
🥇Top AI Papers of the Week
The Top AI Papers of the Week (September 1-7)
1. Why Language Models Hallucinate

The paper argues that hallucinations are not mysterious glitches but the predictable result of how LLMs are trained and evaluated. Pretraining creates statistical pressure to make errors, and post-training benchmarks often reward confident guessing over honest uncertainty. The fix is to realign mainstream evaluations to stop penalizing abstentions.
Pretraining inevitably produces some errors. The authors reduce generation to a binary “Is-It-Valid” classification problem and show a lower bound: the generative error rate scales with the misclassification rate in that classifier. Even with error-free corpora, optimizing cross-entropy yields calibrated base models that still generate errors rather than always saying “I don’t know.”
Arbitrary facts drive a floor on hallucinations. For facts with no learnable pattern (for example, specific birthdays), the paper links hallucination rates to the “singleton rate” in training data. If many facts appear only once, a calibrated base model will hallucinate on at least that fraction of such prompts. This generalizes Good-Turing style missing-mass reasoning and recovers prior results while adding prompts and IDK.
Model class limitations also matter. When the model family cannot represent the needed distinctions, errors persist. The paper formalizes this via an agnostic-learning bound and gives simple cases like multiple choice, where even optimal thresholding leaves a fixed error tied to model capacity, with an example showing classic n-gram models must fail on certain context dependencies.
Post-training often reinforces guessing. Most popular benchmarks grade in a binary correct-incorrect fashion and give zero credit to abstentions, so a model that always guesses can outperform one that withholds uncertain answers. The authors survey widely used leaderboards and find that abstentions are largely penalized, explaining why overconfident hallucinations persist despite mitigation efforts.
Proposed fix: explicit confidence targets. Incorporate clear penalties for wrong answers and neutral credit for IDK directly into mainstream evaluations, instructing models to answer only above a stated confidence threshold. This promotes behavioral calibration, where models choose between answering and abstaining according to the target confidence, and should steer the field toward more trustworthy systems.
2. Disentangling the Factors of Convergence between Brains and Computer Vision Models
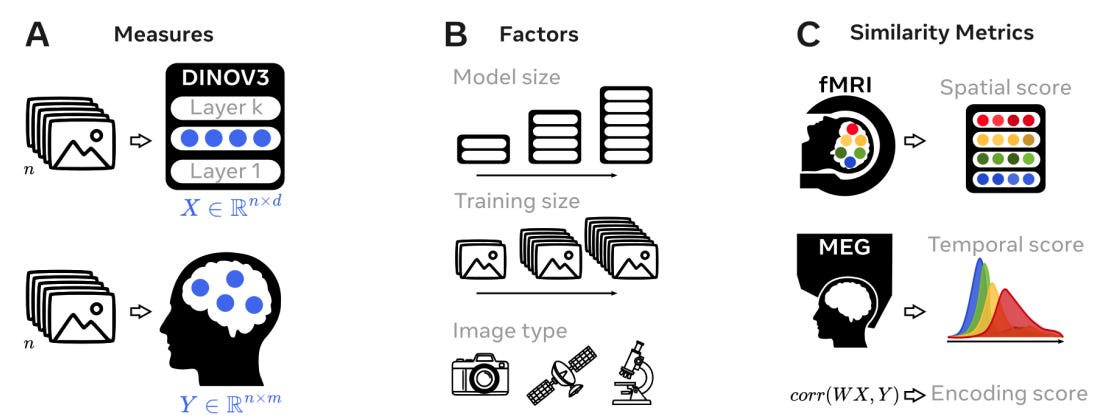
Large self-supervised ViTs trained on natural images develop brain-like internal representations. This paper teases apart what drives that convergence by varying model size, training amount, and image type in DINOv3, then comparing model activations to human fMRI (space) and MEG (time) with three metrics: overall linear predictability (encoding), cortical topography (spatial), and temporal alignment (temporal). Result: all three factors matter, and alignment unfolds in a consistent order from early sensory to higher associative cortex.
