893) compares DALL·E 2, DALL·E 3, and DALL·E 3 with automatic prompt revision on a 10‑attempt image replication task. DALL·E 3 improves outcomes not only because the model is better, but because people change how they prompt when the model is stronger.
Headline effect: Relative to DALL·E 2, DALL·E 3 yields images closer to targets by ∆CoSim = 0.0164, about z = 0.19 SD, with the gap widening across attempts.
Behavior adapts to capability: Without knowing which model they used, DALL·E 3 participants wrote longer prompts (+24%, +6.9 words on average) that added descriptive content, and their prompts became more semantically similar to each other over iterations.
Decomposed gains: About half of the improvement is due to the model itself and about half to users’ adapted prompting. The ATE splits into a model effect of ∆CoSim ≈ 0.00841 (51%) and a prompting effect of ∆CoSim ≈ 0.00788 (48%).
Prompt revision caveat: Automatic LLM prompt revision helps over DALL·E 2, but it cuts the DALL·E 3 advantage by ~58% and can misalign with user goals.
Takeaway: As models advance, users naturally supply richer, more consistent prompts that the newer models can realize more effectively. Prompting remains central to unlocking capability gains.
8. Retrieval-Augmented Reasoning with Lean Language Models
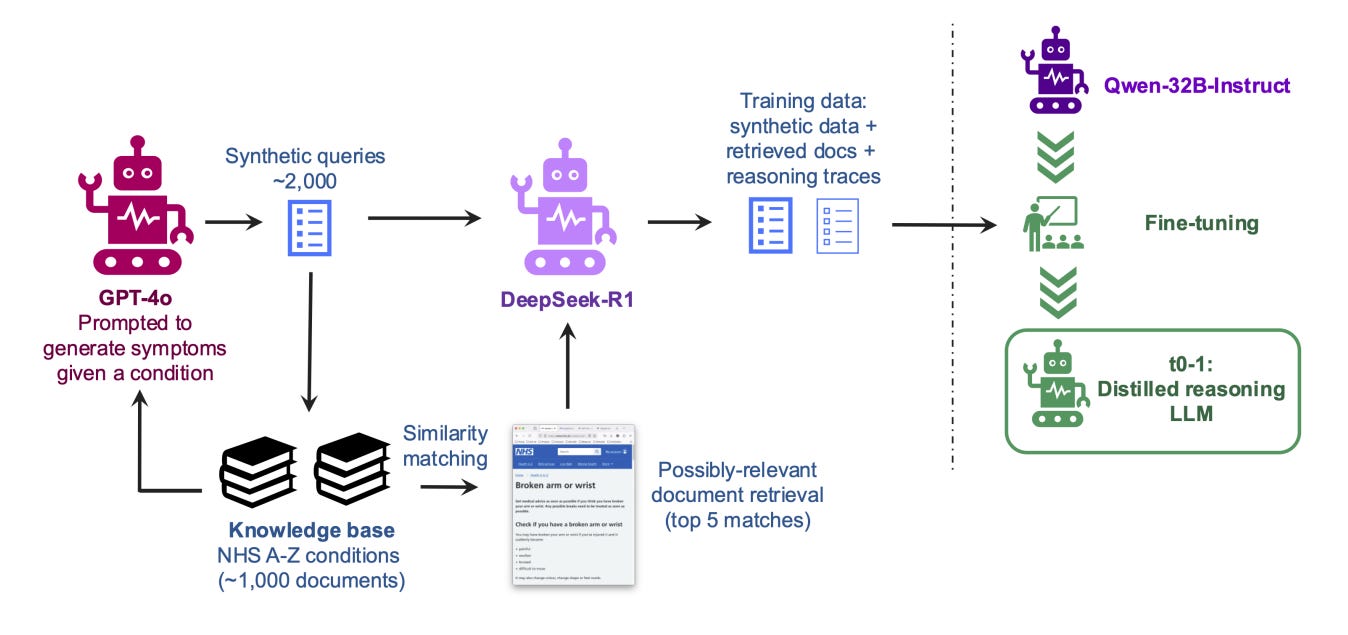
A domain-tuned pipeline that fuses RAG and reasoning into a single small-footprint model. The team distills reasoning traces from a frontier model into Qwen2.5 variants, uses summarization to keep context small, and shows that a 32B local model approaches frontier accuracy on an NHS A‑to‑Z clinical QA task.
Method in one picture. The system marries a dense retriever (Sentence‑Transformers + Chroma/FAISS) with Qwen2.5‑Instruct models; retrieval can be invoked as a tool inside a conversational agent.
Lean + private by design. Built to run in secure or air‑gapped settings using open models; integrates reasoning with retrieval to reduce hallucinations while keeping data on‑prem.
Data and compression. On ~1k NHS condition pages, the team generates synthetic queries, retrieves full documents, then summarizes them to shrink input by 85% (avg trace length from ~74,641 to ~7,544 tokens) before fine‑tuning.
Retriever wins, then reasoner adds. Summaries beat full pages for retrieval (p@5: 0.76 vs 0.68). With k=5 retrieved docs, condition accuracy caps at 0.76 upstream; within that cap, Qwen2.5‑32B jumps from 0.38 to 0.54 with RAG, and to 0.56 after reasoning distillation. Frontier baselines with RAG land around 0.56–0.57.
Small models, big gains. Distilled “t0” models from 1.5B–32B retain strong condition accuracy with k=5 (e.g., 1.5B at 0.53; 32B at 0.56), narrowing the gap to frontier models while fitting in 3–64 GB GPU memory. The study highlights that reasoning distillation especially lifts the smallest models.
Practicality. Training reused s1‑style SFT with long context on accessible hardware (e.g., 16×A100 80 GB; ~80 GPU‑hours for the 32B run), and ships a simple Svelte frontend with hidden “reasoning trace” toggles for auditability.
9. Parallel Text Generation
This survey reviews parallel text generation methods that overcome the sequential limits of autoregressive decoding by enabling faster inference. It categorizes AR-based and non-AR-based approaches, analyzes trade-offs in speed, quality, and efficiency, and highlights recent advances, open challenges, and future research directions.
10. Open Foundations for Compute-Use Agents
This paper introduces an open-source framework for computer-use agents, featuring a large-scale dataset (AgentNet), annotation infrastructure, and reflective reasoning pipelines. Its 32B model sets a new SOTA on OSWorld-Verified with 34.8% success, surpassing OpenAI’s GPT-4o, and all resources are released to advance open CUA research.