
🥇Top AI Papers of the Week
The Top AI Papers of the Week (July 28 - August 3)
1. AlphaEarth Foundations
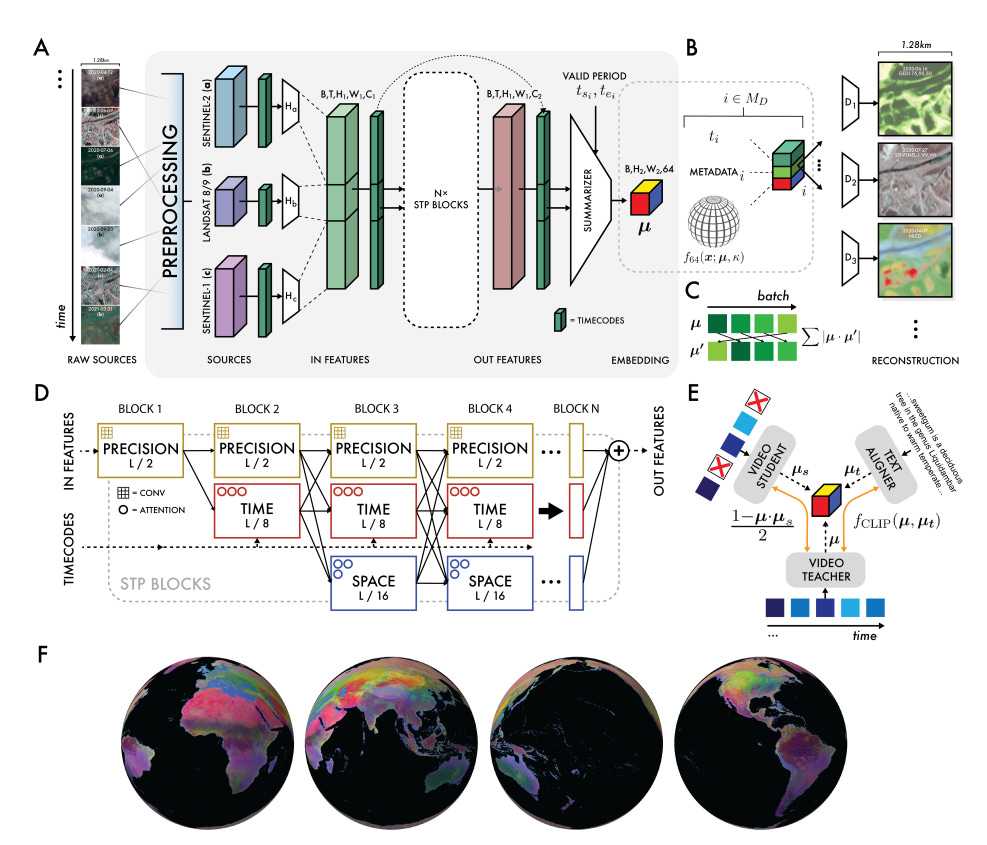
AlphaEarth Foundations (AEF) introduces a task-agnostic geospatial foundation model that learns a compact, time-continuous embedding field of Earth’s surface. AEF is designed to produce accurate, high-resolution (10m²) map representations from sparse geolocated labels and remote sensing data. Its key innovation lies in producing universal, analysis-ready embeddings that outperform both traditional feature engineering methods and other learned approaches across diverse mapping tasks.
AEF combines over 3 billion observations from 10 geospatial data sources, including Sentinel-1/2, Landsat, GEDI, GRACE, and Wikipedia, to generate 64-byte embeddings via a temporal bottleneck architecture. It supports continuous-time modeling with time-conditional summarization and decoding, including for previously unseen time intervals.
AEF embeddings consistently outperform prior state-of-the-art across 15 evaluation tasks spanning thematic mapping, biophysical variable estimation, and change detection. In the max-trial setting, AEF reduces error magnitude by 23.9% on average compared to the best prior methods, with gains also holding in 1-shot and 10-shot regimes.
The model architecture leverages a Space-Time-Precision (STP) encoder combining spatial self-attention, time-axial attention, and convolutional precision blocks. A variational bottleneck modeled as von Mises-Fisher distributions enforces spatial precision and smooth embedding manifolds.
