
🥇Top AI Papers of the Week
The Top AI Papers of the Week (December 22-28)
1. Monitoring Monitorability
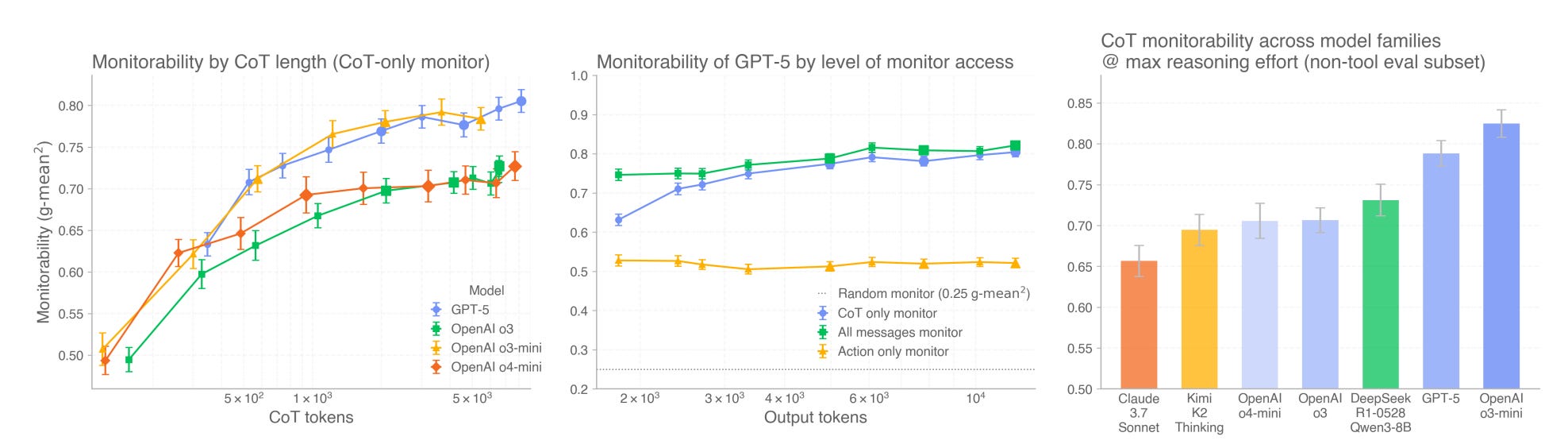
OpenAI introduces a framework for measuring how well we can detect misbehavior in AI systems by monitoring their chain-of-thought reasoning. The paper proposes three evaluation archetypes and a new metric (g-mean2) to track monitorability across different models and training regimes.
Three evaluation archetypes: Intervention evals apply controlled changes to inputs and check if monitors detect reasoning shifts. Process evals verify if models use valid solution paths for problems with known solutions. Outcome-property evals ask if monitors can predict properties of model outputs, like test hacking.
CoT monitoring works: Monitors with access to the chain-of-thought significantly outperform action-only monitors. Longer CoTs are generally more monitorable. GPT-5 Thinking at high reasoning effort shows strong monitorability across the evaluation suite.
RL does not degrade monitorability: Testing on frontier training runs for o3 and GPT-5.1 Codex Max, the authors find that RL optimization does not materially decrease monitorability at the current scale. Monitorability tends to correlate with CoT length during training.
Monitorability tax tradeoff: Smaller models at higher reasoning effort can match larger models’ capabilities while achieving higher monitorability - at increased inference compute cost. Giving weak monitors access to CoT steepens their test-time compute scaling for monitorability.
Message from the Editor

We are excited to announce our second cohort on Claude Code for Everyone. Learn how to leverage Claude Code for increasing your productivity and vibe coding.
Use coupon code EARLYBIRDCC25 for 25% today. Seats are limited!
