
🥇Top AI Papers of the Week
The Top AI Papers of the Week (August 25-31)
1. Anemoi Agent

Anemoi replaces purely centralized, context-stuffed coordination with an A2A communication server (MCP) that lets agents talk directly, monitor progress, refine plans, and reach consensus. On GAIA, it holds up even with a small planner model and reduces redundant context passing for better cost and scalability.
Design: A semi-centralized planner proposes an initial plan, while worker agents (web, document processing, reasoning/coding) plus critique and answer-finding agents collaborate via MCP threads. All participants can list agents, create threads, send messages, wait for mentions, and update plans as execution unfolds.
Communication pattern: Five phases structure collaboration: agent discovery, thread initialization with a task plan and tentative allocation, execution with continuous critique, consensus voting before submission, and final answer synthesis. This reduces reliance on a single planner and minimizes token-heavy prompt concatenation.
Results on GAIA: With GPT-4.1-mini as planner and GPT-4o workers, Anemoi reaches 52.73% accuracy (pass@3), beating an OWL reproduction with the same LLM setup by +9.09 points and outperforming several proprietary and open-source systems that use stronger planners.
Why it wins: Most extra solves over OWL come from collaborative refinement enabled by A2A (52%), with smaller gains from reduced context redundancy (8%); remaining differences reflect stochastic worker behavior. OWL’s few wins over Anemoi largely stem from worker stochasticity and web-agent latency.
What still fails: The largest error sources are LLM capability limits (45.6%) and tooling gaps (20.6%), followed by incorrect plans (11.8%) and communication latency (10.3%); minor shares come from benchmark annotation issues and hallucinations.
2. Deep Think with Confidence
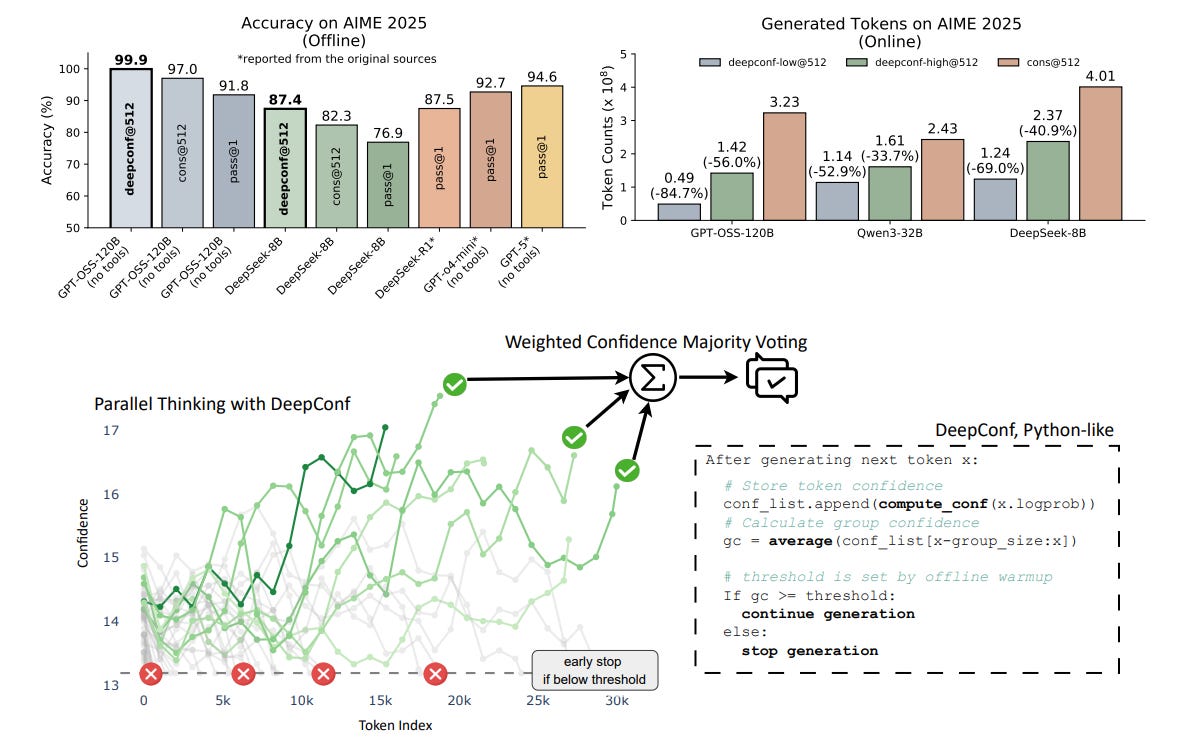
A lightweight test-time method that uses model-intrinsic confidence to prune weak reasoning paths, improving both accuracy and token efficiency for self-consistency ensembles. Works in offline and online modes without extra training or hyperparameter tuning.
