
🥇Top AI Papers of the Week
The Top AI Papers of the Week (September 8-14)
1. SFR-DeepResearch
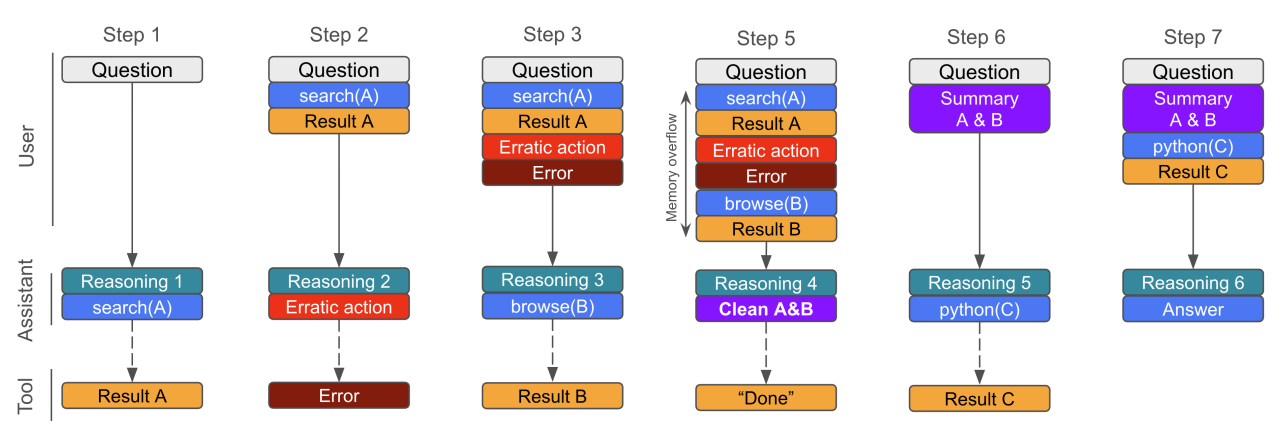
The paper introduces SFR-DeepResearch, a simple reinforcement-learning recipe that turns reasoning-optimized LLMs into autonomous single-agent researchers. The agent uses only three tools (search, static page browse, Python), manages its own context, and is trained end-to-end on synthetic short-form and long-form tasks with a length-normalized REINFORCE objective. Results show strong gains on FRAMES, GAIA, and Humanity’s Last Exam.
Agent design and scaffolding: Reformulates multi-turn tool use into a single, growing contextual question for QwQ and Qwen models, omitting earlier long CoTs to keep prompts stable. Adds a clean_memory tool to self-compress context when nearing limits.
Minimal toolset, fault tolerance: Tools are restricted to a bare search API, a static Markdown page scraper with no hyperlink clicking, and a stateless local Python interpreter, which makes training challenging enough to learn a strategy. Parsing and syntax errors trigger repair or retry routines to keep rollouts on track.
RL recipe: Uses synthetic, harder-than-Hotpot multi-hop QA plus report-writing tasks. Optimizes a group REINFORCE objective with temporal advantage normalization that divides by trajectory length, plus trajectory filtering and reuse of partial rollouts. Localized, cached tooling and a contamination blocklist stabilize training and evaluation.
Results: The best model, SFR-DR-20B, reaches 82.8 on FRAMES, 66.0 on GAIA (text-only), and 28.7 on HLE full text-only, outperforming comparable open agents and rivaling stronger proprietary systems under a contamination blocklist.
Ablations and behavior: The single-turn scaffolding beats default multi-turn templates for Qwen and QwQ, with large FRAMES gains. Length normalization curbs runaway tool calls that hurt reward and accuracy. Tool-use and token-length analysis shows gpt-oss-20B calls tools more yet writes much shorter per-step CoTs, indicating better token efficiency than Qwen-family models.
