
🥇Top AI Papers of the Week
The Top AI Papers of the Week (September 29 - October 5)
1. Training Agents Inside of Scalable World Models
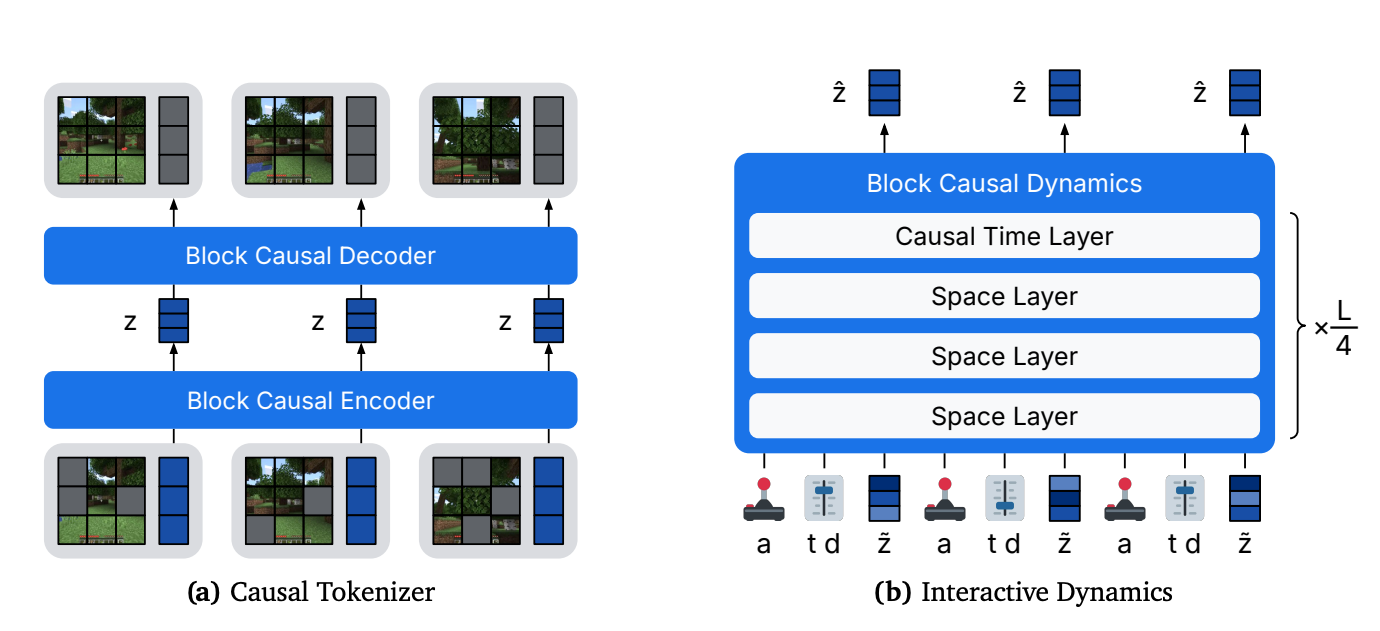
A scalable imagination-RL recipe that learns a fast, accurate Minecraft simulator and trains a controllable agent entirely offline. The world model supports real-time interactive rollouts on a single GPU and enables the first purely offline “get diamonds” result from raw pixels and low-level mouse and keyboard.
Core recipe, built for speed and stability: Causal tokenizer + block-causal dynamics transformer. Shortcut forcing trains the model to take large denoising steps (K=4) while predicting in x-space with a ramped loss, which cuts accumulation errors and preserves quality at low step counts. Space-only and time-only attention layers, temporal layers once every 4, GQA, and alternating long/short batches keep KV cache small and inference fast.
Real-time, longer-context world model that handles mechanics, not just visuals: Interactive inference at 20+ FPS with a 9.6 s context at 640×360, substantially longer than prior Minecraft models. In human-in-the-loop play tests across 16 tasks, Dreamer 4 succeeds on 14, correctly placing/breaking blocks, switching tools, riding boats, using furnaces, and entering portals, whereas Oasis/Lucid miss many object-interaction tasks.
