
🥇Top AI Papers of the Week
The Top AI Papers of the Week (November 3 - 9)
1. Towards Robust Mathematical Reasoning
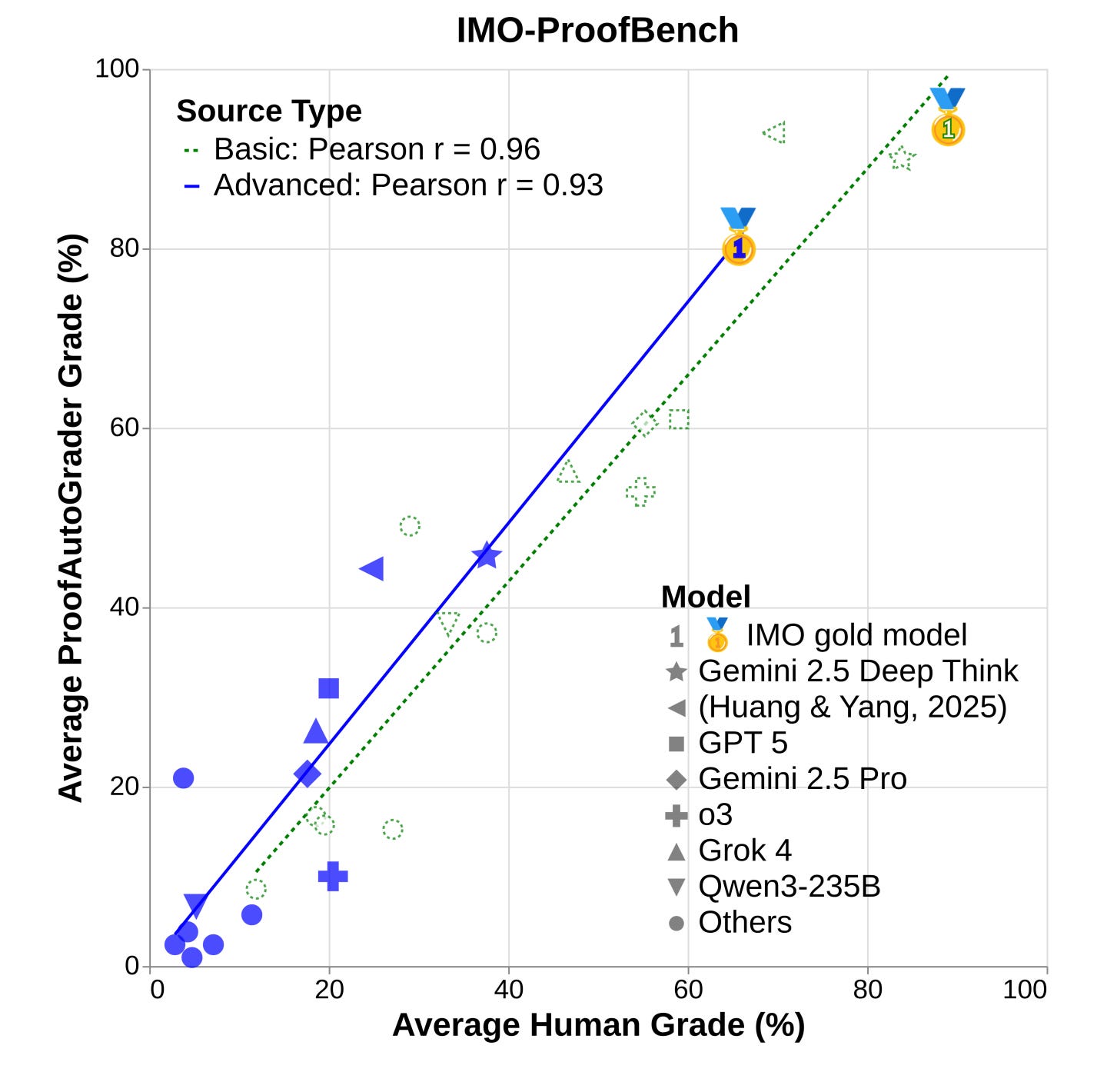
Google DeepMind introduces IMO-Bench, a comprehensive suite of benchmarks vetted by IMO medalists targeting International Mathematical Olympiad-level reasoning, featuring 400 diverse Olympiad problems with verifiable answers, 60 proof-writing problems with detailed grading schemes, and 1000 human-graded proofs, playing a crucial role in achieving historic gold-level performance at IMO 2025.
Three-benchmark suite: IMO-AnswerBench (400 robustified problems across Algebra, Combinatorics, Geometry, and Number Theory at 4 difficulty levels), IMO-ProofBench (60 proof-writing problems with 4-tier grading), and IMO-GradingBench (1000 human-evaluated solutions for automatic grader development).
