
🥇Top AI Papers of the Week
The Top AI Papers of the Week (January 5-11)
1. On the Slow Death of Scaling
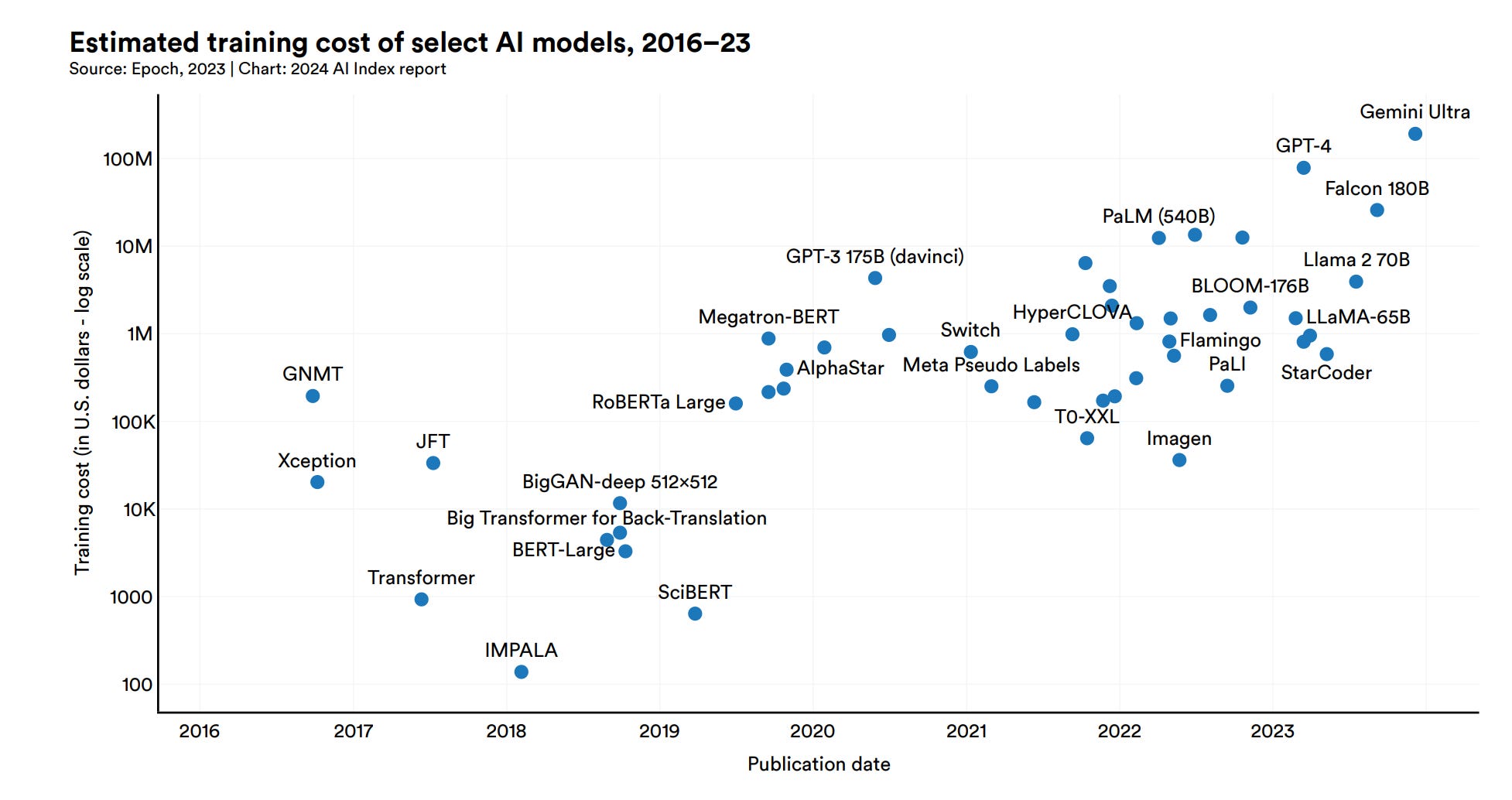
This essay by Sara Hooker challenges the decade-long assumption that scaling compute always leads to better AI performance. It argues that the relationship between training compute and performance is highly uncertain and rapidly changing, with smaller models now routinely outperforming much larger ones.