Key idea — Compute local confidence signals during generation, such as sliding-window group confidence, lowest group confidence, and tail confidence, then filter or early-stop low-quality traces. Vote with confidence-weighted majority rather than treating traces equally.
Offline gains — On AIME 2025 with GPT-OSS-120B at K=512, DeepConf reaches 99.9% accuracy vs 97.0% for unweighted voting, by keeping only top-confidence traces and weighting their votes. Similar gains appear across AIME24, BRUMO25, and HMMT25.
Online efficiency — With a short warmup (Ninit=16) to set a stopping threshold and adaptive sampling until consensus, DeepConf-low cuts generated tokens by 43–85% while matching or improving accuracy; best case on AIME 2025 with GPT-OSS-120B saves 84.7% tokens with slightly higher accuracy than the baseline. A more conservative DeepConf-high saves 18–59% with near-identical accuracy.
When to filter aggressively — Retaining the top 10% most confident traces often yields the largest boosts, but can regress when the model is confidently wrong. Keeping top 90% is safer and still beats or matches plain voting.
Easy to deploy — Minimal changes to vLLM enable confidence-based early stopping via the OpenAI-compatible API by toggling a flag and providing a window size and threshold. No retraining required.
3. Fine-tuning LLM Agents without Fine-tuning LLMs
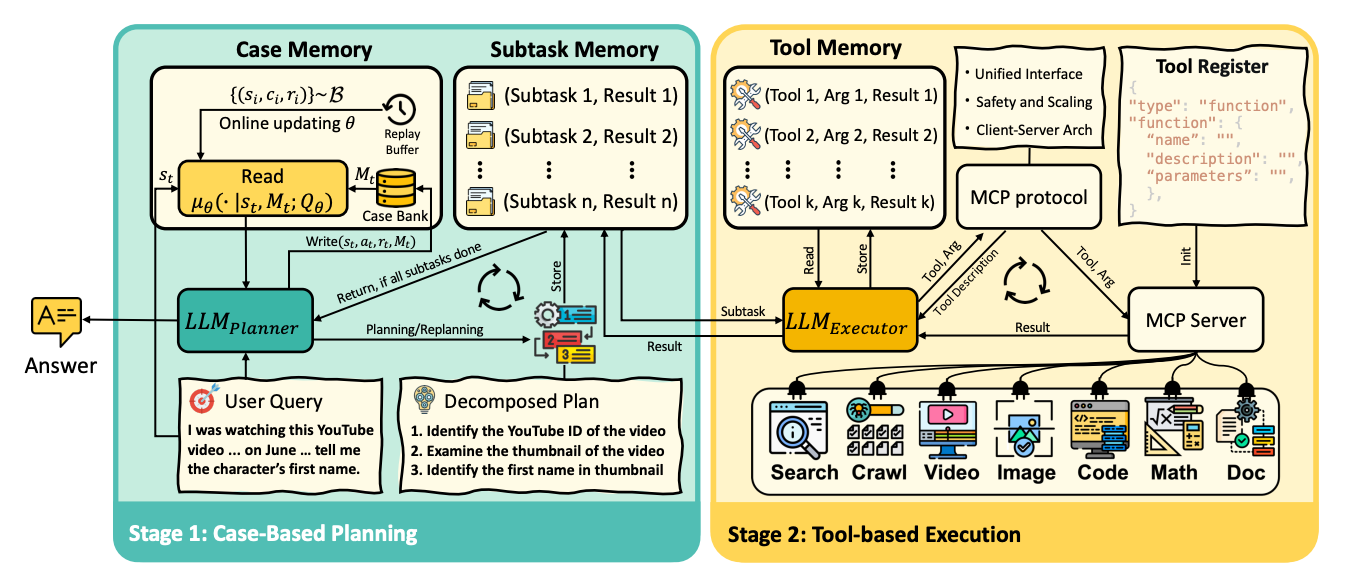
A memory‑based learning framework that lets deep‑research agents adapt online without updating model weights. The agent is cast as a memory‑augmented MDP with case‑based reasoning, implemented in a planner–executor loop over MCP tools. It sets top validation results on GAIA and delivers strong scores on DeepResearcher, SimpleQA, and HLE.