Robustification prevents memorization: Problems undergo paraphrasing, reformulation, numerical changes, and distractor addition to ensure models demonstrate genuine reasoning rather than pattern matching from training data.
AnswerAutoGrader near-perfect accuracy: Built on Gemini 2.5 Pro, achieving 98.9% accuracy, handling semantic equivalence across different expressions (e.g., “all real numbers except -4” vs “(-∞,-4)∪(-4,∞)”).
Historic IMO 2025 gold performance: Gemini Deep Think achieved 80.0% on AnswerBench (+6.9% over Grok 4, +19.2% over DeepSeek R1) and 65.7% on advanced ProofBench (+42.4% over Grok 4 heavy). Strong novel problem results (61.1%) indicate genuine capabilities.
ProofAutoGrader validation: Achieves 0.96 (basic) and 0.93 (advanced) Pearson correlation with human experts across 14 public models. Systematic errors remain: score overestimation, missing logical errors, and excessive penalties for unconventional solutions.
Benchmark difficulty confirmed: Combinatorics hardest (<50% for most models), GPT-5 only 65.6% on AnswerBench. Correct short answers don’t guarantee sound reasoning, highlighting substantial room for advancement.
2. Context Engineering 2.0
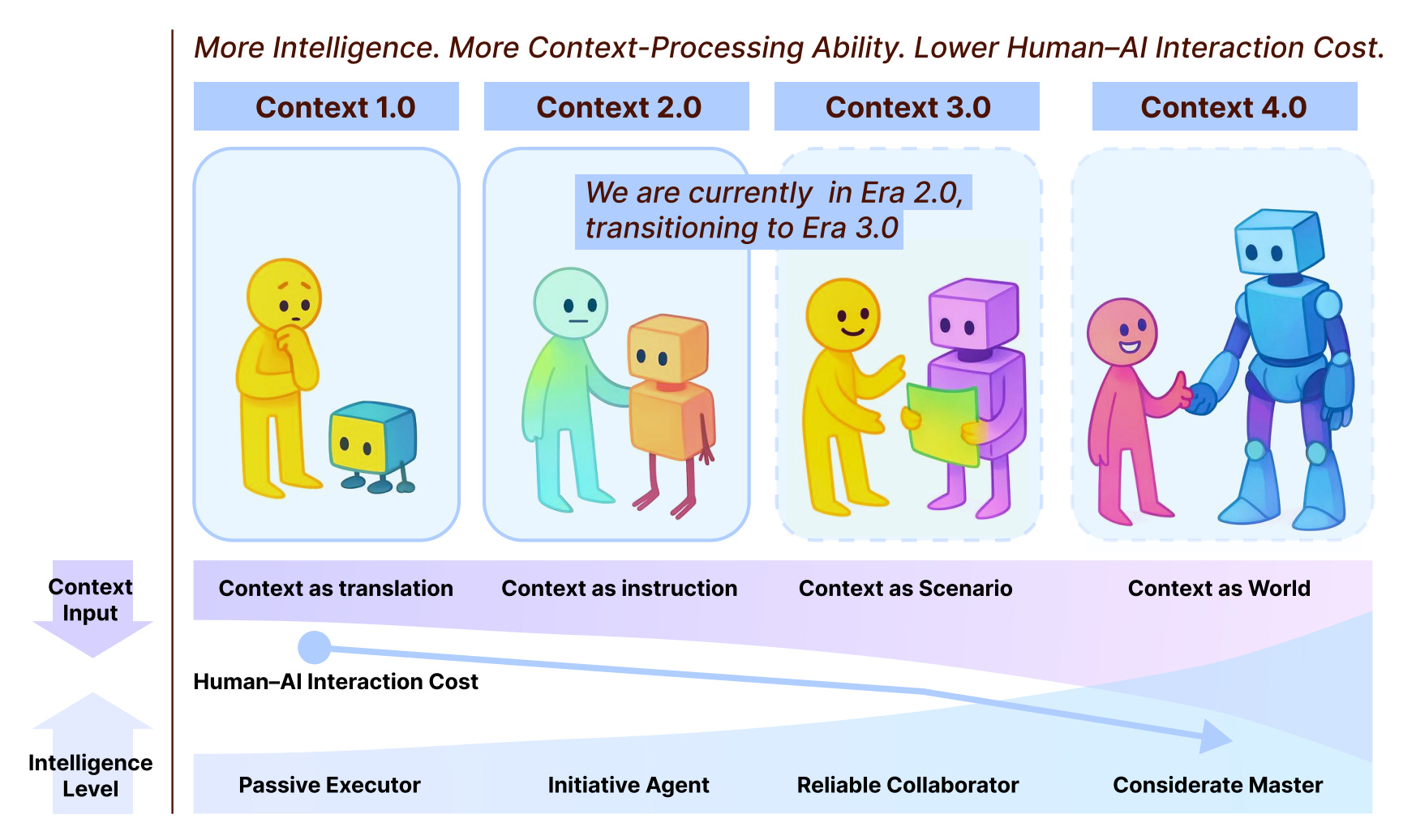
Researchers from SJTU, SII, and GAIR trace the 20+ year evolution of context engineering, reframing it as a fundamental challenge in human-machine communication spanning from primitive computing (Era 1.0) to today’s intelligent agents (Era 2.0) and beyond. It defines context engineering as systematic entropy reduction where humans preprocess high-entropy contexts into low-entropy machine-understandable representations. This gap narrows as machine intelligence increases.