Diminishing returns of scale: Smaller models like Llama-3 8B and Aya 23 8B now outperform far larger models like Falcon 180B and BLOOM 176B despite having only a fraction of the parameters. This trend is systematic, not isolated.
Algorithmic improvements matter more: Progress has been driven by instruction finetuning, model distillation, chain-of-thought reasoning, preference training, and retrieval augmented generation - techniques that add little training compute but yield significant performance gains.
Scaling laws have limits: Scaling laws only reliably predict pre-training test loss, not downstream task performance. Many capabilities display irregular scaling curves, and small sample sizes make predictions statistically weak.
New optimization spaces: Future progress will come from inference-time compute, malleable synthetic data that can be optimized on-the-fly, and better human-AI interfaces rather than simply adding more parameters.
Cultural implications: The belief in scaling has marginalized academia, concentrated breakthroughs in wealthy regions, and led industry labs to stop publishing, reshaping the entire culture of AI research.
2. Recursive Language Models
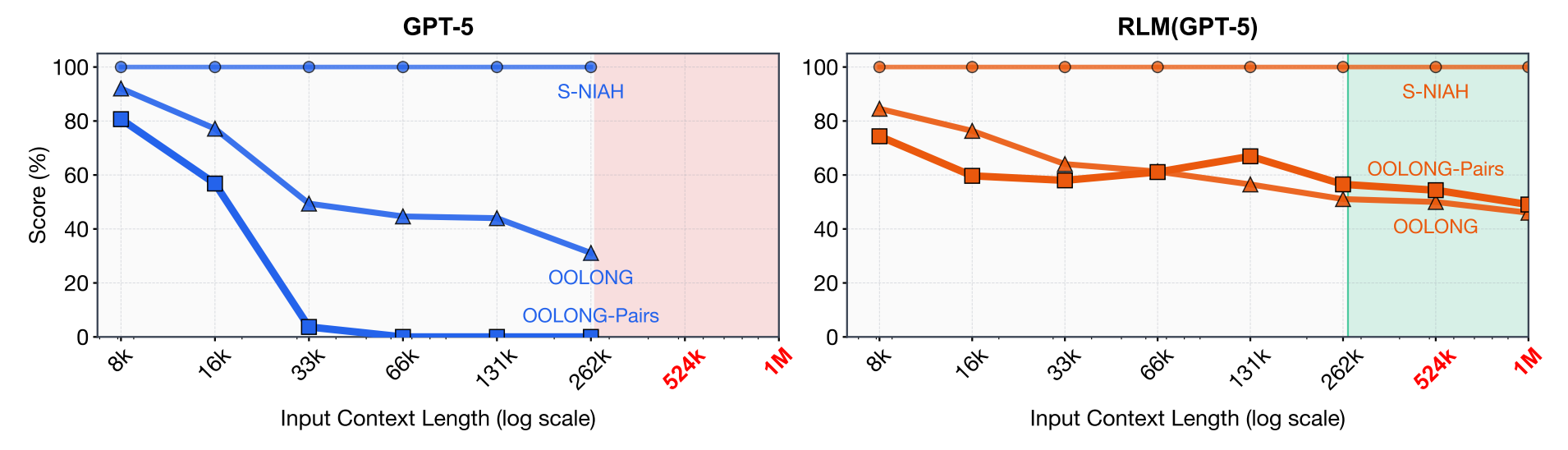
Recursive Language Models (RLMs) are a general inference strategy that allows LLMs to process arbitrarily long prompts by treating them as part of an external environment. Rather than feeding long contexts directly into the model, RLMs load the prompt as a variable in a Python REPL and let the LLM programmatically examine, decompose, and recursively call itself over snippets.
Scaling beyond context windows: RLMs successfully handle inputs up to two orders of magnitude beyond model context windows, scaling to the 10M+ token regime while maintaining strong performance.