2. Emergent Hierarchical Reasoning
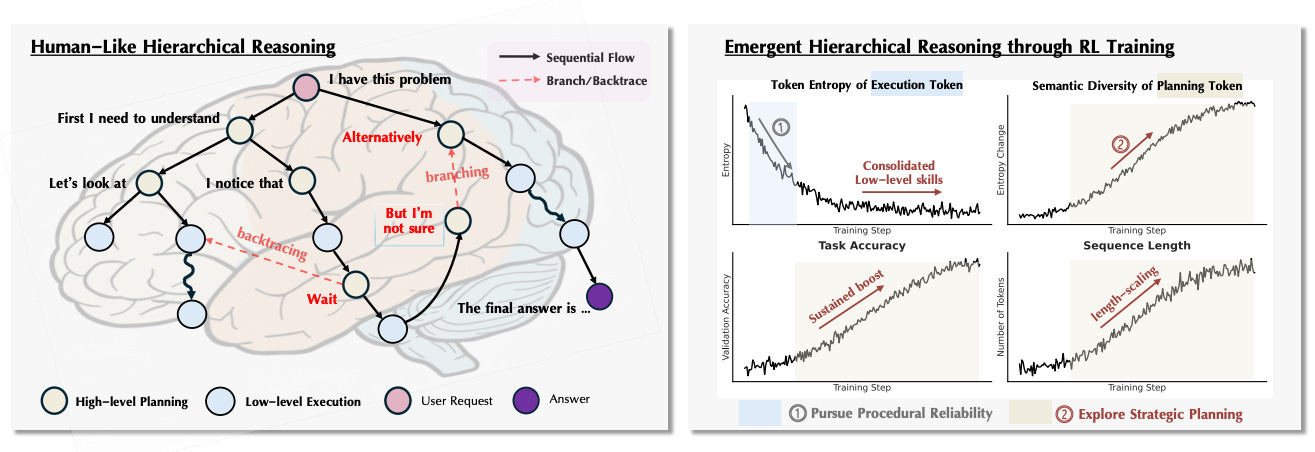
The paper argues that RL improves LLM reasoning via an emergent two-phase hierarchy: first the model firms up low-level execution, then progress hinges on exploring high-level planning. Building on this, the authors propose HICRA, which boosts credit on strategic planning tokens, and show consistent gains over GRPO. They also propose semantic entropy as a better exploration signal than token-level entropy.
Two-phase dynamic. Early RL training reduces perplexity and entropy on execution tokens, consolidating procedural skills. Later gains align with increased diversity in planning tokens and longer, more accurate traces, explaining “aha moments” and length scaling.
Planning vs execution. The paper functionally tags strategic grams (e.g., deduction, branching, backtracing) as planning tokens, distinguishing them from procedural steps. This labeling exposes the shift in the learning bottleneck toward strategy.
HICRA algorithm. Modifies GRPO by amplifying advantages on planning tokens with a scalar α, concentrating optimization on high-impact strategic decisions instead of spreading it across all tokens. This creates targeted exploration and faster reinforcement of effective strategies. Section 3 gives the formulation.
Results. Across Qwen, Llama, and VLMs, HICRA improves Pass@1 on AIME24/25, Math500, AMC23, and multimodal math suites, often by several points over GRPO, with plots showing higher semantic entropy tracking higher validation accuracy.
Signals that matter. Token-level entropy can decline even as true exploration grows, since execution tokens dominate. Semantic entropy over strategic grams better captures strategic exploration and correlates with performance.
Limits and scope. HICRA works best when a model already has a procedural foundation; on weaker bases, the focus on planning may not help. The paper suggests future work on higher-level action spaces, adaptive curricula, and process-oriented rewards.