Offline Diamond Challenge, no environment interaction: Trained only on the 2.5K-hour VPT contractor dataset, the agent is conditioned on task tokens and improved via imagination RL (PMPO with a behavioral prior). It reaches iron pickaxe 29 percent and obtains diamonds 0.7 percent within 60-minute episodes, outperforming strong offline baselines like VPT (finetuned) and a Gemma-3 VLA while using about 100× less data than YouTube-pretrained VPT pipelines.
Action grounding from little paired data generalizes OOD: With 2,541 hours of video but only 100 hours with actions, the model reaches roughly 85 percent PSNR and 100 percent SSIM of the full-action model on action-conditioned prediction. Action conditioning trained only on the Overworld transfers to Nether/End scenes seen without actions, achieving about 76 percent PSNR and 80 percent SSIM of the all-actions model.
Agent finetuning and imagination RL that stay consistent with the model: Task tokens are interleaved with latents, actions, and registers. Heads predict policy, reward, and value with multi-token prediction. Imagination rollouts sample from the frozen world model, and PMPO optimizes sign-based advantages with a reverse-KL to a cloned BC policy, improving robustness and sample efficiency without online data.
2. DeepSeek-V3.2-Exp
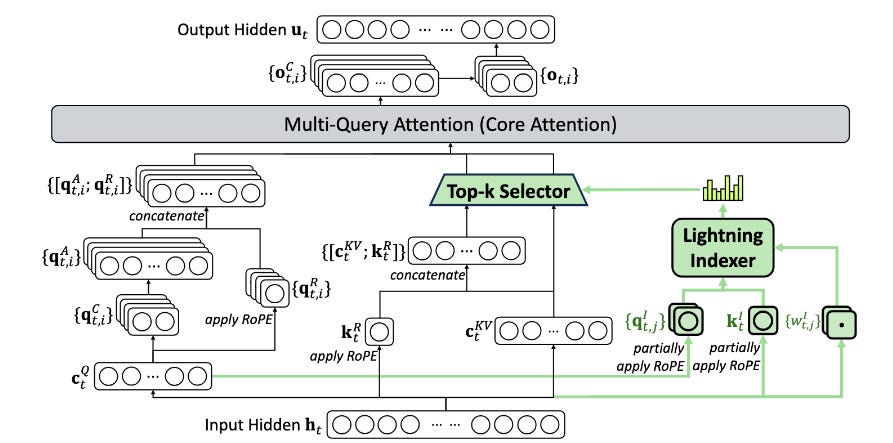
DeepSeek adds a fine-grained sparse attention mechanism (DeepSeek Sparse Attention, DSA) to the V3.1 “Terminus” backbone and shows large cost reductions on 128K context without notable quality loss. Model and inference code are released.
DSA design: a tiny FP8 “lightning indexer” scores past tokens per query, then a top-k selector fetches only those KV entries for the main attention. This changes core attention from O(L²) to approximately O(L·k) for the main path while keeping the indexer lightweight.
Training recipe: start from the 128K V3.1 checkpoint. Warm-up with dense attention while training only the indexer via KL to the dense attention distribution (about 2.1B tokens). Switch to sparse training and optimize all weights with k=2048 selected KV tokens per query (≈944B tokens). Post-train with the same pipeline as V3.1 to isolate DSA’s impact.
Post-training stack: specialist distillation for five domains (math, competitive programming, logical reasoning, agentic coding, agentic search) plus writing and QA, then a single mixed RL stage using GRPO to balance reasoning, agent behavior, and alignment. The RL design uses outcome rewards, length penalties, and language-consistency rewards.
Results: quality tracks V3.1 across general, code, search-agent, and math suites. Table 1 shows near-parity on most metrics, with small drops on GPQA/HLE/HMMT that vanish when using checkpoints with similar token lengths. RL curves for BrowseComp and SWE Verified remain stable with DSA.
Cost and latency: The work shows clear end-to-end token-position cost reductions for both prefilling and decoding at long contexts. For short prefills, they provide a masked MHA path to simulate DSA efficiently. Overall effect: significantly cheaper long-context service while preserving accuracy.
