
🥇Top AI Papers of the Week
The Top AI Papers of the Week (April 14 - April 20)
1). GUI-R1
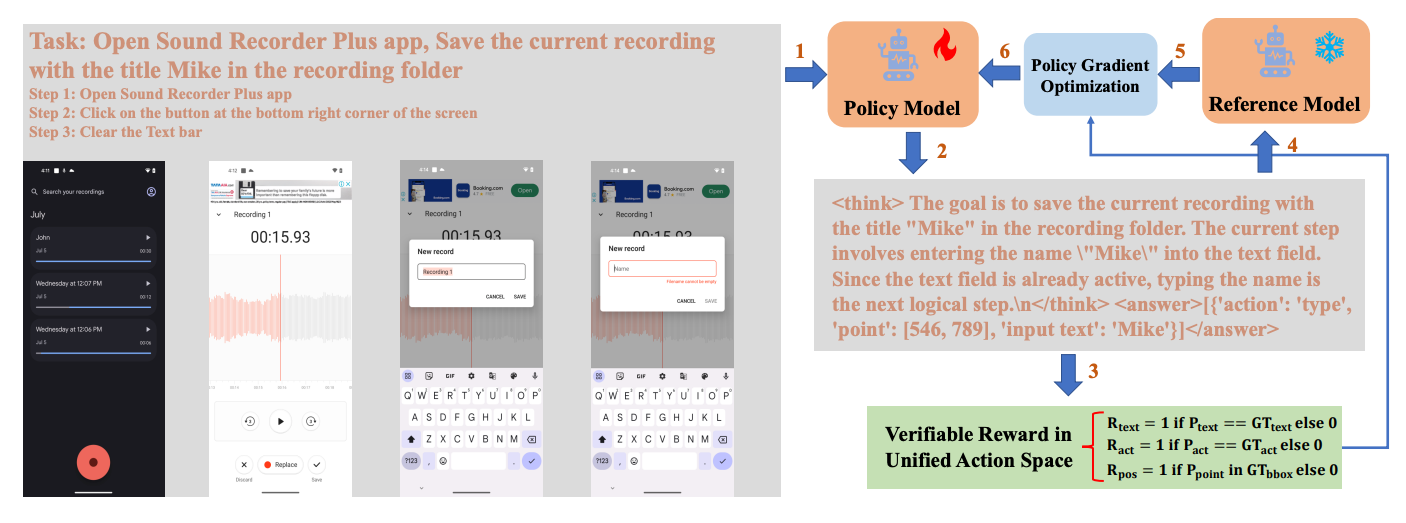
Researchers from the National University of Singapore and the Chinese Academy of Sciences introduce GUI-R1, a reinforcement learning (RL) framework aimed at improving graphical user interface (GUI) agents through unified action-space modeling. Key insights include:
Reinforcement Fine-Tuning (RFT) over Supervised Fine-Tuning (SFT) – GUI-R1 utilizes RFT inspired by methods such as DeepSeek-R1, significantly reducing training data requirements. It uses only 3K carefully curated examples versus millions used by previous models.
Unified Action Space and Reward Modeling – The authors introduce a unified action space that covers actions across different platforms (Windows, Linux, MacOS, Android, and Web). This enables consistent reward signals for evaluating GUI actions, enhancing the model’s adaptability and generalization.
Superior Performance with Minimal Data – GUI-R1 outperforms state-of-the-art methods like OS-Atlas using merely 0.02% of the training data (3K vs. 13M). Evaluations across eight benchmarks spanning mobile, desktop, and web platforms show significant improvements in grounding, low-level, and high-level GUI task capabilities.
Efficient Training and Strong Generalization – By leveraging policy optimization algorithms like Group Relative Policy Optimization (GRPO), GUI-R1 quickly converges to high performance, demonstrating robustness and efficiency even in resource-constrained scenarios.
2). Scaling Reasoning in Diffusion LLMs via RL

Proposes d1, a two‑stage recipe that equips masked diffusion LLMs with strong step‑by‑step reasoning.
Two‑stage pipeline (SFT → diffu‑GRPO) – d1 first applies supervised fine‑tuning on the 1 k‑example s1K dataset and then runs task‑specific RL with the new diffu‑GRPO objective, yielding larger gains than either stage alone.
diffu‑GRPO: RL for masked dLLMs – Extends GRPO to diffusion LLMs via (i) a mean‑field sequence‑log‑prob approximation and (ii) a one‑step per‑token log‑prob estimator with random prompt masking, enabling many gradient updates from a single generation.
Consistent gains on four reasoning benchmarks – On GSM8K, MATH500, Countdown, and Sudoku, diffu‑GRPO beats SFT, and the full d1‑LLaDA variant attains the best scores (e.g., 81.1 % GSM8K & 38.6 % MATH500 at 256 tokens, +5–12 pp over baseline).
Competitive among 7‑8 B models – d1‑LLaDA outperforms DeepSeek‑7B, Mistral‑7B and Llama‑3‑8B on GSM8K and ranks second on MATH500 in the same size class.
Longer decoding unlocks “aha moments” – At 512‑token generation, the model shows self‑verification/backtracking; effective‑token usage grows smoothly, echoing test‑time compute scaling trends.
Random masking speeds RL – Ablations show that random prompt masking during diffu‑GRPO accelerates convergence and boosts correctness relative to fixed masking, with fewer online generations needed.
3). Enhancing Non-Reasoning Models with Reasoning Models