3. Rethinking RAG-based Decoding
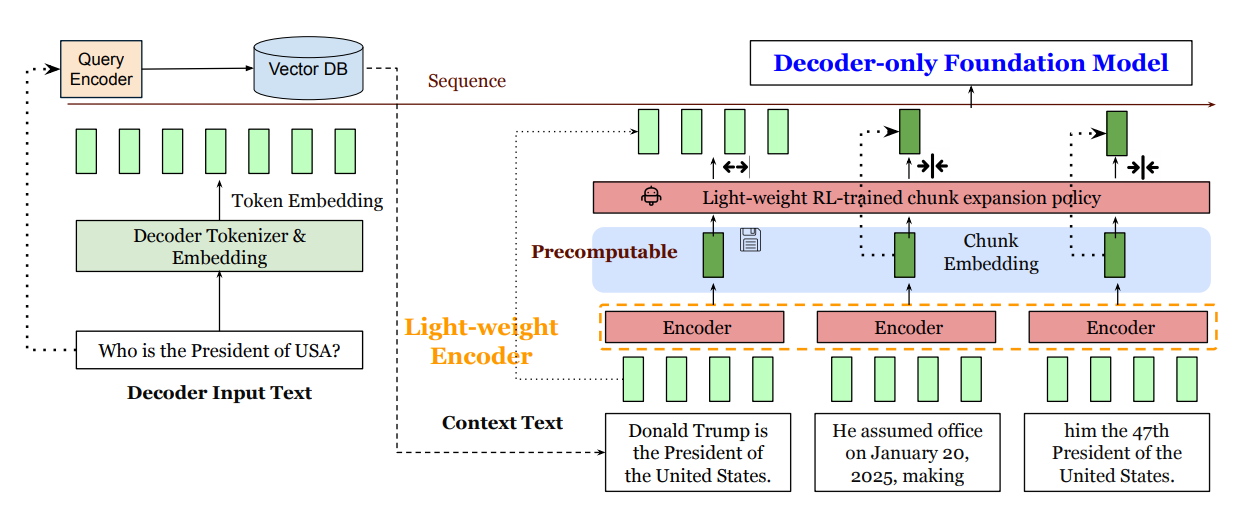
REFRAG replaces most retrieved tokens with precomputed chunk embeddings at decode time, then selectively expands only the few chunks that matter. This exploits block-diagonal attention in RAG prompts to cut latency and memory while preserving accuracy across RAG, multi-turn dialog, and long-doc summarization.
Core idea: Chunk the retrieved context, encode each chunk with a lightweight encoder, project to the decoder’s embedding size, and feed embeddings directly alongside the user query; an RL policy decides which chunks to keep uncompressed (“compress anywhere,” not only in the prefix).
Big speedups without accuracy loss: Up to 30.85× time-to-first-token acceleration vs LLaMA (and 3.75× over CEPE) at high compression rates, with comparable perplexity; throughput gains up to 6.78×.
Longer effective context: Compression lets the model handle much larger contexts (reported 16× extension) while maintaining or improving perplexity as sequence length grows.
RAG wins under fixed latency: With the same latency budget, REFRAG uses more passages and outperforms a LLaMA baseline on 16 RAG tasks. Aggregated plots and detailed results show gains for both strong and weak retrievers.
Generalization across applications: On multi-turn conversational QA, REFRAG preserves longer history and improves scores as passages and turns increase. On long-document summarization, it achieves the best ROUGE at matched decoder tokens.
