
🥇Top AI Papers of the Week
The Top AI Papers of the Week (November 24 - 30)
1. INTELLECT-3
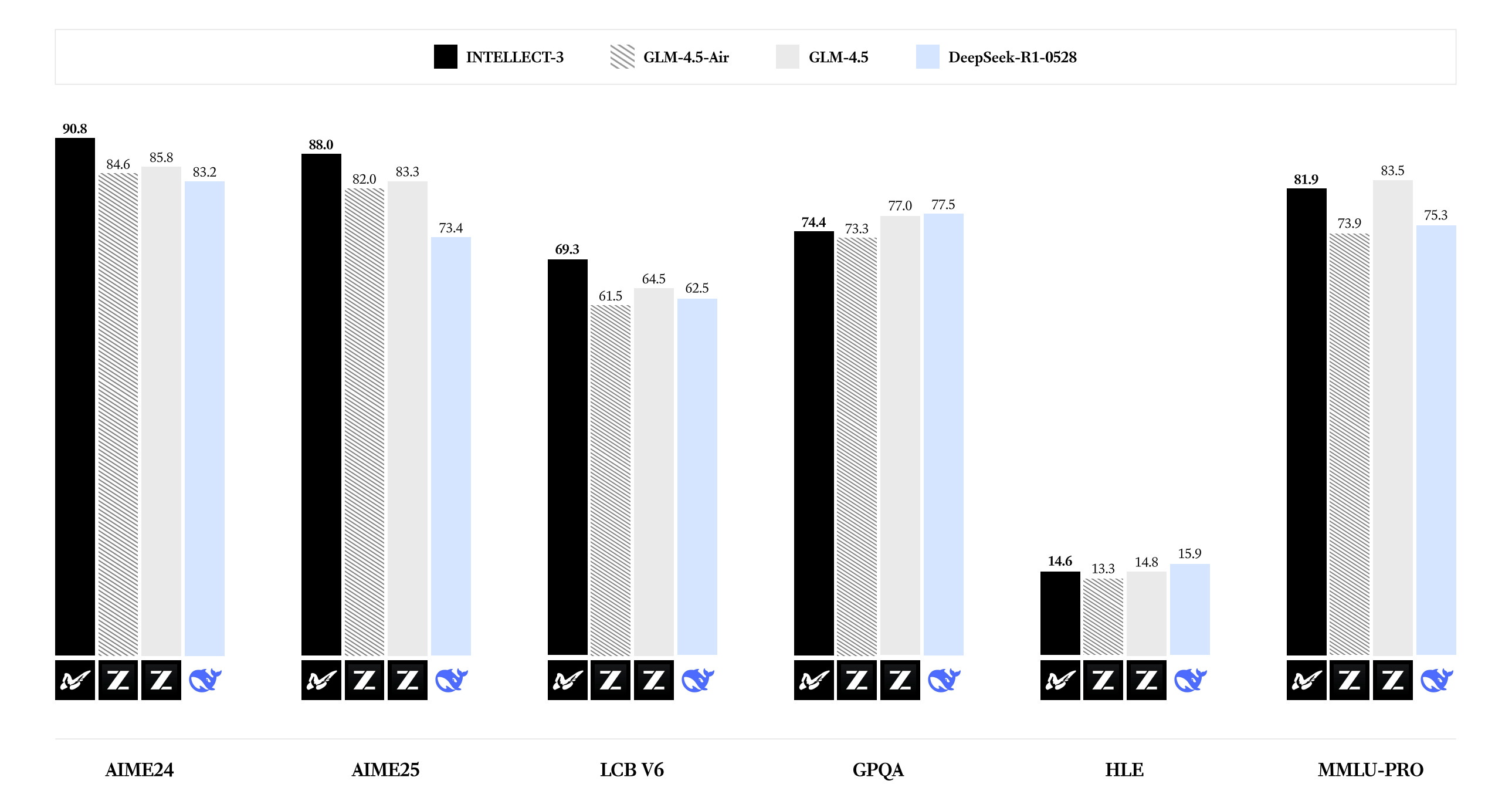
INTELLECT-3 is a 106B-parameter Mixture-of-Experts model (12B active) trained with large-scale reinforcement learning, achieving state-of-the-art performance for its size across math, code, science, and reasoning benchmarks. Built on top of GLM-4.5-Air base, it outperforms many larger frontier models, including DeepSeek R1-0528, and matches GLM-4.6 (which has over 3x the parameters) on key benchmarks.