3. The Era of Real-World Human Interaction
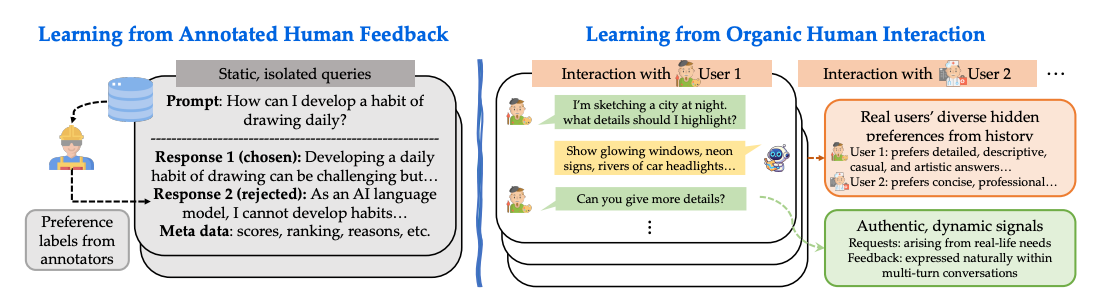
This work presents a post-training recipe that learns directly from real user conversations instead of static annotator labels. RLHI combines user-guided rewrites (using follow-ups as corrections) with persona-based rewards (ranking sampled candidates via a persona-conditioned reward model). Trained on WildChat conversations, it shows strong improvements in personalization, instruction following, and even transfers to reasoning tasks.
Personas are distilled from long-term user histories and prepended at inference; training uses persona-conditioned DPO on rewrites and reward-ranked pairs.
Real chats contain rich correction signals, especially in later turns, providing dense supervision.
On WildChat-based evaluation, rewrites improve personalization and preference, while persona-based rewards lead in instruction following.
Benchmarks show strong results: 77.9% win rate on AlpacaEval 2.0, competitive on Arena-Hard, and reasoning accuracy rising from 26.5 to 31.8 across math/science datasets.
Key ablations: RL > SFT for interaction data, strong quality filters are essential, and user diversity matters more than depth per user.
Next steps include online continual learning, safer reward modeling, and privacy-preserving personalization.
4. Rethinking JEPA
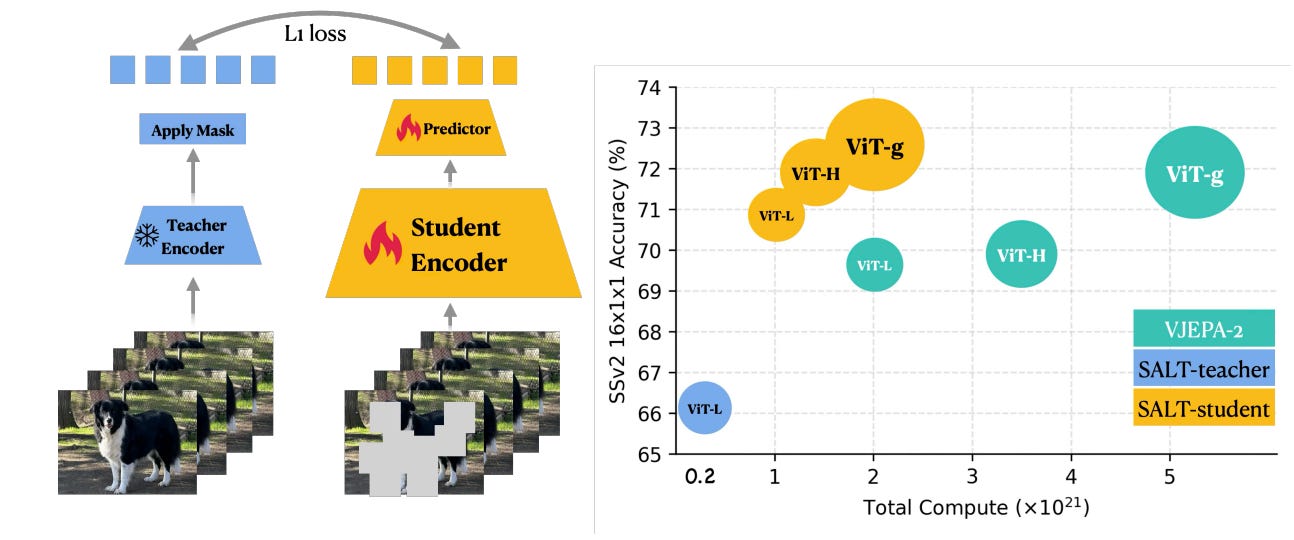
Apple proposes SALT (Static-teacher Asymmetric Latent Training), a simple 2-stage V-JEPA alternative that first trains a teacher with pixel reconstruction, then freezes it and trains a student to predict the teacher’s latents on masked regions. It removes EMA, decouples teacher and student, and gives a cleaner model selection while being more compute-efficient.