Setup and metrics: Eight DINOv3 variants spanning sizes and datasets; comparisons use encoding, spatial, and temporal scores against NSD fMRI and THINGS-MEG.
Baseline alignment: fMRI predictability concentrates along the visual pathway (voxel peaks around R≈0.45). MEG predictability rises ~70 ms after image onset and remains above chance up to 3 s. Spatial hierarchy holds (lower layers ↔ early visual; higher layers ↔ prefrontal; r≈0.38). Temporal ordering is strong (earlier MEG windows ↔ early layers; r≈0.96).
Training dynamics: Alignment emerges quickly but not uniformly: temporal score reaches half its final value first (~0.7% of training), then encoding (~2%), then spatial (~4%). Early visual ROIs and early MEG windows converge sooner than prefrontal ROIs and late windows (distance-to-V1 vs half-time r≈0.91; time-window vs half-time r≈0.84).
Scale and data effects: Bigger models finish with higher encoding, spatial, and temporal scores; gains are largest in higher-level ROIs (e.g., BA44, IFS). Human-centric images beat satellite and cellular images across metrics and ROIs at matched data volume.
Cortical correlates: ROIs whose model alignment appears later are those with greater developmental expansion, thicker cortex, slower intrinsic timescales, and lower myelin (e.g., correlations up to |r|≈0.88). This mirrors biological maturation trajectories.
3. Universal Deep Research
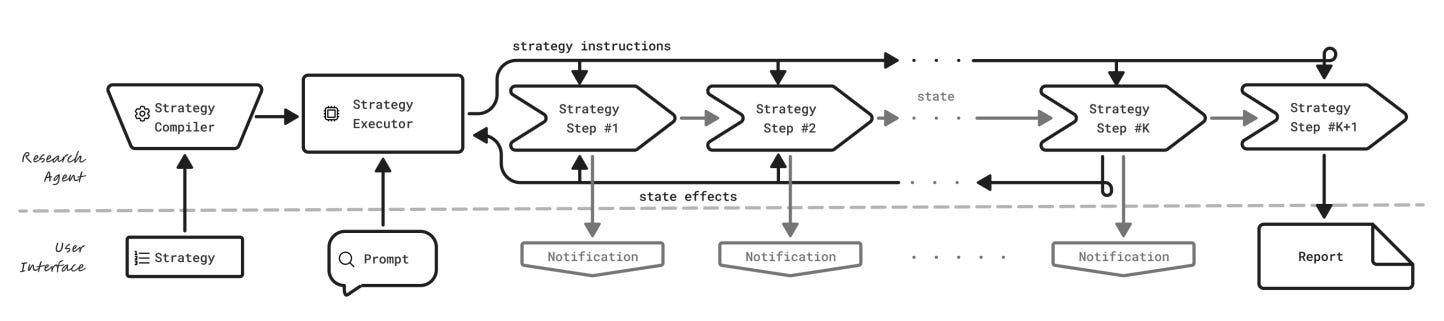
Proposes a general, model-agnostic deep-research agent that lets users “bring your own model and strategy.” Instead of a fixed pipeline, UDR compiles natural-language research strategies into executable code, runs them in a sandbox, and emits structured progress notifications before returning a final report.
Motivation. Current deep-research tools hard-code strategy and model choice, limiting source prioritization, domain-specific workflows, and model swap-ability. UDR targets all three gaps by separating the research strategy from the underlying model.
Mechanism. Users provide a strategy and a prompt. UDR converts the strategy to a single callable function under strict tool and control-flow constraints, then executes it in isolation. Orchestration is pure code; the LLM is called only for local tasks like summarization, ranking, or extraction. State lives in named variables, not a growing context.
Phases and tools. Phase 1 compiles the strategy step-by-step to reduce skipped steps and drift. Phase 2 executes with synchronous tool calls and yield-based notifications for real-time UI updates. The paper provides minimal, expansive, and intensive example strategies to show breadth.
Efficiency and reliability. Control logic runs on CPU while LLM calls remain scoped and infrequent, improving cost and latency. End-to-end strategy compilation proved more reliable than prompting LLMs to “self-orchestrate” or stitching per-step code.