Researchers explore how to distill reasoning-intensive outputs (answers and explanations) from top-tier LLMs into more lightweight models that don’t explicitly reason step by step. By fine-tuning smaller models on the high-quality final answers (and optionally summarized thinking traces) from advanced reasoning models, they demonstrate consistent performance boosts across multiple benchmarks.
Test-time scaling vs. knowledge distillation – While large models like DeepSeek-R1 and OpenAI-o1 can allocate more compute to generate better reasoning traces, this paper focuses on systematically transferring those rich final answers (and possibly a summarized version of the reasoning steps) to more compact models.
Data curation – The authors construct a 1.3M-instance dataset by pulling prompts from multiple open-source repositories (including Infinity Instruct, CodeContests, FLAN, etc.) and generating final answers plus detailed reasoning from DeepSeek-R1.
Three fine-tuning strategies – (1) Use the original baseline answers from existing open-source sets, (2) fine-tune on only the final answer portion of a reasoning model, and (3) combine a summarized chain-of-thought with the final answer. Models trained on the second strategy excelled at math/coding tasks, while the third approach proved better for more conversational or alignment-oriented tasks.
Empirical gains – Fine-tuning Qwen2.5-32B on the reasoning model’s final answers led to notable improvements on GSM8K (92.2%) and HumanEval (90.9%). A think-summarization approach boosted a different set of benchmarks (GPQA and chat-based tests). However, weaving in the “thinking trace” sometimes caused slight drops in instruction strictness (IFEval).
Trade-offs and future work – Distilling advanced reasoning data definitely helps smaller models, but deciding how much of the reasoning trace to include is domain-dependent. The authors suggest that more refined ways of seamlessly blending reasoning steps into final answers (e.g., specialized prompts or partial merges) could further improve performance and avoid alignment regressions.
4). AgentA/B

AgentA/B is a fully automated A/B testing framework that replaces live human traffic with large-scale LLM-based agents. These agents simulate realistic, intention-driven user behaviors on actual web environments, enabling faster, cheaper, and risk-free UX evaluations — even on real websites like Amazon. Key Insights:
Modular agent simulation pipeline – Four components—agent generation, condition prep, interaction loop, and post-analysis—allow plug-and-play simulations on live webpages using diverse LLM personas.
Real-world fidelity – The system parses live DOM into JSON, enabling structured interaction loops (search, filter, click, purchase) executed via LLM reasoning + Selenium.
Behavioral realism – Simulated agents show more goal-directed but comparable interaction patterns vs. 1M real Amazon users (e.g., shorter sessions but similar purchase rates).
Design sensitivity – A/B test comparing full vs. reduced filter panels revealed that agents in the treatment condition clicked more, used filters more often, and purchased more.
Inclusive prototyping – Agents can represent hard-to-reach populations (e.g., low-tech users), making early-stage UX testing more inclusive and risk-free.
Notable results
Simulated 1,000 LLM agents with unique personas in a live Amazon shopping scenario.
Agents in the treatment condition spent more ($60.99 vs. $55.14) and purchased more products (414 vs. 404), confirming the utility of interface changes.
Behavioral alignment with humans was strong enough to validate simulation-based testing.
Only the purchase count difference reached statistical significance, suggesting further sample scaling is needed.
AgentA/B shows how LLM agents can augment — not replace — traditional A/B testing by offering a new pre-deployment simulation layer. This can accelerate iteration, reduce development waste, and support UX inclusivity without needing immediate live traffic.
5). Reasoning Models Can Be Effective Without Thinking

This paper challenges the necessity of long chain-of-thought (CoT) reasoning in LLMs by introducing a simple prompting method called NoThinking, which bypasses explicit "thinking" steps. Surprisingly, NoThinking performs comparably to or better than traditional reasoning under comparable or even lower compute budgets, especially when paired with parallel decoding and best-of-N selection.
Key Insights:
NoThinking prepends a dummy “Thinking” block and jumps straight to final answers.
Despite skipping structured reasoning, it outperforms Thinking in pass@k (1–64) on many benchmarks, especially under token constraints.
With parallel scaling, NoThinking achieves higher pass@1 accuracy than Thinking while using 4× fewer tokens and up to 9× lower latency.
Tasks evaluated: competitive math (AIME24/25, AMC23, OlympiadBench), coding (LiveCodeBench), and formal theorem proving (MiniF2F, ProofNet).
NoThinking is shown to provide superior accuracy–latency tradeoffs and generalizes across diverse tasks.
Results:
Low-budget wins: On AMC23 (700 tokens), NoThinking achieves 51.3% vs. 28.9% (Thinking).
Better scaling: As k increases, NoThinking consistently surpasses Thinking.
Efficiency frontier: Across benchmarks, NoThinking dominates the accuracy–cost Pareto frontier.
Parallel wins: With simple confidence-based or majority vote strategies, NoThinking + best-of-N beats full Thinking on pass@1 with significantly less latency.
6). SocioVerse