Recipe that scales without EMA: Stage 1: train a video encoder with a VideoMAE-style pixel reconstruction objective but using V-JEPA’s multi-block masking (called V-Pixel). Stage 2: freeze that encoder and train a student encoder+predictor to match the teacher’s latents on masked regions. Both losses are proper and stable, eliminating the collapse machinery.
Better frozen-backbone results at lower compute: At matched pretraining steps on the V-3.6M mix, SALT improves average Top-1 over V-JEPA 2 and scales well with student size. The ViT-g/G SALT students top SSv2 and are competitive on K400.
Weak teacher, strong student: Students trained by small or sub-optimal teachers still become SOTA-level. The best ViT-L student uses only a ViT-L teacher, and even a ViT-G student peaks with a ViT-L teacher.
An actually useful training signal: Unlike EMA JEPA, where loss is a poor proxy, SALT’s student training loss correlates tightly with downstream frozen accuracy, enabling interpretable model selection during pretraining.
Masking and data choices that matter: For the teacher, multi-block masking beats random tubes and causal masking. The data mix is robust: K710-only or Panda2.8M-only teachers still yield strong students, with V-3.6M best overall.
5. Agent S3
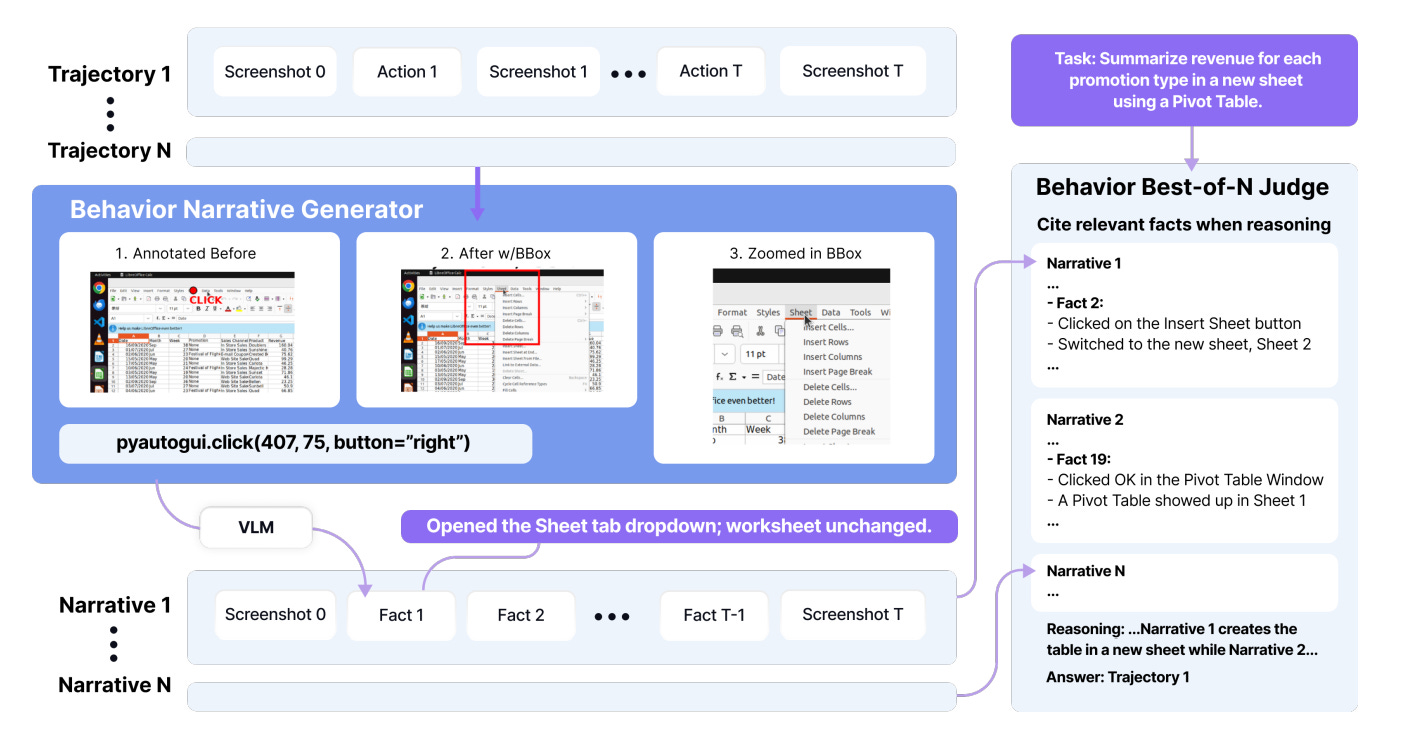