Frontier benchmark results: Achieves 90.8% on AIME 2024 and 88.0% on AIME 2025, outperforming DeepSeek R1-0528. Scores 69.3% on LiveCodeBench v6, beating GLM-4.5-Air by 8%. Competitive on GPQA Diamond (74.4%), HLE (14.6%), and MMLU-Pro (81.9%).
prime-rl framework: Introduces an open-source asynchronous RL framework with disaggregated trainer and inference, continuous batching with in-flight weight updates, and native support for multi-turn agentic rollouts. Scales seamlessly from single node to 512 H200 GPUs.
Two-stage post-training: Combines supervised fine-tuning on over 200B tokens of reasoning traces (from datasets like OpenReasoning-Math/Code/Science) with large-scale RL across diverse environments, including math, code, science, logic, deep research, and software engineering tasks.
Verifiers and Environments Hub: Open-sources the complete training infrastructure, including the verifiers library for environment design, an Environments Hub with 500+ contributed RL environments, and Prime Sandboxes for high-throughput secure code execution supporting over 4,000 concurrent sandboxes.
Full reproducibility: Releases model weights, complete training recipe, RL framework, and all environments used for training and evaluation. Training ran on 512 H200s over two months with a batch size of 256 prompts and 16 rollouts per prompt at 65K context length.
2. Lightweight End-to-End OCR
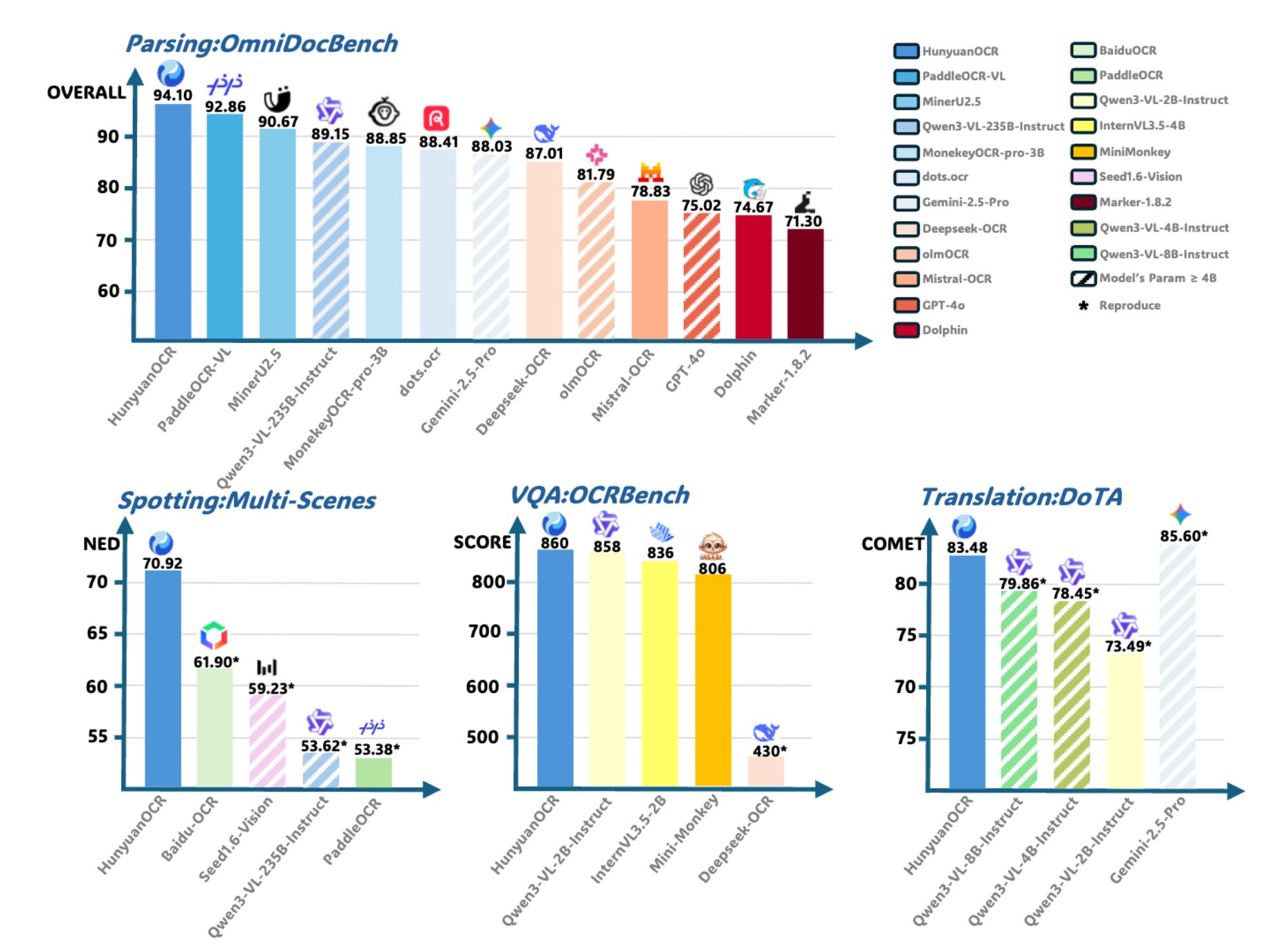
HunyuanOCR is a commercial-grade, open-source, lightweight vision-language model with only 1B parameters designed specifically for OCR tasks. The architecture combines a native-resolution Vision Transformer with a 0.5B-parameter language model through an MLP adapter, outperforming commercial APIs and larger models like Qwen3-VL-4B while achieving state-of-the-art results on OCRBench for models under 3B parameters.