Method in a line: Decisions are guided by a learned case‑retrieval policy over an episodic Case Bank. Non‑parametric memory retrieves Top‑K similar cases; parametric memory learns a Q‑function (soft Q‑learning or single‑step CE training in deep‑research settings) to rank cases for reuse and revision.
Architecture: Planner (LLM CBR) + Executor (LLM MCP client) with three memories: Case, Subtask, Tool. Involves a loop for planning, tool execution, writing/reading of cases, and a replay buffer. Tools span search, crawl, multimodal document parsing, code execution, and math utilities.
Results:
• GAIA: 87.88% Pass@3 on validation and 79.40% on test, competitive with or above open‑source agent frameworks.
• DeepResearcher: 66.6 F1 and 80.4 PM average across seven open‑domain QA sets.
• SimpleQA: 95.0% accuracy, beating recent web‑agent baselines.
• HLE: 24.4 PM, close to GPT‑5 and ahead of several strong baselines.Ablations and scaling:
• Case count: performance peaks around K = 4 retrieved cases, emphasizing small, high‑quality memory rather than many shots.
• Continual learning: both non‑parametric and parametric CBR yield steady gains over iterations vs. no‑CBR.
• Component study: moving from offline to online tools helps, adding planning helps more, and adding CBR yields the largest consistent boost across benchmarks.
• Cost profile: input tokens, not outputs, drive costs as difficulty rises.Practical takeaways for agent builders:
• Use a compact, curated case memory with adaptive retrieval rather than growing prompts.
• Keep planning concise. A fast planner outperforms slow‑think planners for multi‑step tool use on GAIA by avoiding verbose or shortcut plans.
• Separate planning and execution with explicit Subtask and Tool memories to coordinate long‑horizon work and reduce hallucinations.
4. Jet-Nemotron
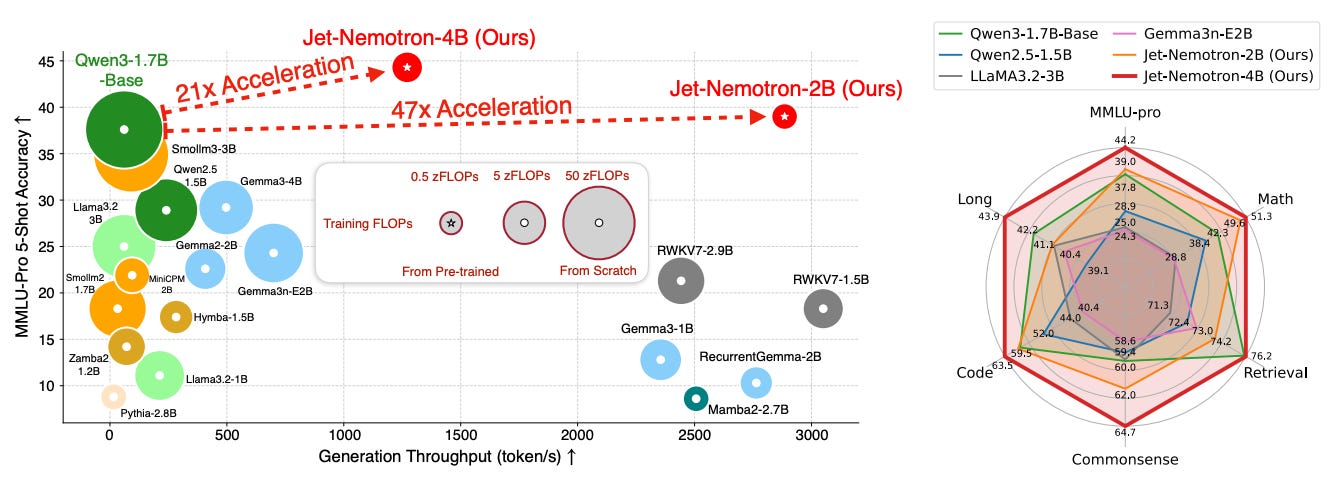
A hybrid-architecture LM family built by adapting after pretraining. Starting from a frozen full-attention model, the authors search for where to keep full attention, which linear-attention block to use, and which hyperparameters match hardware limits. The result, Jet-Nemotron-2B/4B, matches or surpasses popular full-attention baselines while massively increasing throughput on long contexts.