Outperforming base models: On information-dense tasks like OOLONG-Pairs, GPT-5 achieves less than 0.1% F1 while RLM(GPT-5) reaches 58% F1. RLMs outperform base models and common long-context scaffolds by up to 2x on diverse benchmarks.
Emergent decomposition patterns: Without explicit training, RLMs exhibit sophisticated behaviors including filtering context using regex queries based on model priors, chunking and recursive sub-calling, and answer verification through small-context sub-LM calls.
Cost-effective inference: RLMs maintain comparable or lower costs than base model calls at median, with the ability to selectively view context rather than ingesting entire inputs like summarization approaches.
Task complexity scaling: While base LLM performance degrades rapidly with both input length and task complexity, RLMs degrade at a much slower rate, maintaining effectiveness even on quadratically-scaling tasks.
Message from the Editor

Only a couple more days left to enroll in your new popular live training on Claude Code for Everyone. Learn how to leverage Claude Code features to vibe code production-grade AI-powered apps.
Grab the last remaining seats now!
3. Adversarial Program Evolution with LLMs
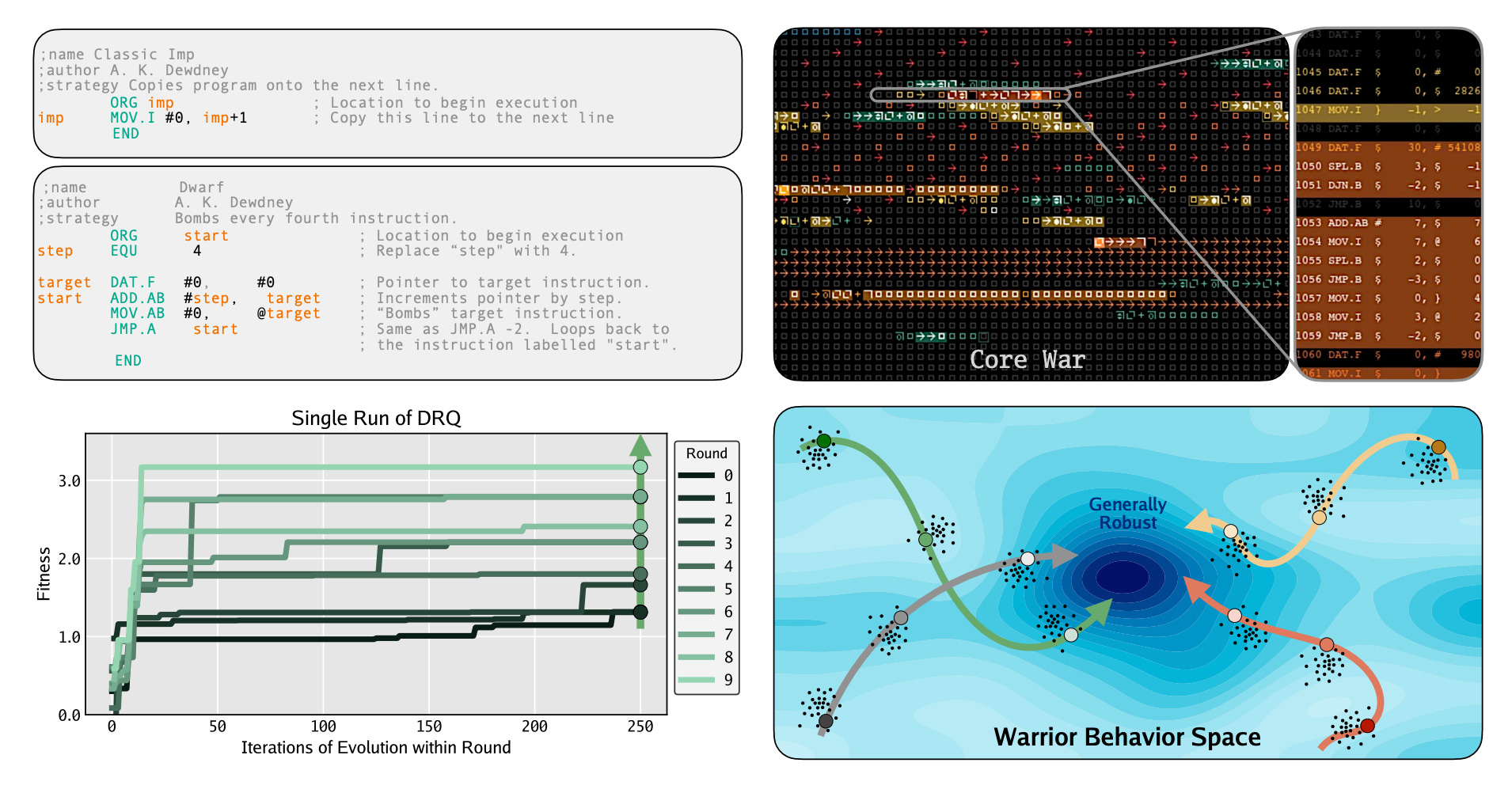