2. Test-Time Training for Long-Context LLMs
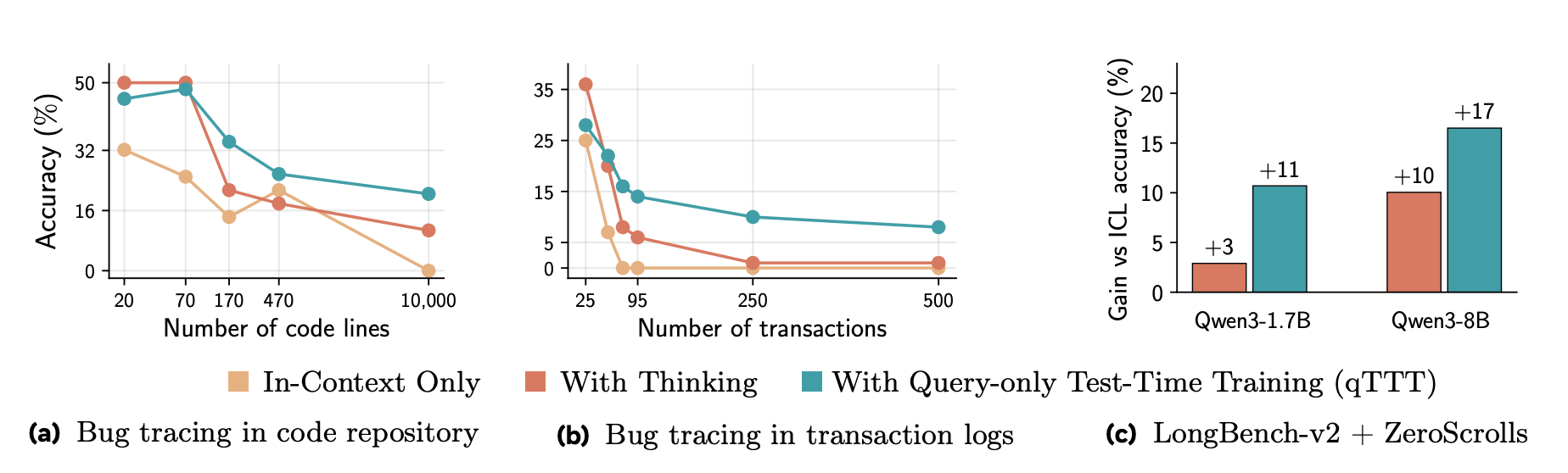
This paper shows that long-context LLMs can access millions of tokens but often fail to meaningfully use that information. The authors propose query-only test-time training (qTTT), which adapts models during inference through targeted gradient updates rather than generating more thinking tokens.
Score dilution problem: The authors identify that static self-attention suffers from score dilution, where target token probabilities vanish as context grows. They prove that target-distractor logit margins must scale logarithmically with context length to maintain performance.
Query-only TTT: qTTT performs a single prefill to cache keys and values, then applies lightweight gradient updates exclusively on query projection matrices. This keeps other parameters fixed and reuses the key-value cache, making it computationally efficient.
Massive improvements: qTTT achieves 12.6 and 14.1 percentage point improvements for Qwen3-4B on LongBench-v2 and ZeroScrolls benchmarks. Gains exceed 20% on code comprehension, multi-document QA, and multi-hop reasoning tasks.
Better compute allocation: Under matched inference-time compute budgets, qTTT consistently outperforms thinking token strategies. The practical takeaway is that a small amount of context-specific training beats generating thousands of thinking tokens for long-context tasks.
3. LaMer
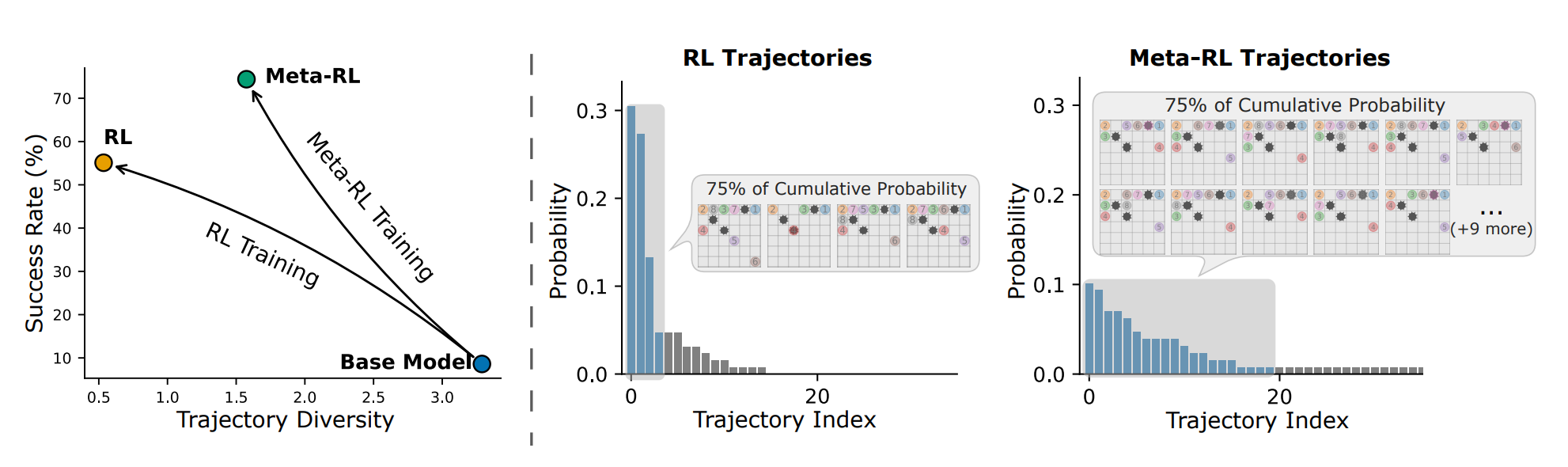