4. ACE-RL
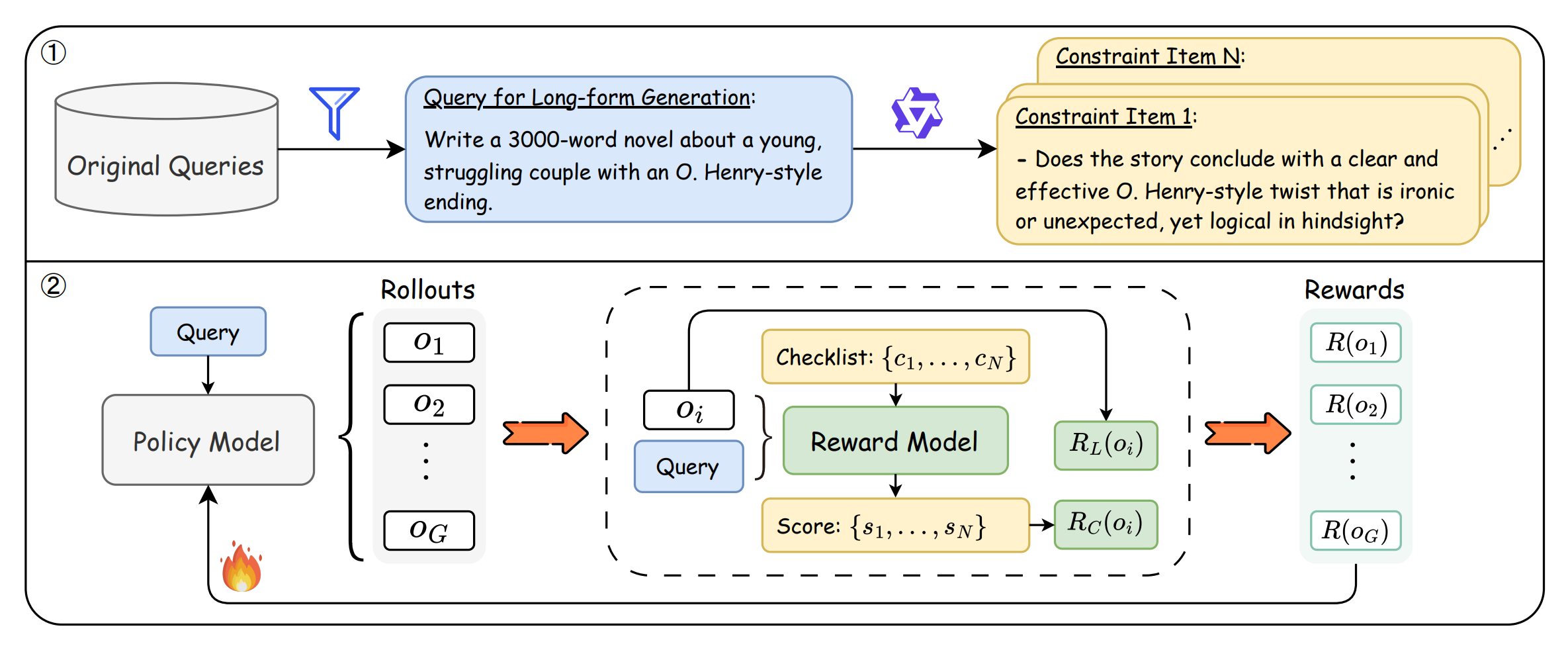
A reinforcement-learning framework that replaces coarse, preference-pair rewards with instruction-specific, verifiable checklists. ACE-RL turns each long-form task into a set of explicit and implicit constraints, scores a model’s output by how well it satisfies them, and mixes this with a length-control reward during GRPO training. The result is stronger, more controllable long-form writing across domains and styles.
Key idea: Automatically deconstruct each instruction into a fine-grained checklist (explicit and implicit demands), then verify each item with a small LLM using a 3-level rubric (Fully/Partially/Not Met). Rewards = mean checklist score + a length reward, optimized with GRPO.
Why it matters: Moves beyond relevance/coherence/helpfulness toward instruction-adaptive quality. No preference pairs required, which lowers cost and improves scalability.
Data & setup: 32K long-form instructions, average 5.48 constraints per prompt, target length around 2.3K words. Verifier uses Qwen3-8B; length reward penalizes deviations beyond a tolerance band.
Results: On WritingBench, ACE-RL lifts models substantially over SFT and LLM-as-judge RL; e.g., Qwen-2.5-7B jumps from 57.0 to 78.6. A small Qwen-3-4B-thinking model trained with ACE-RL beats several proprietary and writing-tuned systems. On Arena-Write, win-rates reach ~68% vs six strong baselines.