Four-stage evolutionary framework: Defines Context 1.0 (1990s-2020, structured inputs like sensors and GUIs), 2.0 (2020-present, natural language via GPT-3+), 3.0 (future human-level with social cues), and 4.0 (superhuman intelligence proactively constructing context). Each stage is driven by breakthroughs that lower human-AI interaction costs.
Formal mathematical definition: Formalizes context as C = ⋃(e∈Erel) Char(e), grounding Dey’s 2001 framework, defining context engineering as systematic operations for collection, storage, management, and usage. Provides a technology-agnostic foundation from the 1990s Context Toolkit to 2025 Claude Code.
Comprehensive lifecycle design: Examines collection (Era 1.0: GPS/mouse; Era 2.0: smartphones/wearables; Era 3.0: tactile/emotional), management (timestamps, QA compression, multimodal fusion, layered memory), and usage (intra-system sharing, cross-system protocols, proactive inference).
Practical implementations: Analyzes Gemini CLI (GEMINI.md hierarchical context), Tongyi DeepResearch (periodic summarization), KV caching optimization, tool design (<30 tools recommended), and multi-agent delegation patterns with clear boundaries.
Era 2.0 shifts: Acquisition expands from location/time to token sequences/APIs, tolerance evolves from structured inputs to human-native signals (text/images/video), understanding transitions from passive rules to active collaboration, achieving context-cooperative systems.
Future challenges: Limited collection methods, storage bottlenecks, O(n²) attention degradation, lifelong memory instability, and evaluation gaps. Proposes a semantic operating system with human-like memory management and explainable reasoning for safety-critical scenarios.
Editor Message:

