
🥇Top AI Papers of the Week
The Top AI Papers of the Week (December 8-14)
1. Towards a Science of Scaling Agent Systems
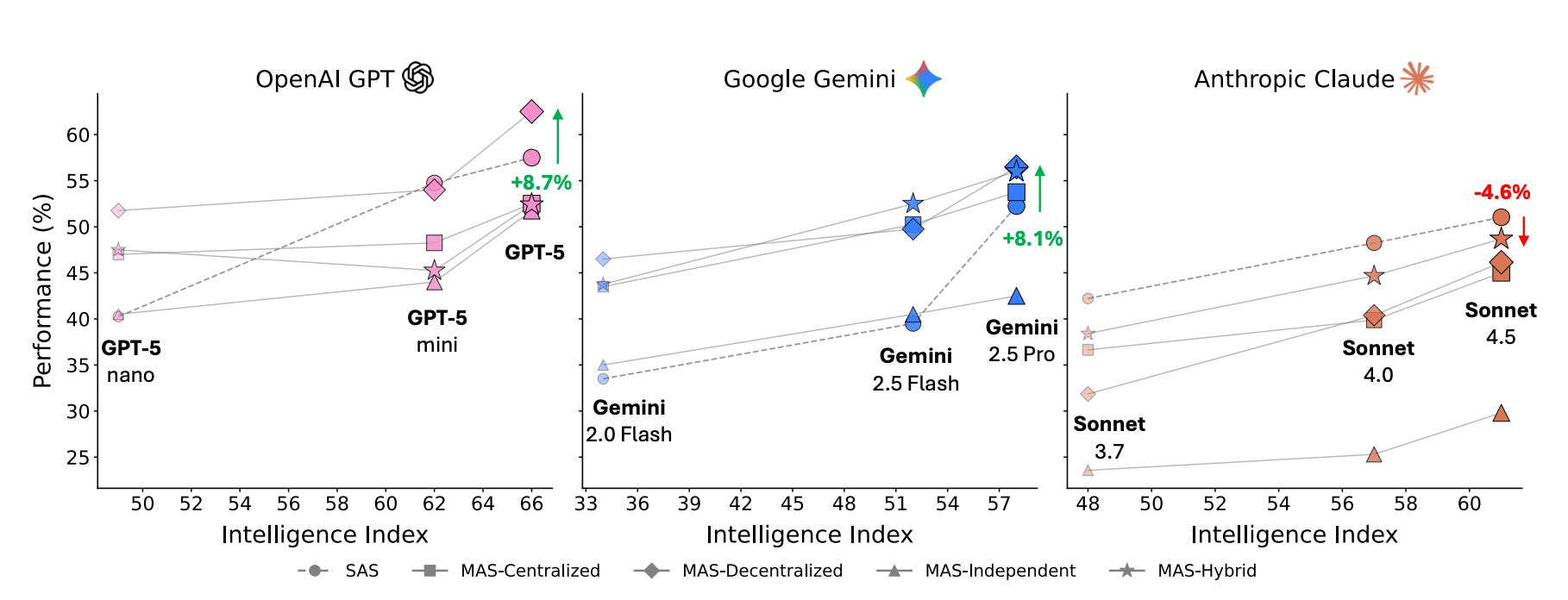
Researchers from Google present a controlled evaluation framework for agent systems, challenging the assumption that “more agents are all you need.” Across 180 configurations spanning three LLM families and four agentic benchmarks, the study establishes quantitative principles for when multi-agent coordination helps versus hurts performance.
Predictive framework: The study derives a mixed-effects model achieving an R-squared of 0.513 using coordination metrics like efficiency, error amplification, and redundancy. Leave-one-domain-out cross-validation achieves R^2 of 0.89 and correctly predicts optimal architectures for 87% of held-out task configurations.
Tool-coordination trade-off: Tool-heavy tasks suffer from multi-agent coordination overhead, with efficiency penalties compounding as environmental complexity increases. Tasks where single-agent performance exceeds 45% accuracy experience negative returns from additional agents.
Error amplification patterns: Independent multi-agent systems amplify errors 17.2x versus single-agent baselines through unchecked error propagation. Centralized coordination achieves 4.4x containment via validation bottlenecks that catch errors before they propagate.
Architecture-task alignment: Performance spans +81% relative improvement (structured financial reasoning under centralized coordination) to -70% degradation (sequential planning under independent coordination). The key finding is that architecture-task alignment, not the number of agents, determines collaborative success.