Digital Red Queen (DRQ) introduces an algorithm where LLMs evolve assembly-like programs called “warriors” that compete for control of a virtual machine in the game of Core War. Rather than optimizing toward static objectives, DRQ embraces “Red Queen” dynamics where goals continually shift based on competition, demonstrating how adversarial self-play can drive the evolution of increasingly sophisticated programs.
Core War as testbed: The classic programming game serves as an ideal environment for studying adversarial adaptation, where programs must simultaneously attack opponents and defend themselves in shared memory space.
Emergent generalization: Evolved warriors become increasingly effective against unseen opponents, suggesting that competitive dynamics produce more robust solutions than static optimization objectives.
Behavioral convergence: Despite independent evolutionary runs, warriors show paradoxical behavioral convergence, indicating that competitive pressure discovers similar successful strategies across different lineages.
Dynamic objectives outperform static: The research demonstrates that continually shifting competitive objectives can outperform traditional static optimization for evolving general-purpose solutions.
Broad applications: The approach has implications for cybersecurity (evolving attack/defense strategies), evolutionary biology (modeling arms races), and AI safety (understanding adversarial dynamics in multi-agent systems).
4. Nemotron-Cascade
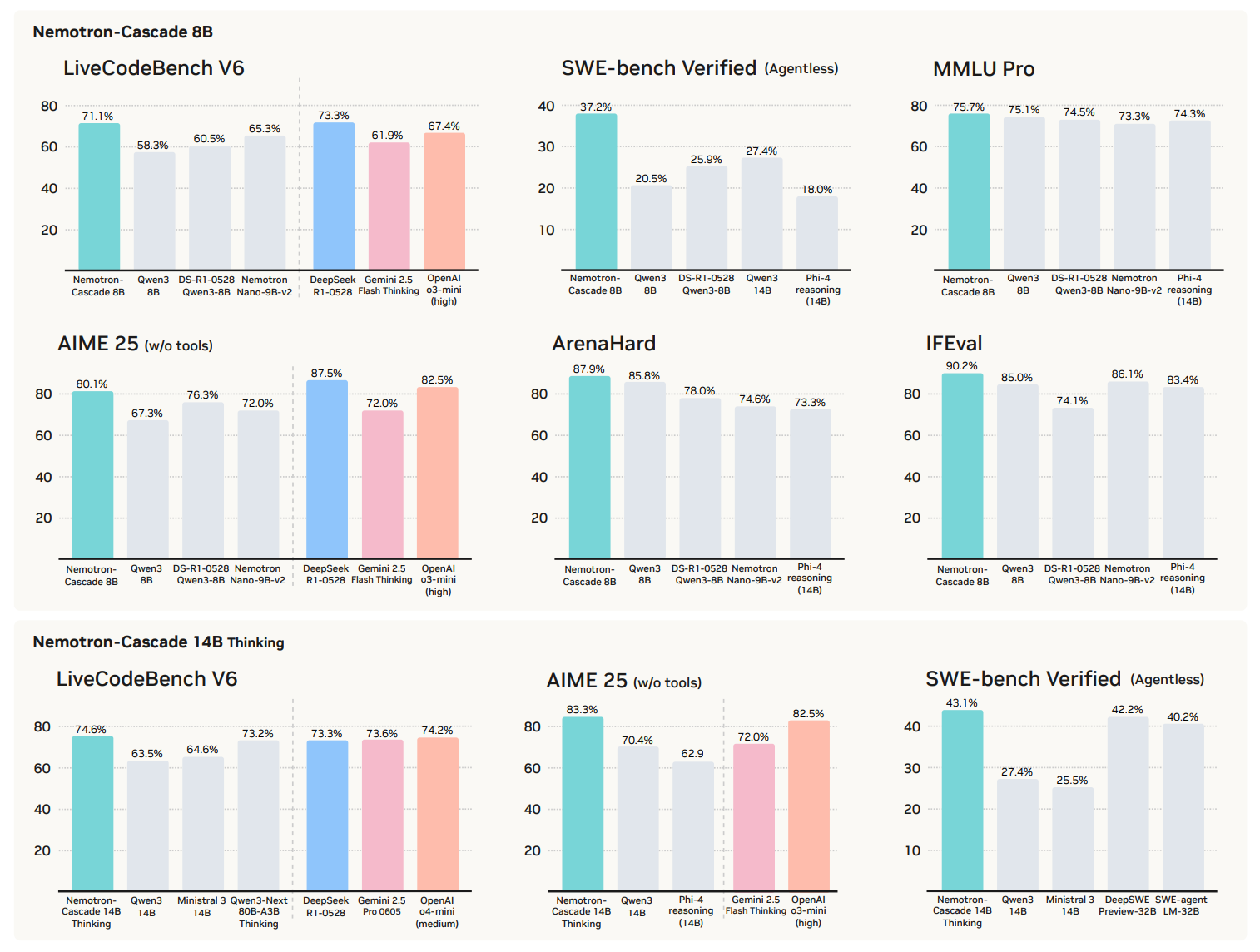