Researchers from Fudan University and collaborators propose SocioVerse, a large-scale world model for social simulation using LLM agents aligned with real-world user behavior. Key ideas include:
Four-fold alignment framework – SocioVerse tackles major challenges in aligning simulated environments with reality across four dimensions:
Environment: Continuously updated real-world events and social contexts (e.g., news, policies) feed into simulations.
Users: Agents are drawn from a massive 10M user pool constructed from real social media data (X and Rednote), labeled across 15 demographic traits.
Scenarios: Structured interaction formats—questionnaires, interviews, experiments, and social media exchanges—enable flexible and scalable simulation setups.
Behavior: Combines traditional ABMs and LLM-powered agents (e.g., GPT-4o-mini, Qwen2.5-72b) to simulate human-like decision-making.
Three representative simulations – SocioVerse showcases its generalizability through:
U.S. presidential election forecasting using electoral college simulation and iterative proportional fitting to match state-wise demographics.
ChatGPT release feedback analysis assessing public sentiment via a six-factor Likert questionnaire (e.g., trust, fairness, acceptance).
China’s national economic survey, modeling income/spending distributions across eight categories using hybrid lognormal-Pareto distributions.
Impressive empirical accuracy –
Election: Qwen2.5-72b predicts 92.2% of state outcomes correctly; DeepSeek-V3 and GPT-4o-mini also perform well (Acc ≈ 0.92).
News: GPT-4o achieves the lowest KL-divergence in mirroring real-world sentiment.
Economy: LLaMA3-70B leads with the lowest NRMSE, especially in developed regions, though all models struggle with housing-related expenditure simulation.
Ablation insights – Removing prior demographic distribution and user knowledge severely degrades election prediction accuracy (Acc drops from 0.80 → 0.60), highlighting the value of realistic population modelingpapersoftheweek.
Toward trustworthy virtual societies – SocioVerse not only standardizes scalable social simulations but also provides a sandbox for testing sociopolitical hypotheses (e.g., fairness, policy change), bridging AI agent systems with traditional social science.
7). DocAgent

Researchers from Meta AI present DocAgent, a tool‑integrated, dependency‑aware framework that turns large, complex codebases into well‑written docstrings. Key ideas include:
Topological Navigator for context building – DocAgent parses the repository’s AST, builds a dependency DAG, and documents components in topological order, so each function/class is visited only after its prerequisites, enabling incremental context accumulation and preventing context‑length explosions.
Role‑specialised agent team – Five agents work together: Reader analyses code, Searcher gathers internal & external references, Writer drafts docstrings, Verifier critiques and revises them, while the Orchestrator manages iterations until quality converges.
Adaptive context management – When retrieved context exceeds the model’s token budget, the Orchestrator trims low‑priority segments while preserving overall structure, keeping generation efficient and faithful2504.08725v1.
Three‑facet automatic evaluation – A new framework scores Completeness (section coverage), Helpfulness (LLM‑as‑judge semantic utility), and Truthfulness (entity grounding against the code DAG) for every docstring.
Substantial gains over baselines – On 366 components across nine Python repos, DocAgent + GPT‑4o‑mini lifts Completeness to 0.934 vs 0.815, Helpfulness to 3.88 / 5 vs 2.95, and Truthfulness (existence ratio) to 95.7 % vs 61.1 % compared with a Chat‑GPT baseline; FIM baselines fare far worse.
Navigator is crucial – An ablation that randomises processing order drops helpfulness by ‑0.44 and truthfulness by ‑7.9 pp, confirming the importance of dependency‑aware traversal.
8). SWE-PolyBench
SWE-PolyBench is a new multi-language benchmark for evaluating coding agents on real-world software tasks across Java, JavaScript, TypeScript, and Python. It introduces execution-based assessments, syntax tree metrics, and reveals that current agents struggle with complex tasks and show inconsistent performance across languages.
9). A Survey of Frontiers in LLM Reasoning
This survey categorizes LLM reasoning methods by when reasoning occurs (inference-time vs. training) and the system's architecture (standalone vs. agentic or multi-agent). It highlights trends like learning-to-reason (e.g., DeepSeek-R1) and agentic workflows (e.g., OpenAI Deep Research), covering prompt engineering, output refinement, and learning strategies such as PPO and verifier training.
10). Advances in Embodied Agents, Smart Cities, and Earth Science
This paper surveys how spatial intelligence manifests across disciplines—from embodied agents to urban and global systems—by connecting human spatial cognition with how LLMs handle spatial memory, representations, and reasoning. It offers a unifying framework to bridge research in AI, robotics, urban planning, and earth science, highlighting LLMs’ evolving spatial capabilities and their interdisciplinary potential.