Security, UI, and limits. Strategies execute in a sandbox to contain prompt-injection or code exploits; the demo UI supports editing strategies, monitoring notifications, and viewing reports. Limitations include reliance on code-generation fidelity, no mid-execution interactivity, and assuming user-written strategies are sound. The authors recommend shipping a library of editable strategies and exploring tighter user control over free reasoning.
4. Visual Story Telling
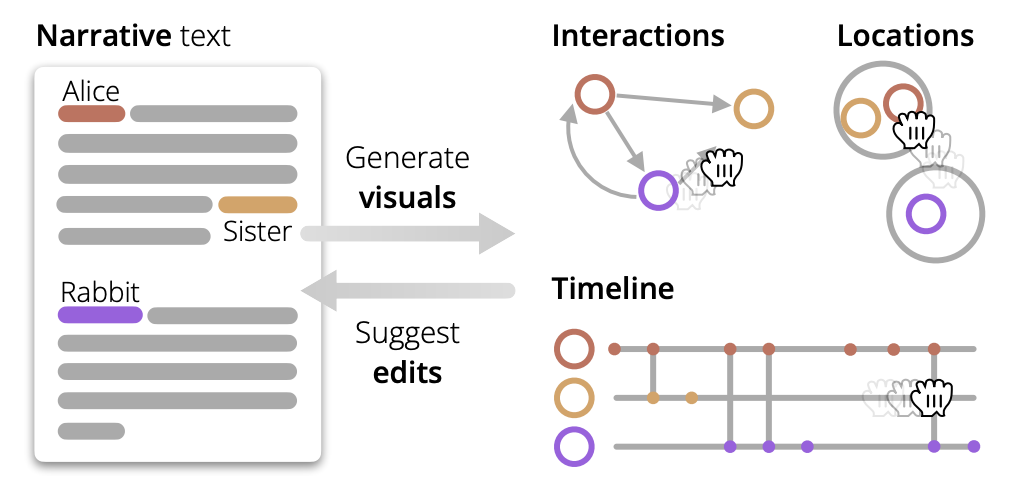
A system and design framework that lets writers edit stories by acting directly on visuals of characters, locations, and timelines. Instead of only prompting, authors drag, connect, and reorder visual elements; the tool proposes synchronized text edits and can regenerate passages from the visual skeleton.
Framework: eight elements + four operators. Builds on narratology (fabula/syuzhet) with story elements (actors/characters, time/temporality, locations/space, events/focalization) and four compositional operators: position, associate, connect, unfold.
Prototype with three coordinated views. An entities–actions graph, a locations canvas, and an event timeline enable direct manipulation: add/remove characters or actions, drag entities between locations, reorder events; coordinated highlighting and selection constrain edits to chosen scenes.
Bi-directional editing and versioning. Manual text edits can refresh visuals; visual edits generate tracked diffs in text; a history tree supports branching exploration; a “refresh from visuals” mode rewrites the story from the current visual state.
Two studies: planning and editing. With 12 participants, visuals improved planning, search, and reflection compared to text-only, though cognitive-load results were mixed and mental-model mismatches appeared. With 8 creative writers, participants successfully expressed spatial, temporal, and entity edits, found it helpful for exploration and inconsistency fixing, and gave a high Creativity Support Index, while asking for more control over style and alternative visual layouts.
Implementation and limits. React + Slate.js front end; GPT-4o prompts for extraction and edits; parallel sentence-level extraction for speed. Occasional LLM latency or unintended edits remain; future work includes richer constructs (relationships, emotions), style controls, support for long/nonlinear narratives, and a view-builder for custom diagrams.