Evaluations include detailed benchmarks like US tree genus classification (39 classes), evapotranspiration regression, crop type mapping, and land use change detection. AEF was the only method to explain evapotranspiration (R² = 0.58), and it achieved >78% accuracy on supervised change detection tasks.
Ablations show that increasing both the number and diversity of input sources improves performance, with diminishing returns past radar or environmental data. AEF also maintains performance under aggressive 8-bit quantization, enabling efficient storage and deployment.
Editor Message
I am launching a new hybrid course on building effective AI Agents with n8n. If you are building and exploring with AI agents, you don’t want to miss this one!
2. Geometric-Mean Policy Optimization

Introduces a stabilized alternative to Group Relative Policy Optimization (GRPO), which is widely used to improve reasoning capabilities in large language models via reinforcement learning. GRPO optimizes the arithmetic mean of token-level rewards but suffers from training instability due to extreme importance sampling ratios. GMPO addresses this by instead maximizing the geometric mean of token-level rewards, leading to more stable updates.
GMPO reduces the impact of outlier tokens by leveraging the geometric mean, which naturally downweights extreme importance-weighted rewards and leads to narrower sampling ratio distributions and lower gradient variance.
The method introduces token-level clipping of importance sampling ratios (rather than sequence-level) and allows for a wider clipping range, encouraging greater policy exploration without sacrificing stability. The chosen range (e⁻⁰.⁴, e⁰.⁴) achieves the best performance tradeoff.
Across five math benchmarks (AIME24, AMC, MATH500, Minerva, OlympiadBench) and one multimodal benchmark (Geometry3K), GMPO outperforms GRPO with a +4.1% Pass@1 gain in reasoning tasks and +1.4% in multimodal reasoning using 7B models.
Theoretical and gradient analysis show that GMPO yields more robust and balanced updates. Empirically, it maintains higher token entropy and smaller KL divergence from the base model, reflecting better exploration and training stability.
Ablation studies confirm the effectiveness of the geometric mean, token-level clipping, and normalization in achieving improved performance and stable training behavior.
3. GEPA
Introduces a new optimizer, GEPA, that adaptively improves prompts for compound AI systems using natural language reflection and Pareto-based search. Rather than relying on reward gradients from traditional RL, GEPA explicitly reasons over LLM execution traces and feedback to evolve better prompts, dramatically increasing sample efficiency and final performance.
GEPA works by iteratively sampling trajectories from an LLM system, reflecting in natural language to identify issues, proposing new prompt edits, and combining successful strategies via a genetic Pareto search. It maintains a pool of diverse prompt candidates along a Pareto frontier to prevent local optima and encourage generalization.
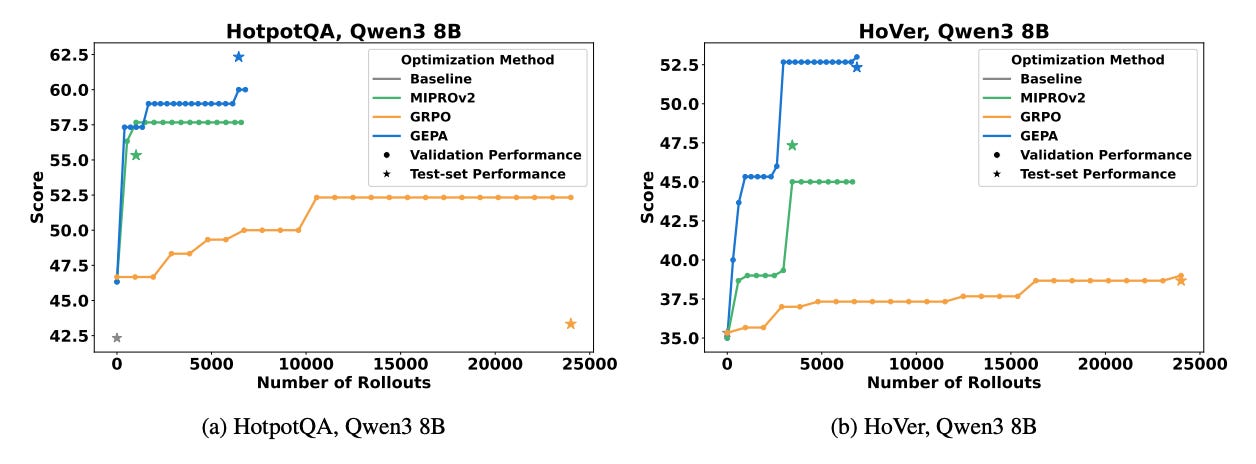
Across four benchmarks, HotpotQA, IFBench, PUPA, and HoVer, GEPA outperforms the strong RL baseline GRPO by up to 20% and requires up to 35× fewer rollouts. It also surpasses the previous state-of-the-art prompt optimizer MIPROv2 by 10–14%, while producing shorter, more efficient prompts that generalize better across tasks and models.