Fully end-to-end architecture: Unlike traditional pipeline-based OCR systems or models requiring separate layout analysis, HunyuanOCR adopts a pure end-to-end paradigm that eliminates error propagation from cascaded processing. This enables complete workflows in a single inference pass, fundamentally resolving issues common in multi-stage systems.
Comprehensive OCR capabilities: Supports text spotting, document parsing, information extraction, visual question answering, and text image translation across 130+ languages in a unified framework. This addresses limitations of narrow OCR expert models and inefficient general VLMs by consolidating diverse capabilities into a compact 1B-parameter architecture.
Data-driven training with RL: Trained on 200M high-quality samples spanning nine real-world scenarios (documents, street views, handwritten text, screenshots, receipts, game interfaces, video frames). First industry demonstration that reinforcement learning (GRPO) yields significant performance gains in OCR tasks, particularly for complex document parsing and translation.
Superior benchmark performance: Won first place in ICDAR 2025 DIMT Challenge (Small Model Track), surpasses MinerU2.5 and PaddleOCR-VL on OmniDocBench for document parsing, exceeds Qwen3-VL-4B in translation and information extraction, and outperforms PaddleOCR 3.0 plus commercial Cloud OCR APIs in text spotting.
Production-ready deployment: Open-sourced on HuggingFace with a high-performance vLLM-based deployment solution. The native-resolution ViT preserves aspect ratios and avoids distortion, making it particularly effective for long-text documents and extreme aspect ratios while maintaining top-tier production efficiency.
Message from the Editor