The paper introduces Behavior Best-of-N (bBoN): run many full CUAs in parallel, convert each rollout into a compact behavior narrative, then do comparative selection to pick the best trajectory. With a stronger base agent (Agent S3), this sets the state of the art on OSWorld and generalizes to Windows and Android.
Behavior Best-of-N: sample multiple complete rollouts, summarize each with before/after deltas and pointer crops, and select the winner via a one-shot MCQ judge.
Agent S3 baseline: a flatter loop with an integrated coding sub-agent increases success and cuts LLM calls and wall time compared to Agent S2.
Results: new SoTA on OSWorld at 100 steps, with strong gains in efficiency, and the approach transfers to Windows and Android setups.
Scaling: accuracy rises as N grows, model diversity improves Pass@N, and single-round comparative selection matches or beats pairwise tournaments at lower cost.
Practical takeaways: spin up parallel VMs from the same snapshot, instrument steps to emit verifiable deltas, start with N around 4 to 10, and add diverse strong models if budget allows.
Limitation: assumes independent parallel runs; shared real-desktop side effects can leak across attempts.
6. DeepSearch
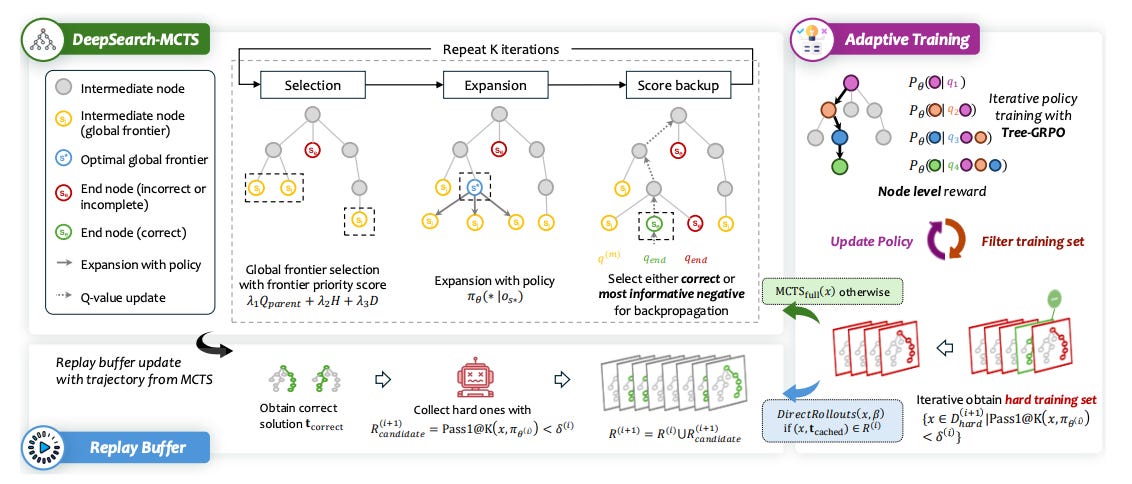
DeepSearch integrates Monte Carlo Tree Search directly into RL with verifiable rewards, but during training rather than only at inference. The result is broader exploration, better credit assignment, and higher sample efficiency on math reasoning vs strong 1.5B baselines.