A key innovation is GEPA’s use of reflective prompt mutation, where it explicitly uses an LLM to rewrite a module’s prompt based on failure traces and evaluation diagnostics. This enables targeted improvements after very few training examples, as visualized in optimization trees.
GEPA also introduces a system-aware merge strategy that combines independently evolved prompt modules from different lineages. While this improved performance with GPT-4.1-mini, gains were more modest with Qwen3-8B, highlighting the importance of model-specific tuning.
Finally, GEPA shows early promise as an inference-time search strategy. In code optimization benchmarks like NPUEval and KernelBench, it significantly boosts performance (e.g., from 4.25% to 30.52% vector utilization on NPUs) by reflecting on compiler errors and updating code-generation prompts accordingly.
4. Group Sequence Policy Optimization
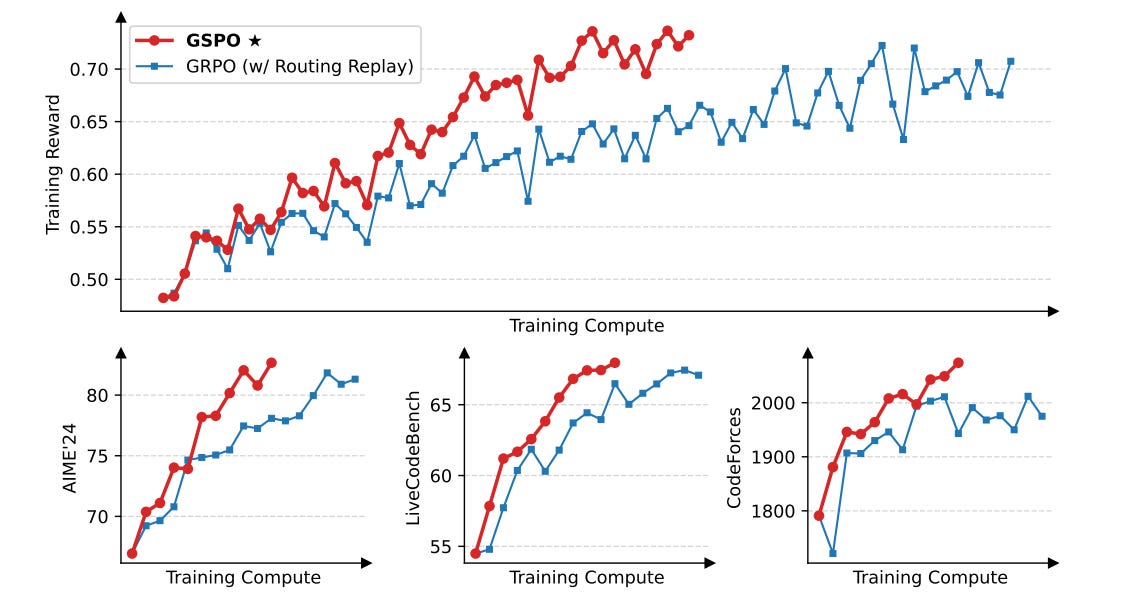
This paper introduces GSPO, a new RL algorithm designed to improve the training of large language models, particularly under high compute and long-sequence regimes. Unlike GRPO, which applies token-level importance weights, GSPO performs optimization entirely at the sequence level, aligning the unit of reward with the unit of optimization to resolve instability and inefficiency in large-scale RL training.