Ablations & insights:
Constraint-based rewards produce higher within-group reward variance than LLM-as-judge, indicating better discrimination among rollouts.
Works with small reward models and even self-reward settings.
Thinking mode plus ACE-RL outperforms non-thinking for long-form generation.
5. ParaThinker
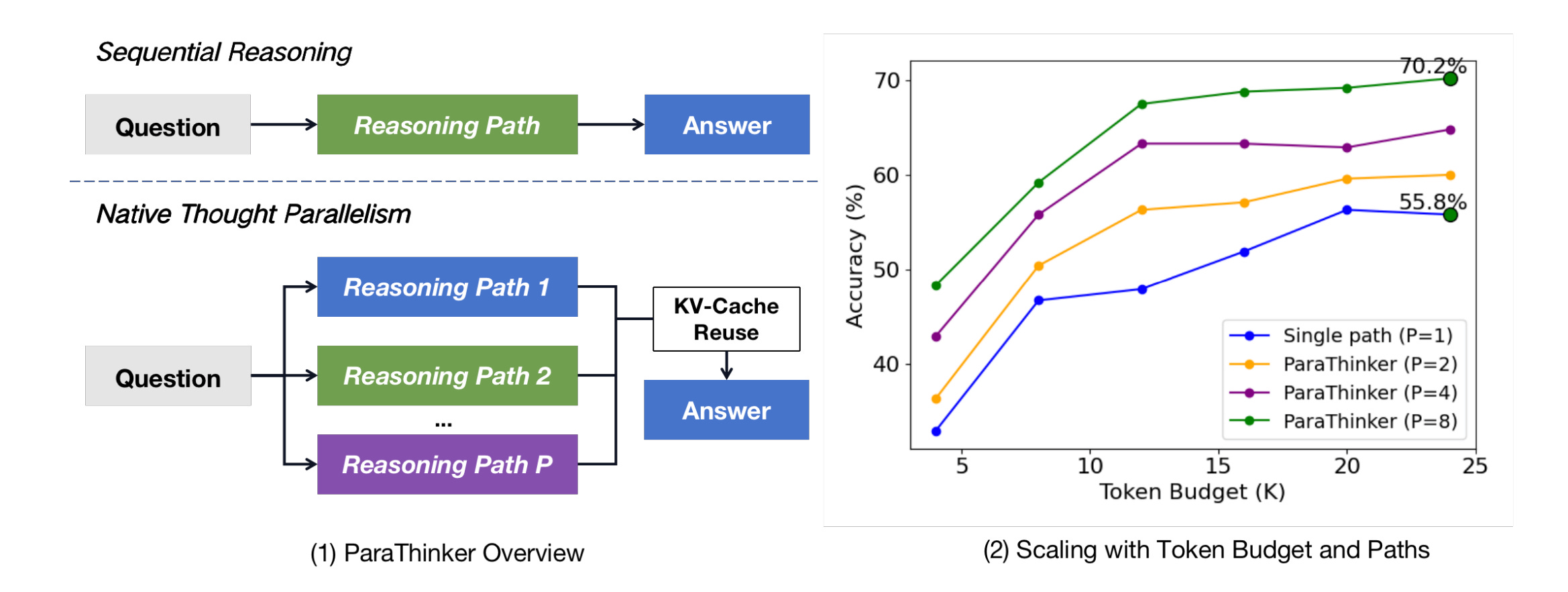
This paper argues that today’s “think longer” strategies trap LLMs in a single line of thought. They propose ParaThinker, which trains models to generate several independent reasoning paths in parallel and then fuse them into one answer. Across math benchmarks, this width-scaling lifts accuracy while adding only a small latency cost.
Problem framing. The paper identifies a test-time bottleneck called “Tunnel Vision,” where early tokens commit the model to a suboptimal path; majority-style parallel sampling can beat one long chain under the same token budget.