We are excited to introduce our new cohort-based course on Building Effective AI Agents. Enroll now to systematically build, evaluate, and deploy real-world AI agents.
Use AGENTX25 for a 25% discount. Seats are limited, so enroll now to secure a spot!
3. Scaling Agent RL via Experience Synthesis
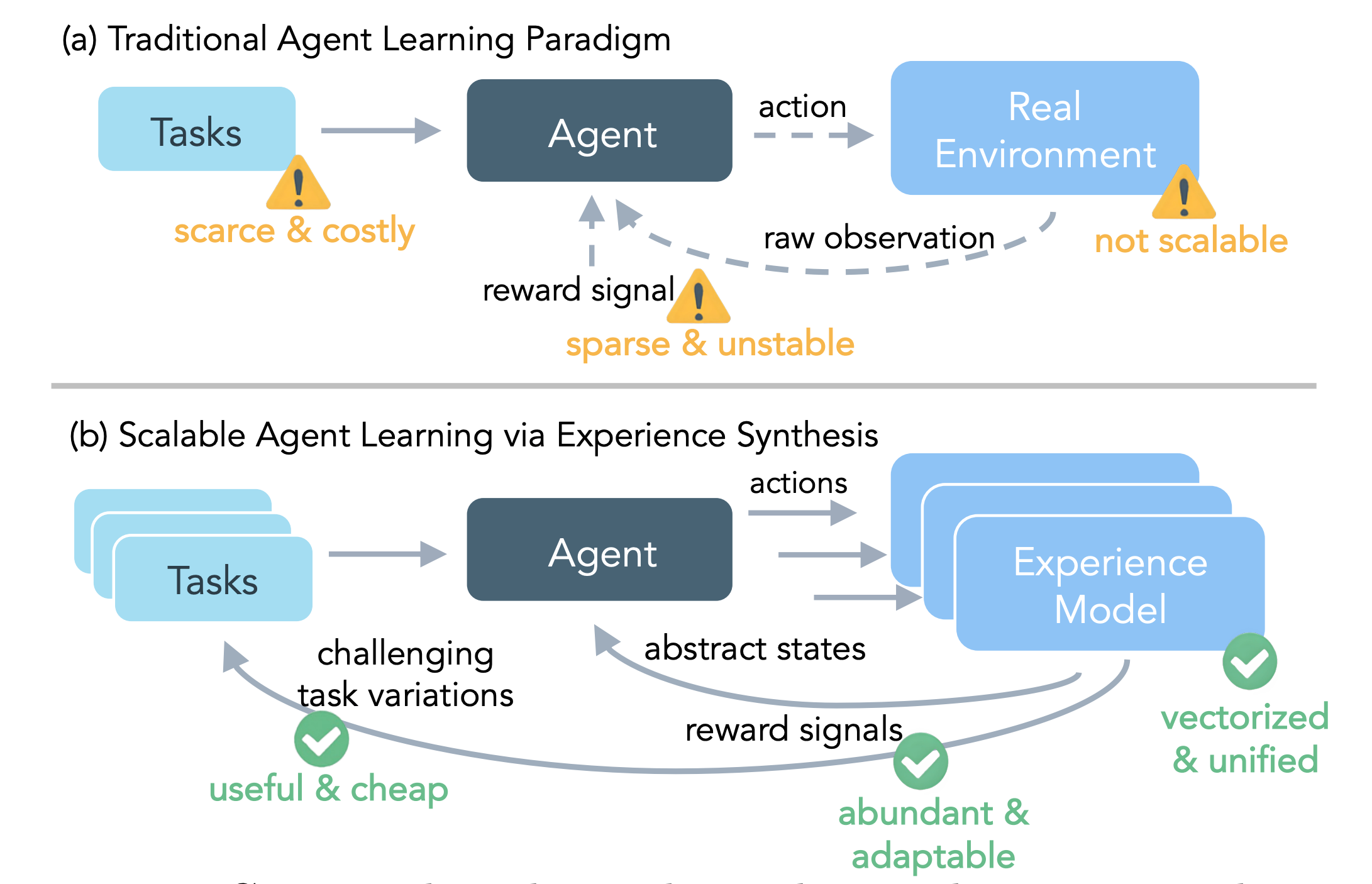
Meta researchers introduce DreamGym, a unified framework that synthesizes diverse training experiences to enable scalable reinforcement learning for LLM agents without costly real-environment rollouts. It addresses fundamental barriers of expensive interactions, limited task diversity, unreliable rewards, and infrastructure complexity.
Reasoning-based experience model: Distills environment dynamics into a textual state space, predicting transitions through chain-of-thought reasoning, enabling scalable rollout collection without pixel-perfect simulation.
Experience replay with co-evolution: Integrates offline demonstrations with online synthetic interactions, retrieving top-k similar trajectories to reduce hallucinations while staying aligned with evolving agent policy.
Curriculum-based task generation: Adaptively generates challenging variations using a reward-entropy heuristic to identify feasible yet difficult tasks, maximizing information gain without manual verification.
Dramatic non-RL-ready performance: On WebArena, DreamGym outperforms all baselines by 30%+ across three backbones, providing the only viable RL approach where traditional methods fail.
Matches traditional RL with zero real interactions: Purely synthetic training matches GRPO/PPO performance versus 80K real transitions. Sim-to-real transfer achieves 40%+ gains using <10% real data.
Sample efficiency and guarantees: Training time reduced to 1/3-1/5 of real-environment RL. Theoretical analysis shows the gap depends on reward accuracy and domain consistency, not strict state reconstruction.