Train-time search, not just test-time: MCTS is embedded in the RL loop with two selectors: local UCT for sibling comparison and a global frontier scorer to pick the next leaf across the whole tree. The frontier score combines parent quality, policy entropy, and a depth bonus √(d/dT).
Supervise both wins and “confident wrong” paths: If no correct terminal is found, DeepSearch picks the negative trajectory with the lowest average entropy along the path for supervision. It backs up node values with a constrained update so nodes on correct paths remain non-negative. This yields fine-grained, step-level advantages instead of only outcome rewards.
Tree-GRPO objective plus q-value soft clipping: Advantages use node-level q(s) with mean-only normalization, clip-higher PPO style ratios, and tanh soft clipping of intermediate q to avoid explosion while keeping gradients smooth. Terminal rewards stay ±1.
Adaptive efficiency: filter hard items and cache solutions: Iteratively filter to a “hard subset” using Pass1@K thresholds, keep a replay buffer of verified solutions, and skip full search when a cached correct trajectory exists. This preserves knowledge and saves compute.
Results - better accuracy with far less compute: On AIME24/25, AMC23, MATH500, Minerva, Olympiad, DeepSearch-1.5B averages 62.95%, topping Nemotron-Research-Reasoning-Qwen-1.5B v2 by +1.25 pp (Table 1 on page 7). With only +50 RL steps, it uses about 330 GPU hours, beating extended training that plateaus at 62.02% after 1,883 GPU hours. Ablations show global frontier selection improves reward and cuts iterations vs vanilla UCT, and the final gains accrue from the combo of new q-backup, node-level advantages, mean-only normalization, and frontier selection.
7. Accelerating Diffusion LLMs

A lightweight, learned policy speeds up diffusion-based LLM decoding by deciding which tokens are already “final” and when to stop generation. The authors train a tiny MLP filter on token confidence signals and add an End-of-Text Prediction that halts decoding as soon as [EoT] is reliably produced. On LLaDA-8B-Instruct, this reaches large throughput gains with minimal or no accuracy loss.
Problem and insight: Semi-autoregressive diffusion LLMs parallelize token updates, but static heuristics keep remasking already-correct tokens. The paper defines an oracle strategy, Extremely Greedy Parallel, that unmasks tokens immediately upon correct prediction and shows big headroom for speedup.
Method: Learn2PD filter: Train a 2-layer MLP filter fθ on token confidence patterns to predict “finalize or remask” per position. Only the filter is trained with BCE loss; the dLLM stays frozen. Inference applies a threshold τ to the filter’s logits to commit tokens.
Stop early with EoTP: End-of-Text Prediction halts once [EoT] is decoded, avoiding long tails filled with [EoT]. Appendix B notes about 89.59% of extra compute at length 1024 comes from post-EoT padding.
Results: On GSM8K, MATH, HumanEval, and MBPP, Learn2PD alone yields 3–12× speedup depending on length; Learn2PD+EoTP reaches 22.58× at length 1024 on GSM8K with accuracy preserved or slightly improved. Combining with KV cache further boosts throughput to 57.51× with small accuracy tradeoffs. Longer sequences benefit more; Table 4 shows acceleration grows from 3.36× at length 128 to 22.58× at 1024.
Engineering notes: The filter is tiny and quick to train: for block size 32 it has ~2k parameters, trained in minutes on a single T4 after a short data collection pass. Overhead at inference is negligible relative to gains. Method is orthogonal to KV caching and slotting into existing dLLM decoders is straightforward.