Message from the Editor

We are excited to announce our second cohort on Vibe Coding with Claude Code. Learn how to leverage Claude Code for increasing your productivity and vibe coding.
Use coupon code EARLYBIRDCC25 for 25% today. Seats are limited!
2. GigaTIME
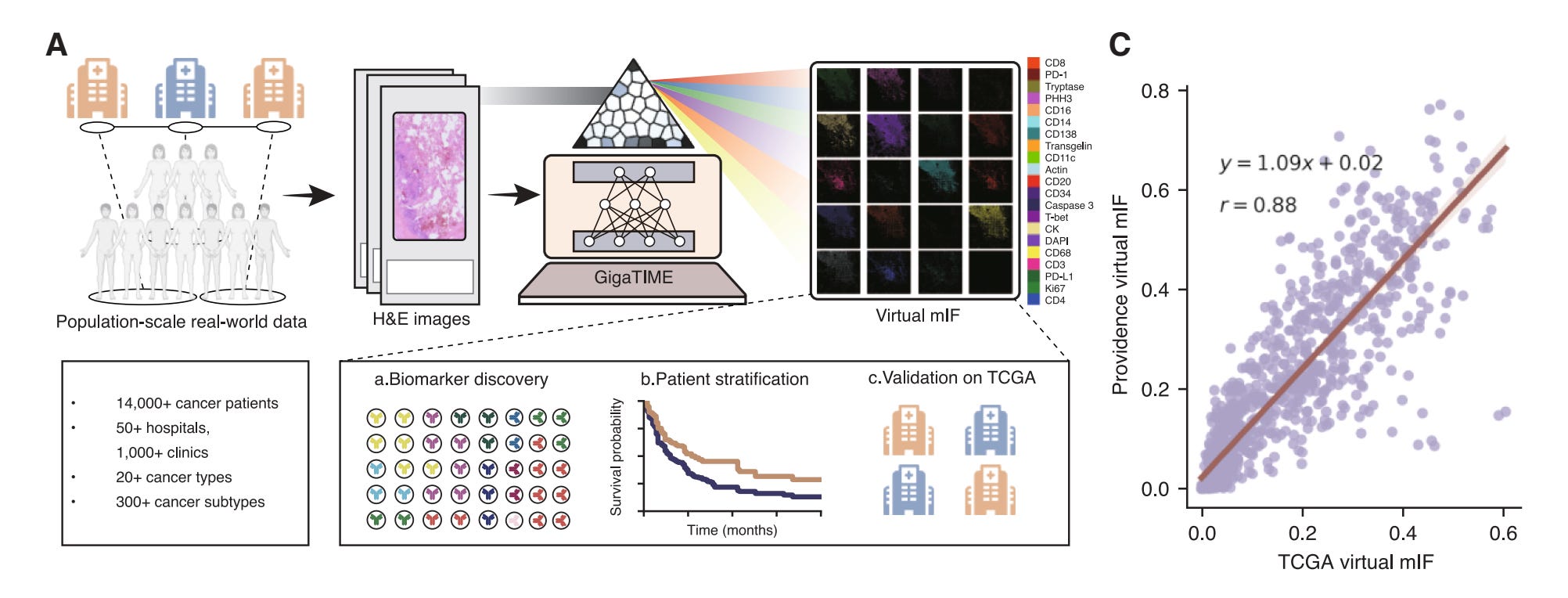
Microsoft Research and Providence Health introduce GigaTIME, a multimodal AI framework that generates virtual multiplex immunofluorescence (mIF) images from standard H&E pathology slides, enabling population-scale tumor immune microenvironment modeling. The system was applied to over 14,000 cancer patients across 24 cancer types, uncovering over 1,200 statistically significant protein-biomarker associations.
Cross-modal translation: GigaTIME learns to translate H&E slides into virtual mIF images across 21 protein channels by training on 40 million cells with paired H&E and mIF data. The model uses a NestedUNet architecture that significantly outperforms CycleGAN baselines on pixel, cell, and slide-level metrics.
Virtual population at scale: Applied to 14,256 patients from 51 hospitals across seven US states, generating 299,376 virtual mIF whole-slide images. This enabled the discovery of 1,234 statistically significant associations between TIME proteins and clinical biomarkers at pan-cancer, cancer-type, and subtype levels.
Clinical discovery: The virtual population revealed associations between immune markers and genomic alterations like TMB-H, MSI-H, and KMT2D mutations. A combined GigaTIME signature of all 21 virtual protein channels outperformed individual markers for patient stratification and survival prediction.