Nemotron-Cascade introduces cascaded domain-wise reinforcement learning (Cascade RL) to build general-purpose reasoning models capable of operating in both instruct and deep thinking modes. Rather than blending heterogeneous prompts from different domains, Cascade RL orchestrates sequential, domain-wise RL stages that reduce engineering complexity while delivering state-of-the-art performance.
Sequential domain-wise RL: The approach chains RLHF, instruction-following RL, math RL, code RL, and SWE RL in sequence. Subsequent stages rarely degrade earlier domain performance and may even improve it, avoiding catastrophic forgetting.
RLHF as reasoning booster: RLHF for alignment, when used as a pre-step, boosts reasoning ability far beyond mere preference optimization, serving as a foundation for subsequent domain-specific RL stages.
Strong competitive coding results: The 14B model outperforms its SFT teacher DeepSeek-R1-0528 on LiveCodeBench v5/v6/Pro and achieves silver-medal performance at the 2025 International Olympiad in Informatics (IOI).
Cross-domain excellence: The 8B model achieves 71.1% on LiveCodeBench V6, 37.2% on SWE-bench Verified, and 80.1% on AIME 2025, outperforming larger models like Qwen3-8B and matching or exceeding frontier reasoning models.
Transparent recipes: NVIDIA shares complete training and data recipes, including multi-stage SFT, reward modeling, and domain-specific RL configurations for reproducibility.