Core idea: GSPO replaces token-level importance ratios with a sequence-level formulation based on normalized likelihood ratios, avoiding the variance explosion and misaligned updates that plague GRPO during long-sequence training.
Training stability and performance: GSPO eliminates the need for a value model (as in PPO) or token-wise reweighting (as in GRPO), and leads to more stable convergence, even in challenging Mixture-of-Experts (MoE) settings, by clipping entire responses rather than individual tokens. This results in significantly better training efficiency despite higher clipping rates (15% vs 0.13% for GRPO).
No need for Routing Replay: In MoE models, token-level importance ratios fluctuate due to routing volatility. GRPO requires Routing Replay to maintain consistent expert paths across updates. GSPO sidesteps this by relying on the sequence-level likelihood, which is more stable and obviates the need for additional stabilization tricks.
Infrastructure simplicity: Since GSPO only requires sequence-level likelihoods, it is more tolerant of numerical differences between inference and training engines. This allows for greater flexibility in infrastructure (e.g., using inference engine outputs directly), particularly in multi-turn or disaggregated RL settings.
5. Graph-R1
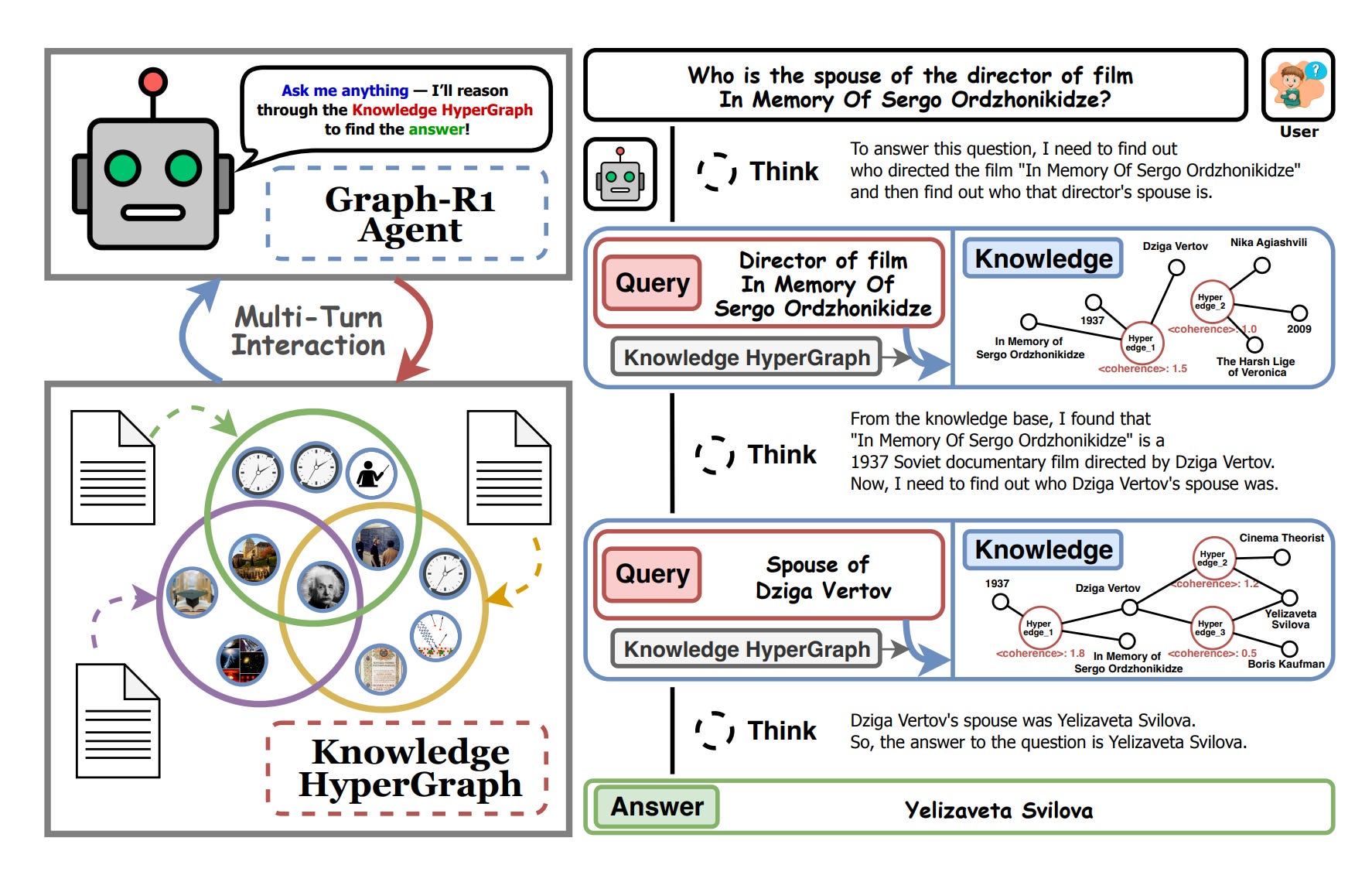
Introduces a novel RAG framework that moves beyond traditional one-shot or chunk-based retrieval by integrating graph-structured knowledge, agentic multi-turn interaction, and RL. The core goal is to improve factual accuracy, retrieval efficiency, and reasoning quality in knowledge-intensive tasks.