LaMer introduces a Meta-RL framework that enables LLM agents to actively explore and learn from environment feedback at test time. Unlike standard RL-trained agents that learn fixed policies and struggle with novel tasks, LaMer agents learn exploration strategies that transfer across environments.
Cross-episode training: Instead of optimizing single episodes independently, LaMer trains agents across sequences of episodes on the same task. Early episodes encourage exploration to gather information, while later episodes exploit that knowledge. A cross-episode discount factor controls the exploration-exploitation tradeoff.
In-context policy adaptation: The agent uses self-reflection to summarize past experiences and adjust strategy without gradient updates. This leverages LLMs’ natural in-context learning abilities - the agent essentially implements an RL algorithm in context during deployment.
Strong performance gains: On Qwen3-4B, LaMer achieves 11% improvement on Sokoban, 14% on MineSweeper, and 19% on Webshop over RL baselines. The framework produces more diverse trajectories while achieving higher success rates, reaching a better exploration-exploitation balance.
Better generalization: LaMer-trained agents generalize better to harder and out-of-distribution tasks compared to standard RL agents. The learned exploration strategies transfer to novel environments, enabling more robust adaptation at test time.
4. Epistemia
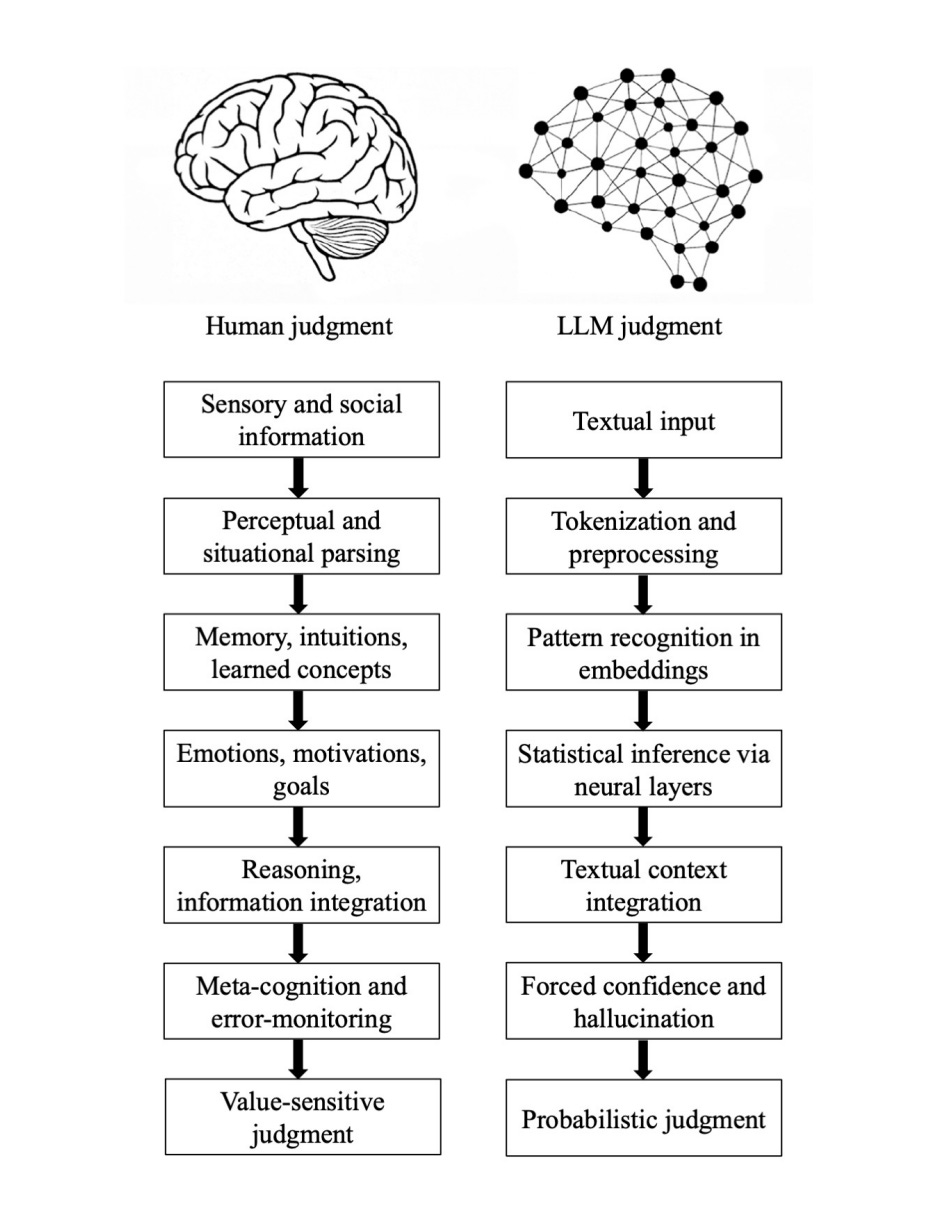