We are excited to announce our new cohort-based training on Claude Code. Learn to use Claude Code to improve your AI workflows, agents, and apps.
Our subscribers can use BLACKFRIDAY for a 30% discount today. Seats are limited.
3. LatentMAS
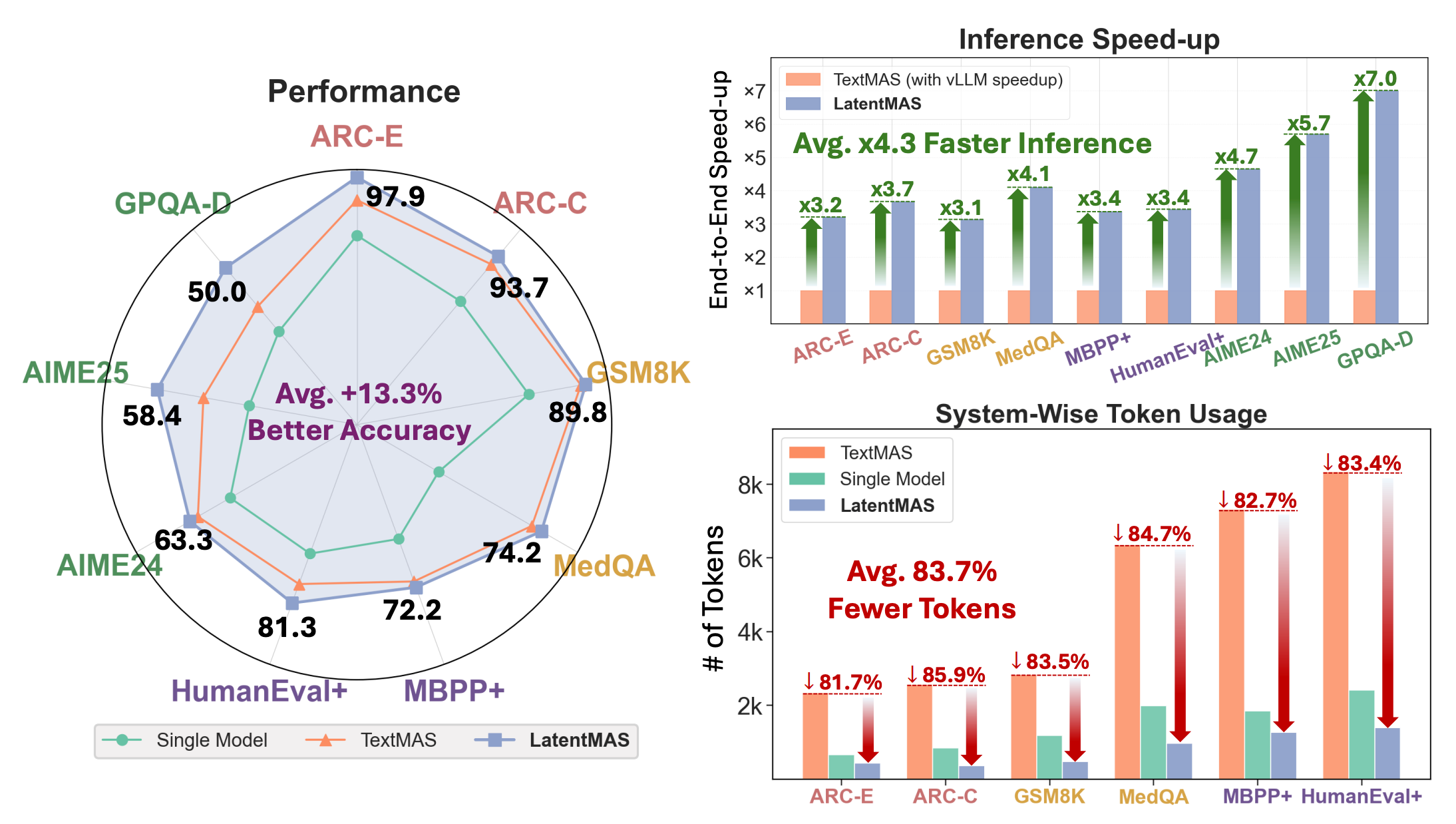
LatentMAS introduces a framework enabling language model agents to collaborate directly within a continuous latent space rather than relying on text-based communication. By using last-layer hidden embeddings and a shared latent working memory, agents preserve and transfer internal representations without information loss from text serialization.
Latent thought generation: Agents perform auto-regressive generation using continuous hidden embeddings instead of discrete tokens. A shared latent working memory stores and transfers internal representations across agents, enabling direct access to each other’s reasoning states without text conversion bottlenecks.
Training-free deployment: The framework requires no additional training or fine-tuning. It works with existing language models by intercepting and sharing hidden states at inference time, making it immediately applicable to current multi-agent systems without retraining costs.
Substantial efficiency gains: Achieves 70.8-83.7% reduction in output token usage and 4x-4.3x faster end-to-end inference speed compared to text-based multi-agent approaches. The latent communication eliminates redundant encoding and decoding cycles that dominate traditional agent collaboration.
Accuracy improvements across benchmarks: Testing across 9 comprehensive benchmarks spanning math and science reasoning, commonsense tasks, and code generation shows up to 14.6% higher accuracy. The lossless information preservation in latent space enables agents to share nuanced reasoning that gets lost in text summarization.