The authors design Graph-R1, an agent that reasons over a knowledge hypergraph environment by iteratively issuing queries and retrieving subgraphs using a multi-step “think-retrieve-rethink-generate” loop. Unlike prior GraphRAG systems that perform fixed retrieval, Graph-R1 dynamically explores the graph based on evolving agent state.
Retrieval is modeled as a dual-path mechanism: entity-based hyperedge retrieval and direct hyperedge similarity, fused via reciprocal rank aggregation to return semantically rich subgraphs. These are used to ground subsequent reasoning steps.
The agent is trained end-to-end using Group Relative Policy Optimization (GRPO) with a composite reward that incorporates structural format adherence and answer correctness. Notably, rewards are only granted if reasoning follows the proper format, encouraging interpretable and complete reasoning traces.
On six RAG benchmarks (e.g., HotpotQA, 2WikiMultiHopQA), Graph-R1 achieves state-of-the-art F1 and generation scores, outperforming prior methods including HyperGraphRAG, R1-Searcher, and Search-R1. It shows particularly strong gains on harder, multi-hop datasets and under OOD conditions.
Ablation studies confirm that Graph-R1’s performance degrades sharply without its three key components: hypergraph construction, multi-turn interaction, and RL. Theoretical analyses support that graph-based and multi-turn retrieval improve information density and accuracy, while end-to-end RL bridges the gap between structure and language.
6. Hierarchical Reasoning Model
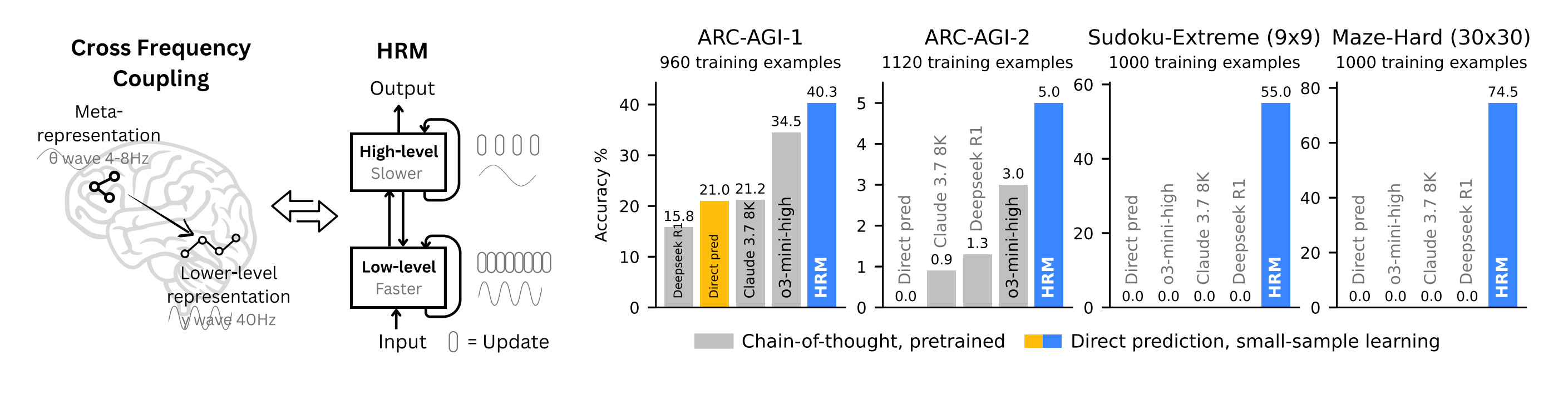
Hierarchical Reasoning Model (HRM) is a novel, brain-inspired architecture that replaces CoT prompting with a recurrent model designed for deep, latent computation. It departs from token-level reasoning by using two coupled modules: a slow, high-level planner and a fast, low-level executor, achieving greater reasoning depth and efficiency with only 27M parameters and no pretraining. Despite its small size and minimal training data (~1k examples), HRM solves complex tasks like ARC, Sudoku-Extreme, and 30×30 maze navigation, where CoT-based LLMs fail.