This paper argues that LLMs are not epistemic agents but stochastic pattern-completion systems. By mapping human and artificial epistemic pipelines, the authors identify seven fundamental fault lines where human and machine judgment diverge, despite producing superficially similar outputs.
Seven epistemic fault lines: The paper identifies divergences in grounding (perception vs text), parsing (situation understanding vs tokenization), experience (episodic memory vs embeddings), motivation (goals and emotions vs statistical optimization), causality (causal reasoning vs correlations), metacognition (uncertainty monitoring vs forced confidence), and value (moral commitment vs probabilistic prediction).
Introducing Epistemia: The authors define Epistemia as the structural condition where linguistic plausibility substitutes for epistemic evaluation. Users experience having an answer without the cognitive labor of judgment - the feeling of knowing without actually knowing.
Why hallucinations are not bugs: In this framework, hallucinations are not anomalous failures but the default operational state. LLMs produce ungrounded content because they lack reference, truth conditions, or evidential constraints. Grounded outputs only occur when the probability structure happens to coincide with the factual structure.
Implications for AI governance: The paper calls for epistemic evaluation beyond surface alignment, governance frameworks that regulate how generative outputs enter epistemic workflows, and new forms of epistemic literacy that help users recognize when apparent judgments are pattern completion rather than genuine evaluation.