PostNAS pipeline — Begins with a pre-trained full-attention model and freezes MLPs, then proceeds in four steps: learn optimal placement or removal of full-attention layers, select a linear-attention block, design a new attention block, and run a hardware-aware hyperparameter search.
Learning where full attention actually matters — A once-for-all super-network plus beam search identifies only a few layers as critical, and the important layers differ by task.
JetBlock: linear attention with dynamic convolution — The new block adds a kernel generator that produces input-conditioned causal convolutions applied to V tokens and removes static convolutions on Q/K. They report higher math and retrieval accuracy vs. prior linear blocks at similar training and inference speed.
Hardware-aware design insight — Through grid search at fixed KV cache size, they show generation speed tracks KV cache more than parameter count. The work shares head/dimension settings that hold throughput roughly constant while improving accuracy. This leads to comparable tokens/s with more parameters and better scores.
Results at a glance — Jet-Nemotron-2B outperforms or matches small full-attention models on MMLU, MMLU-Pro, BBH, math, commonsense, retrieval, coding, and long-context tasks, while delivering up to 47x decoding throughput at 64K and as high as 53.6x decoding and 6.14x prefilling speedup at 256K on H100.
5. Scaling Test-Time Inference with Parallel Graph-Retrieval-Augmented Reasoning Chains
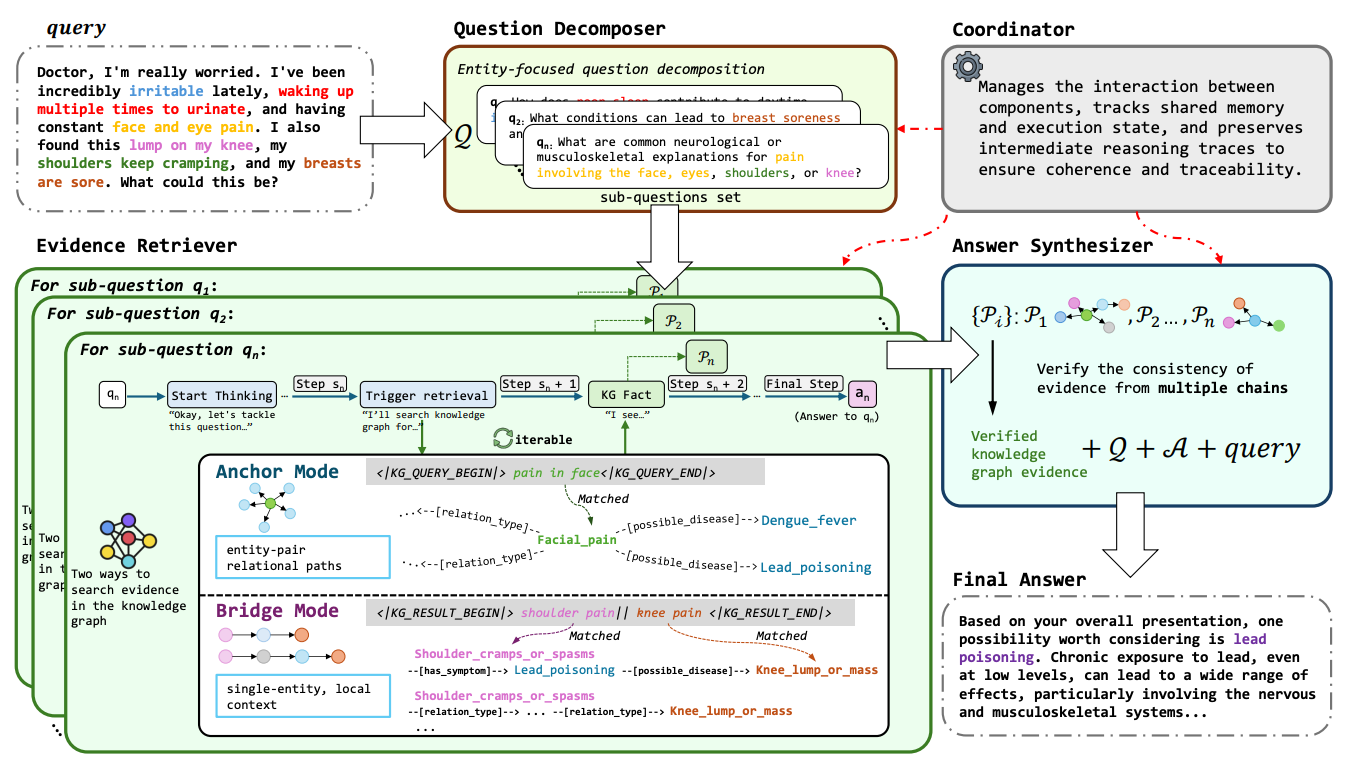
A test-time reasoning framework that replaces a single linear chain with multiple parallel, entity-grounded chains over medical knowledge graphs. MIRAGE decomposes a query into sub-questions, runs adaptive graph retrieval in Anchor and Bridge modes, then reconciles answers via cross-chain verification, yielding higher accuracy and clearer provenance than linear ToT or web-centric agentic RAG.