HRM introduces hierarchical convergence, where the low-level module rapidly converges within each cycle, and the high-level module updates only after this local equilibrium is reached. This allows for nested computation and avoids premature convergence typical of standard RNNs.
A 1-step gradient approximation sidesteps memory-intensive backpropagation-through-time (BPTT), enabling efficient training using only local gradient updates, grounded in deep equilibrium models.
HRM implements adaptive computation time using a Q-learning-based halting mechanism, dynamically allocating compute based on task complexity. This allows the model to “think fast or slow” and scale at inference time without retraining.
Experiments on ARC-AGI, Sudoku-Extreme, and Maze-Hard show that HRM significantly outperforms larger models using CoT or direct prediction, even solving problems that other models fail entirely (e.g., 74.5% on Maze-Hard vs. 0% for others).
Analysis reveals that HRM learns a dimensionality hierarchy similar to the cortex: the high-level module operates in a higher-dimensional space than the low-level one (PR: 89.95 vs. 30.22), an emergent trait not present in untrained models.
7. Where to show demos in your prompt?
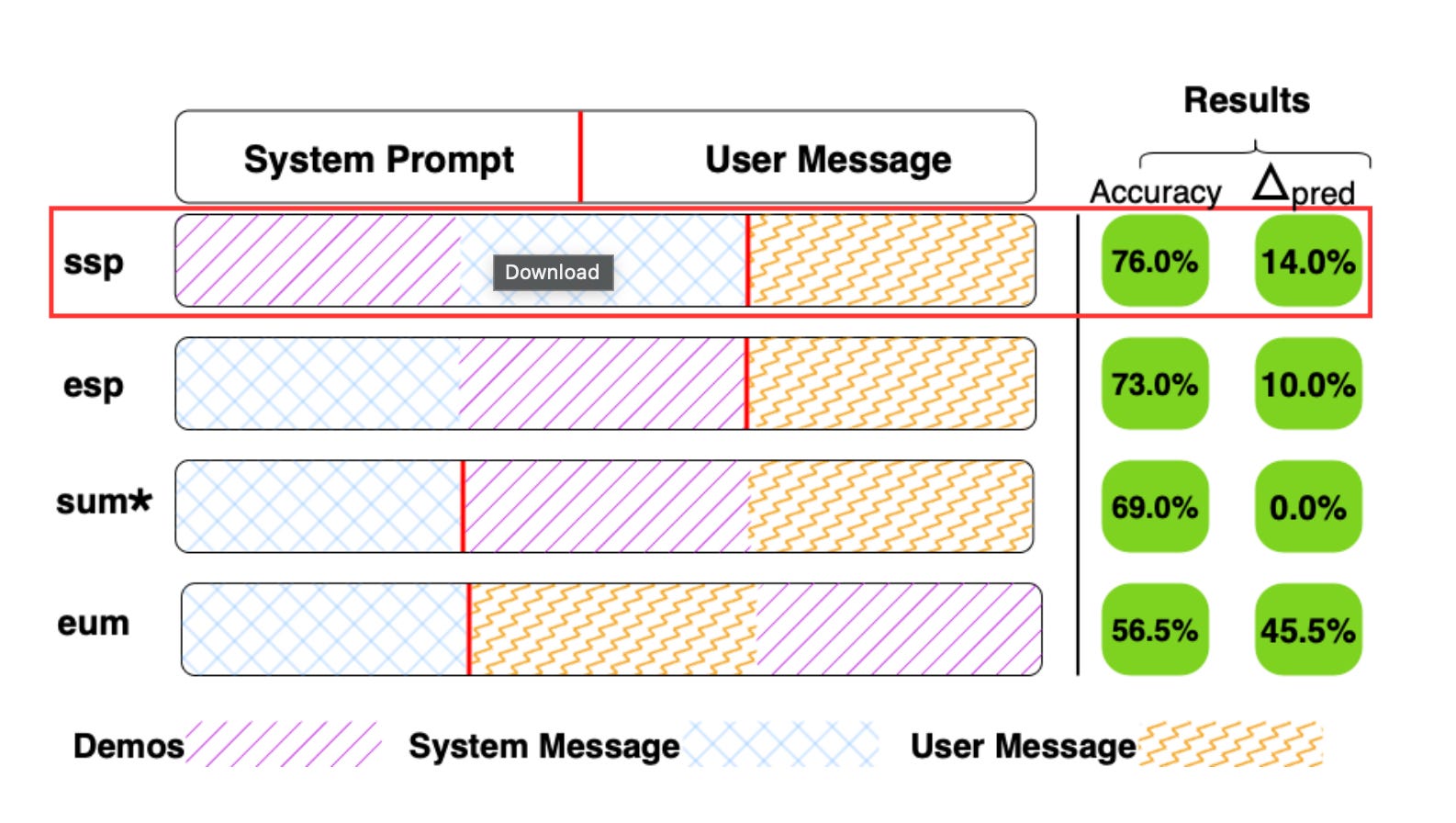
Introduces DPP bias, a new kind of positional sensitivity in LLM where the location of demonstrations in a prompt significantly affects output accuracy and stability. While prior work focused on demo content and order, this study reveals that moving an identical demo block across different sections of a prompt, e.g., before vs. after the user query, can change accuracy by up to 20 points and flip a large percentage of model predictions.
Key findings:
Four canonical demo positions were evaluated: start or end of the system prompt (ssp, esp) and start or end of the user message (sum, eum). Placing demos at the start of the system prompt (ssp) consistently delivered the best performance across most tasks and models, while placing them after the query (eum) degraded accuracy and induced high volatility.