Combinatorial insights: Analysis found that combining protein channels like CD138 and CD68 yields stronger biomarker associations than either protein alone, suggesting coordinated immune responses in antibody-mediated tumor mechanisms.
Independent validation: Testing on 10,200 TCGA patients showed strong concordance with Providence results (Spearman correlation 0.88), demonstrating GigaTIME’s generalizability across different patient populations and data sources.
3. Pre-Training, Mid-Training, and RL Interplay
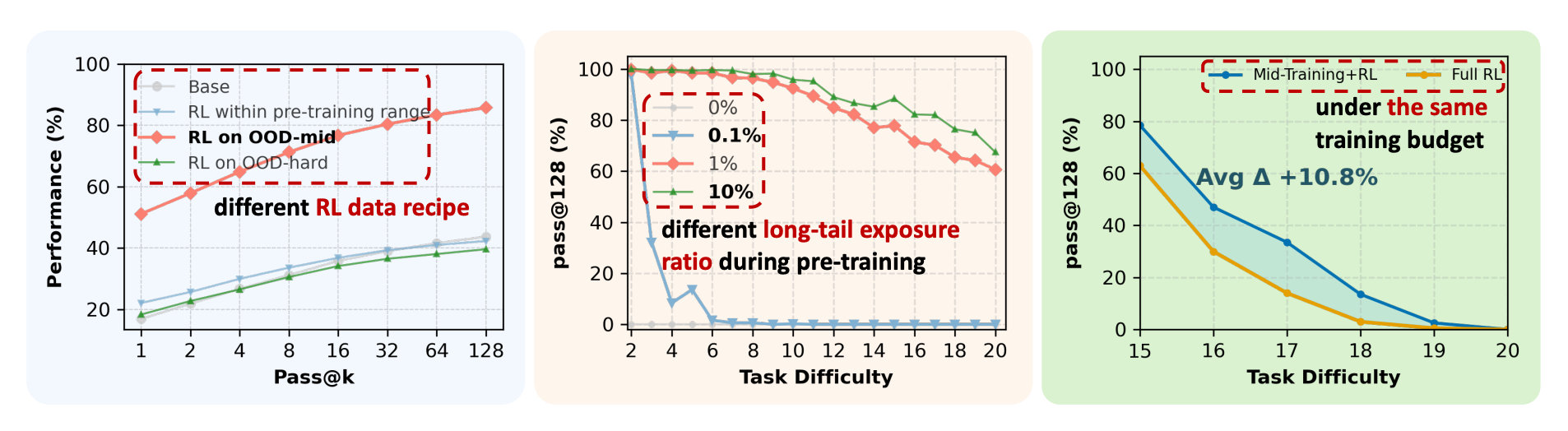
CMU researchers develop a controlled experimental framework using synthetic reasoning tasks to isolate how pre-training, mid-training, and RL-based post-training each contribute to reasoning capabilities in language models. The study reconciles conflicting views on whether RL truly extends reasoning beyond what models learn during pre-training.
Edge of competence: RL produces true capability gains (pass@128) only when pre-training leaves sufficient headroom and when RL data targets the model’s edge of competence - tasks that are difficult but not yet out of reach. When tasks are already covered or too out-of-distribution, gains vanish.
Minimal exposure threshold: Contextual generalization requires minimal yet sufficient pre-training exposure. RL fails with near-zero exposure but generalizes robustly with sparse exposure of at least 1%, yielding up to +60% pass@128 improvements.
Mid-training impact: A mid-training stage bridging pre-training and RL substantially improves out-of-distribution reasoning under fixed compute budgets, with mid-training + RL outperforming RL alone by +10.8% on OOD-hard tasks.
Process rewards: Incorporating process-level rewards reduces reward hacking and improves reasoning fidelity by aligning reinforcement signals with valid reasoning behavior rather than just final answers.