4. OmniScientist
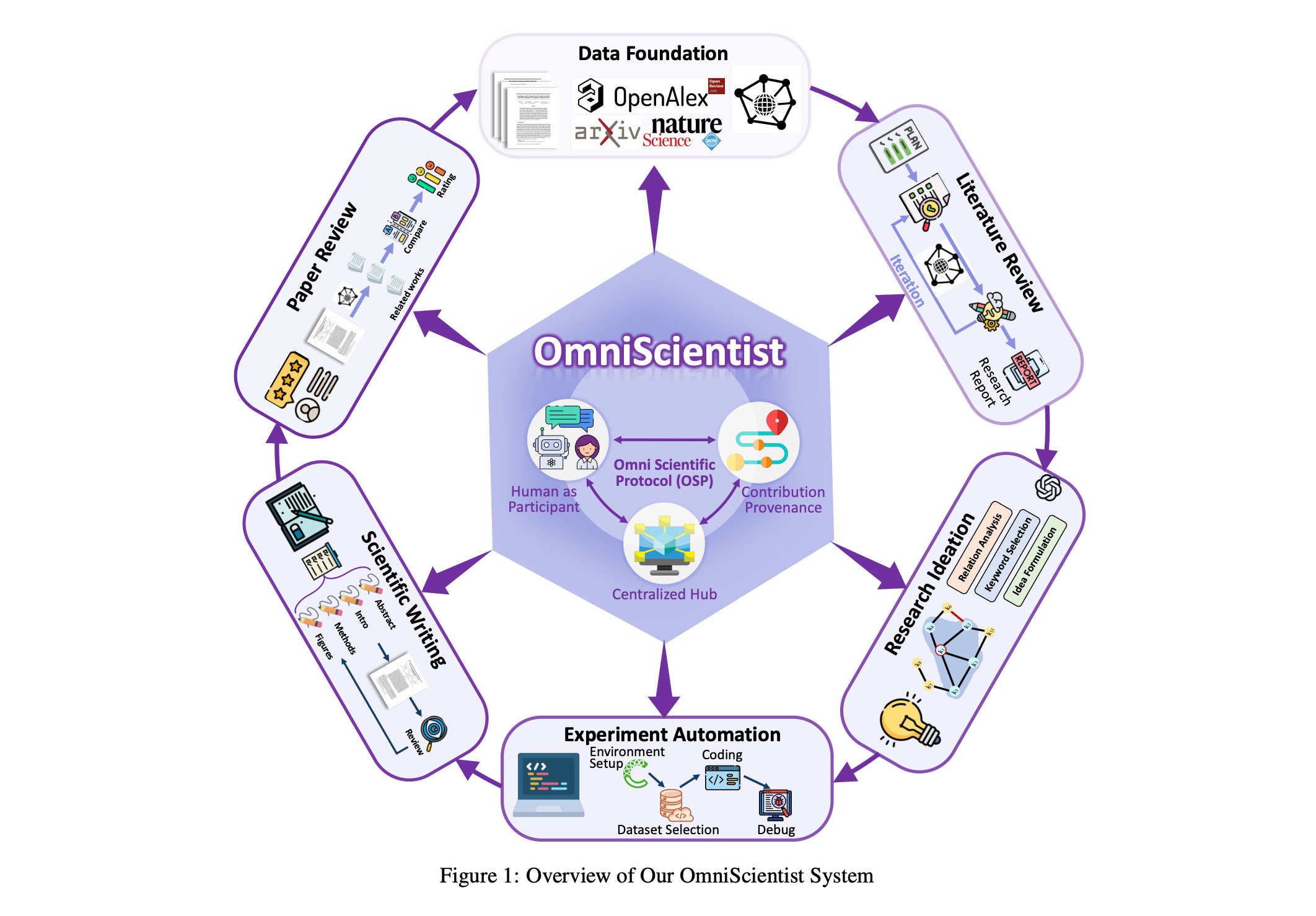
OmniScientist presents an end-to-end framework for building AI scientists capable of autonomously conducting research across the entire scientific lifecycle - from literature review and ideation to experimentation, writing, and peer review. The system establishes a collaborative ecosystem where human and AI scientists co-evolve within a shared scientific environment.
Complete scientific workflow: The framework covers five core research stages: literature review using retrieval and graph-based discovery over 250M+ papers, research ideation powered by 10M+ idea seeds, experiment automation through code generation and lab integration, scientific writing with structured drafting, and paper review via multi-agent critique.
Open Scientific Protocol (OSP): A structured communication standard enabling seamless collaboration between humans and AI agents. OSP defines roles, task formats, and interaction patterns, allowing researchers to delegate subtasks, review outputs, and iteratively refine results while maintaining scientific rigor and reproducibility.
ScienceArena evaluation platform: A comprehensive benchmark suite with 1,500+ expert-verified tasks across multiple disciplines, measuring AI scientists on retrieval accuracy, ideation novelty, experimental correctness, writing quality, and review consistency. Uses blind pairwise voting and Elo rankings for unbiased assessment.
Knowledge infrastructure: Built on citation networks, conceptual relationships, OpenAlex metadata, and arXiv full-texts to help agents understand existing scholarship. The system supports continuous learning through feedback loops and community contributions.