8. Reasoning Traces Tailored for Small Models
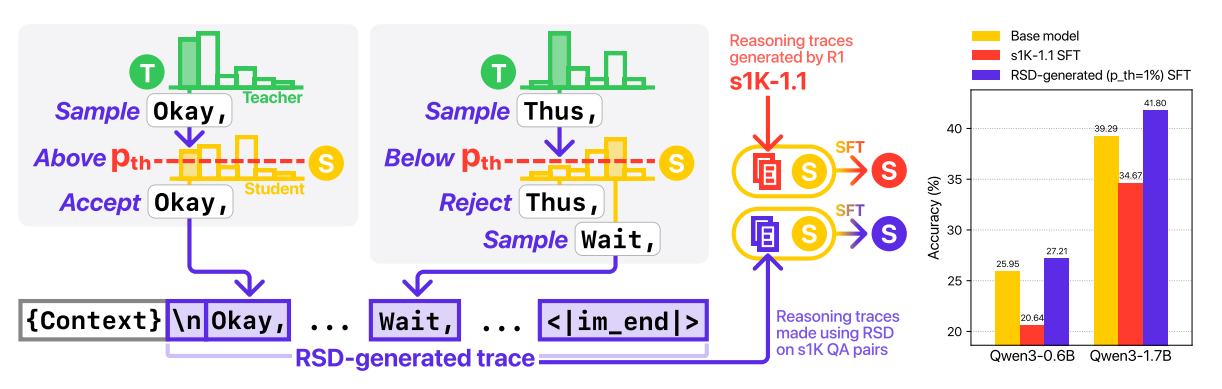
Small models often get worse when you SFT them on long, high-quality CoT from big teachers. This paper pinpoints why and fixes it with Reverse Speculative Decoding (RSD): let the teacher propose tokens, but let the student approve them only if they are probable under the student. Result: traces that stay correct while matching the student’s distribution, which small models can actually learn from.
Core idea: At each step, sample a teacher token and keep it only if the student assigns ≥ p_th probability, else fall back to the student’s own token. This filters high-surprisal spikes that small models cannot track, smoothing token-level difficulty without simplifying the logic.
Why it matters: Direct SFT of Qwen3-0.6B on s1K-1.1 traces hurts average accuracy by 20.5%. Training on RSD traces instead yields +4.9% average gains across AIME24, AIME25, GPQA-Diamond, MATH500.
Data recipe that works for tiny models: Use a tokenizer-compatible teacher (s1.1-7B) and student (Qwen3-0.6B). Generate RSD traces with rejection sampling; when a problem cannot be solved, salvage the first 128 tokens via UPFT-style prefix training. Despite only 180 full solutions and many prefixes, the 0.6B student improves, showing that distributional alignment beats volume.
Key diagnostic: The strongest failure predictor is the share of sub-1% tokens under the student. s1K-1.1 traces contain many such tokens and degrade learning; RSD cuts these to near zero.
Not universal, must be tailored: RSD traces are model-specific. Traces built with Qwen3-0.6B as the “approver” do not transfer to Qwen3-1.7B, Llama-3.2-1B, Gemma-3-1B, or Phi-4-Mini. Running RSD per target model helps, but repeated multi-step RSD on the same model degrades performance via distributional drift.
9. Tool-Use Mixture (TUMIX)
TUMIX is an ensemble recipe for reasoning that mixes text, code execution, and web search, running 15 diverse agents in parallel and passing intermediate answers across rounds. An LLM-judge controls early stopping, giving up to +3.55% accuracy gains over strong tool-augmented baselines on HLE, GPQA-Diamond, and AIME 24/25 while cutting inference cost by ~50%.
10. PrompCoT 2.0
PromptCoT 2.0 introduces an EM-based loop for synthesizing harder and more diverse reasoning prompts, replacing manual heuristics from PromptCoT 1.0. It enables both self-play and SFT training regimes, achieving new SOTA on reasoning benchmarks like AIME, HMMT, LiveCodeBench, and Codeforces, showing prompt synthesis as a new scaling axis for LLM reasoning.