4. Agentic AI Adaptation Survey
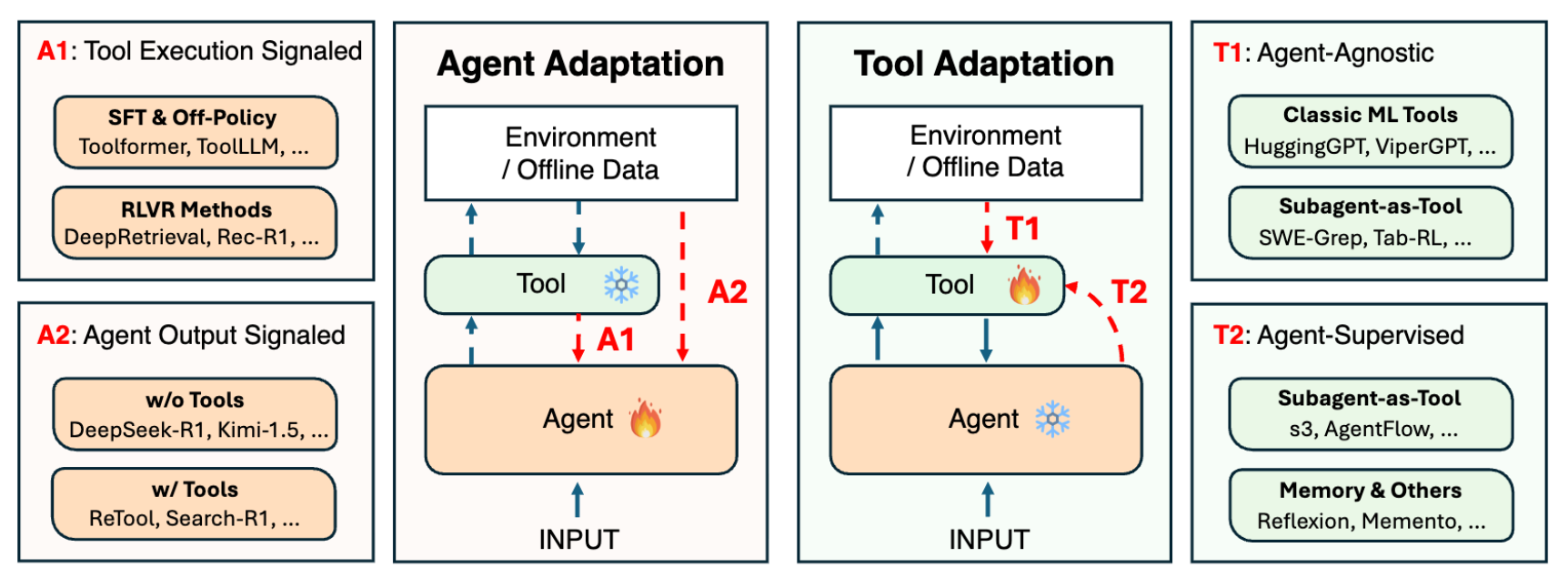
Researchers from UIUC, Stanford, Berkeley, and other institutions present the first comprehensive taxonomy of adaptation strategies for agentic AI systems. The survey organizes recent advances into a unified framework covering how agents and their tools can be modified to achieve higher task performance, improved reliability, and better generalization across diverse scenarios.
Four adaptation paradigms: The framework categorizes methods into A1 (tool execution signaled agent adaptation using verifiable outcomes like code sandbox results), A2 (agent output signaled adaptation from evaluations of final answers), T1 (agent-agnostic tool adaptation where tools train independently), and T2 (agent-supervised tool adaptation where tools adapt using frozen agent feedback).
Key trade-offs identified: Agent adaptation (A1/A2) requires substantial compute for training billion-parameter models but offers maximal flexibility. Tool adaptation (T1/T2) optimizes external components at lower cost but may be constrained by frozen agent capabilities. T1 tools generalize well across agents, while A1 methods may overfit without regularization.
RLVR emergence: The survey traces the evolution from early SFT and DPO methods to reinforcement learning with verifiable rewards (RLVR), where models learn directly from online interaction with tools and environments - marking a shift from pre-collected trajectories to dynamic, context-aware adaptation.
Domain applications: Demonstrates how adaptation strategies apply across deep research, software development, computer use, and drug discovery - with state-of-the-art systems increasingly combining multiple paradigms in cascaded architectures.