Two new metrics, Accuracy-Change and Prediction-Change, were introduced to quantify how performance and decision stability are impacted purely by demo placement.
Smaller models (e.g., Qwen-1.5B, LLAMA3-3B) are highly sensitive to demo position. For instance, on the AG News dataset, accuracy dropped from 76% (ssp) to 56% (eum) for Qwen-1.5B. In contrast, larger models like LLAMA3-70B show more stability but still exhibit shifts in optimal positioning depending on the task.
Scaling trends show that as model size increases, both accuracy differences and prediction flips caused by positional changes decrease. However, in generation tasks like summarization (e.g., XSUM, CNN/DM), even the largest models remain fragile, with prediction flip rates near 100% for late-positioned demos.
No universal best position: While ssp dominates in classification and reasoning tasks, sum or even eum occasionally performs better in generative or arithmetic settings, especially for larger models like Qwen-72B or LLAMA3-70B.
8. Self-Evolving Agents
This survey offers a comprehensive review of self-evolving agents, framing the field around what, when, and how agents evolve across models, memory, tools, and interactions. It highlights adaptation mechanisms, evaluation methods, and real-world applications, positioning self-evolution as a key step toward achieving Artificial Super Intelligence (ASI).
9. Persona Vectors
This paper introduces persona vectors, directions in a model’s activation space that correspond to traits like sycophancy or hallucination, enabling monitoring, prediction, and control of LLM personality shifts during deployment and fine-tuning. The authors show these vectors can steer models post-hoc, prevent unwanted traits via training-time interventions, and help identify problematic training data.
10. Efficient Attention Mechanisms
This survey reviews linear and sparse attention techniques that reduce the quadratic cost of Transformer self-attention, enabling more efficient long-context modeling. It also examines their integration into large-scale LLMs and discusses practical deployment and hardware considerations.