5. InfCode
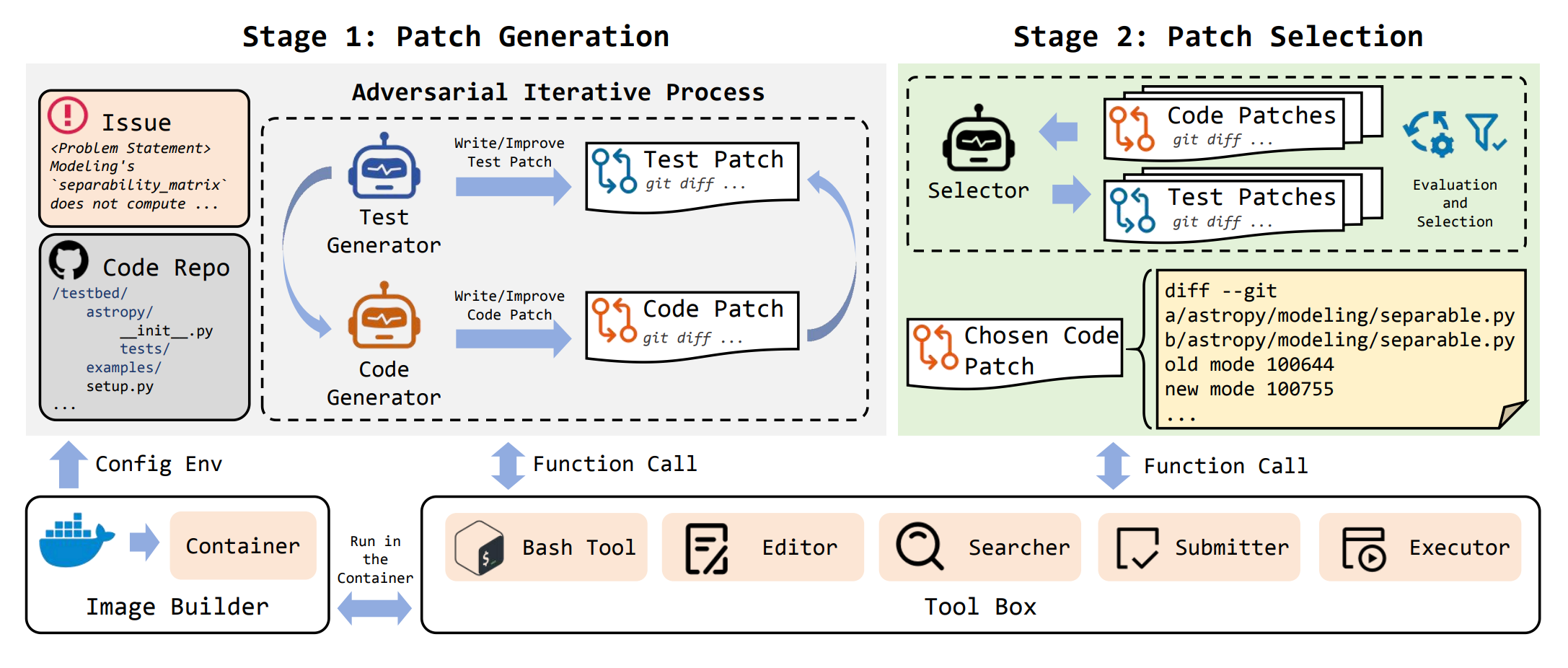
InfCode introduces an adversarial framework for software bug fixing that treats test generation and patch creation as mutually reinforcing processes. Rather than generating patches that simply pass existing tests, the system creates challenging test cases designed to expose patch weaknesses, then iteratively refines patches to handle these adversarial tests.
Adversarial game-theoretic loop: The framework employs an iterative cycle where LLMs first generate tests specifically designed to reveal vulnerabilities in candidate patches, then patches are refined to pass both original and adversarial tests. This cycle repeats until convergence, fundamentally differing from traditional test-driven development with static test suites.
Dynamic edge case discovery: By continuously challenging patches with new adversarial tests, the system achieves superior coverage of potential failure modes. Each iteration exposes corner cases and edge scenarios that single-pass approaches miss, producing solutions more likely to handle real-world complexity.
SWE-Bench Verified evaluation: Testing on the realistic software engineering benchmark using Claude Sonnet 4.5 and DeepSeek models demonstrates measurable improvements in patch reliability. Successive refinement rounds show clear convergence patterns with higher success rates on adversarial test cases compared to baseline methods.
Robust patch generation: The iterative adversarial approach produces more reliable patches than static test-first methodologies. The mutual refinement between tests and patches creates a virtuous cycle where each component strengthens the other, resulting in solutions that better handle unexpected inputs and edge conditions.