5. rStar2-Agent
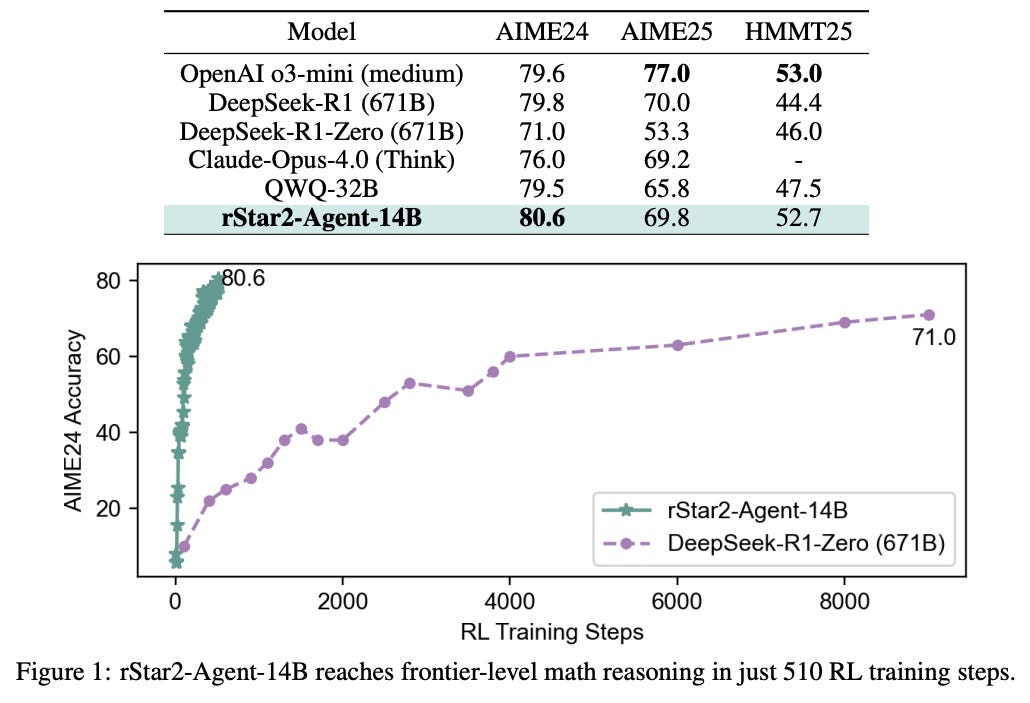
rStar2-Agent is a 14B math-reasoning model trained with agentic RL that learns to think smarter by using a Python tool environment, not just longer CoT. It introduces GRPO-RoC, a rollout strategy that filters noisy successful traces, plus infrastructure for massive, low-latency tool execution. In one week and 510 RL steps on 64 MI300X GPUs, the model reaches frontier-level AIME while producing shorter solutions and showing transfer beyond math.
Method in one line: GRPO-RoC oversamples rollouts then keeps only the cleanest correct ones while preserving diverse failures, reducing tool-call errors and formatting issues during training.
Infrastructure: A dedicated, isolated code service reliably handles up to ~45K concurrent tool calls per training step with ~0.3 s end-to-end latency, and a load-balanced scheduler allocates rollouts by available KV cache to cut GPU idle time.
Training recipe: Start with non-reasoning SFT to teach tool use and formatting, then three RL stages that scale max output length 8K → 12K → 12K, and finally focus on harder problems; RL data curated to 42K math items with integer answers.
Results: Pass@1 AIME24 80.6, AIME25 69.8, HMMT25 52.7, exceeding or matching o3-mini (medium) and DeepSeek-R1 despite far smaller size; responses are shorter on AIME24/25 than Qwen3-14B and QWQ-32B.
Generalization and behaviors: Improves GPQA-Diamond to 60.9 and performs well on tool-use and alignment benchmarks; entropy analysis shows preserved forking tokens and new reflection tokens triggered by tool feedback, enabling verification and correction.