5. GDPO
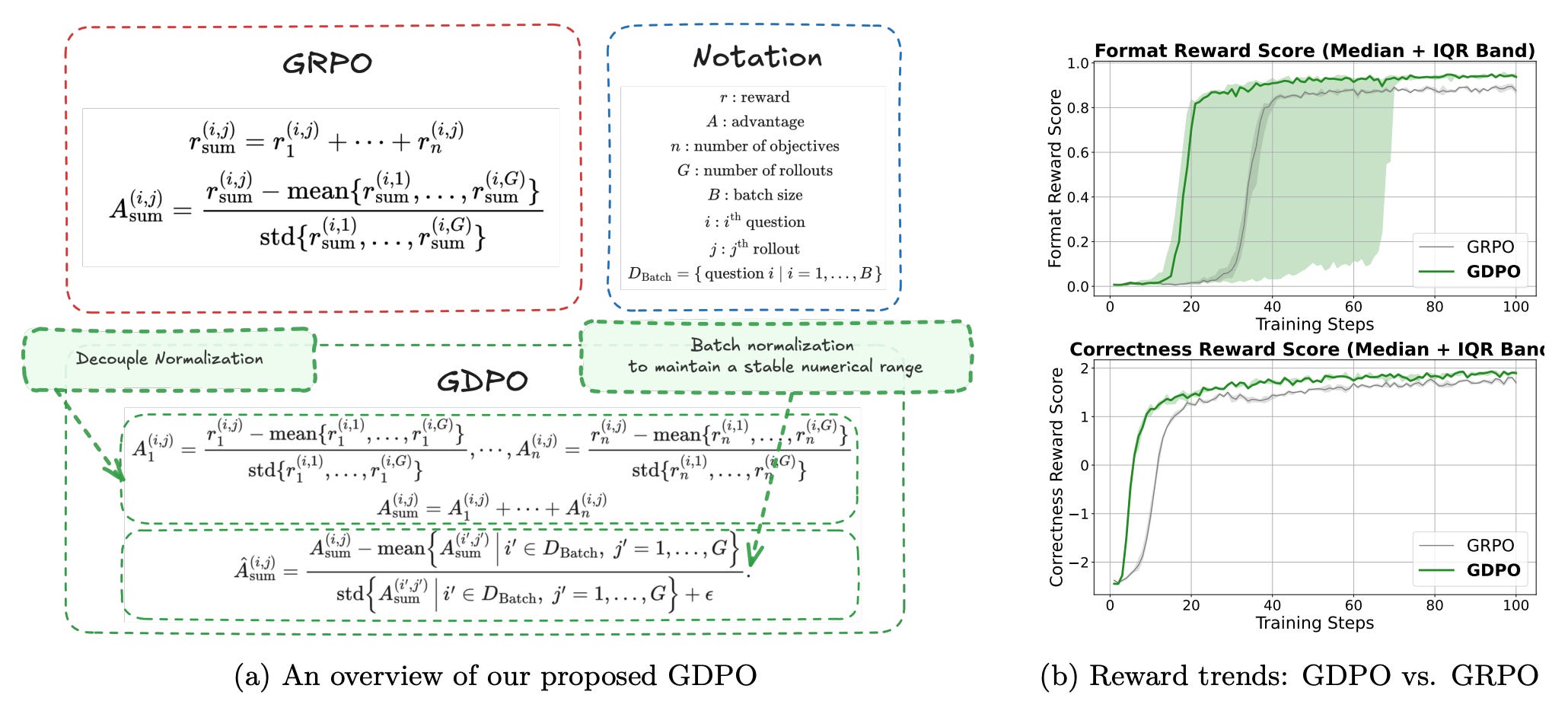
GDPO addresses a critical flaw in training language models with multiple competing objectives. The authors discover that when applying Group Relative Policy Optimization (GRPO) to multi-reward settings, normalizing distinct rollout reward combinations causes them to collapse into identical advantage values, degrading training signal quality and stability.
Fundamental flaw identified: Standard GRPO normalizes rewards across all objectives together, which causes distinct reward combinations to collapse into nearly identical advantage values—destroying the nuanced signal needed for multi-objective optimization.
Decoupled normalization: GDPO decouples the normalization of individual rewards, more faithfully preserving their relative differences and enabling more accurate multi-reward optimization across competing objectives.
Consistent improvements: GDPO demonstrated gains over GRPO across three domains: tool calling, mathematical reasoning, and code generation, improving both correctness metrics (accuracy, defect rates) and constraint adherence (format compliance, output length).
Practical multi-objective training: The approach enables training models that must simultaneously optimize for multiple goals, such as being accurate while following format constraints, without the objectives interfering destructively.
Drop-in replacement: GDPO can serve as a drop-in replacement for GRPO in multi-reward RL pipelines, requiring minimal changes to existing training infrastructure while providing more stable and effective optimization.