6. Evolution Strategies at Hyperscale
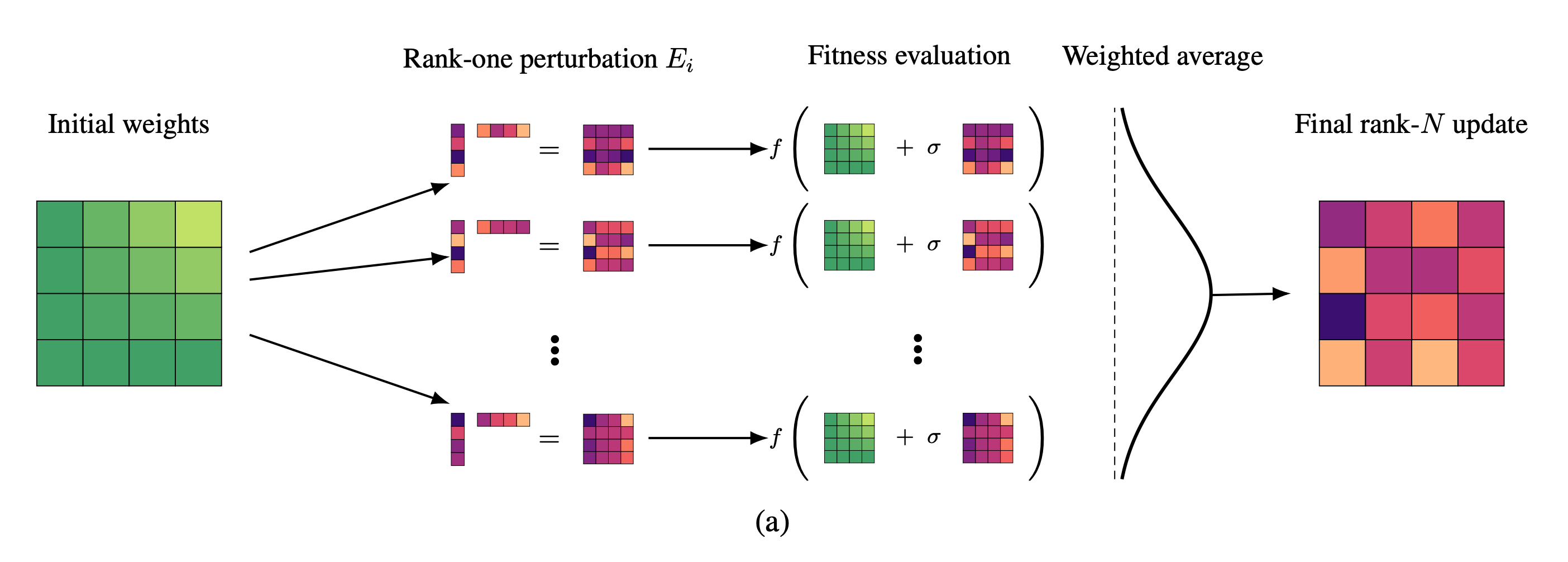
EGGROLL (Evolution Guided General Optimization via Low-rank Learning) is an evolution strategies algorithm designed to scale backprop-free optimization to large population sizes for billion-parameter neural networks. By using low-rank matrix perturbations instead of full-rank ones, EGGROLL achieves a hundredfold increase in training throughput while nearly matching pure batch inference speed.
Low-rank perturbation approach: Instead of sampling full-rank perturbation matrices, EGGROLL generates two smaller random matrices A and B to form low-rank perturbations. This reduces auxiliary storage from mn to r(m+n) per layer and forward pass cost from O(mn) to O(r(m+n)), with theoretical analysis showing the low-rank update converges to full-rank at O(1/r) rate.
Competitive with GRPO for LLM reasoning: On RWKV-7 models fine-tuned for countdown and GSM8K reasoning tasks, EGGROLL outperforms GRPO under the same hardware and wall-clock time. EGGROLL enables 1024 parallel generations per GPU versus GRPO’s 32, achieving 35% validation accuracy compared to 23% on countdown tasks.
Pure integer pretraining demonstration: The paper introduces EGG, a nonlinear RNN language model operating entirely in integer datatypes. EGGROLL enables stable pretraining of this model with population sizes up to 262,144 - two orders of magnitude larger than prior ES work - on a single GPU.
Strong RL performance without compromise: Across 16 reinforcement learning environments, including Brax, Craftax, and Jumanji, EGGROLL matches or outperforms standard OpenES on 14 of 16 tasks while being significantly faster due to efficient batched low-rank adapter inference.