6. Adaptive LLM Routing
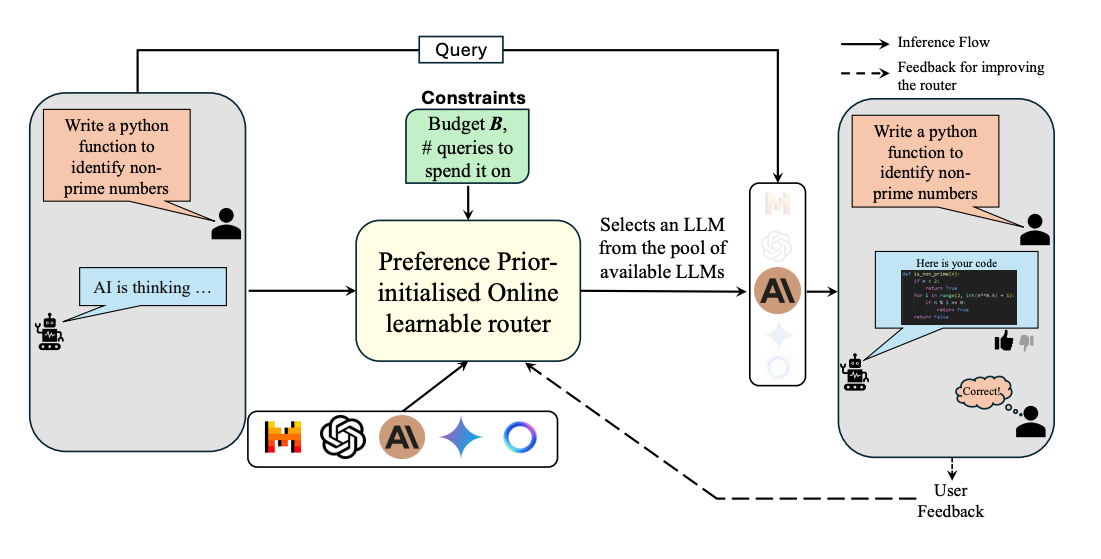
A routing framework that learns online which model to call for each query while honoring a spend limit. It treats routing as a contextual bandit, initializes with human preference data, and adds an online cost policy that allocates budget across queries.
Core idea: Build a shared embedding space for queries and candidate LLMs, align it with offline human preferences, then update LLM embeddings online using bandit feedback. Selection uses a preference-prior LinUCB variant (PILOT) with cosine-similarity rewards.
Budget control: Introduces an online multi-choice knapsack policy (ZCL-style) that filters eligible models by reward-to-cost thresholds and allocates spend in bins so the total stays within budget.
Results: On RouterBench multi-task routing, achieves about 93% of GPT-4 performance at roughly 25% of its cost; on single-task MMLU, about 86% at roughly 27% cost. Cumulative regret is consistently lower than bandit baselines.
Cost policy effectiveness: Online policy matches or outperforms a strong offline P − λC oracle tuned with hindsight across budgets.
Latency overhead: Routing adds little delay relative to inference. Selection takes 0.065–0.239 s vs. ~2.5 s for GPT-4 on MMLU..
7. Implicit Reasoning in LLMs
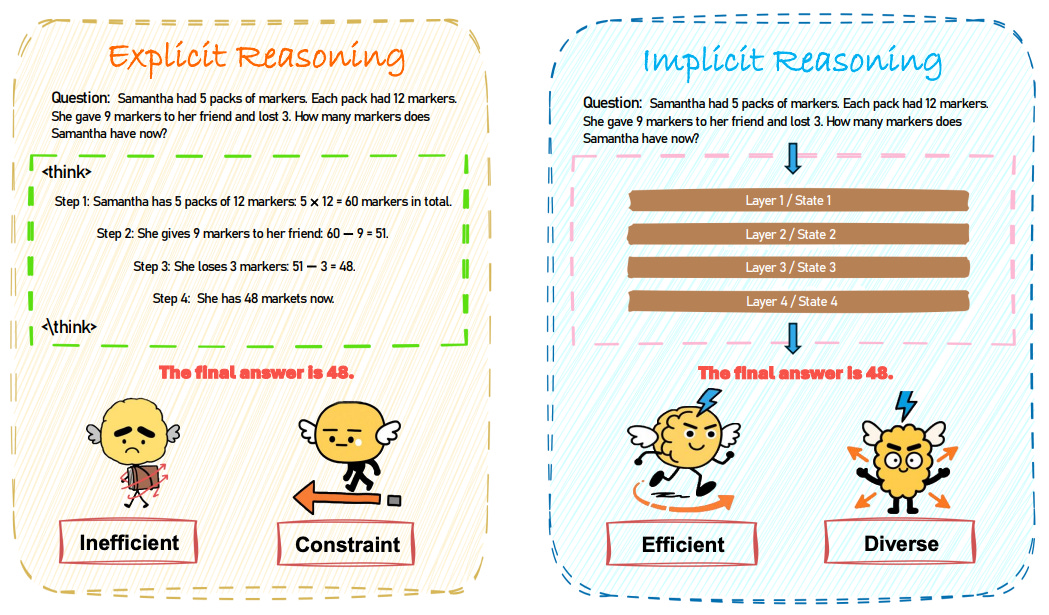
This survey defines implicit reasoning as multi-step problem solving that happens inside a model’s latent states without printing intermediate steps. It organizes the field by execution paradigm rather than representation format, and reviews evidence, evaluation, and open challenges.