Method. ParaThinker runs two stages: parallel reasoning then summarization. It uses trainable control tokens
<think i>to start diverse paths, thought-specific positional embeddings to disambiguate tokens from different paths, and a two-phase attention mask that isolates paths during thinking and unifies them for summarization, reusing KV caches to avoid re-prefill.Training recipe. Supervised fine-tuning on multi-path traces sampled from teacher models, with random assignment of
<think i>so the student can generalize to more paths than seen in training; details and data sources are outlined in Section 4 and the SFT tables in the appendix.Results. On AIME 2024/2025, AMC 2023, and MATH-500, ParaThinker improves pass@1 over sequential baselines by about 12.3% for 1.5B and 7.5% for 7B with 8 paths at fixed per-path budgets, and beats majority voting by 4.3% (1.5B) and 2.0% (7B) on average. Combining ParaThinker with majority voting yields further gains.
Efficiency and design insights. Latency increases slightly with more paths because decoding is memory-bandwidth bound; on a single A800, 16 paths take less than 2× the time of one path for the same length. The best termination policy is “first-finish,” which equalizes path lengths and improves both accuracy and speed. Thought embeddings are crucial; naive flattened positions hurt performance.
6. AgentGym-RL
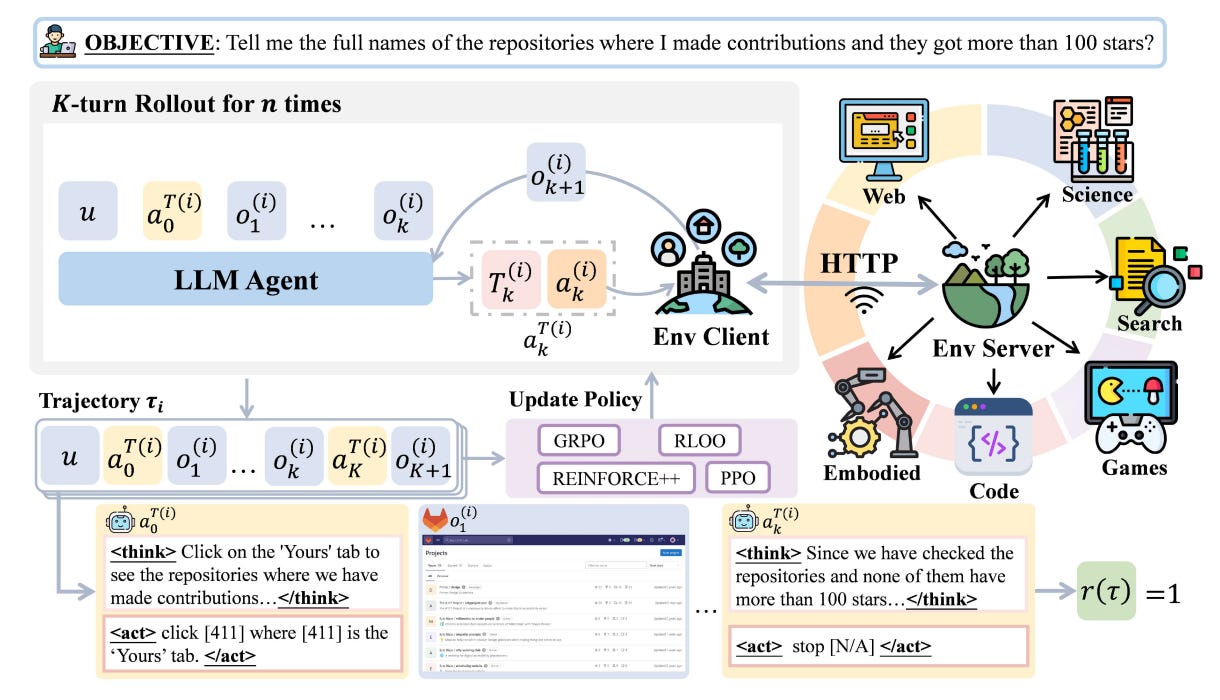
A modular framework for training LLM agents directly via reinforcement learning across realistic environments, plus a simple schedule, ScalingInter-RL, that lengthens interaction horizons over training to improve stability and performance. Results show a 7B open model can rival or beat larger proprietary systems on web navigation, deep search, games, embodied, and science tasks.