6. Training AI Co-Scientists Using Rubric Rewards
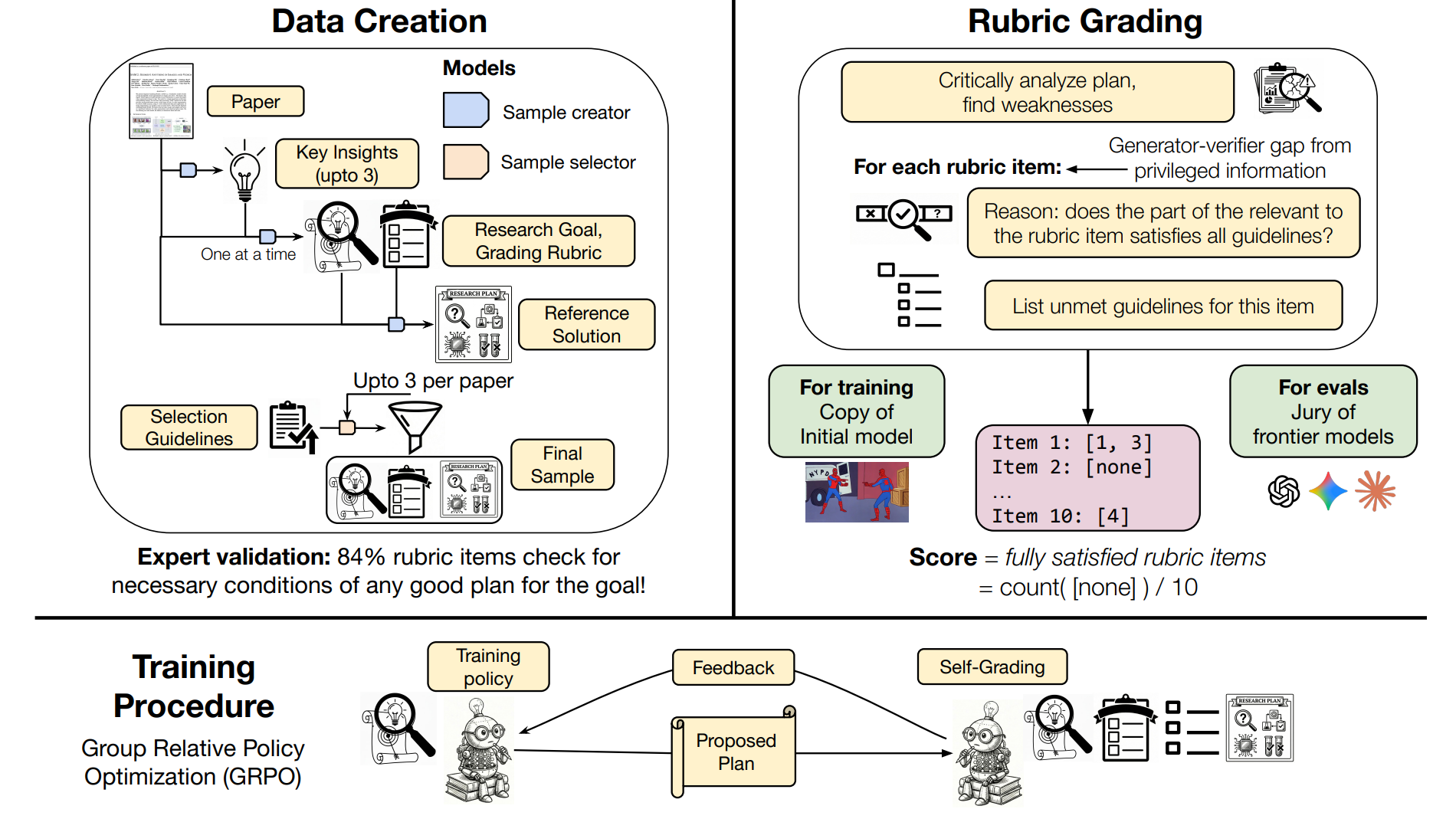
This paper from Meta Superintelligence Labs presents a scalable method to train language models to generate better research plans without expensive human supervision or real-world execution. The approach automatically extracts research goals and goal-specific grading rubrics from scientific papers, then uses reinforcement learning with self-grading to improve plan generation.