5. Reasoning Models Ace the CFA Exams
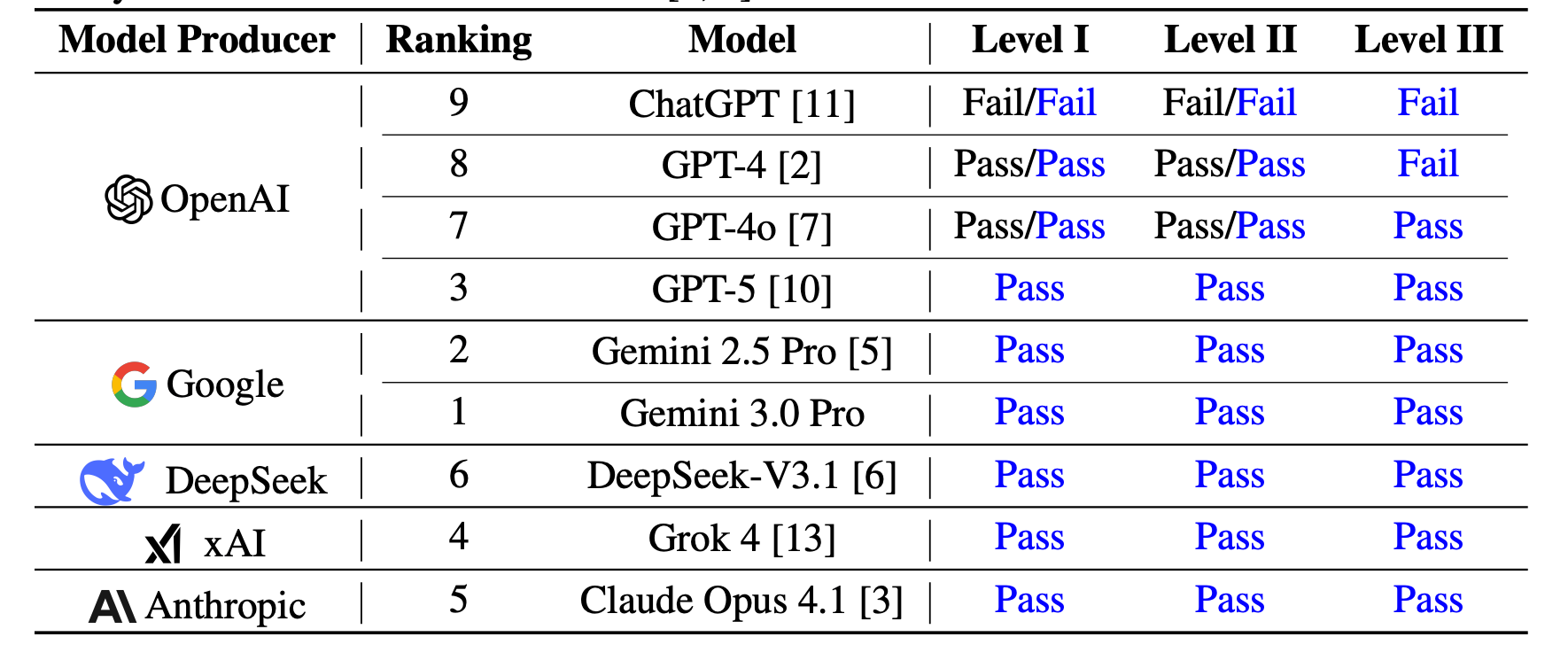
Researchers evaluate state-of-the-art reasoning models on mock CFA exams consisting of 980 questions across all three certification levels. While previous studies reported that LLMs performed poorly on these exams, the latest reasoning models now pass all three levels, with Gemini 3.0 Pro achieving a record 97.6% on Level I.
Top performers: Gemini 3.0 Pro, Gemini 2.5 Pro, GPT-5, Grok 4, Claude Opus 4.1, and DeepSeek-V3.1 all pass every level. GPT-5 leads Level II with 94.3%, while Gemini 2.5 Pro achieves 86.4% on Level III multiple-choice, and Gemini 3.0 Pro scores 92.0% on constructed-response questions.
Dramatic improvement from baselines: ChatGPT (GPT-3.5) failed all levels, GPT-4 passed Levels I and II but failed Level III, and GPT-4o passed all three. The new reasoning models achieve near-perfect scores on Levels I and II.
Shifting difficulty patterns: Quantitative domains, previously identified as primary weaknesses for LLMs, now show near-zero error rates for top models. Ethical and Professional Standards remain the most challenging area, with 17-21% error rates on Level II.
Chain-of-thought trade-offs: CoT prompting helps baseline models significantly but shows inconsistent effects on reasoning models for MCQs. However, CoT remains highly effective for constructed-response questions, boosting Gemini 3.0 Pro from 86.6% to 92.0%.
6. AI and Human Co-Improvement

Meta FAIR researchers Jason Weston and Jakob Foerster argue that fully autonomous self-improving AI is neither the fastest nor safest path to superintelligence. Instead, they advocate for co-improvement: building AI that collaborates with human researchers to conduct AI research together, from ideation to experimentation.