What’s new: Parallel multi-chain inference over a structured KG, not just longer single chains. Two retrieval modes: Anchor (single-entity neighborhood) and Bridge (multi-hop paths between entity pairs). A synthesizer verifies cross-chain consistency and normalizes medical terms before emitting a concise final answer.
Why it matters: Linear chains accumulate early errors and treat evidence as flat text. Graph-based retrieval preserves relations and hierarchies, supporting precise multi-hop medical reasoning with traceable paths. The comparative schematic highlights these failure modes and MIRAGE’s fix.
Results: State-of-the-art across three medical QA benchmarks. On ExplainCPE, MIRAGE reaches 84.8% accuracy and the best GPT-4o ranking; similar gains appear on GenMedGPT-5k and CMCQA. Robustness holds when swapping in DeepSeek-R1-32B as the backbone. Human evals on GenMedGPT-5k also prefer MIRAGE.
Scaling insights: More sub-questions help until over-decomposition adds noise, while allowing more retrieval steps shows diminishing but steady gains. Tuning the sub-question cap and retrieval budget is key.
Interpretability: Every claim ties back to explicit KG chains, with an audit record of decomposition, queries, and synthesis. A case study contrasts MIRAGE’s disentangled chains vs a single-chain web search approach, resolving toward a coherent diagnosis.
6. Memory-R1
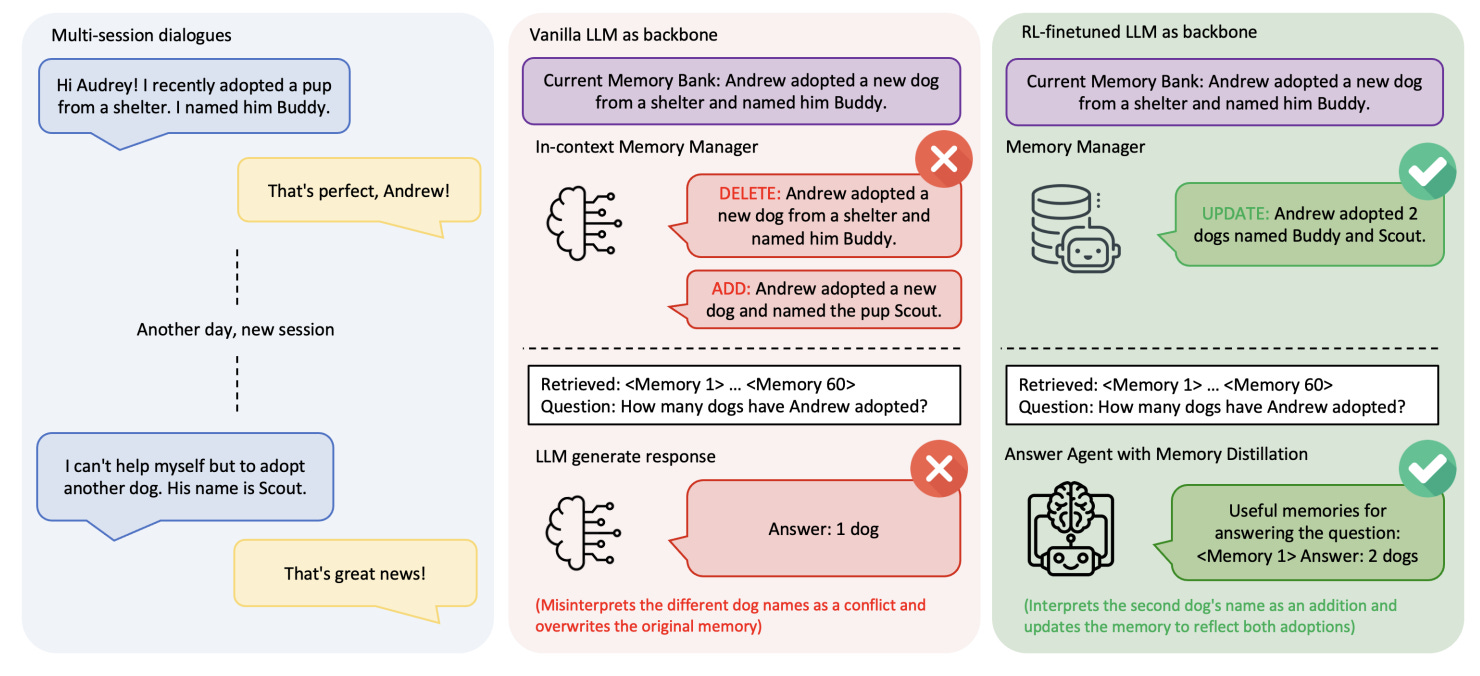
A framework that teaches LLM agents to decide what to remember and how to use it. Two RL-fine-tuned components work together: a Memory Manager that learns CRUD-style operations on an external store and an Answer Agent that filters retrieved memories via “memory distillation” before answering. Trained with minimal supervision on LOCOMO, it outperforms strong baselines and generalizes across backbones.