4. TIR-Judge
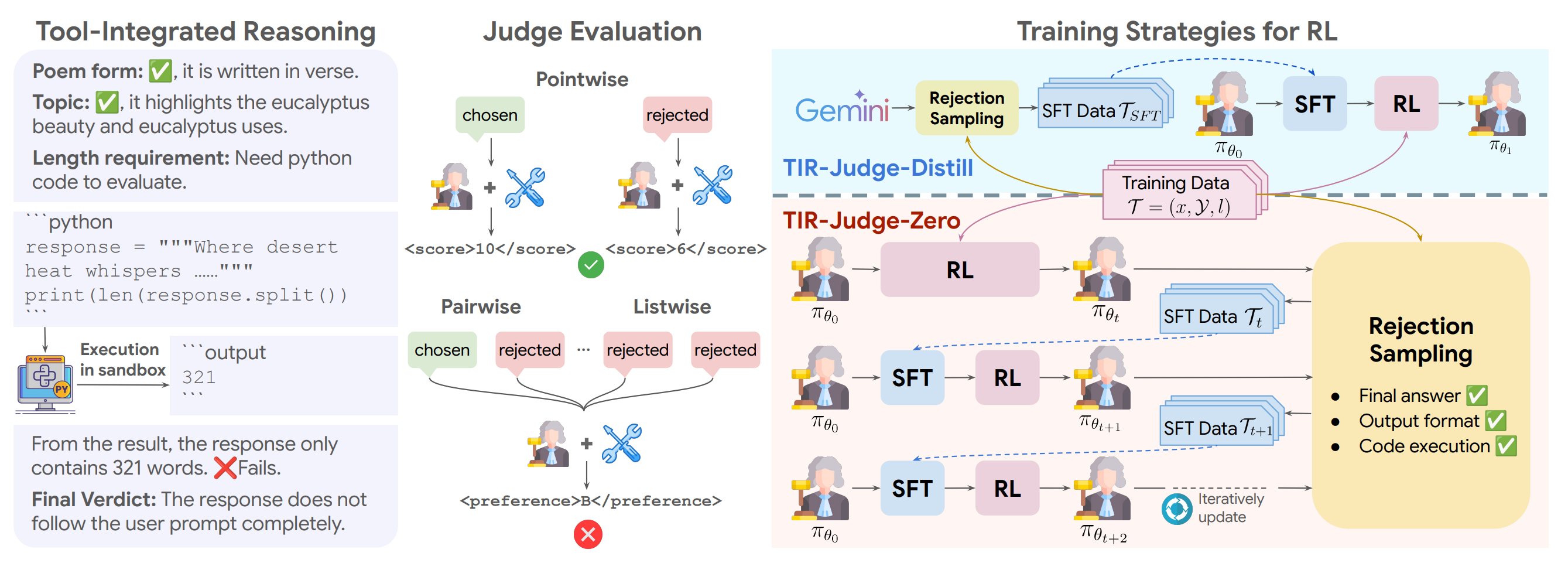
Google and collaborators introduce TIR-Judge, an end-to-end reinforcement learning framework that trains LLM judges to integrate code execution for precise evaluation. It surpasses reasoning-only judges by up to 6.4% (pointwise) and 7.7% (pairwise) while demonstrating that tool-augmented judges can self-evolve without distillation.
Tool-integrated reasoning: Enables judges to generate Python code, execute it, and iteratively refine reasoning during training, addressing text-only limitations on computation and symbolic reasoning tasks.
Three-component reward system: Combines correctness (ground-truth alignment), format (structured output discouraging unnecessary tool use), and tool-specific rewards (penalizing errors, capped at 3 calls). Full credit requires all three.
Diverse training formats: 26k preference pairs covering verifiable (competitive programming, math) and non-verifiable domains (dialogue, safety), supporting pointwise, pairwise, and listwise judgment formats with 8-gram decontamination.
Dramatic efficiency gains: 8B TIR-Judge surpasses 32B reasoning models on PPE and achieves 96% of Claude-Opus-4’s performance on RewardBench 2, with no inference-time overhead due to shorter reasoning during rejection sampling.
Self-improvement without distillation: TIR-Judge-Zero trains purely through iterative RL cycles without teacher trajectories, matching or outperforming distilled variants on 4/6 (pointwise) and 3/6 (pairwise) benchmarks, +1.2% gain at 4B scale.
Best-of-N downstream improvements: Achieves 3.9-6.7% absolute gains over RRM baseline on BigCodeBench and AIME, with the strongest improvements on precise verification tasks, validating real-world effectiveness.