Core thesis: Self-improvement seeks to eliminate humans from the loop as quickly as possible. Co-improvement keeps humans involved, providing steering capability toward positive outcomes while leveraging complementary skill sets. Because AI is not yet mature enough to fully self-improve and is susceptible to misalignment, co-improvement will get us there faster and more safely.
Research collaboration skills: The authors propose measuring and training AI on research collaboration abilities across problem identification, benchmark creation, method innovation, experiment design, collaborative execution, evaluation, scientific communication, and safety/alignment development.
Bidirectional augmentation: Unlike self-improvement, which focuses on autonomous model updates, co-improvement centers on joint progress where humans help AI achieve greater abilities while AI augments human cognition and research capabilities. The goal is co-superintelligence through symbiosis.
Paradigm shift acceleration: Major AI advances came from human researchers finding combinations of training data and method changes. Co-research with strong collaborative AI should accelerate finding unknown new paradigm shifts while maintaining transparency and human-centered safety.
7. Selective Gradient Masking
: A data bar split into General knowledge (teal) and CBRN (coral) feeds into a neural network, with arrows showing Retain and Forget pathways. Right panel (Remove): A neural network with teal nodes marked with plus signs (Retain) connected by teal lines, and one coral node marked with X (Forget) connected by coral lines, showing the forget node being removed.")
Anthropic researchers present Selective Gradient Masking (SGTM), a technique that removes dangerous capabilities like CBRN knowledge from language models during pretraining while preserving general capabilities. Unlike data filtering, SGTM localizes target knowledge into dedicated “forget” parameters that can be zeroed out after training.
Absorption mechanism: SGTM splits parameters into forget and retain components, with gradients masked so only forget parameters update on labeled dangerous content. Unlabeled dangerous content naturally gravitates toward forget parameters through self-reinforcing “absorption,” providing robustness to imperfect labeling.
Recovery resistance: Traditional unlearning methods (RMU) recovered and removed biology knowledge in 50 fine-tuning steps. SGTM required 350 steps - 7x more resistant than RMU and matching the robustness of models trained with perfect data filtering.
Retain/forget trade-offs: On Wikipedia biology experiments with 254M parameter models, SGTM achieved superior trade-offs compared to both weak and strict data filtering, retaining more knowledge from adjacent fields like medicine and chemistry with only 5% compute penalty.
Mechanistic validation: Gradient analysis on bilingual data showed forget parameters develop higher gradient norms for forget-domain content while retain parameters specialize for general content, with this localization strengthening at larger scales.
8. Nanbeige4-3B
Nanbeige4-3B is a 3B parameter model pretrained on 23T tokens and fine-tuned on over 30M instructions using a Fine-Grained Warmup-Stable-Decay scheduler, Dual Preference Distillation, and multi-stage reinforcement learning. Despite its compact size, it outperforms Qwen3-8B and Qwen3-14B on reasoning benchmarks and rivals much larger models on WritingBench, demonstrating that well-engineered small models can match far larger counterparts.
9. AI Agent Adoption Study
Harvard and Perplexity researchers present the first large-scale field study of AI agent adoption using hundreds of millions of anonymized interactions from Perplexity’s Comet browser. Productivity and Learning account for 57% of agentic queries, with digital technology workers (28% of adopters) and knowledge-intensive sectors leading adoption. Users in higher GDP countries with greater educational attainment are more likely to adopt agents, and over time, users shift from media and travel tasks toward more cognitively oriented topics.
10. ProAgent
ProAgent is the first end-to-end proactive LLM agent system that harnesses sensory contexts from AR glasses, smartphones, and edge servers to deliver assistance without explicit user instructions. Unlike reactive agents that wait for commands, ProAgent continuously senses the environment with on-demand tiered perception and achieves up to 33.4% higher proactive prediction accuracy, 16.8% higher tool-calling F1 score, and 38.9% improved user satisfaction over baselines.
“Tool-coordination trade-off: Tool-heavy tasks suffer from multi-agent coordination overhead, with efficiency penalties compounding as environmental complexity increases. Tasks where single-agent performance exceeds 45% accuracy experience negative returns from additional agents.”
Very interesting. So the framework of just add more by default isn’t necessarily all that workable. Great research coming out of Google this week. Thanks!
This piece truely made me think how your emphasis on architecture-task alignment is so insightful, often mirroring complex human team coordination challenges.