Three execution paradigms.
Latent optimization adjusts internal representations directly: token-level inserts or learns special latent tokens; trajectory-level compresses or refines whole chains of thought for semantic fidelity, adaptive efficiency, progressive refinement, or exploratory diversification; internal-state-level distills or steers hidden activations to carry the reasoning signal.
Signal-guided control uses lightweight controls to modulate compute without emitting text, from thinking or pause tokens to instance-level latent adjustment.
Layer-recurrent execution reuses shared blocks in loops to simulate deeper chains internally, with models like ITT, looped Transformers, CoTFormer, Huginn, and RELAY.
Evidence that the latent process is real. Structural signals show layer-wise decomposition and shortcutting; behavioral signatures include step-skipping and grokking-driven phase transitions; representation studies recover intermediate facts from hidden states or induce reasoning via activation steering.
How it is evaluated. Metrics cover final answer correctness (accuracy, Pass@k, EM), efficiency (latency, output length, FLOPs, ACU), perplexity, and probing accuracy. Benchmarks span commonsense, math and code, reading comprehension, multi-hop QA, and multimodal reasoning.
Why is it not solved yet. Key gaps include limited interpretability, weak control and reliability, an accuracy gap to explicit CoT on hard tasks, uneven evaluation, architectural constraints, and dependence on explicit supervision.
Big picture. Implicit reasoning promises faster, cheaper inference and richer internal computation. The survey argues for hybrid designs that keep compute latent yet auditable, standardized evaluations that probe internal trajectories, and architectures that generalize beyond bespoke tokens or loops.
8. On the Theoretical Limitations of Embedding-based Retrieval
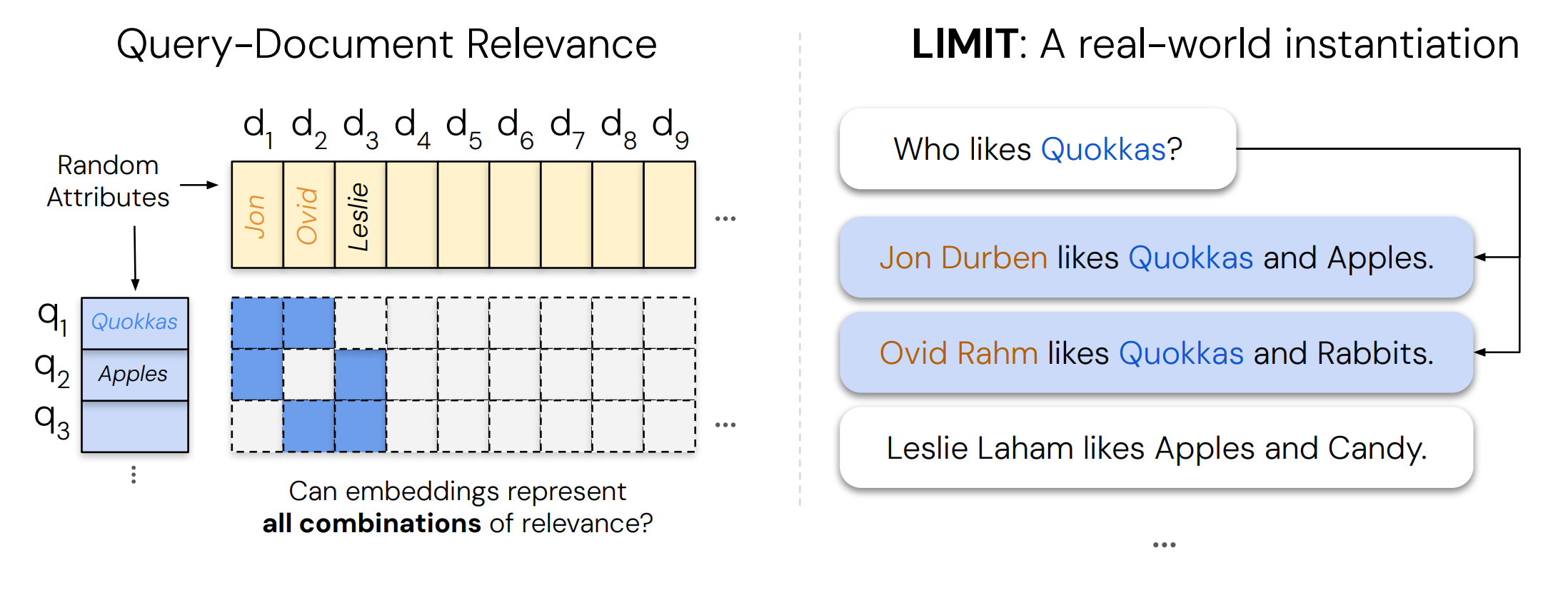
Single-vector dense retrievers cannot realize all possible top-k relevance combinations once queries demand sufficiently many “mix-and-match” document sets. The paper ties this failure to the sign-rank of the relevance matrix, proves lower and upper bounds on the embedding dimension needed, and then stress-tests models with a simple but adversarially combinatorial dataset (LIMIT).