5. Enhancing Long-Term Memory in LLMs
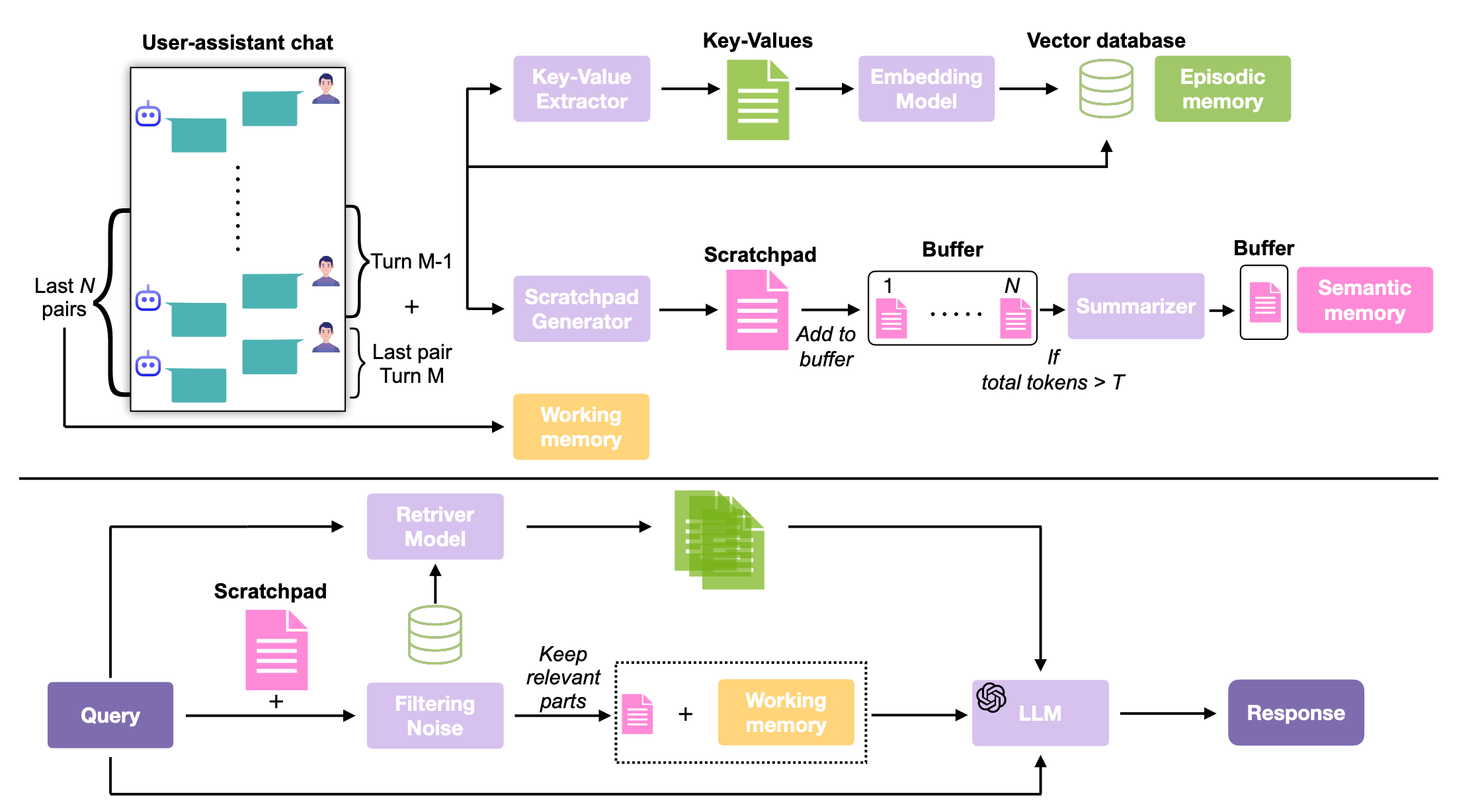
Researchers from the University of Alberta and UMass Amherst introduce BEAM, a new benchmark for evaluating long-term memory in LLMs with conversations up to 10M tokens, and LIGHT, a framework that enhances memory performance through three complementary systems.
Novel benchmark design: 100 diverse conversations (100K-10M tokens) with 2,000 validated questions testing 10 memory abilities, including contradiction resolution, event ordering, and instruction following.
Advanced generation framework: Automatically creates coherent narratives across 19 domains using conversation plans, user profiles, relationship graphs, and bidirectional dialogue dynamics.
Cognitive-inspired architecture: LIGHT integrates episodic memory (retrieval-based), working memory (recent turns), and scratchpad (salient facts), mimicking human memory systems.
Strong empirical results: 3.5-12.69% average improvement over baselines, with the largest gains in summarization (+160.6%), multi-hop reasoning (+27.2%), and preference following (+76.5%).
Scalability at extreme lengths: At 10M tokens, LIGHT shows +155.7% (Llama-4-Maverick) and +107.3% (GPT-4.1-nano) improvements, where no baseline supports full context.
Ablation insights: At 10M tokens, removing retrieval (-8.5%), scratchpad (-3.7%), working memory (-5.7%), or noise filtering (-8.3%) significantly degrades performance.