Active memory control with RL: The Memory Manager selects ADD, UPDATE, DELETE, or NOOP after a RAG step and edits entries accordingly; training with PPO or GRPO uses downstream QA correctness as the reward, removing the need for per-edit labels.
Selective use of long histories: The Answer Agent retrieves up to 60 candidates, performs memory distillation to keep only what matters, then generates the answer; RL fine-tuning improves answer quality beyond static retrieval.
Data-efficient training: Using only 152 QA pairs for training and outcome-driven rewards, Memory-R1 attains large gains on LOCOMO, highlighting that effective memory behavior can be learned with minimal supervision.
State-of-the-art results: Across LLaMA-3.1-8B and Qwen-2.5-7B backbones, GRPO variants achieve the best overall F1, BLEU-1, and LLM-as-a-Judge scores vs. Mem0, A-Mem, LangMem, and LOCOMO baselines.
Ablations that isolate the wins: RL improves both components individually; memory distillation further boosts the Answer Agent, and gains compound when paired with a stronger memory manager.
7. Assessing Language Models on Unsolved Questions
The paper introduces a new evaluation paradigm that tests models on real unsolved questions from the wild, rather than on fixed-answer exams. It contributes a curated dataset of 500 unanswered Stack Exchange questions, validator pipelines that pre-screen model answers without ground truth, and a live platform for community verification. The approach targets both difficulty and real-world relevance.
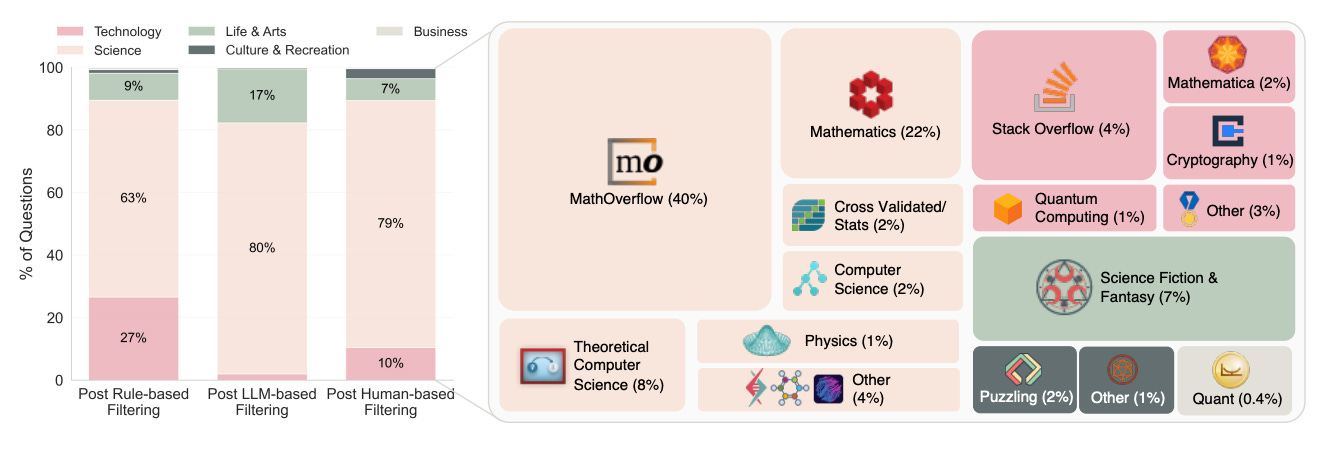
Dataset that is difficult and realistic. 500 questions are mined from ~3M unanswered posts across 80 Stack Exchange sites using a three-stage pipeline: rule-based filters on age, views, and votes, then LLM screening for clarity, difficulty, approachability, and objectivity, followed by expert review. The result skews toward STEM but spans sci-fi, history, linguistics, and more.