Theory. The authors formalize retrieval as preserving row-wise order or thresholds in a binary qrel matrix and show these capacities are sandwiched by the matrix’s sign-rank. For fixed dimension ddd, some top-k sets are unrepresentable, so certain retrieval tasks are impossible for any single-vector embedder at that ddd.
Best-case optimization. With “free embeddings” directly optimized on the test qrels, the maximum solvable corpus size for k=2k=2k=2 scales roughly as a cubic in ddd. Extrapolated critical sizes remain far below web scale even for 4096-dim embeddings, indicating a fundamental ceiling not attributable to training data or losses.
LIMIT dataset results. LIMIT maps all 2-document combinations to natural-language queries like “Who likes X?” Despite the simplicity, SOTA single-vector models often score below 20% Recall@100 on the full task, and they still cannot solve a 46-document version at Recall@20. Performance improves with larger ddd but remains poor.
Combinatorial density matters. When the qrel graph is made dense to maximize distinct top-k combinations, scores collapse across models. Sparser patterns (random, cycle, disjoint) are markedly easier, highlighting that the number of realizable top-k sets is the bottleneck.
Alternatives and implications. Cross-encoders can solve the small LIMIT variant perfectly, multi-vector late-interaction models fare better than single-vector, and high-dimensional sparse baselines like BM25 perform strongly. For instruction-following retrieval that composes many concepts, systems should pair or replace dense first-stage retrieval with rerankers, multi-vector, or sparse methods.
9. Self-Evolving Agents
This survey reviews techniques for building self-evolving AI agents that continuously adapt through feedback loops, bridging static foundation models with lifelong adaptability. It introduces a unified framework, covers domain-specific strategies, and discusses evaluation, safety, and ethics in advancing autonomous agentic systems.
10. Hermes 4
Hermes 4 introduces a family of hybrid reasoning models that integrate structured multi-turn reasoning with broad instruction-following. The report details data and training challenges, evaluates performance across reasoning, coding, and alignment tasks, and publicly releases all model weights.