6. Tool-to-Agent Retrieval
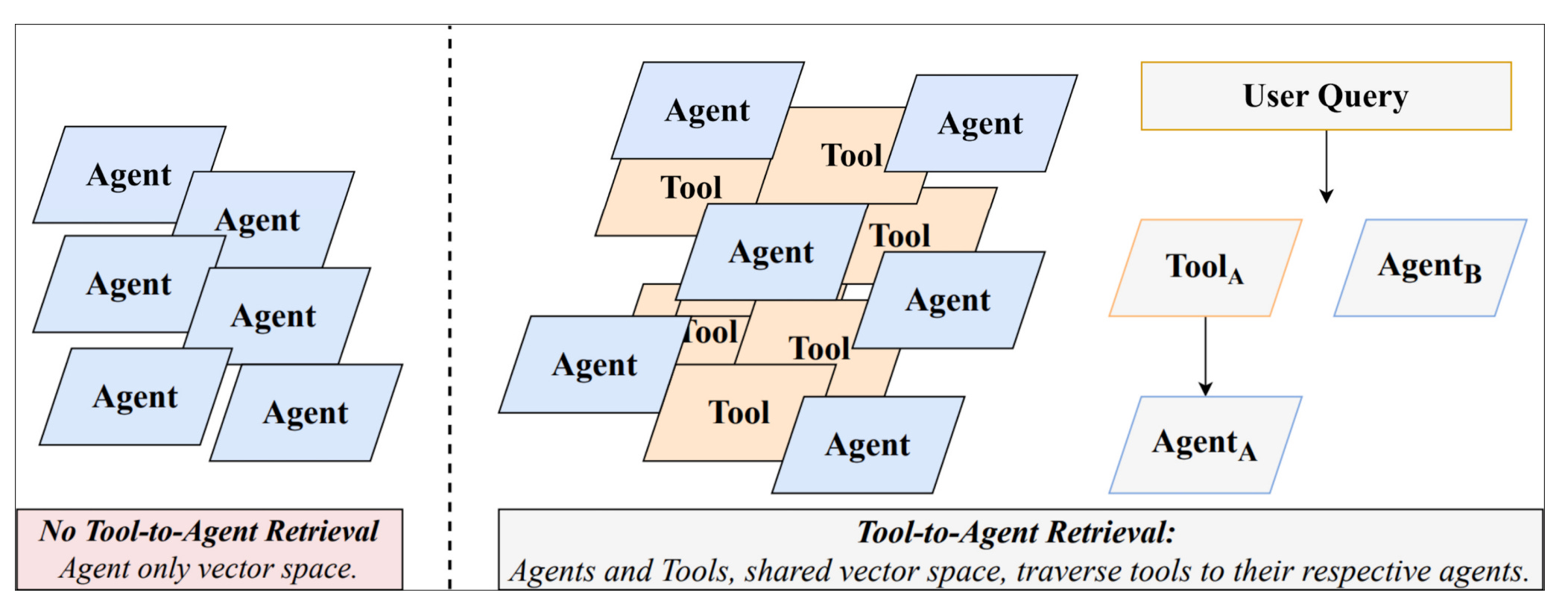
PwC researchers introduce a unified retrieval framework that embeds both tools and agents in a shared vector space with metadata relationships, enabling efficient routing in multi-agent systems coordinating hundreds of MCP servers and tools.
Unified indexing approach: Constructs a joint tool-agent catalog as a bipartite graph with metadata relationships, enabling traversal from tool matches to executable agent context.
Granular retrieval mechanism: Retrieves top-N entities using semantic similarity (dense vectors + BM25), then aggregates parent agents to select top-K unique agents, avoiding context dilution.
Flexible query paradigms: Supports direct querying (high-level questions) and step-wise querying (sub-task decomposition), with step-wise as the primary evaluation for multi-step workflows.
Consistent performance gains: 19.4% improvement in Recall@5 and 17.7% in nDCG@5 over ScaleMCP/MCPZero on LiveMCPBench (70 servers, 527 tools).
Architecture-agnostic improvements: Stable gains across 8 embedding models (Vertex AI, Gemini, Titan, OpenAI, MiniLM) with 0.02 standard deviation in Recall@5, strongest lift on Titan v2 (+28%).
Balanced retrieval distribution: 39.13% of top-K from agent corpus, 34.44% of tools traced to agents, confirming framework preserves both tool precision and agent context.