What it is: A unified, decoupled RL stack with three pluggable modules (Environment, Agent, Training) that supports PPO, GRPO, REINFORCE++, and runs across WebArena, Deep Search, TextCraft, BabyAI, and SciWorld.
Key idea: ScalingInter-RL starts with short horizons to emphasize exploitation and stable learning, then gradually increases allowed turns to encourage exploration and richer behaviors like planning and reflection.
Why it matters: Post-training and test-time compute scale better than model size alone for agentic tasks. A 7B model trained with this framework reaches about 58.6% average success and outperforms much larger baselines.
Results snapshot:
Web navigation: ScalingInter-7B hits 26.00% overall on WebArena, topping GPT-4o at 16.00.
Deep search: 38.25 overall, beating GPT-4o 26.75 and close to strong open baselines; best on NQ at 52.00 and ties TriviaQA at 70.00.
Games: 91.00 overall on TextCraft and one of the few with a non-zero at Depth 4 (33.33).
Embodied: 96.67 on BabyAI, surpassing o3 and GPT-4o on overall accuracy.
Science: 57.00 SOTA on SciWorld, with the 7B RL model also strong at 50.50.
Training dynamics: Longer horizons too early can collapse learning; short horizons cap performance. ScalingInter-RL avoids both.
Engineering notes: Parallelized browsers, reset hooks, and memory-leak fixes enable reliable long rollouts; a visual UI helps inspect trajectories and failure modes.
For practitioners: Prefer GRPO over REINFORCE++ for sparse-reward, long-trajectory agent tasks; curriculum on interaction length offers a simple, robust win; budget compute for post-training and inference sampling before scaling parameters.
7. Talk Isn’t Always Cheap
Multi-agent debate does not always help. Across three reasoning benchmarks and heterogeneous agent pools, debate often lowers accuracy, with stronger models sometimes swayed into worse answers by weaker peers. The authors argue that current alignment makes agents too agreeable, so they adopt persuasive but wrong reasoning instead of challenging it.
Setup. Evaluate debate on CommonSenseQA, MMLU, and GSM8K using GPT-4o-mini, Llama-3.1-8B-Instruct, and Mistral-7B-Instruct. Agents answer once, then debate for two rounds; final output is a majority vote pre- vs post-debate. Prompts require short reasoning and task-specific formats.
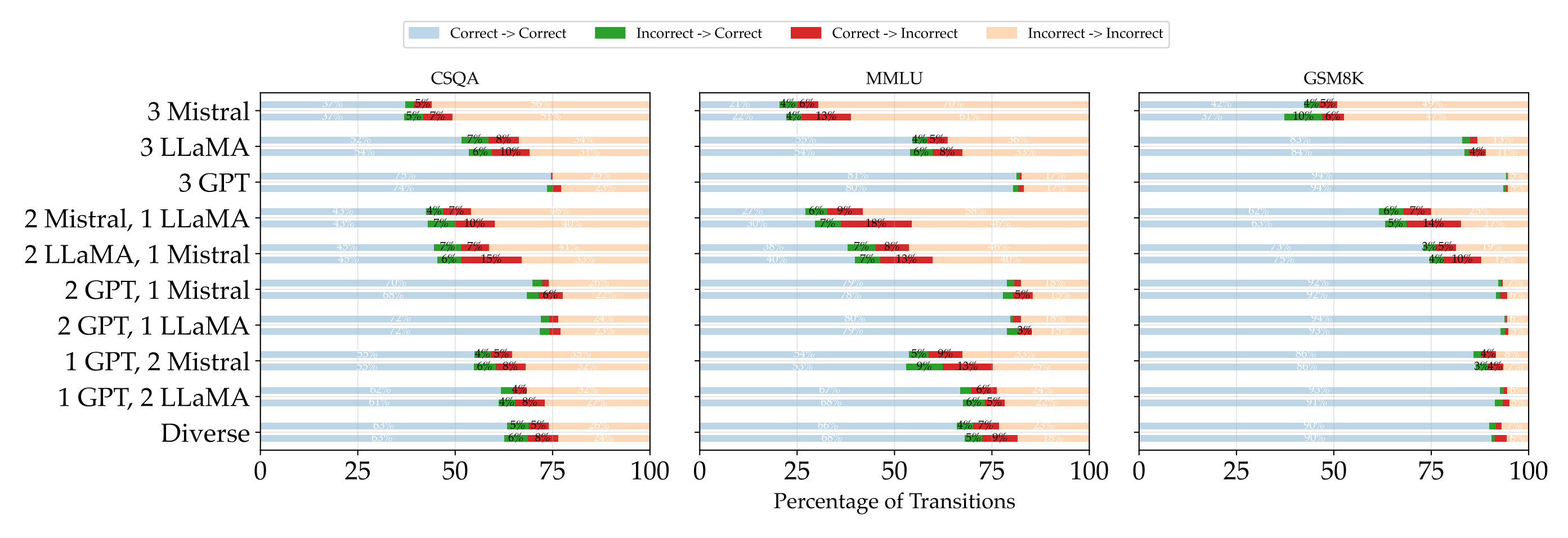