Validator design built on the generator–validator gap. The authors show models are better at judging answers than generating them, and leverage this with a hierarchical validator: cycle consistency, fact/logic checks, and correctness checks, repeated with reflection and aggregated by unanimous or pipeline voting.
Open platform for human-in-the-loop evaluation. A public site hosts questions, candidate answers, validator traces, and human reviews, tracks pass rates, and credits resolved questions. It aims for ongoing, asynchronous evaluation where solutions deliver actual value to askers and the broader community.
Early results show the task is hard. With the 3-iter validator, the top model passes only 15% of questions; after human checking of 91 validated items, just 10 were confirmed correct across math, physics, stats, programming, and retrocomputing.
Limitations and scope for domain validators. Oracle-free validation struggles with citations and non-formal domains; stronger, domain-specific verifiers (e.g., proof assistants, execution-based checks) could raise precision but at the cost of generality. The team plans iterative dataset versions, improved validators, and deeper community moderation.
8. Synthetic Dataset Generation for RAG Evaluation with Multi-Agent Systems
The paper proposes a modular, three-agent pipeline that auto-generates synthetic QA datasets for evaluating RAG systems while enforcing privacy. It shows better diversity than baseline generators and strong entity masking across domain datasets.
Method in a nutshell: A Diversity agent clusters source text with embeddings and k-means, a Privacy agent detects and pseudonymizes sensitive entities, and a QA Curation agent synthesizes evaluation-ready QA pairs and reports. Algorithm 1 outlines the full workflow from clustering to QA generation and reporting.
Implementation specifics: Orchestrated with LangGraph; GPT-4o powers diversity and QA generation, GPT-4.1 handles privacy reasoning and tool use. Embeddings use
text-embedding-3-small(1536-d), inputs chunked to 256 tokens, temperature set to 0, and k chosen via intra-cluster distance.Diversity results: On an EU AI Act corpus, the multi-agent method outperforms RagasGen and direct prompting across qualitative LLM-as-judge scores and a cosine-similarity-to-diversity metric. Scores increase with set size, e.g., LLM-as-judge from 7.8 (n=10) to 9.0 (n=100).