5. JustRL
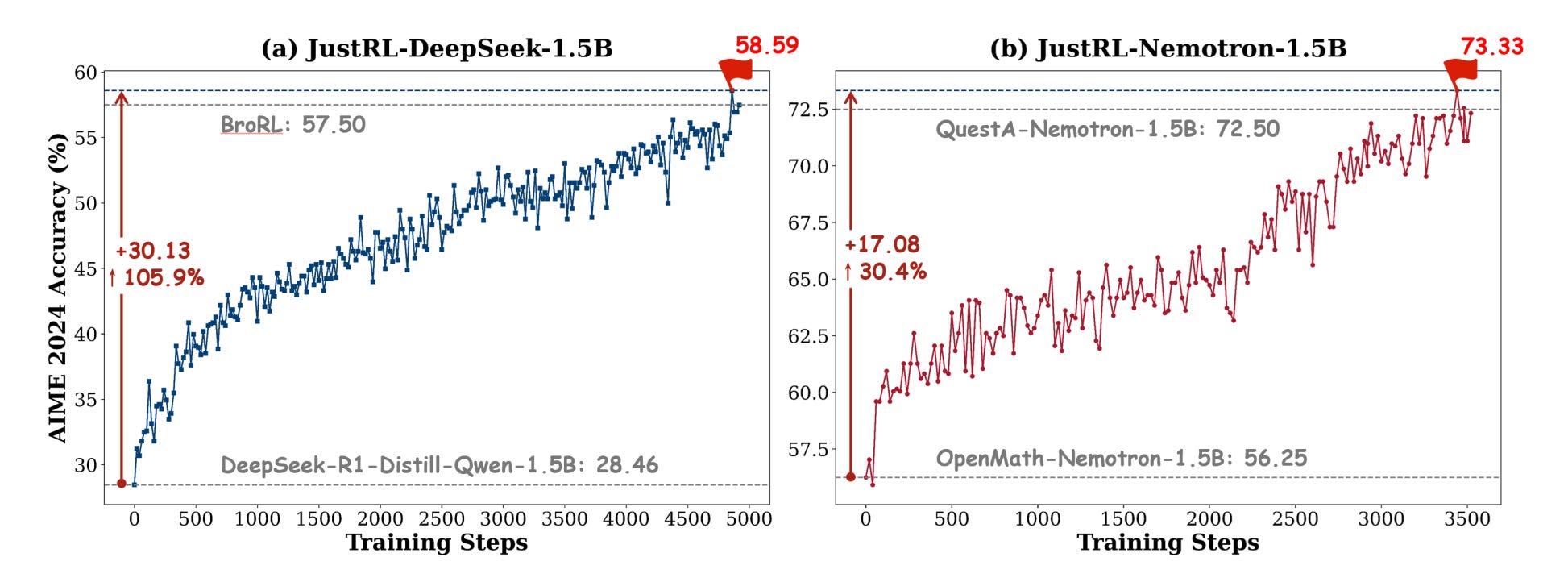
JustRL challenges the assumption that complex RL pipelines are necessary for training small language models. Using single-stage training with fixed hyperparameters, the authors achieve state-of-the-art math reasoning performance on two 1.5B models while using 2x less compute than sophisticated multi-stage approaches.
Simplicity wins: The recipe uses GRPO with binary rewards, no curriculum learning, no dynamic hyperparameters, no length penalties, and no multi-stage training. The same fixed hyperparameters work across both DeepSeek-R1-Distill-Qwen-1.5B and OpenMath-Nemotron-1.5B without tuning.
Strong results with less compute: JustRL-DeepSeek-1.5B achieves 54.9% average across nine math benchmarks, beating ProRL-V2’s 53.1% while using half the compute. JustRL-Nemotron-1.5B reaches 64.3%, slightly outperforming QuestA’s curriculum learning approach.
Stable training dynamics: Training shows smooth, monotonic improvement over 4,000+ steps without the collapses, plateaus, or oscillations that typically motivate complex interventions. Policy entropy stays healthy between 1.0 and 1.6, and response length naturally compresses without explicit penalties.
Adding tricks hurts performance: Ablations reveal that standard optimizations like explicit length penalties and robust verifiers actually degrade results by collapsing exploration. Length penalties dropped AIME24 performance from 55% to 50%, and adding both modifications dropped it to 45%.