Automated data extraction: Research goals and grading rubrics are automatically extracted from papers across ML, medical, and arXiv domains. Human experts validated that 84% of rubric items capture necessary requirements for good research plans.
Self-grading with privileged information: A frozen copy of the initial model acts as a grader, using extracted rubrics as privileged information to evaluate plans. This creates a generator-verifier gap that enables training without external supervision.
Strong human validation: In a 225-hour study with ML experts, the finetuned Qwen3-30B model’s plans were preferred over the initial model for 70% of research goals, with experts rating them as sounder and more likely to lead to better outcomes.
Cross-domain generalization: Models trained on one domain generalize significantly to others. The medical-finetuned model achieved 15% relative improvement on ML tasks and 17.5% on arXiv tasks, suggesting the approach learns generally desirable research plan qualities.
Competitive with frontier models: The finetuned 30B model becomes competitive with Grok-4-Thinking, achieving 12-22% relative improvements across domains, though GPT-5-Thinking remains the top performer.
7. Confucius Code Agent

Confucius Code Agent (CCA) is a software engineering agent designed to operate on large-scale codebases. Built on the Confucius SDK, it introduces a three-axis design philosophy separating Agent Experience (AX), User Experience (UX), and Developer Experience (DX) to enable robust multi-step reasoning and modular tool use.
Hierarchical working memory: Uses adaptive context compression to maintain essential state during long-horizon reasoning without exceeding context limits. A planner agent summarizes earlier turns into structured plans, reducing prompt length by over 40% while preserving key reasoning chains.
Persistent note-taking: A dedicated note-taking agent distills interaction trajectories into structured Markdown notes, capturing both successful strategies and failure cases for cross-session learning. This reduces token costs by approximately 11k and improves resolve rates on repeated tasks.
Modular extension system: Tool-use behaviors are factored into typed extensions that attach to the orchestrator, enabling reusable, auditable, and adaptable capabilities across different agents and tool stacks.
Meta-agent automation: A meta-agent automates a build-test-improve loop that synthesizes, evaluates, and refines agent configurations, enabling rapid adaptation to new environments and tasks without manual prompt engineering.
Strong benchmark results: On SWE-Bench-Pro, CCA achieves 54.3% Resolve@1 with Claude 4.5 Opus, exceeding prior research baselines. With Claude 4.5 Sonnet, CCA reaches 52.7%, outperforming Claude 4.5 Opus with Anthropic’s proprietary scaffold at 52.0%, demonstrating that scaffolding can outweigh raw model capability.
8. SciSciGPT
SciSciGPT is an open-source AI collaborator that uses the science of science domain as a testbed for LLM-powered research tools. Its multi-agent architecture with five specialized modules automates complex research workflows and completes tasks in about 10% of the time required by experienced researchers while producing higher-quality outputs.
9. SWE-EVO
SWE-EVO introduces a benchmark for evaluating coding agents on long-horizon software evolution tasks that require multi-step modifications spanning an average of 21 files per task. The benchmark reveals significant limitations of current agents: GPT-5 with OpenHands achieves only 21% on SWE-EVO compared to 65% on SWE-Bench Verified, highlighting the gap between isolated bug fixes and realistic software development scenarios.
10. Deep Delta Learning
Deep Delta Learning introduces a novel “Delta Operator” that generalizes residual connections by modulating the identity shortcut with a learnable, data-dependent geometric transformation. This enables networks to dynamically interpolate between identity mapping, orthogonal projection, and geometric reflection, allowing selective forgetting of features rather than just accumulation.
Great curation as always, Elvis! Sara Hooker’s ‘On the Slow Death of Scaling’ is a much-needed reality check—efficiency, smart data & clever algorithms are taking over in 2026. Recursive LMs look like a brilliant, cheap hack to escape context walls. Following so I don’t miss the next one!