7. Training LLMs with Reasoning Traces
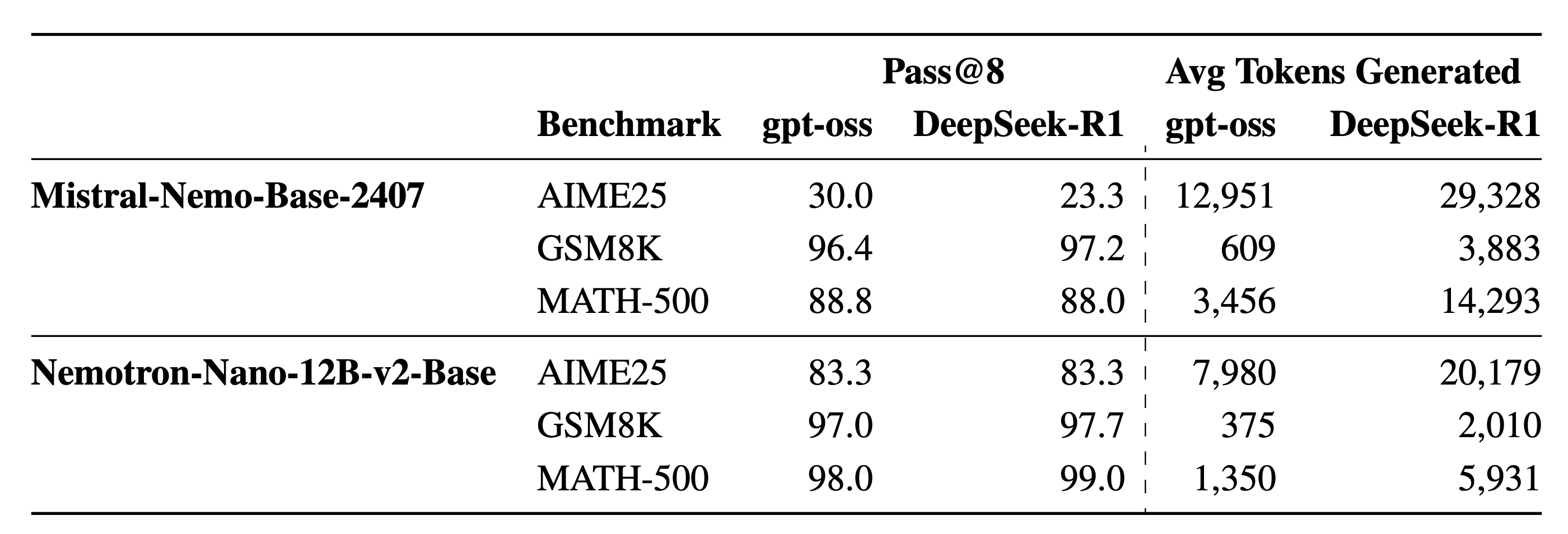
This study investigates how reasoning traces from frontier models like DeepSeek-R1 and GPT-OSS can improve smaller language models through post-training, offering a practical pathway to distill advanced reasoning capabilities without expensive human annotation.
Reasoning trace distillation: Medium-sized LLMs are post-trained on intermediate reasoning traces generated by frontier reasoning models. This leverages test-time scaling insights by capturing the step-by-step problem decomposition that enables advanced models to solve complex tasks methodically.
DeepSeek-R1 vs GPT-OSS comparison: The study directly compares training on reasoning traces from two distinct frontier models, analyzing how trace quality and reasoning style affect downstream performance in the distilled models.
Mathematical reasoning focus: Evaluation centers on mathematical problem-solving benchmarks where explicit reasoning steps provide the clearest signal. Results demonstrate measurable improvements in smaller models trained on high-quality synthetic reasoning data.
Efficiency trade-offs: The work examines the balance between improved accuracy and inference costs, as models trained on reasoning traces may generate longer outputs during inference. This analysis helps practitioners understand when reasoning distillation provides net benefits.
8. Evaluating Honesty and Lie Detection in AI Models
Anthropic researchers evaluate honesty and lie detection techniques across five testbed settings where models generate statements they believe to be false. Simple approaches work best: generic honesty fine-tuning improves honesty from 27% to 65%, while self-classification achieves 0.82-0.88 AUROC for lie detection. The findings suggest coherent strategic deception doesn’t arise easily, as models trained to lie can still detect their own lies when asked separately.
9. Multi-Agent Collaboration for Multimodal LLMs
Microsoft and USC researchers introduce a framework where vision models serve as “eyes” for language models through multi-agent collaboration, enabling modular upgrades without retraining expensive joint vision-language architectures. Specialized vision agents analyze images and communicate findings to language agents through natural language, achieving competitive results on MMMU, MMMU-Pro, and video understanding benchmarks while maintaining full flexibility to swap in improved components independently.
10. Cognitive Foundations for Reasoning in LLMs
Researchers develop a taxonomy of 28 cognitive elements and evaluate 192K reasoning traces from 18 models plus human think-aloud traces, finding that LLMs under-utilize cognitive elements correlated with success while relying on surface-level enumeration rather than human-like abstraction. Test-time reasoning guidance based on the framework improved performance by up to 66.7% on complex problems.