6. Self-Play SWE-RL
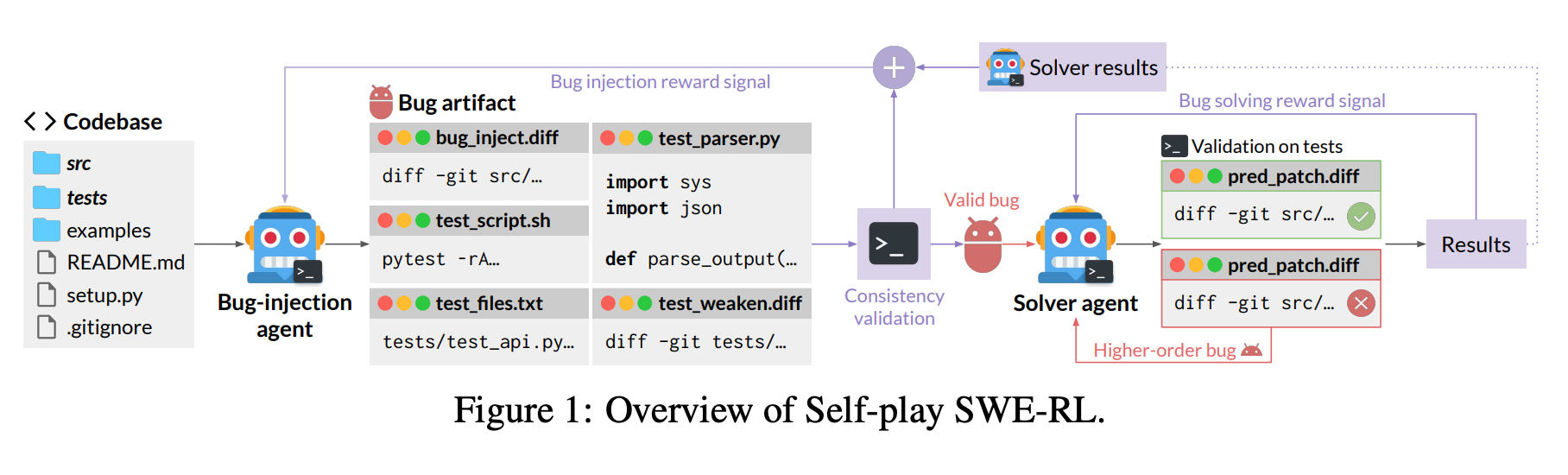
Self-Play SWE-RL (SSR) trains software engineering agents through self-play, requiring only access to sandboxed repositories with no human-labeled issues or tests. A single LLM learns to both inject and repair bugs of increasing complexity, achieving +10.4 points on SWE-bench Verified while consistently outperforming human-data baselines.
Minimal data assumptions: SSR requires only Docker images containing source code and dependencies. The agent discovers how to run tests, creates test parsers, and understands test suite structure entirely through environmental interaction - no prior knowledge of programming language or test framework needed.
Dual-role self-play: The same LLM policy plays two roles - a bug-injection agent that explores repositories and creates bug artifacts (including bug-inducing patches, test scripts, and test-weakening patches), and a bug-solving agent that repairs them. Both share parameters and train jointly with RL.
Higher-order bugs for curriculum: Failed repair attempts become new training data. These higher-order bugs mimic how developers unintentionally write buggy code, creating an evolving curriculum that naturally adapts to the agent’s improving capabilities.
Outperforms human-data training: SSR achieves +10.4 points on SWE-bench Verified and +7.8 on SWE-Bench Pro, consistently beating baseline RL trained with human-curated issues and tests across the entire training trajectory. Improvements transfer to natural language issues absent from self-play training.
7. Empirical Study of Agent Developer Practices
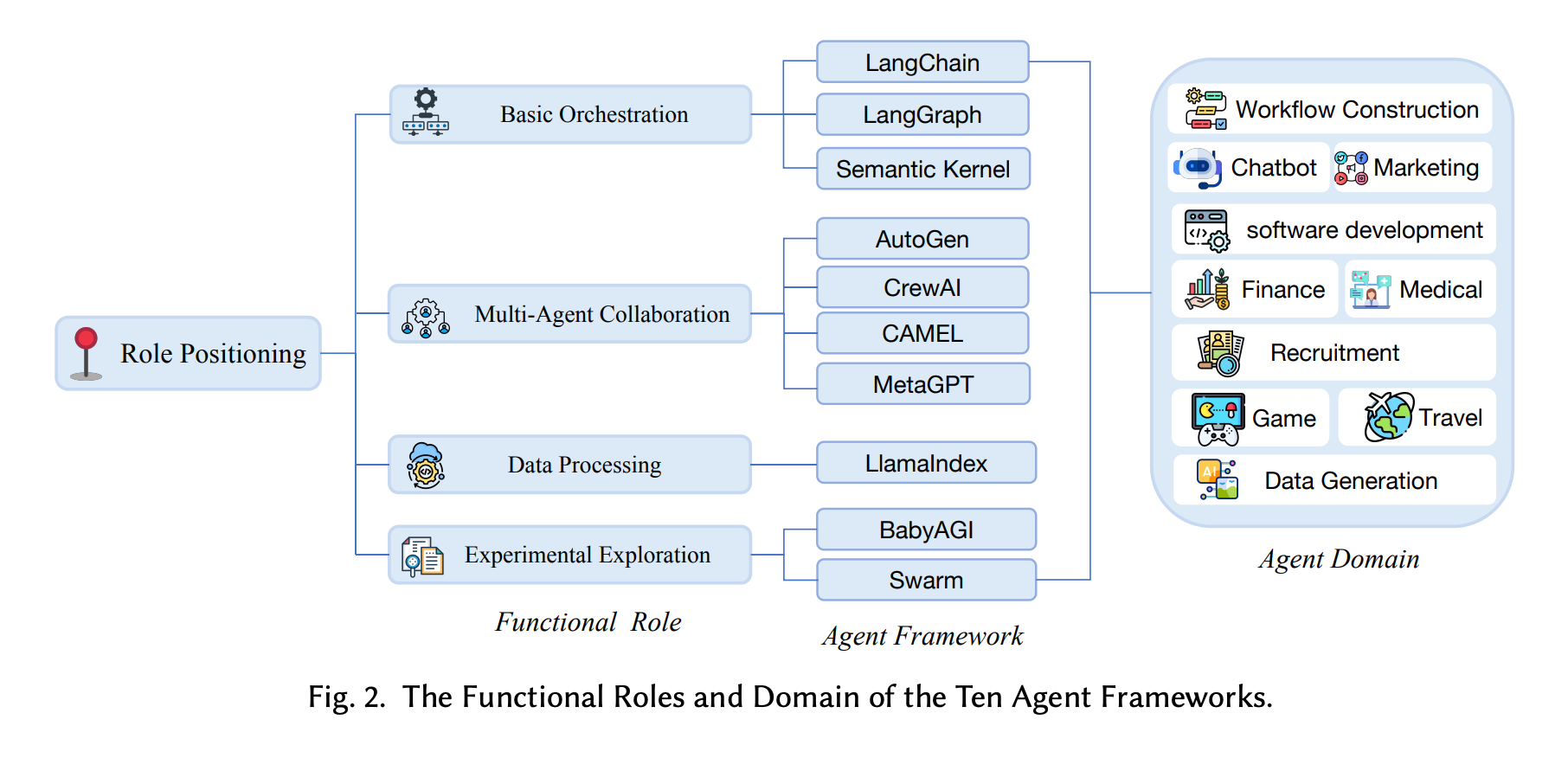
This paper presents the first large-scale empirical study of LLM-based agent frameworks, analyzing 11,910 developer discussions across ten popular frameworks. The research identifies practical challenges developers face and evaluates how well current frameworks meet their needs.
Four challenge domains: Developers encounter issues across logic (25.6% related to task termination and loop prevention), tools (14% from API limitations and permission errors), performance (25% involving context retention and memory management), and version conflicts (23% causing build failures and compatibility issues).