Main result. Debate frequently hurts accuracy, especially on CommonSenseQA and MMLU. They show consistent drops after debate for many groups, including mixed-capability settings: e.g., CSQA falls by 6.6 points for 1×GPT + 2×Llama and by 8.0 points for 2×Llama + 1×Mistral; MMLU drops by 12.0 points for 1×GPT + 2×Llama. GSM8K is more mixed, with small gains in some settings.
Degradation over rounds. This work tracks accuracy across rounds and shows performance often declining as debate proceeds, even when stronger models are in the majority.
Why it happens. Agents tend to favor agreement over critique. They reveal more correct→incorrect flips than incorrect→correct flips across rounds, indicating that debate can actively mislead stronger models. Appendix examples document sycophantic reversals from correct to wrong answers after reading peers.
Implications. Naive debate protocols risk amplifying errors. The authors recommend designs that reward independent verification, weight arguments by agent credibility or confidence, and penalize unjustified agreement to preserve the benefits of discussion.
8. AggLM
AggLM introduces reinforcement learning to train LLMs in aggregating multiple candidate solutions, moving beyond majority voting and reward model ranking. It achieves higher accuracy, recovers minority-correct answers, generalizes across models, and uses fewer tokens than traditional aggregation methods.
9. A Survey of RL for Large Reasoning Models
This survey reviews how reinforcement learning is driving advances in large reasoning models (LRMs), enabling stronger performance on complex tasks like math and coding. It highlights scaling challenges in computation, algorithms, data, and infrastructure, while mapping future directions toward Artificial Superintelligence (ASI).
10. LiveMCP-101
LiveMCP-101 is a new benchmark of 101 real-world queries designed to test MCP-enabled agents on multi-step tasks requiring tool use across search, file ops, math, and data analysis. Results show leading LLMs succeed less than 60%, revealing key weaknesses in tool orchestration and offering insights for advancing autonomous AI systems.
Lot of RL this week
I really enjoyed the SFR-DeepResearch and LiveMCP-101 papers. My only gripe is neither released working code to make evaluation easier.
This is especially frustrating with LiveMCP-101. imo a benchmark is only useful if it can be used ongoing to test new inputs and this benchmark is timely & would have been very useful if they’d released the code. Really odd they didn’t - again imo.