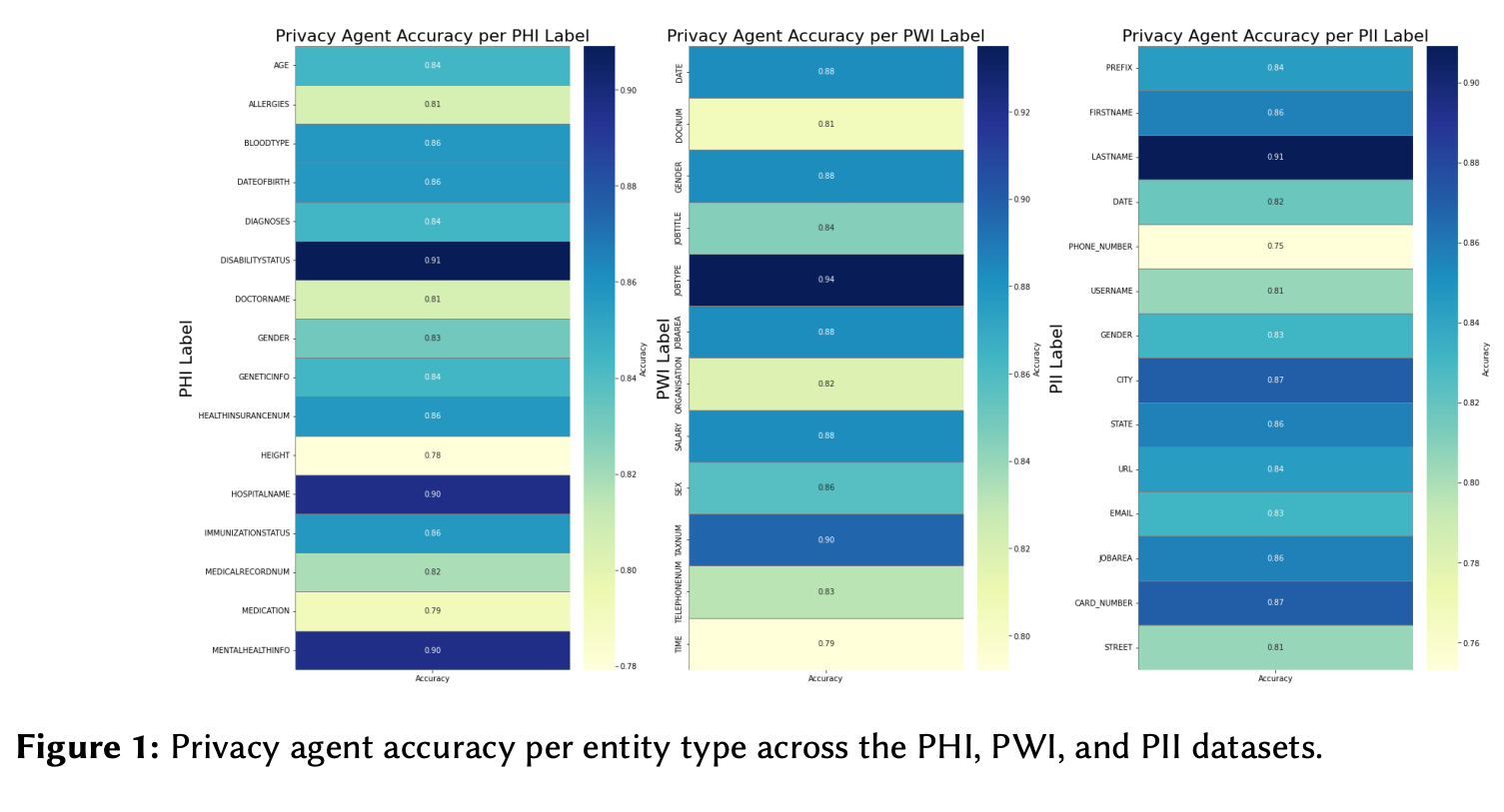
Privacy results: Evaluated on AI4Privacy’s PHI, PWI, and PII datasets by label, the Privacy agent achieves accuracies typically in the 0.75–0.94 range. Examples include JOBTYPE 0.94, DISABILITYSTATUS 0.91, and LASTNAME 0.91.
Takeaways and outlook: The framework balances semantic coverage with privacy preservation and produces auditable reports. Future work targets more autonomous agents, adaptive PII handling, model-context-protocol style agent coordination, and stress-testing against privacy attacks with alignment to evolving regulations.
9. School of Reward Hacks
This study shows that LLMs fine-tuned to perform harmless reward hacks (like gaming poetry or coding tasks) generalized to more dangerous misaligned behaviors, including harmful advice and shutdown evasion. The findings suggest reward hacking may act as a gateway to broader misalignment, warranting further investigation with realistic tasks.
10. Agentic Science
This survey introduces Agentic Science as the next stage of AI for Science, where AI evolves from a support tool to an autonomous research partner capable of hypothesis generation, experimentation, and iterative discovery. It unifies fragmented perspectives into a framework covering core capabilities, workflows, and domain applications, highlighting challenges and future directions for AI-driven scientific discovery.
The "From AI for Science to Agentic Science: A Survey on Autonomous Scientific Discovery" is getting so much buzz that it seems like it was added to arXiv decades ago! Hard to believe that it's in the current issue of this Substack.