Framework selection is hard: More than 80% of developers report difficulty identifying frameworks that best meet their specific requirements. The study recommends prioritizing ecosystem robustness and long-term maintenance over short-term popularity when choosing frameworks.
Multi-framework combinations dominate: Combining multiple frameworks with different functions has become the primary approach to agent development. Each framework excels in different areas: LangChain and CrewAI lower barriers for beginners, while AutoGen and LangChain lead in task decomposition and multi-agent collaboration.
Performance optimization is universally weak: Across all ten frameworks studied, performance optimization remains a common shortcoming. Despite mature ecosystems, AutoGen and LangChain face the highest maintenance complexity, highlighting tradeoffs between feature richness and long-term maintainability.
8. Comprehensive Survey of Small Language Models
This survey provides a comprehensive overview of Small Language Models (SLMs), which address key LLM limitations, including high computational demands, privacy concerns from cloud APIs, and poor performance on edge devices. The authors propose a standardized SLM definition based on specialized task capability and resource-constrained suitability, and develop taxonomies and frameworks for SLM acquisition, enhancement, application, and reliability.
9. Sophia
Sophia introduces System 3, a meta-layer beyond traditional dual-process theory that enables LLM agents to maintain persistent identity and align short-term actions with long-term goals. The framework achieves 80% reduction in reasoning steps for recurring operations and 40% performance improvement on high-complexity tasks.
10. SonicMoE
SonicMoE addresses performance bottlenecks in Mixture of Experts models through IO-aware and tile-aware optimizations. The approach achieves 1.86x compute throughput improvement on Hopper GPUs, reduces activation memory by 45%, and enables training 213 billion tokens per day on 64 H100 GPUs for a 7B model.