7. Diffusion LMs are Super Data Learners
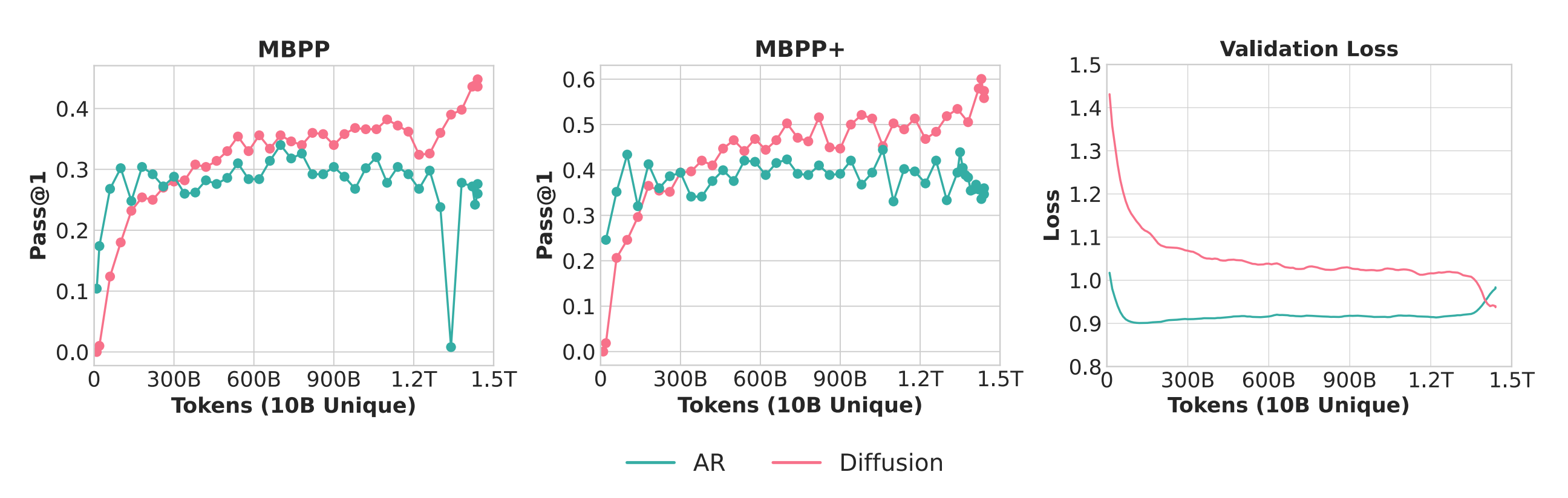
Researchers from NUS, Sea AI Lab, StepFun, and collaborators demonstrate that diffusion language models (DLMs) consistently outperform autoregressive models when unique training data is limited. Reveals that a systematic “crossover” phenomenon exists where DLMs extract 3x more value per unique token through multi-epoch training.
Crossover phenomenon: Under limited unique data, DLMs surpass AR models with more epochs. Crossover timing shifts based on data quantity (more delays it), data quality (higher delays it), and model size (larger triggers earlier).
Three compounding advantages: (1) Any-order modeling enabling 2^L corruption patterns vs AR’s L prefixes, (2) super-dense compute through iterative bidirectional denoising (>100x training FLOPs), (3) built-in Monte Carlo augmentation via masked sequence expectations.
Dramatic efficiency at scale: 1.7B DLM on 10B Python tokens for ~150 epochs (1.5T total) surpasses AR baseline on MBPP/MBPP+. 1B DLM achieves 56% HellaSwag and 33% MMLU using only 1B tokens repeated 480 epochs.
Data vs compute trade-off: DLMs achieve >3x data efficiency but require >100x training FLOPs and 16-4700x inference FLOPs, optimal when high-quality data is the primary constraint.
Validation loss decoupling: Rising validation cross-entropy doesn’t imply degraded performance. Models continue improving on HellaSwag, MMLU, MBPP, and HumanEval as relative NLL gaps widen consistently.
Ablation insights: Noise injection in AR inputs (10-90% masking) or dropout improves data-constrained performance but falls short of DLMs. Sparse AR degrades badly while DLM MoEs benefit consistently, confirming the super-density advantage.
8. Mathematical Exploration and Discovery at Scale
Google DeepMind, Princeton, Brown, and Terence Tao apply AlphaEvolve, an AI system using LLM-guided evolutionary search to autonomously discover mathematical constructions across analysis, combinatorics, geometry, and number theory. Across 67 problems, AlphaEvolve rediscovered best-known solutions, improved several problems, and extended finite solutions into general formulas with significantly reduced computation time.
9. Petri Dish Neural Cellular Automata
Sakana AI researchers introduce PD-NCA, a differentiable artificial life framework where multiple independent agents continuously update their parameters through gradient descent during simulation, enabling within-lifetime learning and open-ended behavioral change. The system exhibits emergent phenomena, including rock-paper-scissors dynamics, cyclic interactions, and spontaneous cooperation despite purely competitive optimization objectives.
10. Unlocking the Power of Multi-Agent LLM for Reasoning
Researchers from Penn State, Harvard, Microsoft, and collaborators introduce Dr. MAMR, addressing the “lazy agent” problem in multi-agent LLM reasoning through Shapley-inspired causal influence measurement and verifiable restart mechanisms. The framework achieves 78.6% on MATH500 (+4.2% over ReMA), 20.0% on AIME24, and maintains balanced agent contributions where baseline approaches collapse into single-agent dominance.